
ニューラルネットワークが簡単に(第68回):オフライン選好誘導方策最適化

はじめに
強化学習は、探索中の環境における最適な行動方策を学習するための普遍的なプラットフォームです。方策の最適性は、環境との相互作用の間に環境から受け取る報酬を最大化することによって達成されます。しかし、ここにこのアプローチの主な問題の1つがあります。適切な報酬関数を作るには、多くの場合、多大な人的労力を必要とします。さらに、報酬がまばらであったり、真の学習目標を表現するには不十分であったりすることもあります。この問題を解決するための選択肢の1つとして、「Beyond Reward:Offline Preference-guided Policy Optimization」の作者は、OPPO (Offline Preference-guided Policy Optimization)法を提案しました。この方法の作者は、環境から与えられる報酬を、探索中の環境で完了した2つの軌跡の間の人間の注釈者の選好に置き換えることを提案しています。提案されたアルゴリズムを詳しく見てみましょう。
1.OPPOのアルゴリズム
オフライン選好誘導学習(OPPO)の文脈では、一般的なアプローチは2つのステップから構成されます。通常、教師あり学習を使用して報酬関数モデルを最適化し、次に学習された報酬関数を使用して再定義された遷移上で任意のオフラインRLアルゴリズムを使用して方策を学習します。しかし、報酬関数を個別に訓練することは、最適な行動をとる方法を直接的に方策に指示することにはならないかもしれません。選好ラベルは学習課題を定義するため、報酬を最大化することよりも、最も好まれた軌道を学習することが目標となります。複雑な問題の場合、スカラー報酬は方策の最適化において情報のボトルネックを作り出し、その結果エージェントの行動が最適化されなくなります。さらに、オフラインでの方策最適化は、不正確な報酬関数の脆弱性を悪用する可能性があります。その結果、望ましくない行動につながります。
この2段階のアプローチに代わるものとして、オフライン選好誘導方策最適化法(OPPO)の作者は、オフライン選好誘導データセットから直接方策を学習することを目指しています。彼らは、報酬関数を別途訓練する必要なく、オフラインの選好をモデル化し、最適な決定方策を同時に学習するワンステップアルゴリズムを提案しています。これは2つの目標を使用することで達成されます。
- オフラインが「ない」場合の情報収集
- 選好モデリング
これらの目標を繰り返し最適化することで、オフラインデータと選好Z'の最適文脈をモデル化する文脈方策π(A|S,Z)を構築します。OPPOの焦点は、高次元空間Zを探索し、そのような空間における方策を評価することです。この高次元Z空間は、スカラーペイオフに比べ、目の前のタスクに関するより多くの情報を捉え、方策最適化の目的に理想的です。また、学習した最適文脈Z'に対して文脈方策π(A|S,Z)を条件付きでモデル化することで最適方策を得ます。
このアルゴリズムの作者は、モデルIθによって選好関数を近似することが可能であるという仮定を導入しています。これにより、次の目標を立てることができます。
![]()
ここで、Z=Iθ(τ)は選好の文脈です。このエンコーダーデコーダーの構造は、オフラインのシミュレーション学習に似ています。しかし、選好に基づく学習設定には専門家の実演がないため、アルゴリズムの作者は選好ラベルを使用して遡及的な情報を抽出しています。
履歴情報Iθ(τ)とラベル付けされたデータセットの選好との整合性を達成するために、この方法の作者は選好モデリングの目標を次のように定式化しました。
![]()
ここで、z+とz-はそれぞれ、選好された(正の)軌道Iθ(yτj + (1-y)τi)と、選好されなかった(負の)軌道Iθ(yτi + (1-y)τj)の文脈を表します。この目標の根底にある仮定は、通常、2つの軌跡(τi, τj)間で選好を表明する前に、通常2段階の比較がおこなわれるということです。
- 軌道τi仮想最適軌道τ*、つまりl(z*,z+) との類似性と、軌道τjと仮説最適軌道τ* 、つまりl(z*,z-)との類似性の個別の比較
- 優先軌道に近い方に設定された軌道を使用した、この2つの類似度l(z*,z+)とl(z*,z-)の差の推定
このように、目標の最適化によって、z+に近く、z-に近くない最適な文脈が確実に見つかります。
z*は軌跡τ*に関連する文脈であり、軌跡τ*は常にデータセット内のオフラインの軌跡よりも優先されることを明確にしておく必要があります。
なお、最適文脈z*の事後確率と遡及的選好情報Iθ(•)の抽出は、学習の安定性を確保するために1つずつ更新されます。最適な埋め込みをより適切に推定することで、エンコーダーは、人が選好する際に、より注意を払う特徴を抽出することができます。その結果、より優れた遡及的情報エンコーダーは、高レベルの埋め込み空間における最適な軌道を見つけるプロセスをスピードアップします。したがって、エンコーダーの損失関数は2つの部分から構成されます。
- 教師付き学習スタイルにおける振り返りからの情報を比較する際の誤差
- ラベル付けされた選好データセットが提供するバイナリ観測をより良く取り入れるための誤差
作者によるOPPOアルゴリズムの可視化を以下に示します。
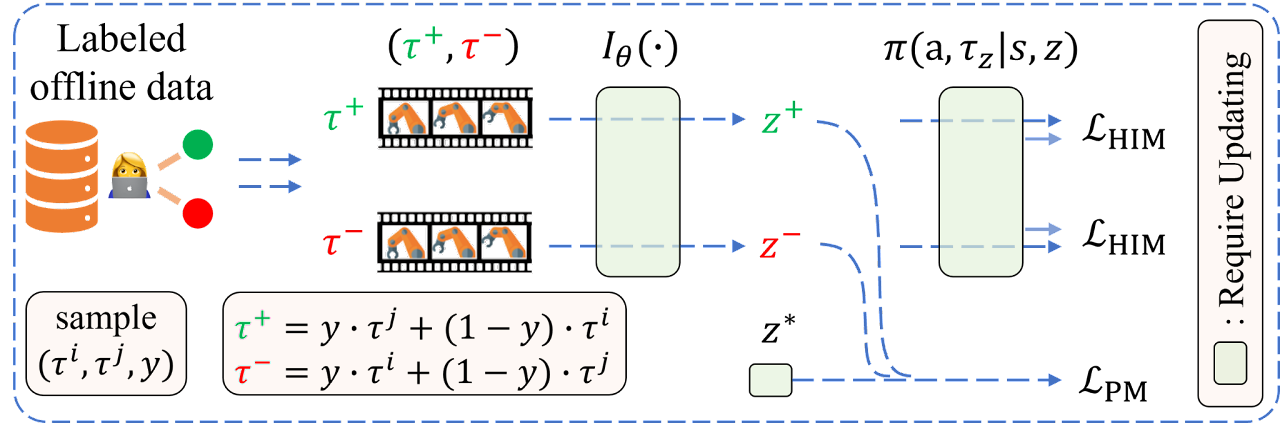
2.MQL5を使用した実装
アルゴリズムの理論的側面について考察したので、次は実用的な部分に移り、提案アルゴリズムの実装について考察します。まずはデータ保存構造体のSStateです。上述したように、この方法の作者は、従来使用されてきた報酬を軌跡選好ラベルに置き換えています。したがって、環境の新しい状態に移行するたびに報酬を保存する必要はありません。同時に、選好された軌道の文脈という概念も紹介します。環境状態を記述する構造体で提案されたロジックに従い、報酬を分解したrewards配列をscheduler文脈配列に置き換えます。
struct SState { float state[BarDescr * NBarInPattern]; float account[AccountDescr]; float action[NActions]; float scheduler[EmbeddingSize]; //--- SState(void); //--- bool Save(int file_handle); bool Load(int file_handle); //--- void Clear(void) { ArrayInitialize(state, 0); ArrayInitialize(account, 0); ArrayInitialize(action, 0); ArrayInitialize(scheduler, 0); } //--- overloading void operator=(const SState &obj) { ArrayCopy(state, obj.state); ArrayCopy(account, obj.account); ArrayCopy(action, obj.action); ArrayCopy(scheduler, obj.scheduler); } };
名前だけでなく、配列のサイズも変更したことに注意してください。
隠された文脈に加え、このアルゴリズムは軌道の選好という概念も導入しています。ここで注意すべき点がいくつかあります。
- 優先順位は、個々の行動や移行ではなく、軌道全体に対して設定される(方策は評価される)
- 優先順位は、オフラインデータセット内のすべての軌跡の間で、[0:1]の範囲で設定される
- 優先順位は専門家が決める
経験再生バッファからすべての軌道に手動で優先順位を設定するわけではないことに注意してください。また、優先順位のチェス表は作りません。
選択できる優先基準はかなり多いです。しかし、この記事の枠内では、軌道を通過することによる利益の1つだけを使用しました。残高とエクイティの両方の観点から、最大ドローダウンを基準に加えることは可能だと思います。また、プロフィットファクターやその他の基準も加えることができます。ご自分にとって最適な基準とその係数を独自に選択することをお勧めします。選択する基準のセットは、確かに方策の訓練の最終結果に影響しますが、提案された実装のアルゴリズムには影響しません。
また、優先順位は軌跡全体に対して設定されるため、軌跡の最後に受け取った利益分だけを保存すればよいです。それを軌跡記述構造体STrajectoryに保存します。
struct STrajectory { SState States[Buffer_Size]; int Total; double Profit; //--- STrajectory(void); //--- bool Add(SState &state); void ClearFirstN(const int n); //--- bool Save(int file_handle); bool Load(int file_handle); //--- overloading void operator=(const STrajectory &obj) { Total = obj.Total; Profit = obj.Profit; for(int i = 0; i < Buffer_Size; i++) States[i] = obj.States[i]; } };
もちろん、構造体のフィールドを変更するには、指定された構造体のファイルをコピーしたり操作したりする方法を変更する必要があります。これらの調整は非常に特殊なので、添付ファイルでよく理解することをお勧めします。
2.1 モデルのアーキテクチャ
方策の訓練には2つのモデルを使用します。スケジューラーは選好を学習し、エージェントは行動方策を学習します。どちらのモデルもDecision Transformer (DT)の原理に基づいて構築され、アテンションメカニズムを使用します。ただし、モデルを1つずつ更新する作者の解とは異なり、モデルを訓練するために2つのEAを作成します。それぞれが1つのモデルの訓練に参加するだけです。モデルをテストし運用する段階で、それらを1つのメカニズムに統合します。そこで、モデルのアーキテクチャを記述するために、2つのメソッドも作成します。
- CreateSchedulerDescriptions:スケジューラのアーキテクチャを記述
- CreateAgentDescriptions:エージェントのアーキテクチャを記述
スケジューラーに次を入力します。
- 過去の値動きと指標データ
- 口座状況と未決済ポジションの説明
- タイムスタンプ
- エージェントの最後の行動
bool CreateSchedulerDescriptions(CArrayObj *scheduler) { //--- CLayerDescription *descr; //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; } //--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions); descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
以前の記事で見てきたように、Decision TransformerはGPTアーキテクチャを探索し、以前に受け取ったデータの埋め込みを隠しステートに保存します。これにより、エピソード全体を通じて単一のコンテキストで意思決定をおこなうことができます。そのため、最新の変更点を中心に、現状を簡単に説明するのみです。つまり、最後に閉じたローソク足のデータだけをモデルに入力します。
受信したデータは正規化層で前処理されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
その後、埋め込み層で同等の形に変換されます。
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!scheduler.Add(descr)) { delete descr; return false; }
次に、SoftMax関数を使用して、結果の埋め込みを正規化します。
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count * 4; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
このようにして前処理されたデータは、アテンションブロックを通過します。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count * 4; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
再びSoftMax関数で受信データを正規化し、全結合決定層のブロックに通します。
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = EmbeddingSize; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- return true; }
モデルの出力では、文脈の潜在的な表現のベクトルを受け取ります。そのサイズは EmbeddingSize 定数によって決まります。
エージェントにも同様のアーキテクチャを描いています。生成された文脈は、そのソースデータに追加されます。
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CreateAgentDescriptions(CArrayObj *agent) { //--- CLayerDescription *descr; //--- if(!agent) { agent = new CArrayObj(); if(!agent) return false; } //--- Agent agent.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (BarDescr * NBarInPattern + AccountDescr + TimeDescription + NActions + EmbeddingSize); descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
また、データはバッチ正規化と埋め込み層を通して前処理され、SoftMax関数によって正規化されます。
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; prev_count = descr.count = HistoryBars; { int temp[] = {BarDescr * NBarInPattern, AccountDescr, TimeDescription, NActions, EmbeddingSize}; ArrayCopy(descr.windows, temp); } int prev_wout = descr.window_out = EmbeddingSize; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count * 5; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
アテンションブロックとSoftMax関数による正規化を完全に繰り返します。ここでは、処理されるテンソルのサイズを変更することだけに注意すればよいです。
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; prev_count = descr.count = prev_count * 5; descr.window = EmbeddingSize; descr.step = 8; descr.window_out = 32; descr.layers = 4; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = EmbeddingSize; descr.step = prev_count; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
次に、畳み込み層を使用してデータの次元を減らすと同時に、その中から安定したパターンを特定しようとします。
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = EmbeddingSize; descr.step = EmbeddingSize; prev_wout = descr.window_out = EmbeddingSize; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count; descr.window = prev_wout; descr.step = prev_wout; prev_wout = descr.window_out = prev_wout / 2; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = prev_count; descr.step = prev_wout; descr.activation = None; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; }
その後、データは4つの全結合層からなる意思決定ブロックを通過します。最後の層のサイズはエージェントの行動スペースに等しくなります。
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.optimization = ADAM; descr.activation = LReLU; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!agent.Add(descr)) { delete descr; return false; } //--- return true; }
2.2 訓練のための軌道の収集
モデルのアーキテクチャを説明した後、その訓練のためのEAの構築に移ります。まず、環境とのインタラクションのためのEAを構築し、軌跡を収集し、経験再生バッファを埋めます。これは、後でオフライン学習プロセス「...\OPPO\Research.mq5」で活用します。
環境を探索するために、ɛグリーディ戦略を使用し、対応する外部パラメータをEAに追加します。
input double Epsilon = 0.5;
前述したように、環境との相互作用の過程で、両方のモデルを使用します。そのため、グローバル変数を宣言する必要があります。
CNet Agent; CNet Scheduler;
EAを初期化するメソッドは、先に説明したEAの同様の方法と大差ありません。したがって、そのアルゴリズムを改めて検討する必要はないと思います。添付ファイルで確認できます。OnTickメソッドについて考えてみましょう。このメソッドの本体では、環境との相互作用とデータ収集の主要なプロセスが構築されています。
メソッド本体では、新しいバーを開くイベントの発生を確認します。
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
必要に応じて、過去の値動きデータをダウンロードします。
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), History, Rates); if(!ArraySetAsSeries(Rates, true)) return;
そして、分析した指標の数値を更新します。
RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
受信したデータを現在の状態の構造にフォーマットし、モデルの入力データとして使用するためにデータバッファに転送します。
//--- History data float atr = 0; //--- for(int b = 0; b < (int)NBarInPattern; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
次の段階では、口座残高と未決済ポジションに関する情報で、環境の現状に関する記述の構造を補足します。
//--- Account description sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
収集された情報は、ソースデータバッファにも追加されます。
bState.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bState.Add((float)(sState.account[1] / PrevBalance)); bState.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bState.Add(sState.account[2]); bState.Add(sState.account[3]); bState.Add((float)(sState.account[4] / PrevBalance)); bState.Add((float)(sState.account[5] / PrevBalance)); bState.Add((float)(sState.account[6] / PrevBalance));
次に、タイムスタンプとエージェントの最後の行動をソースデータバッファに追加します。
//--- Time label double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bState.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bState.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bState.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action bState.AddArray(AgentResult);
この段階で、スケジューラーのフィードフォワードパスに必要な情報は十分に収集できました。これによって、エージェントに必要な文脈ベクトルを形成することができます。そこで、スケジューラーのフィードフォワードパスを実行します。
if(!Scheduler.feedForward(GetPointer(bState), 1, false)) return; Scheduler.getResults(sState.scheduler); bState.AddArray(sState.scheduler);
得られた結果をアンロードし、ソースデータバッファを補足します。その後、エージェントのフィードフォワードパスメソッドを呼び出します。
if(!Agent.feedForward(GetPointer(bState), 1, false, (CBufferFloat *)NULL)) return;
ここで、各段階での正しい業務遂行を管理する必要性を思い出してください。
この段階で、モデルでの作業を終え、その後の操作のためにデータを保存し、環境との直接対話に移ります。
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
エージェントからデータを受け取った後、必要に応じてノイズを加えます。
Agent.getResults(AgentResult); if(Epsilon > (double(MathRand()) / 32767.0)) for(ulong i = 0; i < AgentResult.Size(); i++) { float rnd = ((float)MathRand() / 32767.0f - 0.5f) * 0.03f; float t = AgentResult[i] + rnd; if(t > 1 || t < 0) t = AgentResult[i] - rnd; AgentResult[i] = t; } AgentResult.Clip(0.0f, 1.0f);
ポジションサイズから重複ボリュームを削除します。
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(AgentResult[0] >= AgentResult[3]) { AgentResult[0] -= AgentResult[3]; AgentResult[3] = 0; } else { AgentResult[3] -= AgentResult[0]; AgentResult[0] = 0; }
その後、まずロングポジションを調整します。
//--- buy control if(AgentResult[0] < 0.9 * min_lot || (AgentResult[1] * MaxTP * Symb.Point()) <= stops || (AgentResult[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double(AgentResult[0] + FLT_EPSILON) - min_lot) / step_lot) * step_lot; double buy_tp = Symb.NormalizePrice(Symb.Ask() + AgentResult[1] * MaxTP * Symb.Point()); double buy_sl = Symb.NormalizePrice(Symb.Ask() - AgentResult[2] * MaxSL * Symb.Point()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
そして、ショートポジションについても同様の操作をおこないます。
//--- sell control if(AgentResult[3] < 0.9 * min_lot || (AgentResult[4] * MaxTP * Symb.Point()) <= stops || (AgentResult[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double(AgentResult[3] + FLT_EPSILON) - min_lot) / step_lot) * step_lot; double sell_tp = Symb.NormalizePrice(Symb.Bid() - AgentResult[4] * MaxTP * Symb.Point()); double sell_sl = Symb.NormalizePrice(Symb.Bid() + AgentResult[5] * MaxSL * Symb.Point()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
この段階で通常、報酬ベクトルを形成します。しかし、現在のアルゴリズムの枠組みでは、報酬は使用されていません。したがって、エージェントの完了した行動に関するデータを転送し、軌跡を保存するためのデータを送信するだけです。
for(ulong i = 0; i < NActions; i++) sState.action[i] = AgentResult[i]; if(!Base.Add(sState)) ExpertRemove(); }
そして次のバーが開くのを待ちます。
このとき、選好をどのように評価するのかという疑問が生じます。
答えは簡単です。ストラテジーテスターでパスを完了した後、OnTesterメソッドにパスの有効性に関する情報を追加します。
//+------------------------------------------------------------------+ //| Tester function | //+------------------------------------------------------------------+ double OnTester() { //--- double ret = 0.0; //--- Base.Profit = TesterStatistics(STAT_PROFIT); Frame[0] = Base; if(Base.Profit >= MinProfit) FrameAdd(MQLInfoString(MQL_PROGRAM_NAME), 1, Base.Profit, Frame); //--- return(ret); }
環境と相互作用するためのEAの残りのメソッドに変更はありません。添付ファイルをご覧ください。モデルの訓練アルゴリズムの検討に移りましょう。
2.3 選好モデルの訓練
まず、選好モデル訓練用EA「...\OPPO\StudyScheduler.mq5」を見てみましょう。EAのアーキテクチャーに変更はないので、ここではモデルの訓練方法についてのみ詳しく説明します。
モデル訓練のプロセスには、以前の記事から発展させたものを使用していることを認めなければなりません。私の個人的な意見ですが、それらとの共生は学習プロセスの効率を高めるはずです。
学習プロセスを開始する前に、CWBC法で提案されたように、収益性に基づいて軌道を選択するための確率分布を生成します。しかし、先に説明したGetProbTrajectoriesメソッドは、報酬ベクトルがないため、いくつかの修正が必要です。まず、軌跡の総合結果に関する情報源を変えます。この場合、分解された報酬ベクトルは最終利益のスカラー値に置き換えられます。そこで、行列をベクトルに置き換えます。
vector<double> GetProbTrajectories(STrajectory &buffer[], float lanbda) { ulong total = buffer.Size(); vector<double> rewards = vector<double>::Zeros(total); for(ulong i = 0; i < total; i++) rewards[i]=Buffer[i].Profit;
そして、収益性の最大水準と標準偏差を決定します。
double std = rewards.Std(); double max_profit = rewards.Max();
次のステップでは、パーセンタイルを正しく決定するために、軌跡の結果を並べ替えます。
vector<double> sorted = rewards; bool sort = true; while(sort) { sort = false; for(ulong i = 0; i < sorted.Size() - 1; i++) if(sorted[i] > sorted[i + 1]) { double temp = sorted[i]; sorted[i] = sorted[i + 1]; sorted[i + 1] = temp; sort = true; } }
確率分布を構築するための更なる手順は変更されておらず、以前説明した形で使用されています。
double min = rewards.Min() - 0.1 * std; if(max_profit > min) { double k = sorted.Percentile(90) - max_profit; vector<double> multipl = MathAbs(rewards - max_profit) / (k == 0 ? -std : k); multipl = exp(multipl); rewards = (rewards - min) / (max_profit - min); rewards = rewards / (rewards + lanbda) * multipl; rewards.ReplaceNan(0); } else rewards.Fill(1); rewards = rewards / rewards.Sum(); rewards = rewards.CumSum(); //--- return rewards; }
この時点で準備段階は完了したと考えることができるので、選好モデルの学習アルゴリズムであるTrainの検討に移ります。
メソッドの本体では、まず、前述のGetProbTrajectoriesメソッドを用いて、経験再生バッファから軌道を選択する確率分布のベクトルを形成します。
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { vector<double> probability = GetProbTrajectories(Buffer, 0.1f); uint ticks = GetTickCount();
次に、モデルの訓練ループのシステムを整理します。外部ループの反復回数は、EAの外部パラメータによって決定されます。
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr_p = SampleTrajectory(probability); int tr_m = SampleTrajectory(probability); while(tr_p == tr_m) tr_m = SampleTrajectory(probability);
ループ本体では、正と負の例として2つの軌道をサンプリングします。最大限の客観性の原則に従うため、経験再生バッファから2つの異なる軌道を選択するよう制御します。
明らかに、単純なサンプリングは、最初に正の軌道を選択することを保証しません。その逆も当てはまります。そこで、選択された軌道の収益性を確認し、必要であれば変数内の軌道へのポインタを再配置します。
if(Buffer[tr_p].Profit < Buffer[tr_m].Profit) { int t = tr_p; tr_p = tr_m; tr_m = t; }
さらに、OPPOアルゴリズムでは、負の軌道から選好された軌道に向かう方向に選好モデルを訓練する必要があります。一見、簡単で明白に見えるかもしれません。しかし、実際にはいくつかの落とし穴があります。
すべての軌跡を生成するために、過去のデータの1セグメントを使用しました。したがって、値動きに関する情報と、すべての軌跡の分析指標の値は同じになります。しかし、他の分析パラメータについては状況が異なります。口座の状況、未決済ポジション、そしてもちろんエージェントの行動についてです。したがって、誤差勾配の正しい伝搬を保証するためには、両方の軌道からの状態に対してフィードフォワードパスを順次実行する必要があります。
しかし、これは次の疑問につながります。私たちのモデルでは、入力データのシーケンスに敏感なGPTアーキテクチャを使用しています。では、1つのモデルの中で2つの異なる軌道のシーケンスを保存するにはどうすればいいのでしょうか。明白な答えは、TD3やSAC法におけるターゲットモデルのソフト更新と同様に、重み係数を周期的にマージしながら2つのモデルを並行して使用することです。しかし、ここにも困難があります。前述の方法では、ターゲットモデルは訓練されませんでした。私たちはソフトラーニングの一環として、それらのモーメントバッファを利用しました。この場合、モデルは訓練されます。そのため、モーメントバッファは本来の目的で使用されます。重み係数のソフトな更新に関する情報でそれらを補うことは、学習プロセスを歪める可能性があります。詳細な分析を省略せず、建設的な解決策を模索します。
私の意見では、最も受け入れやすい選択肢は、まず1つの軌道のデータで1つのモデルを順次訓練し、次に誤差勾配の逆数値を使用して2つ目の軌道のデータで訓練することです。なぜなら、選好された軌道では距離を最小にし、そうでない軌道では距離を最大にするからです。
このロジックに従って、選好された軌道上の初期状態をサンプリングします。
//--- Positive int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr_p].Total - 2 * HistoryBars - NBarInPattern, MathMin(Buffer[tr_p].Total, 20))); if(i < 0) { iter--; continue; }
モデルスタックをクリアし、望ましい軌道の枠組みの中で学習プロセスを整理します。
Scheduler.Clear(); for(int state = i; state < MathMin(Buffer[tr_p].Total - 1 - NBarInPattern, i + HistoryBars * 2); state++) { //--- History data State.AssignArray(Buffer[tr_p].States[state].state);
ループ本体では、軌跡の訓練サンプルから過去の値動き値と指標値で初期データバッファを満たします。
口座状況と未決済ポジションに関する情報を追加します。
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr_p].States[state].account[0] : Buffer[tr_p].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr_p].States[state].account[1] : Buffer[tr_p].States[state - 1].account[1]); State.Add((Buffer[tr_p].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr_p].States[state].account[1] / PrevBalance); State.Add((Buffer[tr_p].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr_p].States[state].account[2]); State.Add(Buffer[tr_p].States[state].account[3]); State.Add(Buffer[tr_p].States[state].account[4] / PrevBalance); State.Add(Buffer[tr_p].States[state].account[5] / PrevBalance); State.Add(Buffer[tr_p].States[state].account[6] / PrevBalance);
タイムスタンプのハーモニクスとエージェントの最後の行動のベクトルを追加してみましょう。
//--- Time label double x = (double)Buffer[tr_p].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_p].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr_p].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_p].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action if(state > 0) State.AddArray(Buffer[tr_p].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions));
必要なデータをすべて収集することに成功したら、訓練済みモデルに対してフィードフォワードパスを実行します。
//--- Feed Forward if(!Scheduler.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
モデルは教師あり学習法と同様に訓練され、経験再生バッファ内の対応する選好された軌道データからの予測される文脈値の偏差を最小化することを目的としています。
//--- Study Result.AssignArray(Buffer[tr_p].States[state].scheduler); if(!Scheduler.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
次に、学習プロセスの進捗状況をユーザーに通知し、選好された軌道でモデルを学習する次の反復に移ります。
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheeduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
選好された軌道内でのループの反復が成功したら、2番目の軌道での作業に移ります。
理論的には、同じような期間で作業し、正の軌道のためにサンプリングされた初期状態を使用することができます。ある履歴期間では、すべての軌跡において同じステップ数です。しかし、これは特殊なケースです。しかし、より一般的なケースを考えれば、軌道のステップ数が異なるさまざまなバリエーションがあり得ます。例えば、長い期間や少額の保証金で運用する場合、保証金を失い、ストップアウトする可能性があります。そこで、作業軌跡内の初期状態をサンプリングすることにしました。
//--- Negotive i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr_m].Total - 2 * HistoryBars - NBarInPattern, MathMin(Buffer[tr_m].Total, 20))); if(i < 0) { iter--; continue; }
次に、モデルスタックをクリアし、訓練ループを構成します。選好された軌道の枠組み内で上記でおこなわれた作業と同様です。
Scheduler.Clear(); for(int state = i; state < MathMin(Buffer[tr_m].Total - 1 - NBarInPattern, i + HistoryBars * 2); state++) { //--- History data State.AssignArray(Buffer[tr_m].States[state].state); //--- Account description float PrevBalance = (state == 0 ? Buffer[tr_m].States[state].account[0] : Buffer[tr_m].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr_m].States[state].account[1] : Buffer[tr_m].States[state - 1].account[1]); State.Add((Buffer[tr_m].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr_m].States[state].account[1] / PrevBalance); State.Add((Buffer[tr_m].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr_m].States[state].account[2]); State.Add(Buffer[tr_m].States[state].account[3]); State.Add(Buffer[tr_m].States[state].account[4] / PrevBalance); State.Add(Buffer[tr_m].States[state].account[5] / PrevBalance); State.Add(Buffer[tr_m].States[state].account[6] / PrevBalance); //--- Time label double x = (double)Buffer[tr_m].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_m].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr_m].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr_m].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action if(state > 0) State.AddArray(Buffer[tr_m].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions)); //--- Feed Forward if(!Scheduler.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
ただし、目標設定には細かい点があります。2つの選択肢を考慮します。まず、特別なケースとして、選好された軌道と2番目の軌道の利益が同じである場合(基本的に、どちらの軌道も選好される)、選好された軌道と同様のアプローチを用います。
//--- Study if(Buffer[tr_p].Profit == Buffer[tr_m].Profit) Result.AssignArray(Buffer[tr_m].States[state].scheduler);
2つ目のケースはより一般的で、2つ目の軌道の利益が低い場合、そこから逆方向に跳ね返らなければなりません。そのために、予測値をアンロードし、経験再生バッファから負の軌跡の文脈からのずれを見つけます。しかし、ここでは逆の方向に進まなければなりません。したがって、予測値からその結果の偏差を足すのではなく、引くのです。選好された軌道に向かう優先度を高めるため、目標値を計算する際、結果として生じる偏差を2倍にします。
else { vector<float> target, forecast; target.Assign(Buffer[tr_m].States[state].scheduler); Scheduler.getResults(forecast); target = forecast - (target - forecast) / 2; Result.AssignArray(target); }
これで、調整された目標との偏差を最小化するために、利用可能な方法を用いてモデルのバックプロパゲーションパスを実行することができます。
if(!Scheduler.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
学習プロセスの進捗状況をユーザーに知らせ、ループの次の反復に移ります。
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheeduler", (iter + 0.5) * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
学習ループシステムのすべての反復が完了したら、チャートのコメント欄を消去します。訓練プロセスの結果をログに記録し、EAを強制的にシャットダウンするプロセスを開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); ExpertRemove(); //--- }
選好モデル「...\OPPO\StudyScheduler.mq5」を訓練するためのEAメソッドの検討が完了しました。すべてのメソッドと関数の完全なコードは添付ファイルにあります。
2.4 エージェント方策の訓練
次に、エージェント方策訓練EA「...\OPPO\StudyAgent.mq5」を構築します。EAのアーキテクチャは、前述したEAとほぼ同じです。Trainモデルの訓練方法に若干の違いがあるだけです。もう少し詳しく考えてみましょう。
前回と同様、メソッド本体では、まずGetProbTrajectoriesメソッドを呼び出して軌道を選択する確率を決定します。
vector<double> probability = GetProbTrajectories(Buffer, 0.1f); uint ticks = GetTickCount();
次に、ネストされたモデル学習ループのシステムを構成します。
bool StopFlag = false; for(int iter = 0; (iter < Iterations && !IsStopped() && !StopFlag); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * MathMax(Buffer[tr].Total - 2 * HistoryBars - NBarInPattern, MathMin(Buffer[tr].Total, 20))); if(i < 0) { iter--; continue; }
今回は、外側ループの本体で1つの軌跡だけをサンプリングします。この段階では、潜在的な文脈と特定の行動をマッチさせることができるエージェントの方策を学習する必要があります。これにより、エージェントの行動をより予測しやすく、制御しやすくなります。従って、選好された軌道とそうでない軌道に分けることはしません。
次に、モデルスタックをクリアし、サンプリングされたサブトラジェクトリの連続する状態の中で、ネストされたモデル学習ループを構成します。
Agent.Clear(); for(int state = i; state < MathMin(Buffer[tr].Total - 1 - NBarInPattern, i + HistoryBars * 2); state++) { //--- History data State.AssignArray(Buffer[tr].States[state].state);
ループの本文では、初期データバッファに、過去の値動きデータと、訓練セットから分析した指標を入れます。口座状況と未決済ポジションに関するデータを補足します。
//--- Account description float PrevBalance = (state == 0 ? Buffer[tr].States[state].account[0] : Buffer[tr].States[state - 1].account[0]); float PrevEquity = (state == 0 ? Buffer[tr].States[state].account[1] : Buffer[tr].States[state - 1].account[1]); State.Add((Buffer[tr].States[state].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[state].account[1] / PrevBalance); State.Add((Buffer[tr].States[state].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[state].account[2]); State.Add(Buffer[tr].States[state].account[3]); State.Add(Buffer[tr].States[state].account[4] / PrevBalance); State.Add(Buffer[tr].States[state].account[5] / PrevBalance); State.Add(Buffer[tr].States[state].account[6] / PrevBalance);
タイムスタンプのハーモニクスとエージェントの最後の行動のベクトルを追加します。
//--- Time label double x = (double)Buffer[tr].States[state].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Buffer[tr].States[state].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(2.0 * M_PI * x)); //--- Prev action if(state > 0) State.AddArray(Buffer[tr].States[state - 1].action); else State.AddArray(vector<float>::Zeros(NActions));
選好モデルとは異なり、エージェントは文脈を必要とします。経験再生バッファからそれを取ります。
//--- Scheduler
State.AddArray(Buffer[tr].States[state].scheduler);
収集されたデータは、エージェントモデルのフィードフォワードパスには十分です。そこで、関連するメソッドを呼び出します。
//--- Feed Forward if(!Agent.feedForward(GetPointer(State), 1, false, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
前述のように、潜在的な文脈と実行される行動の間に依存関係を構築するために、actorの方策を訓練します。これはDTの目標と完全に一致しています。DTでは、目標と行動の間に依存関係を構築しました。潜在的な文脈は、目標のある種の埋め込みと考えることができます。形は変わっても本質は同じです。その結果、学習プロセスも似てきます。予測と実際の行動との誤差を最小化します。
//--- Policy study Result.AssignArray(Buffer[tr].States[state].action); if(!Agent.backProp(Result, (CBufferFloat*)NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); StopFlag = true; break; }
次にやるべきことは、学習プロセスの進捗状況をユーザーに知らせ、次の反復に移ることです。
//--- if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Agent", iter * 100.0 / (double)(Iterations), Agent.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } } }
訓練が終了したら、カルテのコメント欄を消去します。モデルの訓練結果をログに出力し、EAの完了を開始します。
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Agent", Agent.getRecentAverageError()); ExpertRemove(); //--- }
最後に、この記事で使用されているプログラムのアルゴリズムを紹介します。全コードは添付ファイルにあります。添付ファイルには、学習したモデルをテストするためのEA「...\OPPO\Test.mq5」のコードも含まれており、EAの環境との相互作用のアルゴリズムをほぼ完全に繰り返しています。エージェントの行動にノイズを加えることだけを除外しました。これにより、無作為性の要因を排除し、学習された方策を完全に評価することができます。
3.テスト
オフライン選好誘導方策最適化(OPPO)アルゴリズムを実装するために多くの作業をおこなってきました。繰り返しになりますが、この作品は、方法の作者によって記述された元のアルゴリズムに欠けているいくつかの操作を追加した実装の個人的なビジョンを提示しているという事実に、注意を喚起します。私は、OPPO法の作者の功績や仕事を自分の手柄にしようとは決して思っていません。その一方で、元のアイデアの欠陥や誤解を彼らのせいにはしたくありません。
いつものように、モデルはEURUSDの履歴データ、2023年の最初の7ヶ月のH1時間枠で訓練されます。訓練済みモデルは、2023年8月からの履歴データを使用してテストされました。
この作業では軌跡の保存構造体が変更されたため、以前の作業で収集された軌跡例を使用することはできません。そのため、まったく新しい軌跡が訓練データセットに収集されました。
ここで、無作為な重みで初期化された新しいモデルから500の軌跡を集めるのに、私のノートパソコンで3日間かかりっきりになったことを認めなければなりません。これは予想外のことでした。
訓練データセットを収集した後、モデルの並列訓練を開始しました。これは、訓練プロセスを2つの独立したEAに分割することで可能になりました。
いつものように、モデルのアップデートを考慮に入れて訓練データセットを繰り返し選択しなければ、学習プロセスは完了しませんでした。おわかりのように、学習プロセスは非常に着実で、指示されたものです。訓練データセットにパスがない場合でも、このメソッドは方策の改善が可能であることを発見します。
私の個人的な観察によれば、エージェントの行動に対して有益な戦略を構築するためには、訓練データセットがポジティブなパスを持っていなければなりません。このようなパスの存在は、追加の軌道を収集しながら環境を探索することによってのみ達成されます。また、前回の記事で見たように、EAの軌跡やコピーシグナルのトランザクションを使用することも可能です。また、収益性の高いパスを追加することで、モデルの訓練プロセスが大幅にスピードアップします。
訓練の過程で、訓練サンプルとテストサンプルの両方で利益を生み出すことができるモデルが得られました。テスト時間間隔におけるモデルパフォーマンスの結果を以下に示します。


スクリーンショットをご覧いただければおわかりのように、残高は急激な上昇と下降を繰り返しています。残高グラフは安定しているとは言い難いですが、全般的な上昇傾向は保たれています。テスト月の結果に基づいて、利益を上げました。
テスト期間中、EAは合計180回の取引をおこないました。そのうち49%近くが黒字決算でした。利益取引と負け取引のパリティと呼ぶこともできますが、平均的な黒字取引が平均的な赤字取引を30%上回っているため、全体的な収支は増加しています。このテスト期間におけるプロフィットファクターは1.25でした。
結論
今回は、もう1つの興味深いモデル訓練法を紹介しました。オフライン選好誘導方策最適化(OPPO)です。この方法の主な特徴は、モデルの訓練プロセスから報酬関数を排除することです。これにより、その使用範囲は大幅に拡大します。というのも、ある学習目標を立て、それを明示することは、時として非常に困難だからからです。個々の行動が最終的な結果に与える影響を評価することは、特に環境からの反応がまばらな場合、さらに難しくなります。あるいは、そのような返答が多少遅れて届いた場合です。その代わりに、提示されたOPPO法は、軌跡全体を単一の方策から生じる単一の全体として評価します。したがって、エージェントの行動ではなく、特定の環境における方策を評価します。そして、この方策を受け継ぐか、あるいは逆に、より最適な解決策を見つけるために反対方向に進むかを決断します。
本稿の実践編では、元のメソッドから若干の逸脱はあるものの、MQL5を使用してOPPO法を実装しました。それにもかかわらず、訓練データセットを超えた過去の訓練期間とテスト期間の両方で利益を生み出すことができる方策を訓練することができました。
モデルの訓練とテストの結果は、提案されたアプローチを実際の取引戦略の構築に使用できる可能性を示しています。
しかし、この記事で紹介されているプログラムはすべて、技術のデモンストレーションを目的としたものであり、実際の金融取引に使用できるものではないことを、もう一度お断りしておきたいとおもいます。
参照文献
記事で使用されているプログラム
| # | 名前 | 種類 | 詳細 |
|---|---|---|---|
| 1 | Research.mq5 | EA | コレクションEAの例 |
| 2 | StudyAgent.mq5 | EA | エージェント訓練EA |
| 3 | StudyScheduler.mq5 | EA | 選好モデル訓練EA |
| 4 | Test.mq5 | EA | モデルをテストするEA |
| 5 | Trajectory.mqh | クラスライブラリ | システム状態記述の構造体 |
| 6 | NeuroNet.mqh | クラスライブラリ | ニューラルネットワークを作成するためのクラスのライブラリ |
| 7 | NeuroNet.cl | コードベース | OpenCLプログラムコードライブラリ |
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/13912
 RestAPIを統合したMQL5強化学習エージェントの開発(第2回):三目並べゲームREST APIとのHTTPインタラクションのためのMQL5関数
RestAPIを統合したMQL5強化学習エージェントの開発(第2回):三目並べゲームREST APIとのHTTPインタラクションのためのMQL5関数
- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索