
Нейросети — это просто (Часть 89): Трансформер частотного разложения сигнала (FEDformer)

Введение
Долгосрочное прогнозирование временных рядов является давней проблемой в решении различных прикладных задач. Модели на основе Transformer показывают многообещающие результаты. Однако высокая вычислительная сложность и требования к памяти затрудняют применение Transformer для моделирования длинных последовательностей. Это дало толчок многочисленным исследованиям, которые были посвящены снижению вычислительных затрат Transformer.
Несмотря на прогресс, достигнутый методами прогнозирования временных рядов на основе Transformer, в некоторых случаях они не могут уловить общие характеристики распределения временного ряда. Попытка решения данной проблемы была предпринята авторами статьи "FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting". Они сравнивают реальные данные временного ряда с его прогнозными значениями, полученными от ванильного Transformer. Скриншот из авторской статьи представлен ниже.
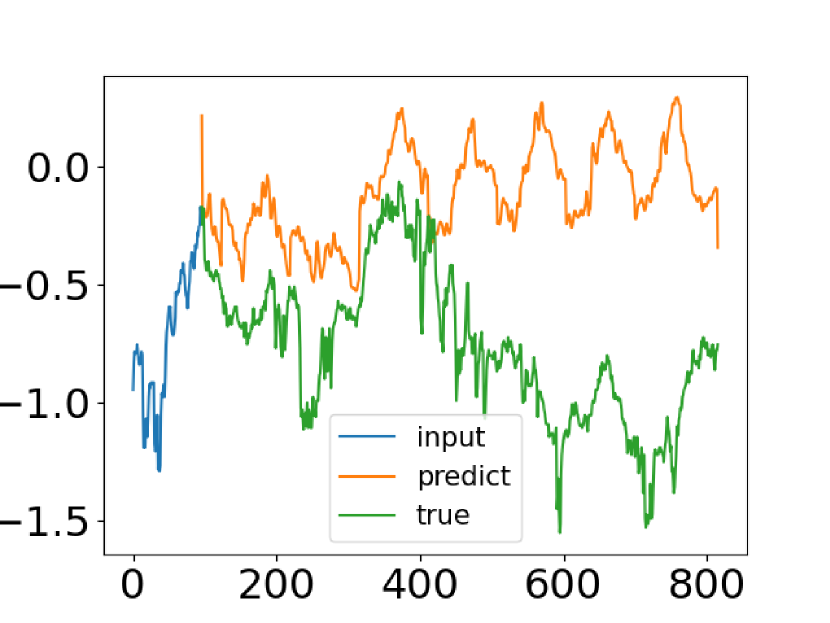
Легко заметить, что распределение прогнозного временного ряда сильно отличается от истинного. Несоответствие между ожидаемыми и прогнозируемыми значениями можно объяснить точечным вниманием в Transformer. Поскольку прогноз для каждого временного шага делается индивидуально и независимо, вполне вероятно, что модель не может сохранить глобальные свойства и статистику временных рядов в целом. Для решения этой проблемы авторы статьи эксплуатируют две идеи.
Первая заключается в использовании подхода декомпозиции сезонных тенденций, который широко используется в анализе временных рядов. Авторы статьи представляют специальную архитектуру модели, которая эффективно приближает распределение прогнозов к истинному.
Вторая идея — внедрить анализ Фурье в алгоритм Transformer. Вместо применения Transformer к временному измерению последовательности предлагается анализировать её частотные характеристики, что помогает Transformer лучше улавливать глобальные свойства временных рядов.
Объединение предложенных идей реализовано в модели Frequency Enhanced Decomposition Transformer или сокращенно FEDformer.
Один из важнейших вопросов, связанных с FEDformer, заключается в том, какое подмножество частотных компонентов следует использовать в анализе Фурье для представления временных рядов. В подобных анализах чаще всего сохраняют низкочастотные компоненты и отбрасывают высокочастотную составляющую. Однако это может быть неприемлемо для прогнозирования временных рядов, поскольку некоторые изменения тенденций во временных рядах связаны с важными событиями. Эта часть информации может быть потеряна при простом удалении всех высокочастотных компонентов сигнала. Авторы метода принимают тот факт, что временные ряды обычно имеют неизвестные разреженные представления на основе базиса Фурье. Проведенный ими теоретический анализ показал, что случайно выбранное подмножество частотных компонентов, включая как низкие, так и высокие, дает лучшее представление временных рядов. Данное наблюдение было подтверждено обширными эмпирическими исследованиями.
Помимо повышения эффективности для долгосрочного прогнозирования, сочетание Transformer с частотным анализом позволяет снизить вычислительные затраты с квадратичной до линейной сложности.
Авторы статьи резюмируют свои достижения следующим образом:
1. Предложена архитектура Transformer декомпозиции сигнала с улучшенной частотной характеристикой и использованием экспертов для декомпозиции сезонных тенденций, что повышает способность улавливать глобальные свойства временных рядов.
2. Предложены расширенные блоки Фурье и улучшенные вейвлет-блоки в архитектуре Transformer, которые позволяют фиксировать важные структуры во временных рядах посредством изучения частотных характеристик. Они служат заменой блоков как внутреннего, так и перекрестного внимания.
3. Путем случайного выбора фиксированного числа компонентов Фурье, предложенная модель достигает линейной вычислительной сложности и затрат памяти. Эффективность данного метода отбора проверена как теоретически, так и эмпирически.
4. Проведенные эксперименты на шести базовых наборах данных в различных областях показывают, что предложенная модель повышает эффективность современных методов на 14,8% и 22,6% для многомерного и одномерного прогнозирования соответственно.
1. Алгоритм FEDformer
Сразу надо сказать, что авторы метода представили 2 варианта модели FEDformer. Одна использует базис Фурье для анализа частотных характеристик временного ряда. А другая построена на использовании вейвлетов, которые позволяют совместить анализ как в разрезе времени, так и в области частотных характеристик.
Прогнозирование долгосрочных временных рядов представляет собой проблему sequence-to-sequence. Обозначим размер последовательности исходных данных как I и прогнозируемой последовательность как O. Пусть D представляет размер вектора описания одного состояния ряда. Тогда на вход Энкодера мы подаем тензор размером I*D, а Декодер получает на вход матрицу (I/2+O)*D.
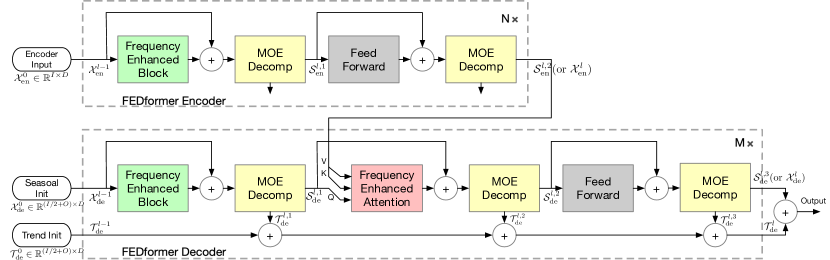
Как уже было сказано выше, авторы метода совершенствуют архитектуру Transformer, внедряя в неё анализ разложения и распределения сезонных тенденций. Обновленный Transformer представляет собой архитектуру глубокой декомпозиции и включает блок анализа частотных характеристик (FEB), блок внимание частотных характеристик (FEA), блоки декомпозиции Mixture Of Experts (MOEDecomp).
Энкодер FEDformer использует многоуровневую структуру, аналогично Энкодеру Transformer. Отдельный его блок можно представить следующими математическими выражениями:
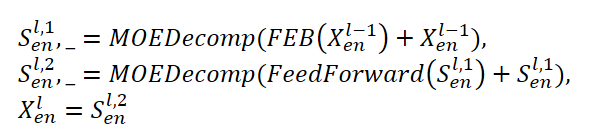
Здесь Sen представляет собой сезонную составляющую, выделяемую из исходных данных в блоке разложения MOEDecomp.
Для модуля FEB авторы метода предлагают 2 разные версии (FEB-f и FEB-w), которые реализованы посредством механизма дискретного преобразования Фурье (DFT) и дискретного вейвлет-преобразования (DWT) соответственно. В данной реализации они заменяют блок Self-Attention.
Декодер также использует многоуровневую структуру, как и Энкодер. Но архитектура его составных блоков гораздо шире и описывается формулами:
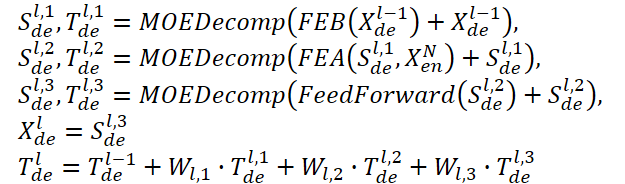
Sde и Tde представляют сезонную и трендовую составляющую после блока разложения MOEDecomp. А Wl выполняет роль проекции для извлеченного тренда. Подобно FEB, FEA имеет две разные версии (FEA-f и FEA-w), которые реализуются через проекцию DFT и DWT соответственно. FEA выполнен с дизайном внимания и заменяет блок перекрестного внимания ванильного Transformer.
Окончательный прогноз представляет собой сумму двух уточненных разложенных компонентов. Сезонная составляющая проецируется с помощью матрицы WS до целевого измерения.
![]()
Предлагаемая модель FEDformer использует дискретное преобразование Фурье (DFT), которое позволяет разложить анализируемую последовательность на составляющие её гармоники (синусоидальные составляющие). Для повышения эффективности модели, авторы FEDformer используют быстрое преобразования Фурье (FFT).
Как было сказано ранее, в методе используется случайное подмножество базиса Фурье, а масштаб подмножества ограничен скаляром. Выбор индекса режима перед операциями DFT и обратного DFT (IDFT) позволяет дополнительно решулировать сложность вычислений.
Блок с расширенным частотным диапазоном и преобразованием Фурье (FEB-f) используется как в Энкодере, так и в Декодере. Исходные данные блока FEB-f сначала линейно проецируются, а затем преобразуются из временной области в частотные характеристики. Из полученных частотных характеристик случайным образом сэмплируется М гармоник. После чего, отобранные частотные характеристики умножаются на матрицу параметризированного ядра, которое инициализируется случайными параметрами и корректируется в процессе обучения модели. Результат дополняется нулями до размерности полных частотных характеристик перед выполнением обратного преобразования Фурье, которое возвращает анализируемую последовательность во временную область. Авторская визуализация блока FEB-f представлена ниже.
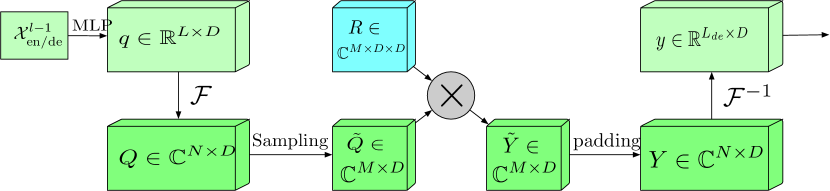
В блоке внимания частотных характеристик с использованием дискретного преобразования Фурье (FEA-f) используется канонический подход Transformer с небольшим дополнением. Исходные данные преобразуются в представления Query, Key и Value. При перекрестном внимании Query поступают от Декодера, а Key и Value взяты из Энкодера. Однако в FEA-f мы преобразуем Query, Key и Value с помощью преобразования Фурье и выполняем аналогичный каноническому механизм внимания в области частотных характеристик. Здесь, как и в блоке FEB-f для анализа мы случайным образом сэмплируем M гармоник. Результат операции внимания дополняется нулями до размера исходной последовательности, и выполняется обратное преобразование Фурье. Структура FEA-f показана ниже в авторской визуализации.
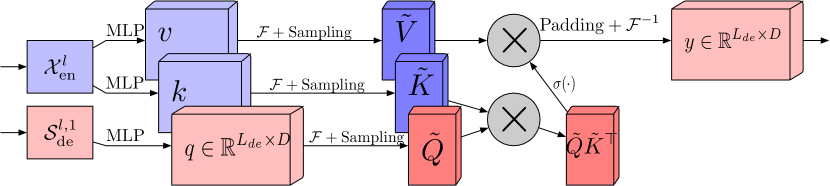
В то время как преобразование Фурье создает представление сигнала в виде частотных характеристик, вейвлет-преобразование позволяет представить сигнал как в частотной, так и во временной области, обеспечивая эффективный доступ к локализованной информации об исходном сигнале. Мультивейвлет-преобразование объединяет преимущества ортогональных полиномов, а также вейвлетов. Мультивейвлетное представление сигнала может быть получено путем тензорного произведения мультимасштабного и мультивейвлетного базиса. Обратите внимание, что базисы в различных масштабах связаны тензорным произведением. Авторы метода FEDformer адаптируют нестандартное вейвлет-представление, чтобы уменьшить сложность модели.
Архитектура FEB-w отличается от FEB-f рекурсивным механизмом: исходные данные рекурсивно разлагаются на 3 части, и каждая из них обрабатывается индивидуально. Для вейвлет-разложения авторы метода предлагают фиксированную матрицу разложения базиса вейвлетов Лежандра. Три модуля FEB-f используются для обработки результирующей высокочастотной части, низкочастотной части и оставшейся части вейвлет-разложения соответственно. На каждой итерации создается обработанный высокочастотный тензор, обработанный тензор низкочастотной частоты и необработанный низкочастотный тензор. Это нисходящий подход, и на этапе разложения выполняется прореживание сигнала в 1/2 раза. Три набора блоков FEB-f используются совместно во время разных итераций декомпозиции. Касательно вейвлет-реконструкции авторы метода также рекурсивно создают выходной тензор.
FEA-w содержит этап разложения и этап реконструкции, аналогично FEB-w. Здесь авторы FEDformer оставляют этап реконструкции без изменений. Единственное отличие заключается в стадии разложения. Тут используется та же матрица для разложения сигнала на сущности Query, Key и Value. Как показано выше, блок FEB-w содержит три блока FEB-f для обработки сигнала. Можно рассматривать FEB-f как замену механизму Self-Attention. Авторы метода используют простой способ создания перекрестного внимания с усилением частоты с помощью вейвлет-разложения, заменяя каждый FEB-f модулем FEA-f. Кроме того, добавлен еще один модуль FEA-f для обработки наиболее грубых остатков.
Из-за часто наблюдаемого сложного периодического паттерна в сочетании с компонентом тренда, в реальных данных извлечение тренда может быть затруднено при объединении средних значений с фиксированным окном. Чтобы преодолеть такую проблему, был разработан блок декомпозиции Mixture Of Experts (MOEDecomp). Он содержит набор фильтров из средних разных размеров, для извлечения нескольких компонентов тренда из исходного сигнала, и набор зависящих от данных весов, для их объединения в результирующий тренд.
Полный алгоритм метода FEDformer представлен в авторской визуализации ниже.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов предложенного метода FEDformer, сразу надо сказать, что наша реализация будет далека от оригинальной. Мы воспользуемся предложенными подходами, но не будем реализовывать полностью предложенный алгоритм. И на то есть несколько моих личных убеждений.
Для начала нам нужно определиться, какую базу мы будем использовать DFT или DWT. Вопрос довольно сложный и неоднозначный, над которым можно долго "ломать голову". Но мы поступим гораздо проще. Обратимся к результатам тестирования метода, которые представлены в авторской статье.

Обратите внимание на колонку "Exchange". Мы не будем вдаваться в подробности, на каких именно данных проводилось тестирование модели, но наблюдается однозначное превосходство модели с использованием DWT. Вероятно, что из-за отсутствия ярко выраженной периодичности в исходных данных, DFT не способен определить момент изменения тенденций. Ведь он игнорирует временную составляющую исходных данных. В то же время, DWT, который анализирует сигнал в обоих измерениях, способен обеспечить более точные прогнозные данные. Думаю, в такой ситуации наш выбор в пользу DWT очевиден.
2.1 Реализация DWT
Определившись с базисом реализации, мы первым делом реализуем возможность вейвлет-разложения в нашей библиотеке. Для этого мы создадим новый объект CNeuronLegendreWavelets.
Давайте немного подумаем об архитектуре создаваемого объекта. Как уже было сказано выше, для вейвлет-разложения авторы метода предлагают использовать фиксированную матрицу разложения базиса вейвлетов Лежандра. Иными словами, для разложения сигнала нам достаточно умножить вектор сигнала на матрицу базиса вейвлетов.
В нашей последовательности исходных данных нам предстоит анализировать несколько параллельных сигналов мультимодального временного ряда. При этом, для каждого унитарного временного ряда мы будем использовать одну и ту же базисную матрицу.
Данный процесс очень похож на свертку с несколькими фильтрами. Только в данном случае роль матрицы фильтров выполняет базисная матрица вейвлетов. Следовательно, вполне логично будет создать новый объект наследником нашего сверточного слоя. При продуманном подходе мы можем максимально полно использовать унаследованные методы, переопределив буквально пару из них.
class CNeuronLegendreWavelets : public CNeuronConvOCL { protected: virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) { return true; } public: CNeuronLegendreWavelets(void) {}; ~CNeuronLegendreWavelets(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronLegendreWavelets; } };
В представленной выше структуре нового класса CNeuronLegendreWavelets можно увидеть всего 3 переопределяемых метода, один из которых идентификатор класса Type, который возвращает предопределенную константу.
Второй момент, который уже упоминался выше, — мы используем фиксированную матрицу базисных вейвлетов. Следовательно, в нашем классе не будет обучаемых параметров, и метод updateInputWeights мы переопределяем "заглушкой".
По сути, нам предстоит поработать лишь с методом инициализации объекта класса Init. В новом методе мы не объявляем каких-либо локальных переменных или объектов. И в методе инициализации нам предстоит лишь заполнить матрицу базисных вейвлетов.
Авторы метода предлагают в качестве вейвлетов использовать полиномы Лежандра. Я выбрал 9 таких полиномов, визуализация которых представлена ниже.

Как можно заметить, представленные на графике полиномы позволяют описать довольно широкий спектр частот.
Так же следует обратить внимание, что диапазон допустимых значений представленных полиномов [0, 1]. Это вполне удобно. Мы определяем длину окна анализируемой последовательности за 1. И делим диапазон на количество элементов в последовательности. Тем самым мы определяем временной шаг между двумя соседними элементами последовательности, которую мы изначально формируем с фиксированным шагом. И здесь не имеет значения тайм-фрейм собираемых исходных данных. Мы анализируем частотные характеристики сигнала в рамках видимого окна исходной последовательности.
И здесь перед нами становится проблема определения количества элементов в последовательности на стадии проектирования модели. Перед созданием базисной матрицы нам необходимо указать её размеры. На данном этапе у нас есть только количество фильтров, которые мы отобрали. Но размер окна анализируемой последовательности нам будет известен только при инициализации модели. На самом деле, у нас есть 2 варианта выхода из сложившейся ситуации:
- Определить жесткие размеры матрицы базисных вейвлетов и заполнить сразу её значения. А использование обучаемого сверточного слоя перед матрицей позволит нам работать с любым размером исходной последовательности.
- Создание универсального алгоритма заполнения матрицы базисных вейвлетов на стадии инициализации модели для любого размера исходных данных.
Первый вариант нам позволяет заполнить матрицу фиксированными значениями любым доступным способом. Мы можем даже найти в интернете коэффициенты интересующих нас базовых вейвлетов. Но как нам определить эту "золотую середину" между точностью и производительностью? К тому же требования к точности прогнозов могут сильно меняться в различных задачах.
И здесь, на мой взгляд, более оптимальным выглядит второй вариант. Для его реализации мы создадим в виде макроподстановок формулы отобранных полиномов. Вот лишь некоторые (полный список доступен во вложении):
#define Legendre4(x) (70*pow(x,4) - 140*pow(x,3) + 90*pow(x,2) - 20*x + 1) #define Legendre6(x) (924*pow(x,6) - 2772*pow(x,5) + 3150*pow(x,4) - 1680*pow(x,3) + \ 420*pow(x,2) - 42*x + 1) #define Legendre8(x) (12870*pow(x,8) - 51480*pow(x,7) + 84084*pow(x,6) - 72072*pow(x,5) + \ 34650*pow(x,4) - 9240*pow(x,3) + 1260*pow(x,2) - 72*x + 1)
С помощью данных макроподстановок мы можем получить значение полинома для любого дискретного значения. И после завершения подготовительной работы, мы можем перейти непосредственно к описанию алгоритма инициализации объекта нашего нового класса CNeuronLegendreWavelets::Init.
В параметрах методу мы передаем ключевые параметры архитектуры объекта:
bool CNeuronLegendreWavelets::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint units_count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, window, step, 9, units_count, optimization_type, batch)) return false;
И в теле метода мы сначала вызываем одноименный метод родительского класса.
Обратите внимание, что в параметрах метода инициализации нового класса мы получаем только размер окна анализируемой последовательности и количество элементов в последовательности. А при вызове аналогичного метода родительского класса, нам необходимо добавить шаг окна и количество фильтров. С количеством фильтров мы определились ранее – их 9. А шаг анализируемого окна мы указываем равным анализируемому окну.
После успешного выполнения метода инициализации родительского класса, наша матрица параметров свертки заполнена случайными значениями. Нам же необходимо её заполнить базисными параметрами вейвлета. Для этого мы сначала заполняем матрицу весов нулевыми значениями. Это очень важный момент, так как нам необходимо обнулить заданные параметры bias-смещения.
WeightsConv.BufferInit(WeightsConv.Total(), 0);
А затем в цикле заполним матрицу значения базисных вейвлет:
for(uint i = 0; i < iWindow; i++) { uint shift = i; float k = float(i) / iWindow; if(!WeightsConv.Update(shift, Legendre4(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre6(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre8(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre10(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre12(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre16(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre18(k))) return false; shift += iWindow + 1; if(!WeightsConv.Update(shift, Legendre20(k))) return false; }
Заполненную матрицу перенесем в память контекста OpenCL:
if(!!OpenCL) if(!WeightsConv.BufferWrite()) return false; //--- return true; }
И завершаем работу метода.
Здесь надо сказать, что в такой реализации весь остальной функционал, необходимый для корректной работы объекта, мы унаследовали от родительского класса. Следовательно, мы завершаем работу над этим классом и идем далее.
2.2 Блок FED-w
Следующим этапом нашей работы мы, так сказать, подымаемся на ступеньку выше и создаем свое видение блока FED-w, функционал которого реализован в классе CNeuronFEDW. Структура данного класса представлена ниже.
class CNeuronFEDW : public CNeuronBaseOCL { protected: //--- uint iWindow; uint iCount; //--- CNeuronLegendreWavelets cWavlets; CNeuronBatchNormOCL cNorm; CNeuronSoftMaxOCL cSoftMax; CNeuronConvOCL cFF[2]; CNeuronBaseOCL cReconstruct; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); //--- virtual bool Reconsruct(CBufferFloat* inputs, CBufferFloat *outputs); public: CNeuronFEDW(void) {}; ~CNeuronFEDW(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint count, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual int Type(void) const { return defNeuronFEDW; } virtual void SetOpenCL(COpenCLMy *obj); //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); };
Можно заметить, что данный класс имеете боле сложную архитектуру в сравнении с предыдущим. В нем объявляются 2 локальные переменные для хранения ключевых параметров. И объявляется целый ряд внутренних объектов, с назначением которых мы познакомимся в процессе реализации. Все объекты объявлены статично, что позволяет нам оставить "пустыми" конструктор и деструктор класса.
Непосредственно инициализация всех вложенных объектов, как всегда, осуществляется в методе CNeuronFEDW::Init. В параметрах методу передаются основные параметры архитектуры объекта. Среди них можно выделить основополагающие параметры размера видимого окна данных (window) и количества анализируемых унитарных последовательностей (count).
bool CNeuronFEDW::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint count, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * count, optimization_type, batch)) return false;
В теле метода мы сначала вызываем одноименный метод родительского класса, что, можно сказать, является правилом в реализации наших объектов. После чего, сохраним в локальные переменные параметры архитектуры инициализируемого объекта:
iWindow = window; iCount = count;
И затем инициализируем внутренние объекты в порядке их последующего использования.
Вначале мы планируем извлекать частотные характеристики из получаемых исходных данных. Для этого мы используем экземпляр выше созданного класса CNeuronLegendreWavelets:
if(!cWavlets.Init(0, 0, OpenCL, iWindow, iWindow, iCount, optimization, iBatch)) return false; cWavlets.SetActivationFunction(None);
Должен сказать, что создаваемый нами блок FED-w сильно упрощен, по сравнению с предложенным авторами метода. Я отказался от использования блоков DFT. Мне кажется, что анализ частотных характеристик в отрыве от временной составляющей может сыграть против нас и снизит качество прогнозов. Это, как минимум, ставит под сомнение целесообразность использования DFT. Но это мое личное мнение, и оно может оказаться ошибочным.
К тому же, исключение довольно трудоемкого процесса FFT значительно снизит затраты вычислительных ресурсов в процессе обучения и эксплуатации модели.
С учетом вышесказанного, я решил пойти по пути повышения производительности модели, принимая риски возможного ухудшения качества прогнозирования.
Полученные после вейвлет-разложения данные я сначала нормализую с помощью слоя пакетной нормализации:
if(!cNorm.Init(0, 1, OpenCL, 9 * iCount, 1000,optimization)) return false; cNorm.SetActivationFunction(None);
А затем оценю долю каждого из используемых фильтров. Для этого переведу полученные данные в подпространство вероятностей с помощью функции SoftMax.
if(!cSoftMax.Init(0, 1, OpenCL, 9 * iCount, optimization, iBatch)) return false; cSoftMax.SetHeads(iCount); cSoftMax.SetActivationFunction(None);
Обратите внимание, что мы оцениваем каждый унитарный канал отдельно.
После чего мы восстановим из вероятного представления исходный временной ряд путем обратной свертки с нашей матрицей базисов вейвлетов. Результат будем сохранять в создаваемом вложенном базовом слое:
if(!cReconstruct.Init(0, 2, OpenCL, iWindow, optimization, iBatch)) return false; cReconstruct.SetActivationFunction(None);
Можно заметить, что указанные выше операции совершают некий замкнутый круг: временной ряд → вейвлет разложение → нормализация → вероятностное представление → временной ряд. Но на выходе мы получаем довольно сглаженное представление исходного временного ряда, который мы пропустили через своеобразный цифровой фильтр. В результате мы получили довольно эффективную фильтрацию данных с минимумом обучаемых параметров, которые присутствуют только в слое пакетной нормализации. И данный блок заменяет Self-Attention в нашей реализации.
Здесь важно отметить, что по существу, мы заменяем обучаемые параметры модели на заранее определенные вейвлеты. Это делает нашу модель более понятной, в отличие от "черного ящика" обучаемых параметров, но менее гибкой. И накладывает дополнительную нагрузку на архитектора модели в части поиска оптимальных вейвлетов для решения поставленной задачи. Я не зря вынес полиномы вейвлетов в отдельный блок макроподстановок. Такой подход позволит нам легко экспериментировать с различными вейвлетами на пути поиска оптимальных.
Но вернемся к нашему методу инициализации класса. И за блоком цифрового фильтра идет привычный для архитектуры Transformer блок FeedForward. Здесь мы используем без изменений 2 слойный MLP с LReLU между слоями. Как и ранее, для реализации независимой обработки каналов мы используем объекты сверточного слоя:
if(!cFF[0].Init(0, 3, OpenCL, iWindow, iWindow, 4 * iWindow, iCount, optimization, iBatch)) return false; cFF[0].SetActivationFunction(LReLU); if(!cFF[1].Init(0, 4, OpenCL, 4 * iWindow, 4 * iWindow, iWindow, iCount, optimization, iBatch)) return false; SetActivationFunction(None);
В завершении метода инициализации мы организовываем подмену буфера градиента ошибок с целью минимизации излишних операций копирования данных:
if(Gradient != cFF[1].getGradient()) SetGradient(cFF[1].getGradient()); //--- return true; }
После завершения работы по инициализации нашего объекта мы переходим к реализации прямого прохода предложенной модели. Из представленного выше описания планируемого процесса стоит выделить обратную свертку полученных вероятностей во временной ряд.
"Обратная свертка" звучит как нечто новое в нашей реализации. Тем не менее, мы уже давно реализовали этот процесс. Именно с помощью обратной свертки мы распределяем градиент ошибки в сверточном слое. Но теперь нам необходима реализация указанного процесса в рамках прямого прохода.
Сложность состоит в том, что все методы наших классов работают с фиксированным списком буферов данных. Это позволяет нам не задумываться об используемых буферах данных в процессе создания моделей. Достаточно дать указатель на объект, а все буфера данных уже прописаны в методе. "Обратная сторона медали" заключается в том, что мы не можем использовать метод обратного прохода для реализации алгоритма в рамках прямого прохода. Но мы ведь можем создать новый метод, в котором будем использовать ранее созданный кернел с передачей ему правильных буферов и параметров.
Так и поступим. Создадим метод CNeuronFEDW::Reconsruct, в параметрах которого мы передадим указатели на буферы полученных вероятностей и восстанавливаемой последовательности:
bool CNeuronFEDW::Reconsruct(CBufferFloat *sequence, CBufferFloat *probability) { uint global_work_offset[1] = {0}; uint global_work_size[1]; global_work_size[0] = sequence.Total();
В теле метода мы определим пространство задач и передадим все необходимые параметры в кернел:
if(!OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv, def_k_chgc_matrix_w, cWavlets.GetWeightsConv().GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv, def_k_chgc_matrix_g, probability.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv, def_k_chgc_matrix_o, probability.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_CalcHiddenGradientConv, def_k_chgc_matrix_ig, sequence.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CalcHiddenGradientConv, def_k_chgc_outputs, probability.Total())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CalcHiddenGradientConv, def_k_chgc_step, (int)iWindow)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CalcHiddenGradientConv, def_k_chgc_window_in, (int)iWindow)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CalcHiddenGradientConv, def_k_chgc_window_out, (int)9)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CalcHiddenGradientConv, def_k_chgc_activation, (int)None)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_CalcHiddenGradientConv, def_k_chgc_shift_out, (int)0)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
После чего осуществим постановку кернела в очередь выполнения:
if(!OpenCL.Execute(def_k_CalcHiddenGradientConv, 1, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
На этом подготовительная работа завершена, и мы можем приступить к непосредственному описанию метода прямого прохода нашего класса CNeuronFEDW::feedForward. Как всегда, в параметрах метода прямого прохода мы передаем указатель на объект предыдущего слоя нашей модели, который содержит необходимые исходные данные:
bool CNeuronFEDW::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!cWavlets.FeedForward(NeuronOCL.AsObject())) return false;
В теле метода мы сначала раскладываем полученную последовательность на составляющие ее частотные характеристики. Для этого мы вызываем метод прямого прохода вложенного объекта cWavlets.
Далее, согласно предложенному алгоритму, мы нормализуем полученные данные и переводим их в вероятностное подпространство:
if(!cNorm.FeedForward(cWavlets.AsObject())) return false; if(!cSoftMax.FeedForward(cNorm.AsObject())) return false;
После чего восстанавливаем временную последовательность:
if(!Reconsruct(cReconstruct.getOutput(), cSoftMax.getOutput())) return false;
Дальнейший алгоритм аналогичен классическому Transformer. Мы складываем и нормализуем исходную и восстановленную временные последовательности:
if(!SumAndNormilize(NeuronOCL.getOutput(), cReconstruct.getOutput(), cReconstruct.getOutput(), iWindow, true, 0, 0, 0, 1)) return false;
Проводим данные через блок FeedForward:
if(!cFF[0].FeedForward(cReconstruct.AsObject())) return false; if(!cFF[1].FeedForward(cFF[0].AsObject())) return false;
После чего повторно суммируем и нормализуем временные последовательности от двух потоков данных:
if(!SumAndNormilize(cFF[1].getOutput(), cReconstruct.getOutput(), getOutput(), iWindow, true, 0, 0, 0, 1)) return false; //--- return true; }
Прямой проход реализован, и мы переходим к построению методов обратного прохода. Вначале мы создадим метод распределения градиента ошибки CNeuronFEDW::calcInputGradients:
bool CNeuronFEDW::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
В теле метода мы сначала проверяем корректность полученного в параметрах указателя на объект предыдущего слоя. Ведь в случае его отсутствия, теряется всякий смысл проведения операций метода.
Как вы помните, в методе инициализации класса мы осуществили подмену буферов данных градиента ошибки. И теперь мы можем сразу перейти к работе с блоком FeedForward.
if(!cFF[0].calcHiddenGradients(cFF[1].AsObject())) return false; if(!cReconstruct.calcHiddenGradients(cFF[0].AsObject())) return false;
Аналогично потоку данных при прямом проходе, в обратном проходе мы так же распределяем градиент ошибки по двум параллельным потокам данных. И на данном этапе мы суммируем градиент ошибки от обоих потоков.
if(!SumAndNormilize(Gradient, cReconstruct.getGradient(), cReconstruct.getGradient(), iWindow, false)) return false;
Далее нам предстоит провести градиент ошибки через операцию обратной свертки. Очевидно, что это обычная операция свертки. Но опять незадача. Метод прямого прохода сверточного слоя не работает с буферами градиентов ошибки. На это раз мы пойдем на небольшую хитрость — подменим на время буфера результатов работы слоев на буфера их градиентов. При этом предусмотрительно сначала сохраним указатели на подменяемые буфера данных:
CBufferFloat *temp_r = cReconstruct.getOutput(); if(!cReconstruct.SetOutput(cReconstruct.getGradient(), false)) return false; CBufferFloat *temp_w = cWavlets.getOutput(); if(!cWavlets.SetOutput(cSoftMax.getGradient(), false)) return false;
Осуществим прямой проход сверточного слоя:
if(!cWavlets.FeedForward(cReconstruct.AsObject())) return false;
И вернем буфера данных в исходное положение:
if(!cWavlets.SetOutput(temp_w, false)) return false; if(!cReconstruct.SetOutput(temp_r, false)) return false;
Далее мы опускаем градиент ошибки до предыдущего слоя:
if(!cNorm.calcHiddenGradients(cSoftMax.AsObject())) return false; if(!cWavlets.calcHiddenGradients(cNorm.AsObject())) return false; if(!NeuronOCL.calcHiddenGradients(cWavlets.AsObject())) return false;
И суммируем градиент ошибки от двух потоков данных:
if(!SumAndNormilize(NeuronOCL.getGradient(), cReconstruct.getGradient(), NeuronOCL.getGradient(), iWindow, false)) return false; //--- return true; }
Не забываем контролировать выполнение всех операций. После чего завершаем работу метода.
За распределением градиента ошибки до всех элементов нашей модели идет оптимизация обучаемых параметров модели. Функционал оптимизации параметров данного объекта реализован в методе CNeuronFEDW::updateInputWeights. Алгоритм метода довольно прост, мы лишь вызываем одноименные методы вложенных объектов и проверяем результат выполнения операций по логическому результату работы вызываемых методов.
bool CNeuronFEDW::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!cFF[0].UpdateInputWeights(cReconstruct.AsObject())) return false; if(!cFF[1].UpdateInputWeights(cFF[0].AsObject())) return false; if(!cNorm.UpdateInputWeights(cWavlets.AsObject())) return false; //--- return true; }
Обратите внимание, что в данном методе мы работаем лишь с теми объектами, которые содержат обучаемые параметры.
На этом мы завершаем рассмотрение алгоритмов построения методов новых классов. А с полным кодом рассмотренных классов и их методов вы можете самостоятельно ознакомиться во вложении. Там же вы найдете полный код всех программ, используемых при подготовке статьи.
Обратите внимание, что мы создали лишь собственное видение Энкодера состояния предложенного алгоритма FEDformer. При этом мы полностью опустили Декодер. Это осознанное решение, связанное с принципиальным подходом к поставленной задаче получения прибыльной торговой стратегии. Дело в том, что, как бы это ни казалось странным, мы не стремимся максимально точно спрогнозировать последующие состояния окружающей среды. Ведь они опосредованно влияют на работу нашего Агента. Если бы мы строили четкий алгоритм с правилами к последующему состоянию, нам бы потребовался максимально точный прогноз предстоящего ценового движения. Мы же строим политику нашего Агента иначе.
Мы обучаем Энкодер прогнозированию будущих состояний окружающей среды с целью получения максимально информативного скрытого состояния Энкодера. Актер же в свою очередь извлекает скрытое состояние Энкодера, которое по сути является составной частью Актера и выполняет функцию анализа текущего состояния окружающей среды. И, исходя уже из проведенного анализа текущего состояния окружающей среды Актера, строить свою политику поведения.
В этом есть тонкая грань, которую нам нужно понимать. И поэтому мы не затрачиваем излишнее количество ресурсов на декомпозицию скрытого состояния Энкодера для получения максимально точного прогноза будущих состояний окружающей среды.
2.3 Архитектура моделей
После построения объектов, которые являются составными "кирпичиками" нашей модели, мы переходим к описанию целостной архитектуры обучаемых моделей. Должен сказать, что в данной работе я решил совместить, казалось бы, совершенно различные подходы. Даже можно сказать, соперничающие. Я решил использовать предложенный подход с вейвлет-разложением временного ряда в качестве первичной обработки исходных данных перед рассмотренным в предыдущей статье методом TiDE. Следовательно, изменения коснулись архитектуры Энкодера состояния окружающей среды, которая представлена в методе CreateEncoderDescriptions.
bool CreateEncoderDescriptions(CArrayObj *encoder) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; }
В теле метода мы, как обычно, сначала проверяем актуальность полученного указателя на динамический массив для записи архитектуры модели и, при необходимости, создаем экземпляр нового объекта.
Для получения исходных данных мы используем объект базового полносвязного нейронного слоя.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Модель, как всегда, получает "сырые" исходные данные, и первичную их обработку мы осуществляем в слое пакетной нормализации данных:
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 10000; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Затем мы транспонируем исходные данные, чтобы при последующих операциях осуществлялся независимый анализ унитарных последовательностей используемых индикаторов:
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = HistoryBars; descr.window = BarDescr; if(!encoder.Add(descr)) { delete descr; return false; }
Далее мы используем блок из 10 слоев FED-w:
//--- layer 3-12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFEDW; descr.count = BarDescr; descr.window = HistoryBars; descr.activation = None; for(int i = 0; i < 10; i++) if(!encoder.Add(descr)) { delete descr; return false; }
А непосредственно за блоком мы установим полносвязный Энкодер временных рядов:
//--- layer 13 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTiDEOCL; descr.count = BarDescr; descr.window = HistoryBars; descr.window_out = NForecast; descr.step = 4; { int windows[] = {HistoryBars, 2 * EmbeddingSize, EmbeddingSize, 2 * EmbeddingSize, NForecast}; if(ArrayCopy(descr.windows, windows) <= 0) return false; } descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Далее, как и ранее, используется сверточный слой коррекции смещения прогнозных значений:
//--- layer 14 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = BarDescr; descr.window = NForecast; descr.step = NForecast; descr.window_out = NForecast; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Транспонируем прогнозные значения в представление исходных данных:
//--- layer 15 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = BarDescr; descr.window = NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
И вернем статистические параметры исходной временной последовательности:
//--- layer 16 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRevInDenormOCL; descr.count = BarDescr * NForecast; descr.activation = None; descr.optimization = ADAM; descr.layers = 1; if(!encoder.Add(descr)) { delete descr; return false; } //--- return true; }
Как можно заметить, изменения коснулись лишь внутренней архитектуры Энкодера. Поэтому нам достаточно лишь изменить указатель на слой латентного состояния Энкодера для извлечения данных. А архитектура Актера и Критика остаются без изменений.
#define LatentLayer 14
Кроме того, нам нет необходимости вносить изменения ни в советники взаимодействия с окружающей средой, ни в советники обучения моделей. Их полный код вы найдете во вложении, а описание алгоритмов — в предыдущей статье.
3. Тестирование
В данной статье мы познакомились с методом FEDformer, который переводит анализ временных рядов в область частотных характеристик. Довольно интересный многообещающий метод. И мы провели довольно большую работу по реализации предложенных подходов средствами MQL5.
Еще раз хочу обратить внимание, что в статье представлено собственное видение реализации предложенных подходов, которое довольно сильно отличается от представленного в авторской статье описания метода. Соответственно выводы, сделанные по результатам тестирования модели, относятся только к данной реализации и не могут в полном объеме экстраполироваться на авторский метод.
Как было сказано выше, изменения затронули лишь внутреннюю архитектуру Энкодера. А значит, для обучения моделей мы можем использовать собранные ранее обучающие выборки.
Напомню, что для офлайн обучения моделей мы используем предварительно собранные траектории взаимодействия с окружающей средой. Сбор данных осуществлялся на реальных исторических данных за весь 2023 год. Инструмент — EURUSD, таймфрейм — H1. Тестирование обученной модели осуществляется в тестере стратегий MetaTrader 5 на исторических данных Января 2024 года.
На первом этапе мы осуществляем обучение Энкодера состояния окружающей среды путем минимизации ошибки между фактическими показателями описания последующих состояний окружающей среды и их прогнозными значениями. В Энкодере анализируются и прогнозируются только состояния окружающей среды, которые не зависят от действий Агента. Поэтому мы осуществляем полное обучение Энкодера без обновления обучающей выборки.
По моему субъективному мнению, на данном этапе качество прогнозирования последующих состояний окружающей среды повысилось. Об этом свидетельствует снижение ошибки в процессе обучения. Однако, я не проводил графического сопоставления фактических и прогнозных значений для детального анализа их качества.
На втором итерационном этапе мы осуществляем обучение политики Актера, которое осуществляется параллельно с моделью Критика, которая дает наиболее вероятную оценку действий Актера. На этом этапе нам критически важна точность оценки действий Актера. Поэтому мы чередуем процесс обучения моделей и обновления данных обучающей выборки с учетом текущей политики Актера.
После ряда указанных итераций мне удалось обучить политику поведения Актера, которая генерировала бы прибыль как на обучающем, так и на тестовом временном отрезке. Результаты тестирования представлены ниже.

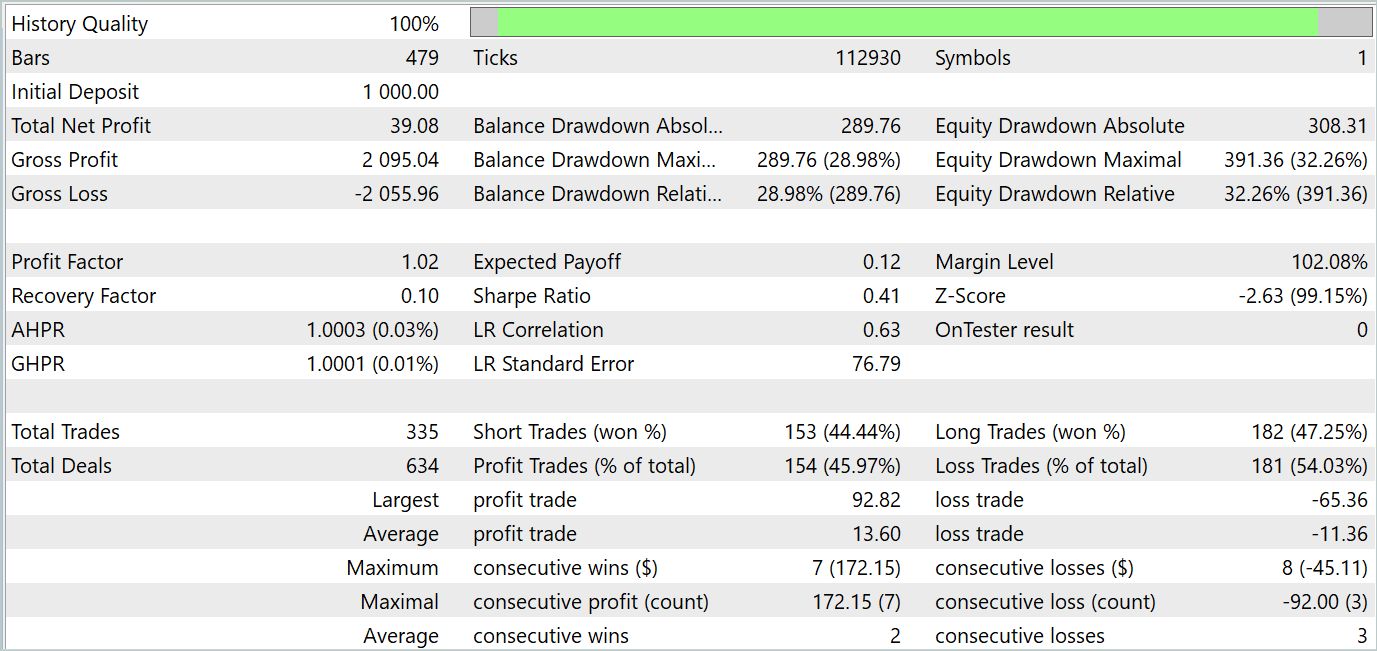
Как можно заметить, график баланса сохраняет общую тенденцию к росту. При этом на графике можно четко выделить 4 тенденции: 2 прибыльных и 2 убыточных. Положительным является тот факт, что прибыльные тенденции имеют больший потенциал. Это позволяет накопить достаточную прибыль, чтобы не потерять депозит в убыточном периоде. Однако наблюдается балансирование на грани. За период тестирования профит-фактор составил лишь 1.02, а доля прибыльных сделок чуть ниже 46%.
В целом, модель демонстрирует наличие потенциала, но требуется дополнительная работа для минимизации убыточных периодов.
Заключение
В этой статье мы познакомились с методом FEDformer, который был предложен для долгосрочного прогнозирования временных рядов. В нем предложен механизм внимания с низкоранговой аппроксимацией по частоте и смешанным разложением для управления сдвигом распределения.
В практической части мы реализовали свое видение предложенных подходов средствами MQL5. Обучили и протестировали модель на реальных исторических данных. Результаты тестирования демонстрируют потенциал рассмотренной модели. Но в то же время есть моменты, требующие дополнительного внимания.
Ссылки
- FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | StudyEncoder.mq5 | Советник | Советник обучения Энкодера |
| 5 | Test.mq5 | Советник | Советник для тестирования модели |
| 6 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 7 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 8 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования