神经网络变得轻松(第三十一部分):进化算法
Dmitriy Gizlyk | 7 二月, 2023
内容
概述
我们继续研究优化模型的非梯度方法。 这些优化方法的主要优势是能够优化梯度方法无法应对的模型。 这些都是无法判定模型函数的导数,或其计算因某些因素而变得复杂的任务。 在上一篇文章中,我们领略了遗传优化算法。 这种算法的思路是从自然科学中借鉴来的。 每个模型权重由模型基因组中的一个单独基因表示。 优化过程评估随机初始化的特定模型种群。 种群的“寿命”是有限的。 在世代结束时,该算法选择种群的“最佳”代表,它将为下一个世代繁衍“后代”。 为每一个体随机选择一对“亲本”(新种群中的模型)。 “亲本的基因”也是随机遗传的。
1. 基本算法构造原理
如您所见,之前研究的遗传优化算法中存在很多随机性。 我们有目的地从每个种群里选出最佳的代表,而种群的大多数被淘汰。 故此,在每个世代对整个种群进行完全迭代的过程中,我们执行了许多“无用”的工作。 此外,模型群体从一个世代发展到另一个世代,其方向,我们需要在很大程度上取决于机会因素。 没有什么能保证朝着目标的方向前进。
如果我们回到梯度下降方法,那一次我们在每次迭代时都有目的地朝向抗梯度。 以这种方式,我们最大限度地减少了模型误差。 模型正朝着所需的方向发展。 当然,为了应用梯度下降法,我们需要分析判定函数在每次迭代时的导数。
如果我们没有这样的机会怎么办? 我们能否以某种方式将这两种方法结合起来?
我们首先回顾一下函数导数的几何含义。 函数的导数表征函数值在给定点的变化率。 它被定义为当参数的变化趋于 0 时,函数值变化与其参数变化之比的极限。 前提是存在这样的极限。
这意味着除了解析导数之外,我们还可以通过实验找到它的近似值。 为了通过实验判定函数相对于参数 x 的导数,我们需要在其它条件相等的情况下稍微改变 x 参数的值,并计算函数的值。 函数值的变化与参数的变化之比,将为我们提供导数的近似值。
由于我们的模型是非线性的,为了在实验上获得导数的更好定义,建议针对每个参数执行以下 2 个操作。 在第一种情况下,我们将添加一些值;在第二种情况下,我们将减去相同的值。 两个运算的平均值,相对于给定点的所分析参数,生成函数导数值的更准确的近似值。
这种方式常用于评估导数模型输出的正确性。 进化算法也正是利用了这一属性。 进化优化策略的主要思路就是利用实验获得的梯度来判定模型参数优化的方向。
但采用实验梯度的主要问题是需要执行大量操作。 例如,要判定一个参数对模型结果的影响,我们需要针对拥有相同源数据的模型进行 3 次前馈验算。 相应地,所有模型参数都伴随着迭代次数增加 3 倍。
这不太好,故我们需要做点什么。
例如,我们能变化的参数不只一个,而是两个。 但在这种情况下,如何判定它们中每一个的影响如何更改所选参数 — 同步与否? 如果所选参数对结果的影响不同,且应以不同的强度变化,该怎么办?
好吧,我们可以说模型内部发生的过程对我们来说并不重要。 我们需要一个满足我们要求的模型。 它也许不是最优的。 无论如何,最优化的概念是针对所提出的所有需求的最大可能满足。
在这种情况下,我们可将模型及其参数集视为一个整体。 我们可用一些算法,并一次性更改模型的所有参数。 更改参数的算法可以是任意的,例如随机分布。
我们将以唯一可用的方式评估变化的影响 — 通过在训练样本上测试模型。 如果新的参数集提升了之前的结果,那么我们接受它。 如果结果变得更糟,则拒绝它,并返回到前一组参数。 一次又一次地取新参数重复循环。
看起来不像遗传算法? 但上面提到的实验梯度的估算在哪里?
我们来更深入遗传算法。 我们将再次使用整个模型种群,并基于某个有限训练集上测试其有效性。 但在这种情况下,我们所用的参数值都较接近,与遗传算法相比较,其每个模型都是随机创建的一种个体。 实际上,我们将采用一个模型,并在其参数中添加一些随机噪音。 使用随机噪音将产生一个没有单一雷同模型的种群。 少量的噪音将令我们能够以很小的偏差获得同一子空间中所有模型的结果。 这意味着模型的结果将是可比较的。
![]()
其中 w' 是种群里的模型参数
w 是源模型参数
ɛ 是一个随机噪音。
为了估算来自种群中每个模型的效率,我们可用损失函数或奖励系统。 选择在很大程度上取决于您要解决的问题。 此外,我们还考虑到优化政策。 我们最小化损失函数,并最大化总奖励。 在本文的实施部分,我们将最大化总奖励,类似于我们在解决强化学习问题时实现的过程。
基于训练样本测试新种群的性能之后,我们需要判定如何优化原始模型的参数。 如果我们应用数学,我们可以尝试以某种方式判定每个参数对结果的影响。 在此,我们将采用一些假设。 但我们早些时候同意将模型视为一个整体来考虑。 这意味着在每个单独的种群模型中加进的整个噪因集,能够依据在训练集上测试模型有效性时获得的总奖励来估算。 因此,我们将在原始模型的参数中加入来自种群所有模型相应参数噪音的加权平均值。 噪音将按总奖励加权。 当然,得到的加权平均值将乘以模型的学习系数。 参数更新公式如下所示。 如您所见,此公式与使用梯度下降更新权重的公式非常相似。
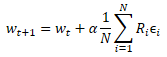
这种进化优化算法是由 OpenAI 团队在 2017 年 3 月的文章“进化策略作为强化学习的可扩展替代方案”中提出的。 在文章中,所提出的算法被认为是先前研究的 Q-学习 和 策略梯度 方法的替代方案。 所提出的算法具有良好的可行性和生产力。 它还表现出对行动频率和延迟奖励的容忍度。 此外,作者提出的算法缩放方法,通过利用额外的计算资源,能够以几乎线性的依赖性提高问题解决速度。 例如,他们使用一千多台并行计算机,在短短 10 分钟内解决了三维人形行走问题。 但在我们的文章中我们不会研究缩放问题。
2. 利用 MQL5 实现
我们已研究过算法的理论方面,那好现在我们进入实施部分,我们将研究利用 MQL5 实现所提出的算法。 请注意,我们将要实现的算法不是 100% 原创的。 尽管算法的整体思想都被保留,但也会有一些变化。 特别是,作者建议采用贪婪算法来选择动作。 不过,在选择动作时,我们采用的是概率算法。 此外,我们还添加了突变参数,类似于遗传算法。 原始算法未用到突变。
为了实现该算法,我们创建一个新的神经网络类 CNetEvolution — 自遗传算法模型继承它。 继承将是私密的。 因此,我们需要覆盖用到的所有方法。 乍一看,采用公开继承,无需重新定义某些方法,我们能简单地将其重定向到父类的方法。 但非公开继承将阻止访问未用到的方法。 这在重载方法时最有用。 用户不会看到父类的重载方法,因此我们避免了不必要的混淆。
class CNetEvolution : protected CNetGenetic { protected: virtual bool GetWeights(uint layer) override; public: CNetEvolution() {}; ~CNetEvolution() {}; //--- virtual bool Create(CArrayObj *Description, uint population_size) override; virtual bool SetPopulationSize(uint size) override; virtual bool feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) override; virtual bool Rewards(CArrayFloat *rewards) override; virtual bool NextGeneration(float mutation, float &average, float &mamximum); virtual bool Load(string file_name, uint population_size, bool common = true) override; virtual bool Save(string file_name, bool common = true); //--- virtual bool GetLayerOutput(uint layer, CBufferFloat *&result) override; virtual void getResults(CBufferFloat *&resultVals); };
我们不会在新类的主体中声明新的类实例。 甚至,我们不会声明任何内部变量。 我们只用父类的对象和变量。 因此,类的构造函数和析构函数都保持为空。
请注意,在添加噪音之前,我们不会创建对象来存储原始模型的权重。 这也是来自原始算法的偏差。 但我们将在实现算法时回到这个问题。
接着来到创建模型种群的 Create 方法。 该方法在参数中接收一个动态数组,其中包含一个模型的描述和种群规模,类似于父类方法。 主要功能将按父类方法实现。 在此,我们只需要调用类,并传递获得的参数。
在 CNetGenetic::Create 遗传算法类方法中,我们创建了一个拥有一种架构和随机权重的模型种群。 现在我们需要创建一个类似的种群。 但我们模型的参数应该很接近。 为了确保它们接近,我们调用 NextGeneration 方法,稍后我们将研究该方法。
不要忘记检查每一步的操作结果。 在方法末尾,返回操作的逻辑结果。
bool CNetEvolution::Create(CArrayObj *Description, uint population_size) { if(!CNetGenetic::Create(Description, population_size)) return false; float average, maximum; return NextGeneration(0,average, maximum); }
我早前曾提到 NextGeneration 方法。 我们来看看它的算法。 此方法的功能类似于父类中同名方法的功能。 但有某些与算法需求关联的特别之处。
在参数中,该方法接收突变概率,和两个变量,我们将在其中写入平均和最大奖励。
在方法主体中,保存所需的奖励值,并限制突变的最大值。 我们限制突变最大值,是因为我们需要得到经过训练的模型。 如果突变值很高,我们将在每次迭代时生成随机模型参数,无论获得的结果如何。 而后果就是,种群将不断由随机的未经训练的模型组成。
bool CNetEvolution::NextGeneration(float mutation, float &average, float &maximum) { maximum = v_Rewards.Max(); average = v_Rewards.Mean(); mutation = MathMin(mutation, MaxMutation);
接下来,我们准备更新模型权重的基础。 正如本文理论部分讨论的那样,在更新参数时,对噪因大小进行加权的度量,是训练集上单个模型的总奖励。 但取决于所采用的奖励政策,总奖励可以是正的,也可以是负的。 伴随高度可能,我们将遇到一种状况,即所有种群成员的总奖励都具有相同的符号。 即,,它们要么都正面的,要么都是负面的。
并非所有添加到模型参数的噪音都会产生正面或负面的影响。 在这种情况下,某些分量的正面影响将被其它分量的负面影响所掩盖。 充其量,它会减缓我们朝着正确方向前进的速度。 在最坏的情况下,这可能会导致模型训练朝着相对的方向发展。 为了尽量减少这种效应的影响,我们将特定模型的总奖励与整个种群的平均总奖励之间的差值,写入概率的向量 v_Probability。
此步骤与我们添加的噪音属于正态分布的假设有关。 这意味着原始模型的总奖励大约处于种群总奖励总分布的中间。 一旦计算出差值后,总奖励低于平均水平的模型将获得负值概率。 模型的总奖励越小,其概率负值越大。 同样地,总奖励最高的模型也将获得最高的正值概率。 它的实际益处是什么? 如果增加的噪音拥有正面影响,则将其乘以正值概率,我们将权重向同一方向偏移。 因此,我们鼓励在所需的方向上进行模型训练。 如果增加的噪音拥有负面影响,则将其乘以负值概率,如此我们就将权重偏移的方向转负为正。 这也指导模型训练实现总奖励的最大化。
接下来,根据原始算法,取噪音的加权平均值对模型参数进行校正。 因此,我们还对所得概率的向量进行归一化,令其所有向量元素的绝对值之和等于 1。
v_Probability = v_Rewards - v_Rewards.Mean(); float Sum = MathAbs(v_Probability).Sum(); if(Sum == 0) v_Probability[0] = 1; else v_Probability = v_Probability / Sum;
判定模型更新系数后,且我们已写入向量 v_Probability,继续循环遍历模型各层。 新种群模型的参数将在此循环的主体中形成。
在循环体中,我们首先得到一个当前各层对象的动态数组的指针。 立即检查所接收指针的有效性。 此外,检查动态数组的大小。 它必须与给定的种群规模相匹配。 如果种群规模不足,则调用 CreatePopulation 方法创建其它模型。 在此,我们使用父类方法,且无需任何修改。
for(int l = 1; l < layers.Total(); l++) { CLayer *layer = layers.At(l); if(!layer) return false; if(layer.Total() < (int)i_PopulationSize) if(!CreatePopulation()) return false;
之后,调用 GetWeights 方法,该方法将创建模型当前层的更新参数。 参数将在 m_Weights 矩阵和 m_WeightsConv 矩阵中创建。 我们稍后将研究该方法的算法。
if(!GetWeights(l)) return false;
更新模型参数之后,我们就可开始填充种群。 为此,我们创建一个嵌套循环,其迭代次数等于种群规模。
在循环的主体中,我们得到一个指针,指向正在分析的神经层的当前神经元对象。 立即检查所获指针的有效性。 此处还获取指向权重矩阵对象的指针。
for(uint i = 0; i < i_PopulationSize; i++) { CNeuronBaseOCL* neuron = layer.At(i); if(!neuron) return false; CBufferFloat* weights = neuron.getWeights();
如果收到的权重矩阵指针有效,则开始操控此矩阵。 在此,我们创建另一个嵌套循环,它将遍历权重矩阵的元素。
在循环主体中,我们首先检查采用的突变概率,并在必要时生成一个随机数。 如果生成的随机数小于突变概率,则将随机权重系数写入矩阵的当前元素。 之后,继续循环的下一次迭代。 在遗传算法中使用了类似的方法。
if(!!weights) { for(int w = 0; w < weights.Total(); w++) { if(mutation > 0) { int err_code; float random = (float)Math::MathRandomNormal(0.5, 0.5, err_code); if(mutation > random) { if(!weights.Update(w, GenerateWeight((uint)m_Weights.Cols()))) { Print("Error updating the weights"); return false; } continue; } }
如果需要更新当前权重,那么我们首先检查其当前值。 如有必要,应将无效数字替换为随机权重。
if(!MathIsValidNumber(m_Weights[0, w])) { if(!weights.Update(w, GenerateWeight((uint)m_Weights.Cols()))) { Print("Error updating the weights"); return false; } continue; }
在嵌套循环迭代结束时,往当前权重里加进噪音。
if(!weights.Update(w, m_Weights[0, w] + GenerateWeight((uint)m_Weights.Cols()))) { Print("Error updating the weights"); return false; } } weights.BufferWrite(); }
将噪音添加到当前种群元素的权重矩阵的所有元素后,将更新后的参数传输到 OpenCL 关联环境内存。
如有必要,对卷积层权重矩阵重复上述迭代。
if(neuron.Type() != defNeuronConvOCL) continue; CNeuronConvOCL* temp = neuron; weights = temp.GetWeightsConv(); for(int w = 0; w < weights.Total(); w++) { if(mutation > 0) { int err_code; float random = (float)Math::MathRandomNormal(0.5, 0.5, err_code); if(mutation > random) { if(!weights.Update(w, GenerateWeight((uint)m_WeightsConv.Cols()))) { Print("Error updating the weights"); return false; } continue; } } if(!MathIsValidNumber(m_WeightsConv[0, w])) { if(!weights.Update(w, GenerateWeight((uint)m_WeightsConv.Cols()))) { Print("Error updating the weights"); return false; } continue; } if(!weights.Update(w, m_WeightsConv[0, w] + GenerateWeight((uint)m_WeightsConv.Cols()))) { Print("Error updating the weights"); return false; } } weights.BufferWrite(); } }
重复迭代序列的所有元素。
在方法结束时,重置总奖励累积向量,并终止该方法。
v_Rewards.Fill(0); //--- return true; }
根据方法序列,现在我们来研究之前方法调用的 GetWeights 方法。 其目的是更新正在优化的模型参数。 父类遗传算法 CNetGene 有一个同名的方法,用于下载所有种群模型的一个神经层的参数。 结果矩阵随后用来创建新种群。 这次我们采用相同的逻辑,只是内容根据所采用的优化算法略有变化。
该方法在参数中接收神经层的索引,以便为其创建参数矩阵。 在方法主体中,在更新模型参数时,采用种群代表的概率检查所形成向量的可用性。 调用父类的同名方法。 记住要控制操作的执行。
bool CNetEvolution::GetWeights(uint layer) { if(v_Probability.Sum() == 0) return false; if(!CNetGenetic::GetWeights(layer)) return false;
一旦父类方法的操作完成,我们期望 m_Weights 矩阵和 m_WeightsConv 矩阵将包含所有种群模型的分析神经层的权重。
请注意,矩阵包含权重。 然而,为了更新模型参数,我们需要添加的噪音值,和原始模型的参数。
我们的做法与奖励的调整类似。 我们知道噪音具有正态分布。 种群模型的每个参数都是原始模型的相应参数和噪音的合计。 我们假设原始模型的参数处于种群模型相应参数分布的中间。 那么,我们可以取相应种群参数的平均值向量。
if(m_Weights.Cols() > 0) { vectorf mean = m_Weights.Mean(0);
通过从种群模型的参数矩阵中减去平均值的向量,我们可以找到所需的附加噪音矩阵。
matrixf temp = matrixf::Zeros(1, m_Weights.Cols()); if(!temp.Row(mean, 0)) return false; temp = (matrixf::Ones(m_Weights.Rows(), 1)).MatMul(temp); m_Weights = m_Weights - temp;
如果我们采用相同的方法来判定增加的噪音,及其在更新模型权重时采用的概率,我们会得到可比较的值。 接下来,我们可以利用上面的公式来更新模型参数。 之后,我们只需要将得到的值传输到相应的矩阵。
mean = mean + m_Weights.Transpose().MatMul(v_Probability) * lr; if(!m_Weights.Resize(1, m_Weights.Cols())) return false; if(!m_Weights.Row(mean, 0)) return false; }
如有必要,针对第二个矩阵重复这些操作。
if(m_WeightsConv.Cols() > 0) { vectorf mean = m_WeightsConv.Mean(0); matrixf temp = matrixf::Zeros(1, m_WeightsConv.Cols()); if(!temp.Row(mean, 0)) return false; temp = (matrixf::Ones(m_WeightsConv.Rows(), 1)).MatMul(temp); m_WeightsConv = m_WeightsConv - temp; mean = mean + m_WeightsConv.Transpose().MatMul(v_Probability) * lr; if(!m_WeightsConv.Resize(1, m_WeightsConv.Cols())) return false; if(!m_WeightsConv.Row(mean, 0)) return false; } //--- return true; }
下面的附件中提供了所有方法和类的完整代码。
我们已研究过方法的算法,它是经过修改实现的进化算法。 为了完成类功能,我们仍然需要重写方法,从而将线程重定向到父类的相应方法。 请注意,这是非公开继承的必要措施。
bool CNetEvolution::SetPopulationSize(uint size) { return CNetGenetic::SetPopulationSize(size); } bool CNetEvolution::feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) { return CNetGenetic::feedForward(inputVals, window, tem); } bool CNetEvolution::Rewards(CArrayFloat *rewards) { if(!CNetGenetic::Rewards(rewards)) return false; //--- v_Probability = v_Rewards - v_Rewards.Mean(); v_Probability = v_Probability / MathAbs(v_Probability).Sum(); //--- return true; } bool CNetEvolution::GetLayerOutput(uint layer, CBufferFloat *&result) { return CNet::GetLayerOutput(layer, result); } void CNetEvolution::getResults(CBufferFloat *&resultVals) { CNetGenetic::getResults(resultVals); }
为了完成这个类,我们应该重写操控文件的方法。 首先,我们需要决定模型保存方法。 您也许已经注意到,我们没有单独保存更新了参数的模型。 我们仅更新了参数来构建新种群。 但是要保存经过训练的模型,我们需要择其一。 从逻辑上讲,应保存拥有最佳结果的模型。 我们已经在父类方法中有了相关的方法。 我们将操作流重定向到它。
bool CNetEvolution::Save(string file_name, bool common = true) { return CNetGenetic::SaveModel(file_name, -1, common); }
我们已经决定了如何保存模型。 我们移至预训练模型加载方法。 状况相似,但略有差别。 在训练过程中,我们不会保存整个种群,而只保存结果最好的那个模型。 相应地,在加载这个模型之后,我们需要创建一个给定规模的种群。 这种可能性已在父类加载方法中实现。 但该方法创建的是一个拥有绝对随机参数的模型种群。 但是,我们创建的一个种群,需要围绕一个模型附带各种噪音。 因此,我们首先调用父类模型的数据加载方法 — 它创建所需规模的功能并填充。 然后,我们重置总奖励向量,并调用之前研究过的方法 NextGeneration,其创建一个具有所需特征的新种群。
bool CNetEvolution::Load(string file_name, uint population_size, bool common = true) { if(!CNetGenetic::Load(file_name, population_size, common)) return false; v_Rewards.Fill(0); float average, maximum; if(!NextGeneration(0, average, maximum)) return false; //--- return true; }
请注意尚未澄清的一点。 我们的新种群生成方法如何从已填充随机权重的模型里分离加载的模型? 解决方案非常简单。 在父类方法中,加载的模型放置在种群索引为 “0” 的位置。 具有随机参数的模型将添加到其中。 为了确定添加的噪音概率,我们使用模型总奖励的向量。 在调用新的种群创建方法之前,此方法之前已重置。 因此,在 NextGeneration 方法主体中,在判定概率时,我们还得到一个零值的向量。 向量值的总和为 0。 在这种情况下,我们 100% 断定仅用到索引为 0 处的模型(从文件加载的),来形成新种群模型的参数基础。 使用随机模型参数的概率为 0。 因此,新种群将围绕从文件加载的模型来构建。
bool CNetEvolution::NextGeneration(float mutation, float &average, float &maximum) { ............. ............. ............. v_Probability = v_Rewards - v_Rewards.Mean(); float Sum = MathAbs(v_Probability).Sum(); if(Sum == 0) v_Probability[0] = 1; else v_Probability = v_Probability / Sum; ............. ............. ............. }
我们已研究完毕 CNetEvolution 新类所有方法的算法。 现在,我们可以进入模型训练。 这将在本文的下一章节中完成。
3. 测试
为了训练模型,我基于在上一篇文章中我们所用的 EA 创建了 Evolution.mq5。 EA 参数和设置均未更改。 实际上,通过简单地修改遗传算法模型训练 EA 中的对象类,我们就可以利用进化算法训练新模型。
我将详细介绍如何创建新模型。 如果您还记得,在第 7 和第 8 部分中创建了迁移学习解决方案之后,我决定不在 EA 代码中指定模型架构。 这样就可以使用不同的模型进行实验,而无需更改 EA 代码。
为了创建一个新模型,我们运行之前创建的 NetCreator。 我们不使用工具的左侧,也不加载任何预先训练的模型,因为我们正在创建一个全新的模型。
我们知道,在训练过程中,我们将每根蜡烛的 12 个描述参数喂到到模型之中。 我们还计划分析 20 根烛台深度的历史数据。 相应地,初始数据层的大小将为 240 个神经元(12 * 20)。 作为输入数据层,我们使用完全连接的神经层,且不用激活函数。 在工具的中央部分指定第一层的参数,然后按“添加图层”按钮。 此操作的结果就是,第一个神经层的描述将显示在工具的右侧板块当中。

接下来是模型架构创建过程。 例如,您希望模型分析 3 根相邻蜡烛的形态。 为此,添加一个卷积层,其分析窗口大小为 36 个神经元 (12 * 3)。 将分析的窗口偏移步长设置为 12 个神经元,这与描述一根烛条的元素数量相对应。 为了给定模型的动作自由度,创建 12 个形态分析过滤器。 至于激活函数,我采用双曲正切线,它可以在逻辑上分离看涨和看跌形态。 神经层输出将在激活函数的范围内归一化。

创建的卷积层首先返回一个过滤器的所有元素序列,然后返回另一个过滤器的序列。 这样就可以与矩阵进行比较,其中每行对应于一个单独的过滤器,而行元素代表整个源数据序列上的过滤器操作结果。
接下来,我们需要分析先前创建的卷积层的滤波器结果。 我们将构建一个由 3 个卷积层组成的级联,每个卷积层将分析前一个卷积层的结果。 所有三层都拥有相同的特征。 它们将以 1 个的增量,分析 2 个相邻神经元。 每层当中,均有两个过滤器参与分析。

如您所见,由于使用了一个小型的分析数据窗口步骤和几个过滤器,结果向量的大小逐层增长。 通常,子采样图层用于降维。 它们要么均化滤波器的输出值,要么取最高值。 我没有用到它们,而是尝试保存尽可能多的有用信息。
卷积层执行一种初始数据准备,在其中定义一些形态。 卷积层越多,模型能够找到的形态就越复杂。 但要避免创建极深的模型,因为这会令学习过程复杂化。 一个事实,非梯度模型优化方法避免了梯度暴涨和暴跌的问题。 但您真的需要深度网络来解决您的问题吗? 试验不同的选项,并判定模型中的增长如何影响最终结果。 您会注意到,在某些时候添加新图层不会改变结果。 但优化模型需要额外的资源。
卷积神经层的结果将以 3 层全连接感知器进行处理,每层拥有 500 个神经元。 此处,我还采用双曲正切作为激活函数。 我建议您尝试各种工作原理的激活函数,并比较结果。

在模型输出中,我们希望获得三个动作的概率分布:买入、卖出、观望。 为此,我们将创建另一个由 3 个神经元组成的完全连接的层。 这次我们不使用激活函数。

利用 SoftMax 层将结果转换到概率区域。

新模型的创建至此完毕。 我们将其保存到 EA 所用的文件当中。 通过单击“保存模型”启动模型保存功能。

该模型基于过去两年的历史数据进行训练。 模型训练过程已在前面的文章中讲述过。 我不会再详述它们。
奇怪的是,在模型优化过程中,总误差动态图形显示出突然的动态。

优化之后,在策略测试器中测试了模型。 为了测试模型,我用到了 Evolution-test.mq5 EA,它是前几篇文章中的 EA 精确副本。 仅有的影响就是更改了加载模型的文件名。 完整的 EA 代码可在附件中找到。
EA 基于过去 2 周历史数据进行了测试,不包括训练样本。 这意味着 EA 是在接近真实条件下进行测试的。 测试结果展现了所提方法的可行性。 在下面的图表中,您可以看到余额增加的动态。 总体来说,在测试期间执行了107 笔交易。 其中,近 55% 是盈利的。 盈亏交易的比例接近 1:1,但平均盈利比平均亏损高 43%。 因此,生成的盈利因子为 1.69。 抗跌系数已达到 3.39。


结束语
在本文中,我们领略了另一种非梯度优化方法 — 进化算法。 我们还创建了一个实现此算法的类。 所研讨算法的有效性经模型优化后,已得到策略测试器中优化结果的证实。 测试结果表明,EA 能够产生盈利。 不过,请注意,测试是在较短的时间间隔内进行的。 因此,我们不能据此判定 EA 能否长期盈利。
本文中的模型和 EA 仅用于演示该技术。 在真实账户上运用它们之前,需要进行更严格的设置和优化。
参考
- 神经网络变得轻松(第二十六部分):强化学习
- 神经网络变得轻松(第二十七部分):深度 Q-学习(DQN)
- 神经网络变得轻松(第二十八部分):政策梯度算法
- 神经网络变得轻松(第二十九部分):优势扮演者-评价者算法
- 自然进化策略
- 进化策略作为强化学习的可扩展替代方案
- 神经网络变得轻松(第二十三部分):构建迁移学习工具
- 神经网络变得轻松(第二十四部分):改进迁移学习工具
本文中用到的程序
| # | 发行 | 类型 | 说明 |
|---|---|---|---|
| 1 | Evolution.mq5 | EA | 优化模型的 EA |
| 2 | NetEvolution.mqh | 类库 | 组织进化算法的函数库 |
| 3 | Evolution-test.mq5 | EA | 在策略测试器中测试模型的智能系统 |
| 4 | NeuroNet.mqh | 类库 | 创建神经网络模型的类库 |
| 5 | NeuroNet.cl | 代码库 | 创建神经网络模型的 OpenCL 程序代码库 |