Gradient boosting no aprendizado de máquina transdutivo e ativo
Maxim Dmitrievsky | 17 março, 2021
Introdução
O aprendizado semi supervisionado ou transdutiva usa os dados não rotulados, permitindo que o modelo compreenda melhor a estrutura geral de dados. Isso é semelhante ao nosso pensamento. Ao lembrar apenas algumas imagens, o cérebro humano é capaz de extrapolar o conhecimento sobre essas imagens para novos objetos em termos gerais, sem se concentrar em detalhes insignificantes. Isso resulta num menor sobreajuste e numa melhor generalização.
A transdução foi introduzida por Vladimir Vapnik, que é o coinventor da Support-Vector Machine (SVM). Ele acredita que a transdução é preferível à indução, uma vez que a indução requer a resolução de um problema mais geral (inferir uma função) antes de resolver um problema mais específico (computar as saídas para os novos casos).
“Ao resolver um problema de interesse, não resolva um problema mais geral como uma etapa intermediária. Tente obter a resposta de que realmente precisa, mas não uma resposta mais geral."
A suposição de Vapnik é semelhante à observação feita anteriormente por Bertrand Russell:
"nós chegaremos à conclusão de que Sócrates é mortal com uma abordagem maior da certeza se tornarmos nosso argumento puramente indutivo do que se seguirmos o caminho de 'todos os homens são mortais' e então usarmos a dedução".
Espera-se que o aprendizado não supervisionado (com dados não rotulados) se torne muito mais importante no longo prazo. A aprendizagem não supervisionada geralmente é típica de pessoas e animais: eles descobrem a estrutura do mundo observando, não reconhecendo o nome de cada objeto.
Assim, a aprendizagem semi supervisionada combina os dois processos: a aprendizagem supervisionada ocorre em uma pequena quantidade de dados rotulados, após o modelo extrapolar o seu conhecimento para uma grande área não rotulada.
O uso de dados não rotulados implica em alguma conexão com a distribuição de dados subjacente. Pelo menos uma das seguintes premissas deve ser atendida:
- Pressuposto de continuidade. Os pontos próximos um do outro têm maior probabilidade de compartilhar um rótulo. Isso também é assumido no aprendizado supervisionado e produz uma preferência por limites geometricamente simples que separam as classes. No caso de aprendizagem semi supervisionada, a suposição de suavidade adicionalmente produz uma preferência em regiões de baixa densidade, onde poucos pontos estão próximos uns dos outros, mas em classes diferentes.
- Suposição de cluster. Os dados tendem a formar clusters discretos e os pontos no mesmo cluster têm mais probabilidade de compartilhar um rótulo (embora os dados que compartilham um rótulo possam se espalhar por vários clusters). Este é um caso especial da suposição de suavidade que leva ao aprendizado com algoritmos de agrupamento.
- Pressuposto de geração de coleções. Os dados estão aproximadamente em uma coleção de dimensão muito menor do que o espaço de entrada. Nesse caso, o aprendizado da coleção usando os dados rotulados e não rotulados pode evitar a maldição da dimensionalidade. Então, o aprendizado pode continuar usando distâncias e densidades definidas na coleção.
Verifique o link para mais detalhes sobre o aprendizado semi supervisionado.
O método principal no aprendizado semi supervisionado é a pseudo-rotulagem que é implementada da seguinte forma:
- Alguma medida de proximidade (por exemplo, distância euclidiana) é usada para rotular o restante dos dados com base na região dos dados rotulados (pseudo-rótulo).
- Rótulos de treinamento são combinados com pseudo-rótulos e sinais.
- O modelo é treinado em todo o conjunto de dados.
De acordo com os pesquisadores, o uso de dados rotulados em combinação com os dados não rotulados pode melhorar significativamente a precisão do modelo. Eu usei uma ideia semelhante no meu artigo anterior, em que eu usei a estimativa da densidade de probabilidade da distribuição dos dados rotulados e a amostragem dessa distribuição. Mas a distribuição de novos dados pode ser diferente, então o aprendizado semi supervisionado pode trazer alguns benefícios, como o experimento deste artigo mostrará.
O aprendizado ativo é uma certa continuação lógica do aprendizado semi supervisionado. Ele é um processo iterativo de rotular novos dados de forma que os limites que separam as classes sejam locais de otimalidade.
A hipótese principal do aprendizado ativo afirma que o algoritmo de aprendizagem pode escolher os dados com os quais se deseja aprender. Ele pode funcionar melhor do que os métodos tradicionais com uma quantidade significativamente menor de dados de treinamento. Aqui, os métodos tradicionais se referem ao aprendizado supervisionado convencional usando os dados rotulados. Esse treinamento pode ser chamado de passivo. O modelo é simplesmente treinado em dados rotulados. Quanto mais dados, melhor. Um dos problemas mais demorados na aprendizagem passiva é a coleta e rotulagem de dados. Em muitos casos, pode haver restrições associadas à coleta de dados adicionais ou à sua rotulagem adequada.
O aprendizado ativo tem três cenários mais populares, nos quais o modelo de aprendizado solicitará novos rótulos de instância de classe da região não rotulada:
- Solicitar um exemplo sintetizado artificialmente. Nesse caso, o modelo gera uma instância a partir de uma determinada distribuição que é comum a todos os exemplos. Pode ser uma instância de classe com ruído adicionado ou apenas um ponto plausível no espaço em questão. Este novo ponto é enviado ao especialista para treinamento. O especialista é o nome convencional para a função de avaliador que avalia o valor de uma determinada instância de recurso para o modelo.
- Amostragem baseada em fluxo. De acordo com esse cenário, cada ponto de dados não rotulado é examinado um por vez, após o qual o especialista escolhe se deseja consultar um rótulo de classe para esse ponto ou rejeitá-lo com base em algum critério de informação.
- Amostragem baseada em pool. Nesse cenário, há um grande conjunto de exemplos não rotulados, como no caso anterior. As instâncias são selecionadas da pool com base na informatividade. As instâncias mais informativas são selecionadas da pool. Isto é o cenário mais popular entre os fãs do aprendizado ativo. Todas as instâncias não rotuladas serão classificadas e, em seguida, as instâncias mais informativas serão selecionadas.
Cada cenário pode ser baseado em uma estratégia de consulta específica. Conforme mencionado acima, a principal diferença entre o aprendizado ativo e passivo é a capacidade de consultar instâncias de uma região não rotulada com base em consultas anteriores e respostas de modelo. Portanto, todas as consultas requerem alguma medida de informatividade.
As estratégias de consulta mais populares são as seguintes:
- Amostragem de incerteza (menor confiança). De acordo com essa estratégia, nós selecionamos a instância na qual o modelo é mais incerto. Por exemplo, a probabilidade de atribuir um rótulo a uma determinada classe está abaixo de um certo limite.
- Amostragem de margem. A desvantagem da primeira estratégia é que ela determina a probabilidade de pertencer a apenas um rótulo, ao mesmo tempo que desconsidera as probabilidades de pertencer a outros rótulos. A estratégia de amostragem de margem seleciona a menor diferença de probabilidade entre os dois rótulos mais prováveis.
- Amostragem de entropia. A fórmula de entropia é aplicada a cada instância, e a instância com o valor mais alto é consultada.
Igual o aprendizado semi supervisionado, o processo de aprendizado ativo consiste em várias etapas:
- O modelo é treinado em dados rotulados.
- O mesmo modelo é usado para rotular dados não rotulados para prever probabilidades (pseudo-rótulos).
- Uma nova estratégia de consulta de instância é selecionada.
- N instâncias são selecionadas da pool de dados de acordo com a informatividade e são adicionadas à amostra de treinamento.
- Este ciclo é repetido até que algum critério de parada seja alcançado. Um critério de parada pode ser o número de iterações ou a estimativa do erro de aprendizagem, bem como outros critérios externos.
Aprendizado Ativo
Vamos direto ao aprendizado ativo e testar sua eficácia em nossos dados.
Existem várias bibliotecas para o aprendizado ativo na linguagem Python, sendo a mais popular delas:
- modAL é um pacote bastante simples e fácil de aprender, que é uma espécie de invólucro para a famosa biblioteca de aprendizado de máquina scikit-learn (eles são totalmente compatíveis). O pacote fornece os métodos mais famosos de aprendizado ativo.
- Libact usa a estratégia multi-armed bandit sobre as estratégias de consulta existentes para uma seleção dinâmica da melhor consulta.
- Alipy é uma espécie de laboratório de provedores de pacotes, que contém muitas estratégias de consulta.
Eu selecionei a biblioteca modAL por ser mais intuitiva e adequada para me familiarizar com a filosofia de aprendizado ativo. Ela oferece maior liberdade no desenho de modelos e na criação de seus próprios modelos usando blocos padrão ou criando os seus próprios blocos.
Vamos considerar o processo descrito acima usando o esquema abaixo, que não requer mais explicações:
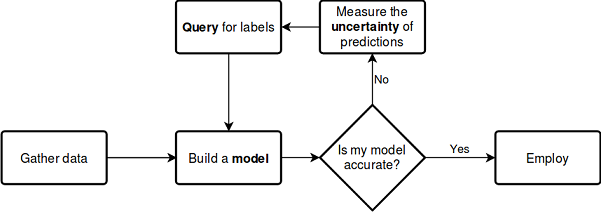
Veja a documentação
O melhor da biblioteca é que você pode usar qualquer classificador scikit-learn. O exemplo a seguir demonstra o uso de uma floresta aleatória como modelo de aprendizagem:
from modAL.models import ActiveLearner from modAL.uncertainty import entropy_sampling from sklearn.ensemble import RandomForestClassifier learner = ActiveLearner( estimator=RandomForestClassifier(), query_strategy=entropy_sampling, X_training=X_training, y_training=y_training )
A floresta aleatória aqui atua como um modelo de aprendizado e como um avaliador permitindo a seleção de novas amostras de dados não rotulados dependendo da estratégia de consulta (por exemplo, com base na entropia, como neste exemplo). Em seguida, um conjunto de dados que consiste em uma pequena quantidade de dados rotulados é passado para o modelo. Isso é usado para o treinamento preliminar.
A biblioteca modAL permite uma combinação fácil de estratégias de consulta e permite fazer estratégias ponderadas compostas a partir delas:
from modAL.utils.combination import make_linear_combination, make_product from modAL.uncertainty import classifier_uncertainty, classifier_margin # creating new utility measures by linear combination and product # linear_combination will return 1.0*classifier_uncertainty + 1.0*classifier_margin linear_combination = make_linear_combination( classifier_uncertainty, classifier_margin, weights=[1.0, 1.0] ) # product will return (classifier_uncertainty**0.5)*(classifier_margin**0.1) product = make_product( classifier_uncertainty, classifier_margin, exponents=[0.5, 0.1] )
Depois que a consulta é gerada, as instâncias que atendem aos critérios da consulta são selecionadas da região de dados sem rótulo, usando os seletores multi_argmax ou weighted_randm:
from modAL.utils.selection import multi_argmax # defining the custom query strategy, which uses the linear combination of # classifier uncertainty and classifier margin def custom_query_strategy(classifier, X, n_instances=1): utility = linear_combination(classifier, X) query_idx = multi_argmax(utility, n_instances=n_instances) return query_idx, X[query_idx] custom_query_learner = ActiveLearner( estimator=GaussianProcessClassifier(1.0 * RBF(1.0)), query_strategy=custom_query_strategy, X_training=X_training, y_training=y_training )
Estratégias de Consulta
Existem três estratégias de consulta principais. Todas as estratégias são baseadas na incerteza de classificação, por isso são chamadas de medidas de incerteza. Vamos ver como elas funcionam.
A incerteza de classificação, em um caso simples, é avaliada como U(x)=1−P(x^|x), onde x é o caso a ser previsto, enquanto x^ é a previsão mais provável. Por exemplo, se houver três classes e três itens de amostra, as incertezas correspondentes podem ser calculadas da seguinte forma:
[[0.1 , 0.85, 0.05], [0.6 , 0.3 , 0.1 ], [0.39, 0.61, 0.0 ]] 1 - proba.max(axis=1) [0.15, 0.4 , 0.39]
Assim, o segundo exemplo será selecionado como o mais incerto.
A margem de classificação é a diferença nas probabilidades da primeira e da segunda consultas com maior probabilidade. A diferença é determinada de acordo com a seguinte fórmula: M(x)=P(x1^|x)−P(x2^|x), onde x1^ e x2^ são a primeira e a segunda classes com maior probabilidade.
Essa estratégia de consulta seleciona instâncias com a menor margem entre as probabilidades das duas classes mais prováveis, pois quanto menor a margem da solução, mais incerta ela é.
>>> import numpy as np >>> proba = np.array([[0.1 , 0.85, 0.05], ... [0.6 , 0.3 , 0.1 ], ... [0.39, 0.61, 0.0 ]]) >>> >>> proba array([[0.1 , 0.85, 0.05], [0.6 , 0.3 , 0.1 ], [0.39, 0.61, 0. ]]) >>> part = np.partition(-proba, 1, axis=1) >>> part array([[-0.85, -0.1 , -0.05], [-0.6 , -0.3 , -0.1 ], [-0.61, -0.39, -0. ]]) >>> part[:, 0] array([-0.85, -0.6 , -0.61]) >>> part[:, 1] array([-0.1 , -0.3 , -0.39]) >>> margin = - part[:, 0] + part[:, 1] >>> margin array([0.75, 0.3 , 0.22])
Nesse caso, a terceira amostra (a terceira linha do array) será selecionada, pois a margem de probabilidade para esta instância é mínima.
A entropia de classificação é calculada usando a fórmula de entropia da informação: H(x)=−∑kpklog(pk), onde pk é a probabilidade de que a amostra pertença à k-ésima classe. Quanto mais próxima a distribuição estiver da uniformidade, maior será a entropia. Em nosso exemplo, a entropia máxima é obtida para o segundo exemplo.
[0.51818621, 0.89794572, 0.66874809]
Ela não parece ser muito difícil. Esta descrição parece ser suficiente para entender as três estratégias de consulta principais. Para mais detalhes, estude a documentação do pacote, porque eu forneço apenas os pontos básicos.
Estratégias de consulta em lote
Consultar um elemento por vez e retreinar o modelo nem sempre é eficiente. Uma solução mais eficiente é rotular e selecionar várias instâncias dos dados não rotulados de uma vez. Existem várias questões para isso. O mais popular deles é a Amostragem de Conjuntos Classificados com base em uma função de similaridade, como a similaridade de cossenos. Este método estima quão bem o espaço de características é explorado próximo à x (instância não rotulada). Após a avaliação, a instância com a classificação mais alta é adicionada ao conjunto de treinamento e removida do conjunto de dados não rotulados. Depois disso, a classificação é recalculada e a melhor instância é adicionada novamente até que o número de instâncias atinja o tamanho especificado (tamanho do lote).
Consultas de densidade de informação
As estratégias de consulta simples descritas acima não avaliam a estrutura de dados. Isso pode levar a consultas abaixo da otimalidade. Para melhorar a amostragem, você pode usar as medidas da densidade de informação que ajudarão a selecionar corretamente os elementos dos dados não rotulados. Ele usa cosseno ou a distância euclidiana. Quanto maior a densidade da informação, maior será a semelhança desta instância selecionada com todas as outras.
Consultas do comitê de classificação
Este tipo de consulta elimina algumas das desvantagens dos tipos de consulta simples. Por exemplo, a seleção de elementos tende a ser enviesada devido às características de um determinado classificador. Alguns elementos de amostragem importantes podem estar faltando. Este efeito é eliminado armazenando simultaneamente várias hipóteses e selecionando as consultas entre as quais existem divergências. Assim, o comitê de classificadores aprende cada um em sua própria cópia da amostra e, em seguida, os resultados são pesados. Outros tipos de aprendizado do comitê de classificação incluem bagging e bootstrapping.
Esta breve descrição cobre quase que completamente a funcionalidade da biblioteca. Você pode consultar a documentação para obter mais detalhes.
Aprendendo de forma ativa
Eu selecionei a estratégia de consulta em lote, bem como as consultas do comitê de classificação, e executei uma série de experimentos. A estratégia de consulta em lote não apresentou bom desempenho nos novos dados, no entanto, ao enviar o conjunto de dados gerado ao GMM, eu comecei a obter resultados interessantes.
Considere um exemplo de implementação da função de aprendizado ativo em lote:
def active_learner(data, labeled_size, unlabeled_size, batch_size, max_depth): X_raw = data[data.columns[1:-1]].to_numpy() y_raw = data[data.columns[-1]].to_numpy() # Isolate our examples for our labeled dataset. training_indices = np.random.randint(low=0, high=X_raw.shape[0] + 1, size=labeled_size) X_train = X_raw[training_indices] y_train = y_raw[training_indices] # fit the model on all data cl = AdaBoostClassifier(DecisionTreeClassifier(max_depth=max_depth), n_estimators=50, learning_rate = 0.01) cl.fit(X_raw, y_raw) print('Score for the passive learning: ', cl.score(X_raw, y_raw), ' with train size: ', data.shape[0]) # Isolate the non-training examples we'll be querying. X_pool = np.delete(X_raw, training_indices, axis=0) y_pool = np.delete(y_raw, training_indices, axis=0) # Pre-set our batch sampling to retrieve 3 samples at a time. preset_batch = partial(uncertainty_batch_sampling, n_instances=batch_size) # Specify our core estimator along with its active learning model. cl = AdaBoostClassifier(DecisionTreeClassifier(max_depth=3), n_estimators=50, learning_rate = 0.03) learner = ActiveLearner(estimator=cl, query_strategy=preset_batch, X_training=X_train, y_training=y_train)
A entrada da função passa um conjunto de dados rotulado, o número de instâncias rotuladas, o número de instâncias não rotuladas, o tamanho do lote para a consulta de rótulo do lote e a profundidade máxima da árvore.
Um número especificado de instâncias rotuladas é selecionado aleatoriamente do conjunto de dados rotulado para o pré-treinamento do modelo. O resto do conjunto de dados forma uma pool a partir do qual as instâncias serão consultadas. Eu usei o AdaBoost como um classificador básico, que é semelhante ao CatBoost. Depois disso, o modelo é treinado iterativamente:
# Allow our model to query our unlabeled dataset for the most # informative points according to our query strategy (uncertainty sampling). N_QUERIES = unlabeled_size // batch_size for index in range(N_QUERIES): query_index, query_instance = learner.query(X_pool) # Teach our ActiveLearner model the record it has requested. X, y = X_pool[query_index], y_pool[query_index] learner.teach(X=X, y=y) # Remove the queried instance from the unlabeled pool. X_pool, y_pool = np.delete( X_pool, query_index, axis=0), np.delete(y_pool, query_index) # Calculate and report our model's accuracy. model_accuracy = learner.score(X_raw, y_raw) print('Accuracy after query {n}: {acc:0.4f}'.format( n=index + 1, acc=model_accuracy)) # Save our model's performance for plotting. performance_history.append(model_accuracy) print('Score for the active learning with train size: ', learner.X_training.shape)
Como tudo pode acontecer como resultado dessa aprendizagem semi supervisionada, o resultado pode ser qualquer um. No entanto, após algumas manipulações com as configurações do aprendiz, eu obtive resultados comparáveis aos do artigo anterior.
Idealmente, a precisão da classificação de um aprendiz ativo em uma pequena quantidade de dados rotulados deve exceder a precisão de um classificador semelhante com todos os dados rotulados.
>>> learned = active_learner(pr, 1000, 1000, 50) Score for the passive learning: 0.5991245668429692 with train size: 5483 Accuracy after query 1: 0.5710 Accuracy after query 2: 0.5836 Accuracy after query 3: 0.5749 Accuracy after query 4: 0.5847 Accuracy after query 5: 0.5829 Accuracy after query 6: 0.5823 Accuracy after query 7: 0.5650 Accuracy after query 8: 0.5667 Accuracy after query 9: 0.5854 Accuracy after query 10: 0.5836 Accuracy after query 11: 0.5807 Accuracy after query 12: 0.5907 Accuracy after query 13: 0.5944 Accuracy after query 14: 0.5865 Accuracy after query 15: 0.5949 Accuracy after query 16: 0.5873 Accuracy after query 17: 0.5833 Accuracy after query 18: 0.5862 Accuracy after query 19: 0.5902 Accuracy after query 20: 0.6002 Score for the active learning with train size: (2000, 8)
De acordo com o relatório, o classificador que foi treinado em todos os dados rotulados têm uma precisão menor do que o aprendiz ativo que foi treinado por apenas 2.000 instâncias. Isso provavelmente é bom.
Agora, essa amostra pode ser enviada para o modelo GMM, após o qual o classificador CatBoost pode ser treinado.
# prepare data for CatBoost
catboost_df = pd.DataFrame(learned.X_training)
catboost_df['labels'] = learned.y_training
# perform GMM clusterization over dataset
X = catboost_df.copy()
gmm = mixture.GaussianMixture(
n_components=75, max_iter=500, covariance_type='full', n_init=1).fit(X)
# sample new dataset
generated = gmm.sample(10000)
# make labels
gen = pd.DataFrame(generated[0])
gen.rename(columns={gen.columns[-1]: "labels"}, inplace=True)
gen.loc[gen['labels'] >= 0.5, 'labels'] = 1
gen.loc[gen['labels'] < 0.5, 'labels'] = 0
X = gen[gen.columns[:-1]]
y = gen[gen.columns[-1]]
pr = pd.DataFrame(X)
pr['labels'] = y
# fit CatBoost model and test it
model = fit_model(pr)
test_model(model, TEST_START, END_DATE)
Este processo pode ser repetido várias vezes, pois em cada etapa do processamento dos dados existe um elemento de incerteza que não permite a construção de modelos inequívocos. Os seguintes gráficos foram obtidos no testador após todas as iterações (período de treinamento de 1 ano seguido por um período de teste de 5 anos):
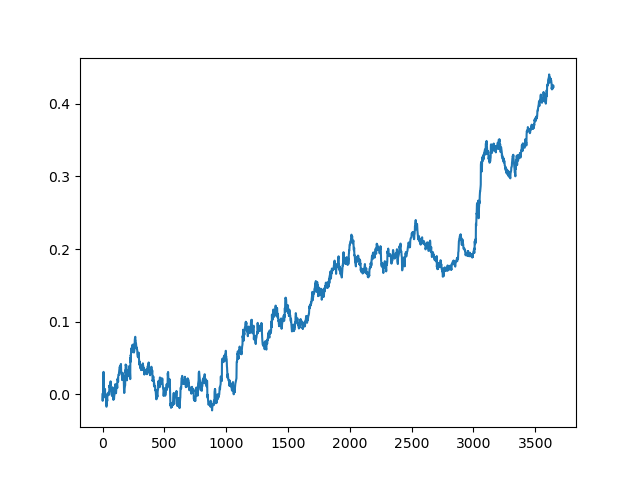
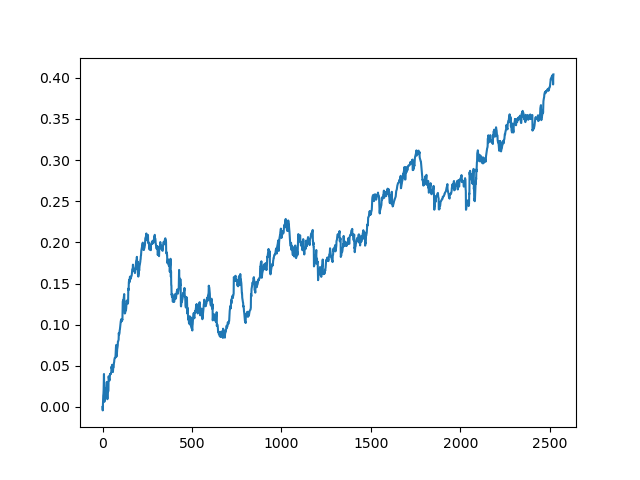
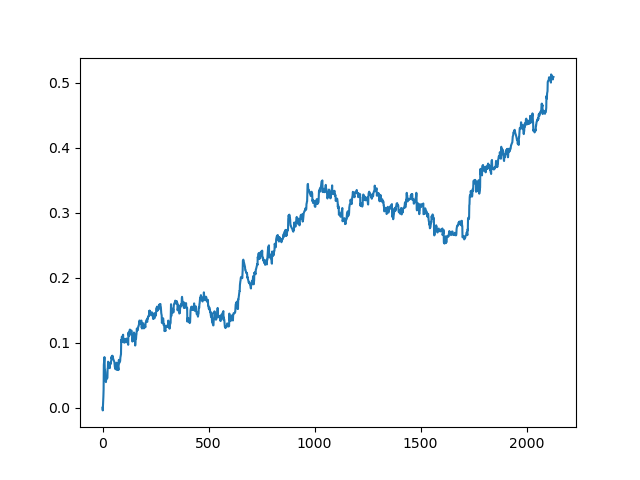
Claro, esses resultados não são benchmark, e eles apenas demonstram que modelos lucrativos (em novos dados) podem ser obtidos.
Vamos agora implementar a função de aprendizagem no comitê de classificação e ver o que acontece:
def active_learner_committee(data, learners_number, labeled_size, unlabeled_size, batch_size): X_pool = data[data.columns[1:-1]].to_numpy() y_pool = data[data.columns[-1]].to_numpy() cl = AdaBoostClassifier(DecisionTreeClassifier(max_depth=3), n_estimators=50, learning_rate = 0.05) cl.fit(X_pool, y_pool) print('Score for the passive learning: ', cl.score( X_pool, y_pool), ' with train size: ', data.shape[0]) # initializing Committee members learner_list = list() # Pre-set our batch sampling to retrieve 3 samples at a time. preset_batch = partial(uncertainty_batch_sampling, n_instances=batch_size) for member_idx in range(learners_number): # initial training data train_idx = np.random.choice(range(X_pool.shape[0]), size=labeled_size, replace=False) X_train = X_pool[train_idx] y_train = y_pool[train_idx] # creating a reduced copy of the data with the known instances removed X_pool = np.delete(X_pool, train_idx, axis=0) y_pool = np.delete(y_pool, train_idx) # initializing learner learner = ActiveLearner( estimator=AdaBoostClassifier(DecisionTreeClassifier(max_depth=2), n_estimators=50, learning_rate = 0.05), query_strategy=preset_batch, X_training=X_train, y_training=y_train ) learner_list.append(learner) # assembling the committee committee = Committee(learner_list=learner_list) unqueried_score = committee.score(X_pool, y_pool) performance_history = [unqueried_score] N_QUERIES = unlabeled_size // batch_size for idx in range(N_QUERIES): query_idx, query_instance = committee.query(X_pool) committee.teach( X=X_pool[query_idx].reshape(1, -1), y=y_pool[query_idx].reshape(1, ) ) model_accuracy = committee.score(X_pool, y_pool) performance_history.append(model_accuracy) print('Accuracy after query {n}: {acc:0.4f}'.format( n=idx + 1, acc=model_accuracy)) # remove queried instance from pool X_pool = np.delete(X_pool, query_idx, axis=0) y_pool = np.delete(y_pool, query_idx) return committee
Novamente, eu selecionei a estratégia de consulta em lote para eliminar a necessidade de treinar novamente o modelo sempre que um elemento for adicionado. Quanto ao resto, eu criei um comitê de um número arbitrário de classificadores AdaBoost (acho que não faz sentido adicionar mais de cinco classificadores, mas você pode experimentar).
Abaixo está uma pontuação de treinamento para um comitê de cinco modelos com as mesmas configurações que foram usadas para o método anterior:
>>> committee = active_learner_committee(pr, 5, 1000, 1000, 50) Score for the passive learning: 0.6533842794759825 with train size: 5496 Accuracy after query 1: 0.5927 Accuracy after query 2: 0.5818 Accuracy after query 3: 0.5668 Accuracy after query 4: 0.5862 Accuracy after query 5: 0.5874 Accuracy after query 6: 0.5906 Accuracy after query 7: 0.5918 Accuracy after query 8: 0.5910 Accuracy after query 9: 0.5820 Accuracy after query 10: 0.5934 Accuracy after query 11: 0.5864 Accuracy after query 12: 0.5753 Accuracy after query 13: 0.5868 Accuracy after query 14: 0.5921 Accuracy after query 15: 0.5809 Accuracy after query 16: 0.5842 Accuracy after query 17: 0.5833 Accuracy after query 18: 0.5783 Accuracy after query 19: 0.5732 Accuracy after query 20: 0.5828
Os resultados do comitê de aprendiz ativos não são tão bons quanto os de um aprendiz passivo. É impossível adivinhar as razões. Talvez esta seja apenas um resultado aleatório. Em seguida, eu executei o conjunto de dados resultante várias vezes usando o mesmo princípio e obtive os seguintes resultados aleatórios:
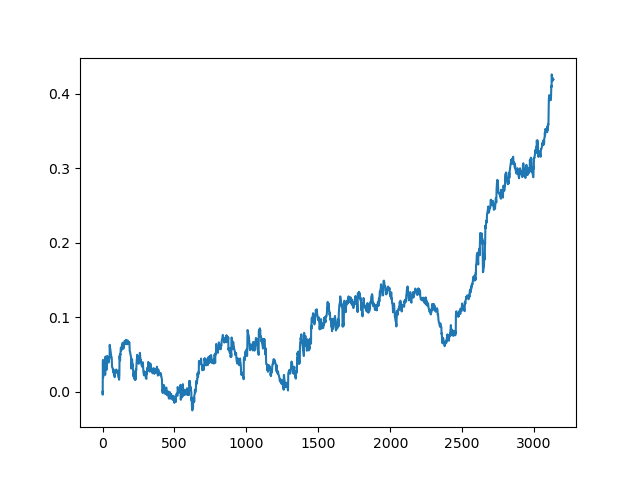
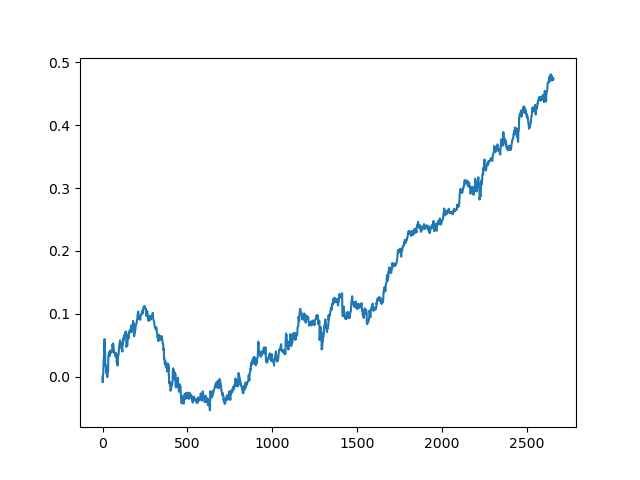
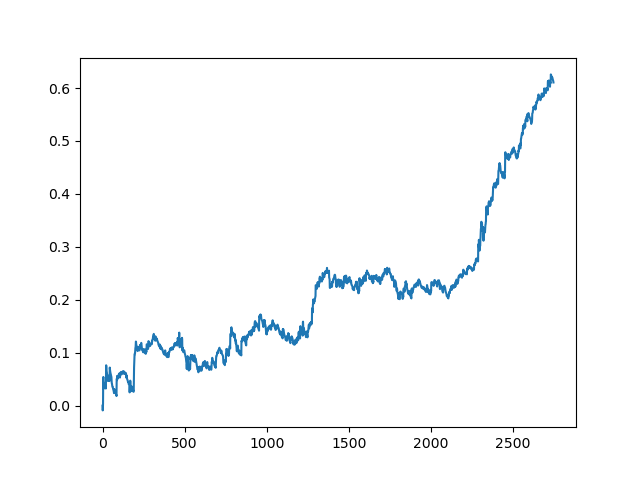
Conclusões
Neste artigo, nós consideramos o aprendizado ativo. A impressão não é clara. Por um lado, é sempre tentador aprender com um pequeno número de instâncias, e esses modelos funcionam bem para alguns problemas de classificação. No entanto, isso ainda está longe de ser inteligência artificial. Esse modelo não pode encontrar padrões estáveis entre os dados de lixo e requer uma preparação mais completa de recursos e rótulos, incluindo a preparação dos dados com base em rótulos de especialistas. Eu não vi nenhum aumento significativo na qualidade dos modelos. Ao mesmo tempo, a intensidade de trabalho e o tempo necessário para treinar os modelos aumentaram, o que é um fator negativo. Eu gosto da filosofia do aprendizado ativo e da utilização das características do pensamento humano. O arquivo anexo fornece todas as funções discutidas. Você pode explorar ainda mais esses modelos e tentar aplicá-los de alguma outra forma original.