Einen handelnden Expert Advisor von Grund auf neu entwickeln (Teil 15): Zugang zu Daten im Internet (I)
Daniel Jose | 25 Juli, 2022
Einführung
MetaTrader 5 ist die vielseitigste und umfassendste Plattform, die sich ein Händler wünschen kann. Trotz anderer Meinungen ist die Plattform äußerst effektiv und leistungsfähig, da sie Möglichkeiten bietet, die weit über eine einfache Beobachtung des gezeichneten Charts hinausgehen, mit Kauf- und Verkaufsoperationen in Echtzeit.
All diese Leistung ergibt sich aus der Tatsache, dass die Plattform eine Sprache verwendet, die der leistungsstärksten derzeit existierenden Sprache fast ebenbürtig ist - wir sprechen von C/C ++. Die Möglichkeiten, die uns diese Sprache bietet, gehen weit über das hinaus, was ein normaler Händler ohne Programmierkenntnisse leisten oder verstehen kann.
Während unserer Tätigkeit auf dem Markt müssen wir in irgendeiner Weise mit verschiedenen Themen auf globaler Ebene verbunden sein. Wir können uns nicht nur auf das Chart beschränken - es ist wichtig, auch andere Informationen zu berücksichtigen, die nicht weniger relevant sind und den Unterschied zwischen Gewinn und Verlust bei einem Handel ausmachen können.
Es gibt viele Webseiten und Orte im Internet, die eine riesige Menge an Informationen bieten. Sie müssen nur wissen, wo Sie suchen und wie Sie diese Informationen am besten nutzen können. Und je besser man im richtigen Zeitraum informiert ist, desto besser ist es für den Handel. Wenn Sie jedoch einen Browser verwenden, egal welchen, werden Sie feststellen, dass es sehr schwierig ist, bestimmte Informationen gut zu filtern, dass Sie gezwungen sind, auf viele Bildschirme und Monitore zu schauen, und dass es letztendlich unmöglich ist, die Informationen zu nutzen, obwohl sie vorhanden sind.
Aber dank MQL5, das C/C++ sehr ähnlich ist, können Programmierer mehr tun, als nur mit einem Chart zu arbeiten: Wir können Daten im Web suchen, filtern, analysieren und somit Operationen auf eine viel konsistentere Weise durchführen als die meisten Händler, weil wir die gesamte Rechenleistung zu unseren Gunsten nutzen werden.
1.0. Planung
Einen Plan zu haben ist entscheidend. Zunächst müssen Sie herausfinden, woher Sie die Informationen bekommen, die Sie verwenden wollen. Dabei sollte man viel sorgfältiger vorgehen, als es den Anschein hat, denn eine gute Informationsquelle wird uns die richtige Richtung weisen. Jeder sollte diesen Schritt individuell durchführen, da jeder Händler bestimmte Daten zu unterschiedlichen Zeitpunkten benötigt.
Unabhängig von der von Ihnen gewählten Quelle ist das, was wir als Nächstes tun werden, im Grunde für alle gleich, sodass dieser Artikel als Studienmaterial für diejenigen dienen kann, die die Methode und die Werkzeuge verwenden möchten, die nur mit MQL5, ohne ein externes Programm, zur Verfügung stehen.
Zur Veranschaulichung des gesamten Prozesses werden wir eine Webseite mit Marktinformationen verwenden, um zu zeigen, wie das Ganze funktioniert. Wir werden alle Schritte des Prozesses durchgehen, und Sie werden in der Lage sein, diese Methode zu nutzen und sie an Ihre speziellen Bedürfnisse anzupassen.
1.0.1. Entwicklung eines Erfassungsprogramms
Um mit den Daten arbeiten zu können, müssen wir ein kleines Programm erstellen, um Daten zu sammeln und sie effizient und genau analysieren zu können. Zu diesem Zweck werden wir ein sehr einfaches Programm verwenden, das im Folgenden gezeigt wird:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { Print(GetDataURL("https://tradingeconomics.com/stocks")); } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 750) { string headers; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; if ((handle = FileOpen("url.txt", FILE_WRITE | FILE_BIN)) != INVALID_HANDLE) { FileWriteArray(handle, charResultPage, 0, ArraySize(charResultPage)); FileClose(handle); }else return "Error saving file ..."; return "File saved successfully..."; }
Dieses Programm ist extrem einfach, nichts könnte einfacher sein.
Wir gehen folgendermaßen vor: In dem hervorgehobenen Teil geben wir die Website an, von der wir Informationen erhalten möchten. Warum benutzen wir ihn und nicht den Browser? Nun, es stimmt, dass wir Informationen im Browser erfassen können, aber wir werden ihn nutzen, um nach dem Herunterladen der Daten Informationen zu finden.
Aber es nützt nichts, dieses Programm nur abzutippen und zu kompilieren. Es gibt noch etwas, das Sie tun sollten, sonst wird es nicht funktionieren.
In der MetaTrader-Plattform müssen wir, bevor wir dieses Skript ausführen, der Plattform erlauben, Daten von der gewünschten Website zu empfangen. Um dies nicht jedes Mal tun zu müssen, wenn Sie die MetaTrader-Plattform installieren müssen, können Sie eine Sicherungskopie dieser Daten speichern, nachdem Sie alles eingerichtet haben. Die Datei sollte unter dem folgenden Pfad gespeichert werden:
C:\Users\< USER NAME >\AppData\Roaming\MetaQuotes\Terminal\< CODE PERSONAL >\config\common.ini
USER NAME ist Ihr Nutzername im Betriebssystem. CODE PERSONAL ist der Wert, den die Plattform bei der Installation erstellt. So können Sie die Datei leicht finden, um ein Backup zu erstellen oder nach einer Neuinstallation zu ersetzen. Nur ein Punkt: Dieser Ort gehört zum WINDOWS-System.
Kehren wir nun zu dem Skript zurück, das wir erstellt haben. Wenn Sie es ohne vorherige Einrichtung verwenden, wird in der Nachrichtenbox Folgendes angezeigt.
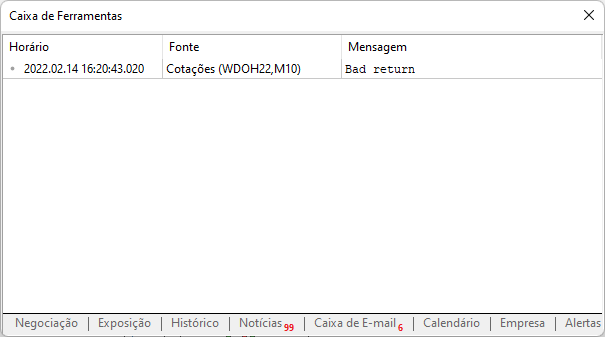
Diese Meldung wurde angezeigt, weil wir die Website in der MetaTrader-Plattform nicht zugelassen haben. Dies sollte wie in der nachstehenden Abbildung dargestellt erfolgen. Achten Sie darauf, was hinzugefügt wurde. Beachten Sie, dass es sich um die Stammadresse der Website handelt, auf die wir über die MetaTrader-Handelsplattform zugreifen werden.
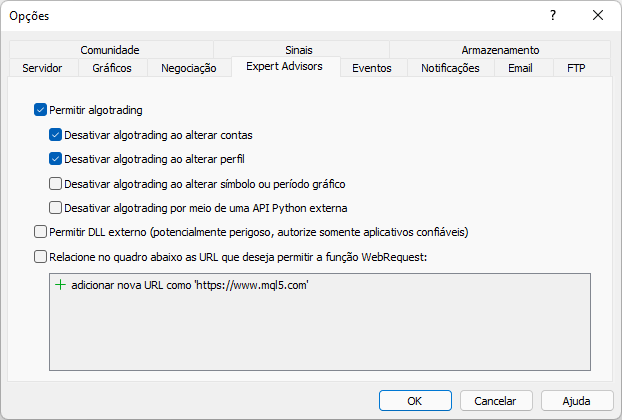

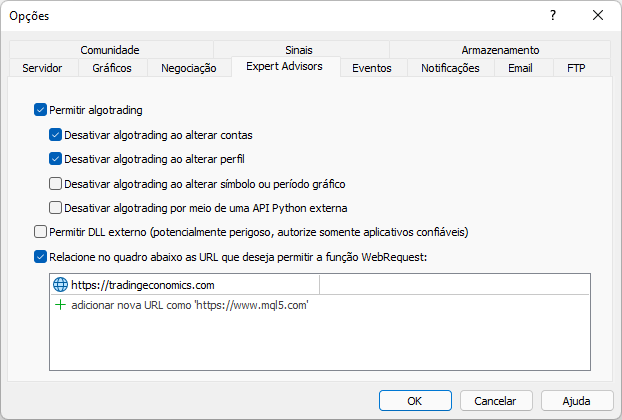
Wenn wir nun dasselbe Skript noch einmal ausführen, sehen wir die folgende Ausgabe, die von der Plattform gemeldet wird:
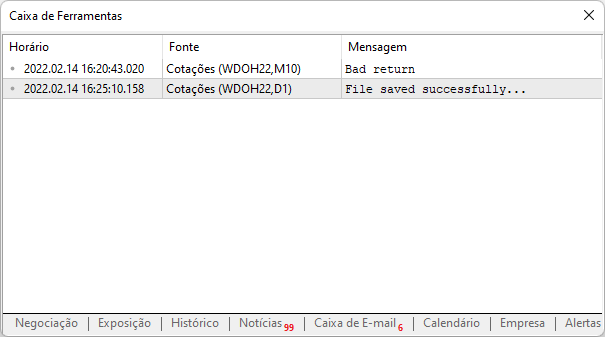
Das bedeutet, dass der Zugriff auf die Website erfolgreich war, die Daten auf Ihren Computer heruntergeladen wurden und Sie sie nun auswerten können. Ein wichtiges Detail ist, dass wir uns nun nicht mehr darum kümmern müssen, dieselbe Website erneut zur Plattform hinzuzufügen, vorausgesetzt natürlich, dass Sie eine Sicherungskopie dieser Datei unter dem oben angegebenen Pfad erstellen.
Um zu verstehen, wie alles funktioniert und um genauere Informationen zu erhalten, können Sie sich die Funktion WebRequest in der Dokumentation ansehen. Wenn Sie noch tiefer in das Netzwerk-Kommunikationsprotokoll eindringen wollen, empfehle ich Ihnen, einen Blick auf andere Netzwerkfunktionen zu werfen, die in MQL5 vorgestellt werden. Die Kenntnis solcher Funktionen kann Ihnen manchmal eine Menge Ärger ersparen.
Der erste Teil der Arbeit ist getan - wir haben die Daten vom gewünschten Standort heruntergeladen. Nun müssen wir den nächsten Schritt tun, der nicht weniger wichtig ist.
1.0.2. Suche nach Daten
Für diejenigen, die nicht wissen, wie man auf einer Website nach den von der MetaTrader 5-Plattform zu erfassenden Daten sucht, habe ich ein kurzes Video gedreht, in dem ich schnell zeige, wie man bei dieser Suche vorgeht.
Es ist wichtig, dass Sie wissen, wie Sie mit Ihrem Browser den Code der Website, von der Sie die Daten abrufen wollen, analysieren können. Das ist nicht schwer, da der Browser selbst bei dieser Aufgabe sehr hilfreich ist. Aber das ist etwas, das man lernen muss. Wenn Sie erst einmal wissen, wie es geht, werden sich Ihnen viele Möglichkeiten eröffnen.
Ich werde Chrome für die Suche verwenden, aber Sie können auch jeden anderen Browser verwenden, der den Zugriff auf den Code mit Hilfe der Entwicklerwerkzeuge ermöglicht.
Wir sind daran interessiert, Daten von diesem unten gezeigten Block zu erhalten, der derselbe Block ist, nach dem ich im obigen Video gesucht habe. Es ist wirklich wichtig zu wissen, wie man mit dem Browser nach Dingen sucht, sonst würde man sich in all den heruntergeladenen Informationen verlieren.
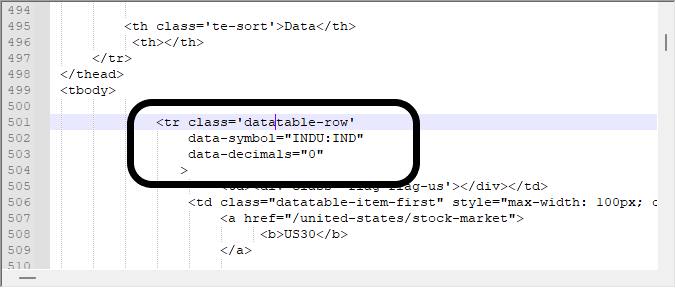
In manchen Fällen reicht es jedoch nicht aus, die Daten auf diese Weise zu betrachten. Wir müssen auf einen Hex-Editor zurückgreifen, um genau zu wissen, womit wir es zu tun haben. Es stimmt, dass die Datenmodellierung in einigen Fällen relativ einfach ist, aber in anderen Fällen kann sie viel komplexer sein - wenn die Daten Bilder, Links und andere Dinge enthalten. Solche Dinge können die Suche erschweren, da sie in der Regel falsch positive Ergebnisse liefern, sodass wir wissen müssen, womit wir es zu tun haben. Wenn wir dieselben Daten in einem Hex-Editor suchen, erhalten wir die folgenden Werte.
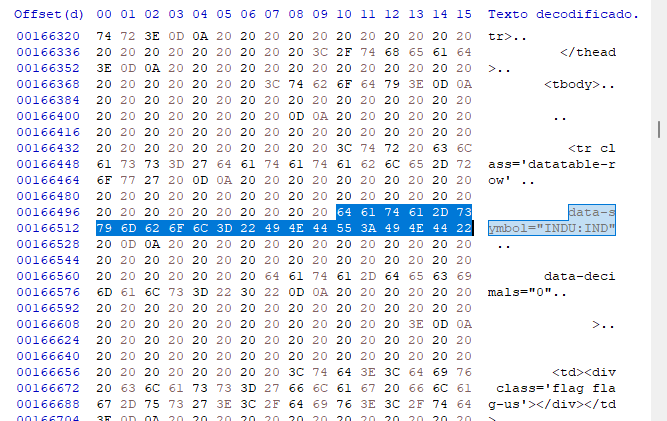
Wir sind in diesem ersten Schritt nicht an den Offsets interessiert, da sie sich bei dynamischen Seiten ändern können, aber wir sind daran interessiert, welche Art der Modellierung verwendet wird. In diesem Fall ist es sehr klar, und wir können ein Suchsystem verwenden, das auf dieser Art von Informationen basiert, die hier im Hex-Editor gefunden werden. Das macht die Suche durch unser Programm etwas einfacher, auch wenn es im ersten Moment kein effizientes System ist. Unsere Suchdatenbank ist leichter zugänglich - wir verwenden Eingaben und verzichten auf zusätzliche Zeichen, wie CARRIAGE oder RETURN, die uns eher behindern als helfen. Der Programmcode lautet also wie folgt.
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks")); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout = 100) { string headers, szInfo; char post[], charResultPage[]; int handle; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; szInfo = ""; for (int c0 = 0, c1 = ArraySize(charResultPage); c0 < c1; c0++) szInfo += CharToString(charResultPage[c0]); if ((handle = StringFind(szInfo, "data-symbol=\"INDU:IND\"", 0)) >= 0) { handle = StringFind(szInfo, "<td id=\"p\" class=\"datatable-item\">", handle); for(; charResultPage[handle] != 0x0A; handle++); for(handle++; charResultPage[handle] != 0x0A; handle++); szInfo = ""; for(handle++; charResultPage[handle] == 0x20; handle++); for(; (charResultPage[handle] != 0x0D) && (charResultPage[handle] != 0x20); handle++) szInfo += CharToString(charResultPage[handle]); } return szInfo; }
Die Idee des Skripts ist es, den Wert auf der Seite zu erfassen. Der Vorteil der oben gezeigten Methode ist, dass wir die Information auch dann noch unter all diesen Befehlen finden können, wenn sich ihre Position aufgrund eines Versatzes ändert. Aber auch wenn alles ideal zu sein scheint, gibt es eine kleine Verzögerung in den Informationen, sodass es notwendig ist, zu messen, wie Sie mit den erfassten Daten arbeiten werden, wenn das obige Skript ausgeführt wird. Das Ergebnis der Ausführung ist unten zu sehen.
Ich empfehle Ihnen, Ihre eigene Analyse durchzuführen und zu sehen, wie die Informationen aufgezeichnet werden, denn es ist wichtig, die Details zu kennen, die sich nicht so einfach in Textform beschreiben lassen: Man muss sie sehen, um zu verstehen.
Lassen Sie uns nun über Folgendes nachdenken. Das obige Skript ist in Bezug auf die Ausführung nicht sehr effizient, da es einige Manipulationen vornimmt, die bei der Verwendung einer Seite mit einem statischen Modell nicht notwendig sind. Sie wird jedoch bei dynamischen Inhalten verwendet, wie im Fall der von uns betrachteten Seite. In diesem speziellen Fall können wir den Offset nutzen, um schneller zu parsen und damit die Daten etwas effizienter zu erfassen. Denken Sie aber daran, dass das System Informationen für einige Sekunden im Cache speichern kann. Daher können die erfassten Informationen im Vergleich zu den im Browser beobachteten Daten veraltet sein. In diesem Fall müssen einige interne Anpassungen im System vorgenommen werden, um dies zu beheben. Aber das ist nicht der Zweck dieses Artikels.
Wenn wir also das obige Skript so ändern, dass es einen Offset für die Suche verwendet, erhalten wir den folgenden Code, der unten in voller Länge gezeigt wird:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1) return "Bad return"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo; }
Das Ergebnis der Skriptausführung ist weiter zu sehen. Es gibt keine Änderungen im Blog, es ist lediglich eine Frage der Berechnungszeit, die durch die Anwendung des Offsetmodells reduziert wird. All dies führt zu einer leichten Verbesserung der Gesamtleistung des Systems.
Bitte beachten Sie, dass der obige Code nur funktionierte, weil die Seite ein statisches Modell hatte: Obwohl sich der Inhalt dynamisch veränderte, änderte sich das Design nicht. Wir können also einen Hex-Editor verwenden, die Position der Informationen nachschlagen, die Offset-Werte abrufen und sofort zu diesen Positionen navigieren. Um aber eine gewisse Garantie zu haben, dass die Offsets noch gültig sind, führen wir einen einfachen Test durch, der in der folgenden Zeile durchgeführt wird:
for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error in Position";
Das ist etwas sehr Einfaches, aber notwendig, damit wir ein Mindestmaß an Sicherheit in Bezug auf die Informationen haben, die auf der Grundlage des Offsets erfasst werden. Dazu müssen wir die Seite analysieren und prüfen, ob es möglich ist, die Offset-Methode zur Datenerfassung zu verwenden. Wenn dies möglich ist, profitieren Sie von einer kürzeren Bearbeitungszeit.
1.0.3. Ein zu lösendes Problem
Obwohl das System oft sehr gut funktioniert, kann es vorkommen, dass wir die folgende Antwort vom Server erhalten:
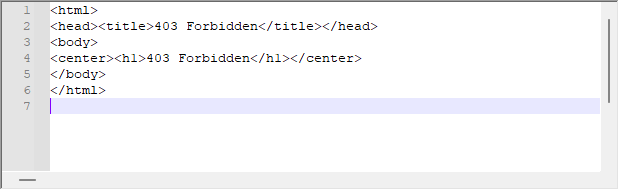
Dies ist die Antwort des Servers auf unsere Anfrage. Auch wenn WebRequest auf der Plattformseite keinen Fehler anzeigt, kann der Server diese Meldung zurückgeben. In diesem Fall sollten wir die Kopfzeile der Rückmeldung analysieren, um das Problem zu verstehen. Um dieses Problem zu lösen, sind kleine Änderungen im Offset-Skript erforderlich, die unten zu sehen sind:
#property copyright "Daniel Jose" #property version "1.00" //+------------------------------------------------------------------+ void OnStart() { while (!IsStopped()) { Print(GetDataURL("https://tradingeconomics.com/stocks", 100, "<!doctype html>", 2, "INDU:IND", 172783, 173474, 0x0D)); Sleep(200); } } //+------------------------------------------------------------------+ string GetDataURL(const string url, const int timeout, const string szTest, int iTest, const string szFind, int iPos, int iInfo, char cLimit) { string headers, szInfo = ""; char post[], charResultPage[]; int counter; if (WebRequest("GET", url, NULL, NULL, timeout, post, 0, charResultPage, headers) == -1 return "Bad"; for (int c0 = 0, c1 = StringLen(szTest); c0 < c1; c0++) if (szTest[c0] != charResultPage[iTest + c0]) return "Failed"; for (int c0 = 0, c1 = StringLen(szFind); c0 < c1; c0++) if (szFind[c0] != charResultPage[iPos + c0]) return "Error"; for (counter = 0; charResultPage[counter + iInfo] == 0x20; counter++); for (;charResultPage[counter + iInfo] != cLimit; counter++) szInfo += CharToString(charResultPage[counter + iInfo]); return szInfo;
Der Test, der in der hervorgehobenen Zeile durchgeführt wird, ist derjenige, der den Test durchführt, denn wenn die vom Server zurückgegebene Nachricht komplexer ist, garantiert uns die bloße Tatsache der Durchführung dieses Tests bereits eine gute Sicherheitsmarge für die Daten, die wir analysieren, um die Analyse von Phantomdaten oder Speichermüll zu vermeiden, wenn das System den ersten Test besteht, der bereits im vorherigen Code vorhanden war. Auch wenn dies nur selten vorkommt, sollten wir die Wahrscheinlichkeit nicht unterschätzen, dass es dazu kommt.
Sie können unten sehen, dass das Ergebnis nicht anders ist, was bedeutet, dass das System wie erwartet funktioniert.
Bis jetzt haben wir noch nicht viel gemacht - wir lesen nur Werte von einer Webseite ab, und das ist nicht sehr nützlich, obwohl es recht interessant ist, zu wissen und zu sehen, wie es gemacht wird. Es ist jedoch nicht sehr nützlich für diejenigen, die tatsächlich auf der Grundlage der Informationen handeln wollen, die Sie von nun an modellieren werden, da Sie sie erfassen und auf andere Weise darstellen. Wir müssen also etwas tun, damit es in einem breiteren System einen Sinn ergibt. Allerdings werden wir diese erfassten Informationen in einen EA übernehmen, auf diese Weise werden wir in der Lage sein, noch beeindruckendere Dinge zu tun und das macht MetaTrader 5 zu einer sensationellen Plattform.
Schlussfolgerung
Nun, das ist noch nicht das Ende. Im nächsten Artikel werde ich zeigen, wie man diese auf dem WEB gesammelten Informationen in den EA übernimmt, und das wird wirklich beeindruckend sein: wir werden sehr wenig erforschte Ressourcen innerhalb der MetaTrader-Plattform nutzen müssen. Verpassen Sie also nicht den nächsten Artikel in dieser Reihe.
Alle in dem Artikel verwendeten Codes sind unten angefügt.