The Group Method of Data Handling: Implementing the Combinatorial Algorithm in MQL5

Introduction
The combinatorial algorithm of the GMDH, often referred to as COMBI, is the basic form of GMDH and serves as a foundation for more complex algorithms within the family. Just like Multilayered Iterative Algorithm (MIA), it operates on an input data sample represented as a matrix containing observations over a set of variables. The data sample is divided into two parts: a training sample and a test sample. The training subsample is used to estimate the coefficients of the polynomial, while the test subsample is used to select the structure of the optimal model based on the minimal value of the selected criterion. In this article we will describe the computation of the COMBI algorithm. As well as present its implementation in MQL5 by extending the "GmdhModel" class described in the previous article. Later on we will also discuss the closely related Combinatorial Selective aglorithm and its MQL5 implementation. And finally conclude by providing a practical application of GMDH algorithms, by building predictive models of the Bitcoin daily price.
The COMBI algorithm
The fundamental difference between MIA and COMBI lies in their network structure. In contrast to the multilayered nature of MIA, the COMBI is characterised by a single layer.

The number of nodes in this layer is determined by the number of inputs. Where each node represents a candidate model defined by one or more of all the inputs. To illustrate, lets consider an example of a system we want to model, defined by 2 input variables. Applying the COMBI algorithm, all possible combinations of these variables are used to construct a candidate model. The number of possible combinations is given by:

where :
- m represents the number of input variables.
For each of these combinations a candidate model is generated. The candidate models evaluated at the nodes of the first and only layer are given by:

where :
- 'a' are the coefficients , 'a1' is the first coefficient and 'a2' is the second.
- 'x' are the input variables, 'x1' representing the first input variable or predictor and 'x2' is the second.
The process involves solving a system of linear equations to derive estimates for the coefficients of a candidate model. Performance criteria of each model are used to select the final model that best describes the data.
COMBI MQL5 implementation
The code that implements the COMBI algorithm relies on the GmdhModel base class described in the previous article. It also depends on an intermediary class LinearModel, declared in linearmodel.mqh. Which encapsulates the most fundamental distinguishing characteristic of the COMBI method. The fact that COMBI models are exclusively linear.
//+------------------------------------------------------------------+ //| linearmodel.mqh | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #include "gmdh.mqh" //+------------------------------------------------------------------+ //| Class implementing the general logic of GMDH linear algorithms | //+------------------------------------------------------------------+ class LinearModel:public GmdhModel { protected: vector calculatePrediction(vector& x) { if(x.Size()<ulong(inputColsNumber)) return vector::Zeros(ulong(inputColsNumber)); matrix modifiedX(1,x.Size()+ 1); modifiedX.Row(x,0); modifiedX[0][x.Size()] = 1.0; vector comb = bestCombinations[0][0].combination(); matrix xx(1,comb.Size()); for(ulong i = 0; i<xx.Cols(); ++i) xx[0][i] = modifiedX[0][ulong(comb[i])]; vector c,b; c = bestCombinations[0][0].bestCoeffs(); b = xx.MatMul(c); return b; } virtual matrix xDataForCombination(matrix& x, vector& comb) override { matrix out(x.Rows(), comb.Size()); for(ulong i = 0; i<out.Cols(); i++) out.Col(x.Col(int(comb[i])),i); return out; } virtual string getPolynomialPrefix(int levelIndex, int combIndex) override { return "y="; } virtual string getPolynomialVariable(int levelIndex, int coeffIndex, int coeffsNumber, vector& bestColsIndexes) override { return ((coeffIndex != coeffsNumber - 1) ? "x" + string(int(bestColsIndexes[coeffIndex]) + 1) : ""); } public: LinearModel(void) { } vector predict(vector& x, int lags) override { if(lags <= 0) { Print(__FUNCTION__," lags value must be a positive integer"); return vector::Zeros(1); } if(!training_complete) { Print(__FUNCTION__," model was not successfully trained"); return vector::Zeros(1); } vector expandedX = vector::Zeros(x.Size() + ulong(lags)); for(ulong i = 0; i<x.Size(); i++) expandedX[i]=x[i]; for(int i = 0; i < lags; ++i) { vector vect(x.Size(),slice,expandedX,ulong(i),x.Size()+ulong(i)-1); vector res = calculatePrediction(vect); expandedX[x.Size() + i] = res[0]; } vector vect(ulong(lags),slice,expandedX,x.Size()); return vect; } }; //+------------------------------------------------------------------+
The file combi.mqh contains the definition of the COMBI class. It inherits from LinearModel and defines the "fit()" methods for fitting a model.
//+------------------------------------------------------------------+ //| combi.mqh | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #include "linearmodel.mqh" //+------------------------------------------------------------------+ //| Class implementing combinatorial COMBI algorithm | //+------------------------------------------------------------------+ class COMBI:public LinearModel { private: Combination getBest(CVector &combinations) { double proxys[]; int best[]; ArrayResize(best,combinations.size()); ArrayResize(proxys,combinations.size()); for(int k = 0; k<combinations.size(); k++) { best[k]=k; proxys[k]=combinations[k].evaluation(); } MathQuickSortAscending(proxys,best,0,int(proxys.Size()-1)); return combinations[best[0]]; } protected: virtual void removeExtraCombinations(void) override { CVector2d realBestCombinations; CVector n; Combination top; for(int i = 0 ; i<bestCombinations.size(); i++) { top = getBest(bestCombinations[i]); n.push_back(top); } top = getBest(n); CVector sorted; sorted.push_back(top); realBestCombinations.push_back(sorted); bestCombinations = realBestCombinations; } virtual bool preparations(SplittedData &data, CVector &_bestCombinations) override { lastLevelEvaluation = DBL_MAX; return (bestCombinations.push_back(_bestCombinations) && ulong(level+1) < data.xTrain.Cols()); } void generateCombinations(int n_cols,vector &out[]) override { GmdhModel::nChooseK(n_cols,level,out); return; } public: COMBI(void):LinearModel() { modelName = "COMBI"; } bool fit(vector &time_series,int lags,double testsize=0.5,CriterionType criterion=stab) { if(lags < 1) { Print(__FUNCTION__," lags must be >= 1"); return false; } PairMVXd transformed = timeSeriesTransformation(time_series,lags); SplittedData splited = splitData(transformed.first,transformed.second,testsize); Criterion criter(criterion); int pAverage = 1; double limit = 0; int kBest = pAverage; if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } bool fit(matrix &vars,vector &targets,double testsize=0.5,CriterionType criterion=stab) { if(vars.Cols() < 1) { Print(__FUNCTION__," columns in vars must be >= 1"); return false; } if(vars.Rows() != targets.Size()) { Print(__FUNCTION__, " vars dimensions donot correspond with targets"); return false; } SplittedData splited = splitData(vars,targets,testsize); Criterion criter(criterion); int pAverage = 1; double limit = 0; int kBest = pAverage; if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } }; //+------------------------------------------------------------------+
Using the COMBI class
Fitting a model to a dataset using the COMBI class is exactly the same as applying the MIA class. We create an instance and call one of the "fit()" methods. This is demonstrated in the scripts COMBI_test.mq5 and COMBI_Multivariable_test.mq5.
//+------------------------------------------------------------------+ //| COMBI_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\combi.mqh> input int NumLags = 2; input int NumPredictions = 6; input CriterionType critType = stab; input double DataSplitSize = 0.33; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- vector tms = {1,2,3,4,5,6,7,8,9,10,11,12}; if(NumPredictions<1) { Alert("Invalid setting for NumPredictions, has to be larger than 0"); return; } COMBI combi; if(!combi.fit(tms,NumLags,DataSplitSize,critType)) return; string modelname = combi.getModelName()+"_"+EnumToString(critType)+"_"+string(DataSplitSize); combi.save(modelname+".json"); vector in(ulong(NumLags),slice,tms,tms.Size()-ulong(NumLags)); vector out = combi.predict(in,NumPredictions); Print(modelname, " predictions ", out); Print(combi.getBestPolynomial()); } //+------------------------------------------------------------------+
Both apply the COMBI algorithm to the same datasets used in the example scripts demonstrating how to apply the MIA algorithm from a previous article.
//+------------------------------------------------------------------+ //| COMBI_Multivariable_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\combi.mqh> input CriterionType critType = stab; input double DataSplitSize = 0.33; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- matrix independent = {{1,2,3},{3,2,1},{1,4,2},{1,1,3},{5,3,1},{3,1,9}}; vector dependent = {6,6,7,5,9,13}; COMBI combi; if(!combi.fit(independent,dependent,DataSplitSize,critType)) return; string modelname = combi.getModelName()+"_"+EnumToString(critType)+"_"+string(DataSplitSize)+"_multivars"; combi.save(modelname+".json"); matrix unseen = {{8,6,4},{1,5,3},{9,-5,3}}; for(ulong row = 0; row<unseen.Rows(); row++) { vector in = unseen.Row(row); Print("inputs ", in, " prediction ", combi.predict(in,1)); } Print(combi.getBestPolynomial()); } //+------------------------------------------------------------------+
Looking at the output of COMBI_test.mq5 we can compare the complexity of the fitted polynomial with the one produced by the MIA algorithm. Below are the polynomial for the timeseries and multivariable dataset respectively.
LR 0 14:54:15.354 COMBI_test (BTCUSD,D1) COMBI_stab_0.33 predictions [13,14,15,16,17,18.00000000000001] PN 0 14:54:15.355 COMBI_test (BTCUSD,D1) y= 1.000000e+00*x1 + 2.000000e+00 CI 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) inputs [8,6,4] prediction [18.00000000000001] QD 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) inputs [1,5,3] prediction [9] QQ 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) inputs [9,-5,3] prediction [7.00000000000001] MM 0 14:54:29.864 COMBI_Multivariable_test (BTCUSD,D1) y= 1.000000e+00*x1 + 1.000000e+00*x2 + 1.000000e+00*x3 - 7.330836e-15
Next are the polynomials revealed by the MIA method.
JQ 0 14:43:07.969 MIA_Test (Step Index 500,M1) MIA_stab_0.33_1_0.0 predictions [13.00000000000001,14.00000000000002,15.00000000000004,16.00000000000005,17.0000000000001,18.0000000000001] IP 0 14:43:07.969 MIA_Test (Step Index 500,M1) y = - 9.340179e-01*x1 + 1.934018e+00*x2 + 3.865363e-16*x1*x2 + 1.065982e+00 II 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) inputs [1,2,4] prediction [6.999999999999998] CF 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) inputs [1,5,3] prediction [8.999999999999998] JR 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) inputs [9,1,3] prediction [13.00000000000001] NP 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f1_1 = 1.071429e-01*x1 + 6.428571e-01*x2 + 4.392857e+00 LR 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f1_2 = 6.086957e-01*x2 - 8.695652e-02*x3 + 4.826087e+00 ME 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f1_3 = - 1.250000e+00*x1 - 1.500000e+00*x3 + 1.125000e+01 DJ 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) IP 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f2_1 = 1.555556e+00*f1_1 - 6.666667e-01*f1_3 + 6.666667e-01 ER 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f2_2 = 1.620805e+00*f1_2 - 7.382550e-01*f1_3 + 7.046980e-01 ES 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f2_3 = 3.019608e+00*f1_1 - 2.029412e+00*f1_2 + 5.882353e-02 NH 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) CN 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f3_1 = 1.000000e+00*f2_1 - 3.731079e-15*f2_3 + 1.155175e-14 GP 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) f3_2 = 8.342665e-01*f2_2 + 1.713326e-01*f2_3 - 3.359462e-02 DO 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) OG 0 14:52:59.698 MIA_Multivariable_test (BTCUSD,D1) y = 1.000000e+00*f3_1 + 3.122149e-16*f3_2 - 1.899249e-15
The MIA model is convoluted whereas the COMBI model is less complicated much like the series itself. A reflection of the linear nature of the method. This is also confirmed from the output of the script COMBI_Multivariable_test.mq5, which represents an attempt to build a model for summing 3 numbers together by providing input variables and corresponding output examples. Here the COMBI algorithm was able to deduce the underlying characteristics of the system successfully.
The exhaustive search of the COMBI algorithm is both and advantage and also a disadvantage. On the positive side, evaluating all combinations of the inputs ensures that the optimal polynomial that describes the data is found. Though, if there are numerous input variables, this extensive search can become computationally expensive. Possibly resulting in long training times. Recall, that the number of candidate models is given by 2 raised to the power m all less 1, the larger m is the greater the number of candidate models that need to be evaluated. The Combinatorial Selective algorithm was developed to address this problem.
The Combinatorial Selective Algorithm
The Combinatorial Selective algorithm, which we will refer to as MULTI, is billed as an improvement of the COMBI method, in terms of efficiency. An exhaustive search is avoided by employing procedures similar to those used in multilayered algorithms of the GMDH. Therefore, it can be viewed as a multilayered approach to the otherwise single layered nature of the COMBI algorithm.

In the first layer , all models containing one of the input variables are estimated, with the best being selected as per the external criteria and passed on to the next layer. In subsequent layers, different input variables are selected and added to these candidate models, with the hope of improving them. New layers are added in this manner depending on whether there is any increase in accuracy in estimating the outputs and/or , on the availability of input variables not already part of a candidate model. This means that the maximum number of possible layers coincides with the total number of input variables.
Evaluating candidate models in this manner often leads to the avoidance of an exhaustive search, but it also introduces a problem. There is the possibility that the algorithm may not find the optimal polynomial that best describes the dataset. An indication that more candidate models should have been considered at the training stage. Deducing the optimal polynomial becomes a matter of careful hyperparameter tuning. Particularly, the number of candidate models that are evaluated at each layer.
Implementing the Combinatorial Selective algorithm
Implementation of the combinatorial selective algorithm is provided in multi.mqh. It contains the definition of the MULTI class, which inherits from LinearModel.
//+------------------------------------------------------------------+ //| multi.mqh | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #include "linearmodel.mqh" //+------------------------------------------------------------------+ //| Class implementing combinatorial selection MULTI algorithm | //+------------------------------------------------------------------+ class MULTI : public LinearModel { protected: virtual void removeExtraCombinations(void) override { CVector2d realBestCombinations; CVector n; n.push_back(bestCombinations[0][0]); realBestCombinations.push_back(n); bestCombinations = realBestCombinations; } virtual bool preparations(SplittedData &data, CVector &_bestCombinations) override { return (bestCombinations.setAt(0,_bestCombinations) && ulong(level+1) < data.xTrain.Cols()); } void generateCombinations(int n_cols,vector &out[]) override { if(level == 1) { nChooseK(n_cols,level,out); return; } for(int i = 0; i<bestCombinations[0].size(); i++) { for(int z = 0; z<n_cols; z++) { vector comb = bestCombinations[0][i].combination(); double array[]; vecToArray(comb,array); int found = ArrayBsearch(array,double(z)); if(int(array[found])!=z) { array.Push(double(z)); ArraySort(array); comb.Assign(array); ulong dif = 1; for(uint row = 0; row<out.Size(); row++) { dif = comb.Compare(out[row],1e0); if(!dif) break; } if(dif) { ArrayResize(out,out.Size()+1,100); out[out.Size()-1] = comb; } } } } } public: MULTI(void):LinearModel() { CVector members; bestCombinations.push_back(members); modelName = "MULTI"; } bool fit(vector &time_series,int lags,double testsize=0.5,CriterionType criterion=stab,int kBest = 3,int pAverage = 1,double limit = 0.0) { if(lags < 1) { Print(__FUNCTION__," lags must be >= 1"); return false; } PairMVXd transformed = timeSeriesTransformation(time_series,lags); SplittedData splited = splitData(transformed.first,transformed.second,testsize); Criterion criter(criterion); if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } bool fit(matrix &vars,vector &targets,double testsize=0.5,CriterionType criterion=stab,int kBest = 3,int pAverage = 1,double limit = 0.0) { if(vars.Cols() < 1) { Print(__FUNCTION__," columns in vars must be >= 1"); return false; } if(vars.Rows() != targets.Size()) { Print(__FUNCTION__, " vars dimensions donot correspond with targets"); return false; } SplittedData splited = splitData(vars,targets,testsize); Criterion criter(criterion); if(validateInputData(testsize, pAverage, limit, kBest)) return false; return GmdhModel::gmdhFit(splited.xTrain, splited.yTrain, criter, kBest, testsize, pAverage, limit); } }; //+------------------------------------------------------------------+
The MULTI class works similarly to the COMBI class with the familiar "fit()" methods. Relative to the COMBI class, readers should take note of the more hyperparameters in the "fit()" methods. "kBest" and "pAverage" are two parameters that may need careful adjustment when applying the MULTI class. Fitting a model to a dataset is demonstrated in the scripts, MULTI_test.mq5 and MULTI_Multivariable_test.mq5. The code is presented below.
//+----------------------------------------------------------------------+ //| MULTI_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+----------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\multi.mqh> input int NumLags = 2; input int NumPredictions = 6; input CriterionType critType = stab; input int Average = 1; input int NumBest = 3; input double DataSplitSize = 0.33; input double critLimit = 0; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- vector tms = {1,2,3,4,5,6,7,8,9,10,11,12}; if(NumPredictions<1) { Alert("Invalid setting for NumPredictions, has to be larger than 0"); return; } MULTI multi; if(!multi.fit(tms,NumLags,DataSplitSize,critType,NumBest,Average,critLimit)) return; vector in(ulong(NumLags),slice,tms,tms.Size()-ulong(NumLags)); vector out = multi.predict(in,NumPredictions); Print(" predictions ", out); Print(multi.getBestPolynomial()); } //+------------------------------------------------------------------+
//+------------------------------------------------------------------+ //| MULTI_Mulitivariable_test.mq5 | //| Copyright 2024, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs #include <GMDH\multi.mqh> input CriterionType critType = stab; input double DataSplitSize = 0.33; input int Average = 1; input int NumBest = 3; input double critLimit = 0; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- matrix independent = {{1,2,3},{3,2,1},{1,4,2},{1,1,3},{5,3,1},{3,1,9}}; vector dependent = {6,6,7,5,9,13}; MULTI multi; if(!multi.fit(independent,dependent,DataSplitSize,critType,NumBest,Average,critLimit)) return; matrix unseen = {{1,2,4},{1,5,3},{9,1,3}}; for(ulong row = 0; row<unseen.Rows(); row++) { vector in = unseen.Row(row); Print("inputs ", in, " prediction ", multi.predict(in,1)); } Print(multi.getBestPolynomial()); } //+------------------------------------------------------------------+
It can be seen, that by running the scripts, the polynomials induced from our simple datasets are exactly the same as those obtained by applying the COMBI algorithm.
IG 0 18:24:28.811 MULTI_Mulitivariable_test (BTCUSD,D1) inputs [1,2,4] prediction [7.000000000000002] HI 0 18:24:28.812 MULTI_Mulitivariable_test (BTCUSD,D1) inputs [1,5,3] prediction [9] NO 0 18:24:28.812 MULTI_Mulitivariable_test (BTCUSD,D1) inputs [9,1,3] prediction [13.00000000000001] PP 0 18:24:28.812 MULTI_Mulitivariable_test (BTCUSD,D1) y= 1.000000e+00*x1 + 1.000000e+00*x2 + 1.000000e+00*x3 - 7.330836e-15 DP 0 18:25:04.454 MULTI_test (BTCUSD,D1) predictions [13,14,15,16,17,18.00000000000001] MH 0 18:25:04.454 MULTI_test (BTCUSD,D1) y= 1.000000e+00*x1 + 2.000000e+00
A GMDH model for Bitcoin prices
In this section of the text we will apply the GMDH method to build a predictive model of daily Bitcoin close prices. This is realized in the script GMDH_Price_Model.mq5 attached at the end of the article. Although, our demonstration deals specifically with the symbol, Bitcoin, the script can be applied to any symbol and timeframe. The script has several user mutable parameters that control various aspects of the program.
//--- input parameters input string SetSymbol=""; input ENUM_GMDH_MODEL modelType = Combi; input datetime TrainingSampleStartDate=D'2019.12.31'; input datetime TrainingSampleStopDate=D'2022.12.31'; input datetime TestSampleStartDate = D'2023.01.01'; input datetime TestSampleStopDate = D'2023.12.31'; input ENUM_TIMEFRAMES tf=PERIOD_D1; //time frame input int Numlags = 3; input CriterionType critType = stab; input PolynomialType polyType = linear_cov; input int Average = 10; input int NumBest = 10; input double DataSplitSize = 0.2; input double critLimit = 0; input ulong NumTestSamplesPlot = 20;
They are listed and described in the table that follows.
| Input Parameter Name | Description |
|---|---|
| SetSymbol | sets the symbols name of the close prices that will be used as training data, if left blank, the symbol of the chart the script is applied is assumed. |
| modeltype | this is enumeration that representing the choice of GMDH algorithm |
| TrainingSampleStartDate | begining date for period of in sample close prices |
| TrainingSampleStopDate | ending date for period of in sample close prices |
| TestSampleStartDate | begining date for period of out of sample prices |
| TestSampleStopDate | ending date for period of out of sample prices |
| tf | the applied timeframe |
| Numlags | defines the number of lagged values that will be used to forecast the next close price |
| critType | specifies the external criteria for the model building process |
| polyType | polynomial type to be used to construct new variables from existing ones during training , applicable only when MIA algorithm is selected |
| Average | The number of the best partial models based to be considered in the calculation of the stopping criteria |
| Numbest | for MIA models it defines the number of the best partial models based on which new inputs of subsequent layer will be constructed whilse for COMBI models it is the number of candidate models that will selected at each layer for consideration in subsequent iterations |
| DataSplitSize | Fraction of the input data that should be used to evaluate models |
| critLimit | The minimum value by which the external criterion should be improved in order to continue training |
| NumTestSamplePlot | The value defines the number of samples from the out of sample dataset that will be visualized along with the corresponding predictions |
The script begins with the selection of a suitable sample of observations to use as training data.
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //get relative shift of IS and OOS sets int trainstart,trainstop, teststart, teststop; trainstart=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TrainingSampleStartDate); trainstop=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TrainingSampleStopDate); teststart=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TestSampleStartDate); teststop=iBarShift(SetSymbol!=""?SetSymbol:NULL,tf,TestSampleStopDate); //check for errors from ibarshift calls if(trainstart<0 || trainstop<0 || teststart<0 || teststop<0) { Print(ErrorDescription(GetLastError())); return; } //---set the size of the sample sets size_observations=(trainstart - trainstop) + 1 ; size_outsample = (teststart - teststop) + 1; //---check for input errors if(size_observations <= 0 || size_outsample<=0) { Print("Invalid inputs "); return; } //---download insample prices for training int try = 10; while(!prices.CopyRates(SetSymbol,tf,COPY_RATES_CLOSE,TrainingSampleStartDate,TrainingSampleStopDate) && try) { try --; if(!try) { Print("error copying to prices ",GetLastError()); return; } Sleep(5000);
Another sample of close prices are downloaded , which will be used to visualize the performance of the model with a plot of predicted and actual close prices.
//---download out of sample prices testing try = 10; while(!testprices.CopyRates(SetSymbol,tf,COPY_RATES_CLOSE|COPY_RATES_TIME|COPY_RATES_VERTICAL,TestSampleStartDate,TestSampleStopDate) && try) { try --; if(!try) { Print("error copying to testprices ",GetLastError()); return; } Sleep(5000); }
The user defined parameters of the script enable the application of one of the three GMDH models we have discussed and implemented.
//--- train and make predictions switch(modelType) { case Combi: { COMBI combi; if(!combi.fit(prices,Numlags,DataSplitSize,critType)) return; Print("Model ", combi.getBestPolynomial()); MakePredictions(combi,testprices.Col(0),predictions); } break; case Mia: { MIA mia; if(!mia.fit(prices,Numlags,DataSplitSize,polyType,critType,NumBest,Average,critLimit)) return; Print("Model ", mia.getBestPolynomial()); MakePredictions(mia,testprices.Col(0),predictions); } break; case Multi: { MULTI multi; if(!multi.fit(prices,Numlags,DataSplitSize,critType,NumBest,Average,critLimit)) return; Print("Model ", multi.getBestPolynomial()); MakePredictions(multi,testprices.Col(0),predictions); } break; default: Print("Invalid GMDH model type "); return; } //---
The program ends by displaying a plot of the predicted close prices along with the actual values from the out of sample dataset.
//--- ulong TestSamplesPlot = (NumTestSamplesPlot>0)?NumTestSamplesPlot:20; //--- if(NumTestSamplesPlot>=testprices.Rows()) TestSamplesPlot = testprices.Rows()-Numlags; //--- vector testsample(100,slice,testprices.Col(0),Numlags,Numlags+TestSamplesPlot-1); vector testpredictions(100,slice,predictions,0,TestSamplesPlot-1); vector dates(100,slice,testprices.Col(1),Numlags,Numlags+TestSamplesPlot-1); //--- //Print(testpredictions.Size(), ":", testsample.Size()); //--- double y[], y_hat[]; //--- if(vecToArray(testpredictions,y_hat) && vecToArray(testsample,y) && vecToArray(dates,xaxis)) { PlotPrices(y_hat,y); } //--- ChartRedraw(); }
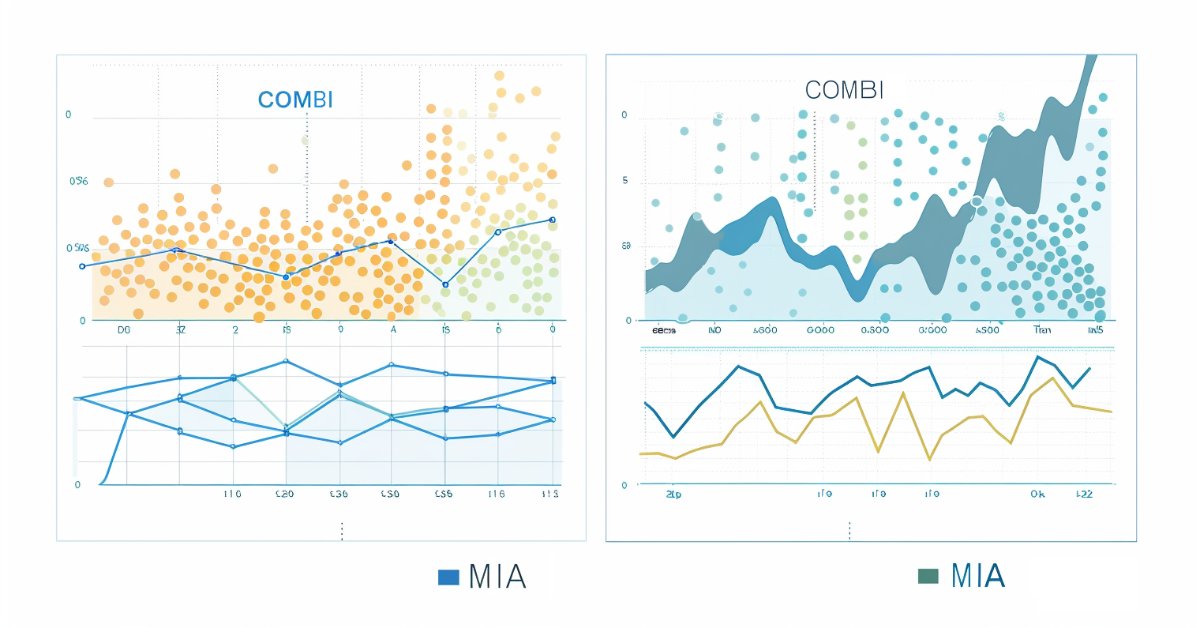
Below are the plots from predictions made using the combinatorial and multilayer iterative algorithms respectively.


Conclusion
In conclusion, the combinatorial algorithm of the GMDH offers a framework for modeling complex systems, with particular strengths in areas where data-driven, inductive approaches are advantageous. Its practical application is limited due to the algorithm's inefficiency when handling large datasets. The combinatorial selective algorithm mitigates this shortcoming only to a certain extent. Gains in speed are weighed down by the introduction of more hyperparameters that need to be tuned, in order to get the most from the algorithm. The application of the GMDH method in financial time series analysis demonstrates its potential in providing valuable insights.
| File | Description |
|---|---|
| Mql5\include\VectorMatrixTools.mqh | header file of function definitions used for manipulating vectors and matrices |
| Mql5\include\JAson.mqh | contains the definition of the custom types used for parsing and generating JSON objects |
| Mql5\include\GMDH\gmdh_internal.mqh | header file containing definitions of custom types used in gmdh library |
| Mql5\include\GMDH\gmdh.mqh | include file with definition of the base class GmdhModel |
| Mql5\include\GMDH\linearmodel.mqh | include file with definition of the intermediary class LinearModel which is the basis for the COMBI and MULTI classes |
| Mql5\include\GMDH\combi.mqh | include file with definition of the COMBI class |
| Mql5\include\GMDH\multi.mqh | include file with definition of the MULTI class |
| Mql5\include\GMDH\mia.mqh | contains the class MIA which implements the multilayer iterative algorithm |
| Mql5\script\COMBI_test.mq5 | a script that demonstrates use of the COMBI class by building a model of a simple time series |
| Mql5\script\COMBI_Multivariable_test.mq5 | a script showing the application of the COMBI class to build a model of a multivariable dataset |
| Mql5\script\MULTI_test.mq5 | a script that demonstrates use of the MULTI class by building a model of a simple time series |
| Mql5\script\MULTI_Multivariable_test.mq5 | a script showing the application of the MULTI class to build a model of a multivariable dataset |
| Mql5\script\GMDH_Price_Model.mqh | a script demonstrating a GMDH model of a price series |
 Developing an MQL5 RL agent with RestAPI integration (Part 2): MQL5 functions for HTTP interaction with the tic-tac-toe game REST API
Developing an MQL5 RL agent with RestAPI integration (Part 2): MQL5 functions for HTTP interaction with the tic-tac-toe game REST API
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use