
Passo a passo do HTML usando MQL4

Introdução
O HTML (Hypertext Mark-Up Language) foi criado para a formatação conveniente de materiais textuais. Todos os documentos desse tipo são formatados com palavras de função especial chamadas "tags". Praticamente todas as informações em arquivos html acabam sendo inseridas com tags. Se quisermos extrair dados puros, precisamos separar as informações de serviço (tags) dos dados relevantes. Nomearemos esse procedimento de passo a passo de HTML voltado para destacar a estrutura de tag.
O que é tag?
Em termos de descrição simples, uma tag é qualquer palavra inserida em colchetes angulares. Por exemplo, isso é uma tag: , embora, em HTML, as tags sejam certas palavras digitadas em letras latinas. Por exemplo, é uma tag correta, mas não existe uma tag . Além disso, muitas tags podem ter atributos adicionais que tornam precisa a formatação executada por dada tag. Por exemplo, <div align="center"> significa a tag <div> na qual o atributo adicional do alinhamento central do conteúdo da tag é especificado.
Normalmente, as tags são utilizadas em pares: há tags de abertura e fechamento. Elas diferem uma da outra apenas pela presença de uma barra. A tag <div> é uma tag de abertura, enquanto a tag </div> é de fechamento. Todos os dados inseridos entre as tags de abertura e fechamento são chamadas de conteúdo de tag. É nesse conteúdo que nos interessamos no passo a passo do código HTML. Exemplo:
<td>6</td>
A tag contém "6" aqui.
O que significa "Passo a passo do texto"?
No contexto deste artigo, significa que queremos obter todas as ocorrências de palavras em um arquivo html e inserir dois colchetes angulares: "" - abertura e fechamento. Não analisaremos aqui se cada palavra nesses colchetes angulares é uma tag correta ou não. Nossa tarefa é puramente técnica. Escreveremos todas as tags consecutivas encontradas em uma série de strings por ordem de ocorrência. Nomearemos essa série de "estrutura de tag".
Função de leitura do arquivo
Antes de analisar o arquivo de um texto, é melhor carregá-lo em uma série de string. Assim, abriremos e fecharemos automaticamente o arquivo para não esquecer de fechá-lo por engano. Além disso, uma função definida pelo usuário que lê o texto de um arquivo em uma série é muito mais conveniente para várias aplicações que escrever todas as vezes o procedimento de leitura de dados completo com uma verificação obrigatória pra possíveis erros. A função ReadFileToArray() tem três parâmetros:
- strings array[] - uma série de strings passada por um link, permite alterar seu tamanho e seu conteúdo diretamente na função;
- string FileName - nome do arquivo do qual as linhas devem ser lidas em série[];
- string WorkFolderName - nome da subpasta no diretório Terminal_directory\experts\files.
//+------------------------------------------------------------------+ //| writing the content of the file into string array 'array[]' | //| in case of failing, return 'false' | //+------------------------------------------------------------------+ bool ReadFileToArray(string &array[],string FileName, string WorkFolderName) { bool res=false; int FileHandle; string tempArray[64000],currString; int stringCounter; int devider='\x90'; string FullFileName; if (StringLen(WorkFolderName)>0) FullFileName=StringConcatenate(WorkFolderName,"\\",FileName); else FullFileName=FileName; //---- Print("Trying to read file ",FileName); FileHandle=FileOpen(FullFileName,FILE_READ,devider); if (FileHandle!=-1) { while(!FileIsEnding(FileHandle)) { tempArray[stringCounter]=FileReadString(FileHandle); stringCounter++; } stringCounter--; if (stringCounter>0) { ArrayResize(array,stringCounter); for (int i=0;i<stringCounter;i++) array[i]=tempArray[i]; res=true; } FileClose(FileHandle); } else { Print("Failed reading file ",FileName); } //---- return(res); }
O tamanho da série de string auxiliar é de 64.000 elementos. Os arquivos de um grande número de linhas não devem ocorrer com frequência. Entretanto, é possível alterar este parâmetro como quiser. A variável stringCounter conta o número de linhas lidas do arquivo em uma série auxiliar temArray[], depois, as linhas lidas são escritas para a série[] cujo tamanho é preliminarmente definido como igual a stringCounter. Em caso de erro, o programa exibirá uma mensagem nos logs de EA, que você poderá ver na guia "Experts".
Se a série[] foi preenchida com sucesso, a função ReadFileToArray() retorna "verdadeira". Caso contrário, ela retornará "falsa".
Função de ajuda FindInArray()
Antes de começar o processamento de conteúdo da série de string em nossa pesquisa por tags, devemos dividir a tarefa geral em várias subtarefas melhores. Há várias soluções para a tarefa de detecção da estrutura de tag. Agora, vamos considerar uma específica. Vamos criar uma função que nos informa em qual linha e em qual posição nesta linha a palavra pesquisada se encontra. Passaremos a informação para essa função a série string e a variável da string contendo a palavra que estamos pesquisando.
//+-------------------------------------------------------------------------+ //| It returns the coordinates of the first entrance of text matchedText | //+-------------------------------------------------------------------------+ void FindInArray(string Array[], // string array to search matchedText for int inputLine, // line number to start search from int inputPos, // position number to start search from int & returnLineNumber, // found line number in the array int & returnPosIndex, // found position in the line string matchedText // searched word ) { int start; returnLineNumber=-1; returnPosIndex=-1; int pos; //---- for (int i=inputLine;i<ArraySize(Array);i++) { if (i==inputLine) start=inputPos; else start=0; if (start>=StringLen(Array[i])) start=StringLen(Array[i])-1; pos=StringFind(Array[i],matchedText,start); if (pos!=-1) { returnLineNumber=i; returnPosIndex=pos; break; } } //---- return; }
A função FindInArray() retorna as "coordenadas" do matchedText usando variáveis inteiras passadas pelo link. A variável returnLineNumber contém o número de linha, enquanto returnPosIndex contém o número de posição nesta linha.
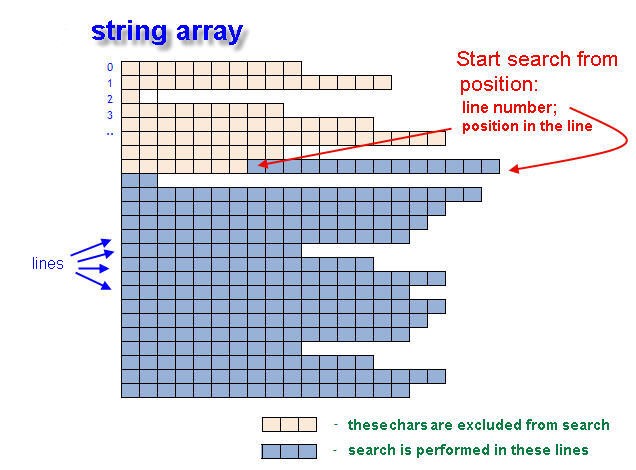
Fig. 1. Pesquise pela posição inicial do texto na série de string
A pesquisa não é executada em toda a série, mas inicia do número da linha inputLine e do número de posição inputPos. Essas são as coordenadas de pesquisa inicial na Série[]. Se a palavra pesquisada não é encontrada, as variáveis de retorno (returnLineNumber e returnPosIndex) conterão o valor de -1 (menos um).
Como conseguir uma linha por suas coordenadas de fim e começo de uma série de string
Se tivermos o começo e o fim das coordenadas de uma tag, precisamos escrever na string todos os caracteres localizados entre os dois colchetes angulares. Usaremos a função getTagFromArray() para isso.
//+------------------------------------------------------------------+ //| it returns a tag string value without classes | //+------------------------------------------------------------------+ string getTagFromArray(string inputArray[], int lineOpen, int posOpen, int lineClose, int posClose, int line_, int pos_) { string res=""; //---- if (ArraySize(inputArray)==0) { Print("Zero size of the array in function getTagFromArray()"); return(res); } string currString; int endLine=-1; int endPos=-1; if (lineClose>=0 && line_>=0) // both space and a closing angle bracket are available { endLine=MathMin(lineClose,line_); // the number of ending line is defined if (lineClose==line_ && pos_<posClose) endPos=pos_;// if the space and the closing angle bracket are in // one line, the position number is the same as that of the space if (lineClose==line_ && pos_>posClose) endPos=posClose;// if the space and the closing angle bracket are in // one line, the position number is the same as that of the space if (lineClose>line_) endPos=pos_;// if the line containing a space is before the line containing a closing bracket, // the position is equal to that of the space if (lineClose<line_) endPos=posClose;// if the line containing a closing bracket is before the line // containing a space, the position is equal to that of the closing bracket } if (lineClose>=0 && line_<0) // no space { endLine=lineClose; endPos=posClose; } for (int i=lineOpen;i<=endLine;i++) { if (i==lineOpen && lineOpen!=endLine) // if the initial line from the given position { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen)); } if (i==lineOpen && lineOpen==endLine) // one line { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen,endPos-posOpen)); } if (i>lineOpen && i<endLine) // copy the whole line { res=StringConcatenate(res,inputArray[i]); } if (i>endLine && endLine>lineOpen) // copy the beginning of the end line { currString=inputArray[i]; if (endPos>0) res=StringConcatenate(res,StringSubstr(currString,0,endPos)); } } if (StringLen(res)>0) res=res+">"; //---- return(res); }
Nessa função, pesquisamos consecutivamente em todas as linhas localizadas dentro das coordenadas de colchetes angulares de abertura e fechamento com a participação de coordenadas de espaço. A operação da função resulta na obtenção da expressão ', que pode ser montada para várias linhas.
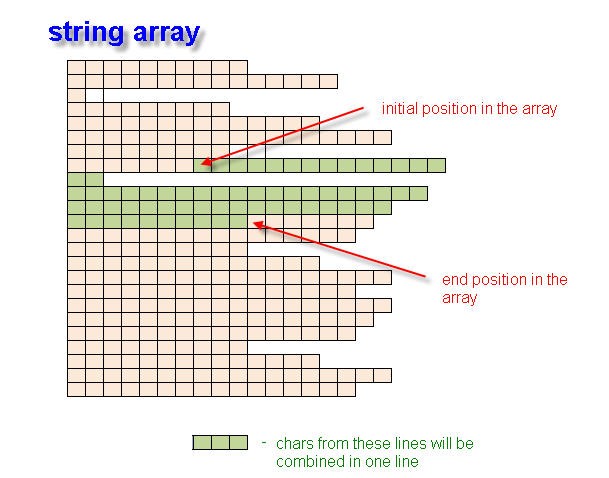
Fig. 2. Criação de uma variável de string de uma série de string usando as posições de fim e início
Como obter a estrutura de tag
Agora, temos duas funções de ajuda, então podemos começar a buscar tags. Para isso, pesquisaremos consecutivamente "" e " " (espaço) com a função FindInArray(). Para ser mais exato, pesquisaremos as posições destes caracteres na série de string e depois montaremos os nomes das tags encontradas usando a função getTagFromArray(), e as colocaremos em uma série contendo a estrutura de tag. Como você pode ver, a tecnologia é muito simples. Esse algoritmo é feito na funçãoFillTagStructure().
//+------------------------------------------------------------------+ //| fill out the tag structure | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// tag structure being created string array[], // initial html text int line, // line number in array[] int pos) // position number in the line { //---- int array_Size=ArraySize(array); if (line==-1000 || pos==-1000 ) { Alert("Invalid values of search position in function FillTagStructure()"); return; } string currString="",newTag=""; int size=ArraySize(array),structureSize=ArraySize(structure); if (size==0) { Alert("Zero-size array is passed for processing to function FillTagStructure()"); return; } int newLine=-1000,newPos=-1000; bool tagFounded=false; int lineOpen,posOpen,lineClose,posClose,line_,pos_; FindInArray(array,line,pos,lineOpen,posOpen,"<"); if (lineOpen!=-1 && posOpen!=-1) { FindInArray(array,lineOpen,posOpen+1,lineClose,posClose,">"); FindInArray(array,lineOpen,posOpen+1,line_,pos_," "); if (lineClose !=-1) // a closing angle bracket is found { newTag=getTagFromArray(array,lineOpen,posOpen,lineClose,posClose,line_,pos_); newLine=lineClose; newPos=posClose+1; tagFounded=true; } else { Print("Closing angle bracket is not found in function FillTagStructure()" ); return; } } if (tagFounded) { ArrayResize(structure,structureSize+1); structure[structureSize]=newTag; FillTagStructure(structure,array,newLine,newPos); } //---- return; }
Observe que, no caso de descobrir uma tag, o tamanho da série representando a estrutura de tag aumenta em um, uma nova tag é adicionada e depois a função chama a si mesma de forma recursiva.

Fig. 3. Um exemplo de função recursiva: A função FillTagStructure() está chamando a si mesma
Esse método de funções escritas para cálculos consecutivos é muito atrativo e melhora com frequência o lote de um programador. Com base nessa função, o script TagsFromHTML.mq4 foi desenvolvido para buscar tags no relatório do provador, StrategyTester.html, e mostrar todas as tags encontradas no log.
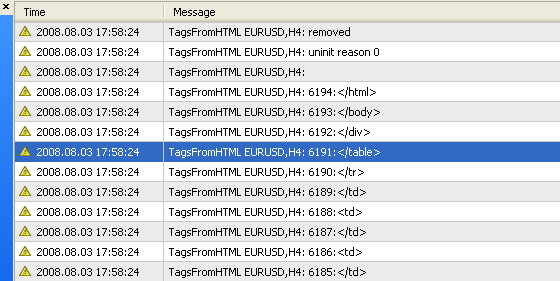
Fig. 4. Resultado das operações do script TagsFromHTML.mq4: O número da tag e a própria tag são exibidos
Como pode ser visto, um relatório de teste pode conter algumas milhares de tags. Na fig. 4, é possível ver que a última tag encontrada, , tem o número 6194. É impossível pesquisar em tal quantidade de tags manualmente.
Como obter os conteúdos inseridos nas tags
A busca por tags é uma tarefa associada, a tarefa principal é obter a informação empacotada nas tags. Se vermos o conteúdo do arquivo StartegyTester.html usando um editor de texto, por exemplo, o Notepad, podemos ver que os dados do relatório estão localizados entre as tags e <table></table>. A tag "table" serve para formatar dados tabulares e normalmente inclui várias linhas colocadas entre as tags <tr> e </tr>.
Por sua vez, cada linha contém células que são inseridas nas tags <td> e </td>. Nossa finalidade é encontrar os conteúdos valiosos entre as tags <td> e </td> coletar esses dados em strings formatadas para nossas necessidades. Primeiro, vamos fazer algumas modificações na função FillTagStructure() para que possamos armazenar a estrutura de tag e as informações sobre as posições de começo/fim de tag.

Fig. 5. Com a tag, suas posições de começo e fim na série de string são escritas nas séries correspondentes
Sabendo o nome da tag e as coordenadas do começo e fim de cada tag, podemos conseguir facilmente o conteúdo localizado entre duas tags consecutivas. Para isso, vamos escrever outra função, GetContent(), que é muito parecida com a função getTagFromArray().
//+------------------------------------------------------------------+ //| get the contents of lines within the given range | //+------------------------------------------------------------------+ string GetContent(string array[], int start[1][2],int end[1][2]) { string res = ""; //---- int startLine = start[0][0]; int startPos = start[0][1]; int endtLine = end[0][0]; int endPos = end[0][1]; string currString; for (int i = startLine; i<=endtLine; i++) { currString = array[i]; if (i == startLine && endtLine > startLine) { res = res + StringSubstr(currString, startPos); } if (i > startLine && i < endtLine) { res = res + currString; } if (endtLine > startLine && i == endtLine) { if (endPos > 0) res = res + StringSubstr(currString, 0, endPos); } if (endtLine == startLine && i == endtLine) { if (endPos - startPos > 0) res = res + StringSubstr(currString, startPos, endPos - startPos); } } //---- return(res); }
Agora, podemos processar os conteúdos das tags da forma que for conveniente para nós. É possível ver um exemplo de tal processamento no script ReportHTMLtoCSV.mq4. Abaixo está a função início () do script:
int start() { //---- int i; string array[]; ReadFileToArray(array, filename,""); int arraySize=ArraySize(array); string tags[]; // array to store tags int startPos[][2];// tag-start coordinates int endPos[][2]; // tag-end coordinates FillTagStructure(tags, startPos, endPos, array, 0, 0); //PrintStringArray(tags, "tags contains tags"); int tagsNumber = ArraySize(tags); string text = ""; string currTag; int start[1][2]; int end[1][2]; for (i = 0; i < tagsNumber; i++) { currTag = tags[i]; //Print(tags[i],"\t\t start pos=(",startPos[i][0],",",startPos[i][1],") \t end pos = (",endPos[i][0],",",endPos[i][1],")"); if (currTag == "<table>") { Print("Beginning of table"); } if (currTag == "<tr>") { text = ""; start[0][0] = -1; start[0][1] = -1; } if (currTag == "<td>") {// coordinates of the initial position for selecting the content between tags start[0][0] = endPos[i][0]; start[0][1] = endPos[i][1]; } if (currTag == "</td>") {// coordinates of the end position for selecting the content between tags end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; } if (currTag == "</td>") {// coordinates of the end position for selecting the content between tags end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; text = text + GetContent(array, start, end) + ";"; } if (currTag == "</tr>") { Print(text); } if (currTag == "</table>") { Print("End of table"); } } //---- return(0); }
Na fig. 6, é possível ver como um arquivo de log aparece contendo as mensagens deste script e aberto no Microsoft Excel.
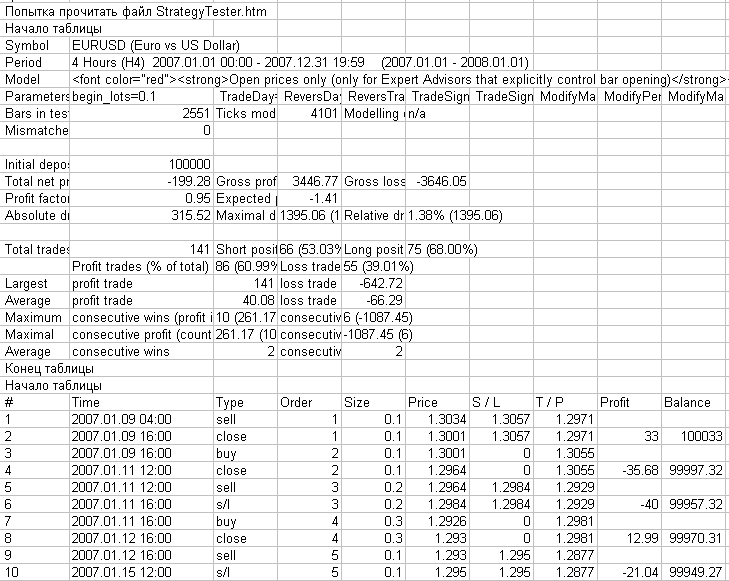
Fig. 6. Arquivo de log da pasta MetaTrader 4\experts\logs contendo os resultados da operação do script ReportHTMLtoCSV.mq4, aberto com o Microsoft Excel
Na fig. 6 acima, é possível ver a estrutura conhecida do relatório de teste do MetaTrader 4.
Defeitos deste script
Há vários tipos de erros de programação. Os erros do primeiro tipo (erros de sintaxe) são fáceis de detectar no estágio de compilação. Os erros do segundo tipo são algorítmicos. O código do programa é compilado com sucesso, mas podem haver situações não previstas no algoritmo, o que resulta em padrões de erros no programa ou até mesmo no seu impacto. Esses erros não são fáceis de detectar, mas ainda são possíveis.
Por fim, podem haver erros do terceiro tipo, conceituais. Tais erros podem ocorrer se o algoritmo do programa, embora escrito corretamente, não esteja pronto para usar o programa em condições um pouco diferentes. O script ReportHTMLtoCSV.mq4 é adequado para o processamento de documentos html pequenos contendo algumas milhares de tags, mas não é adequado para o processamento de milhões delas. Ele tem dois gargalos. O primeiro é o redimensionamento múltiplo de séries.

Fig. 7. Várias chamadas da função ArrayResize() para cada nova tag encontrada
No processo de operação de script, chamar a função ArrayResize() dezenas, centenas de milhares ou mesmo milhões de vezes resultará em uma grande perda de tempo. A cada redimensionamento dinâmico, uma série exige algum tempo para alocar uma nova área de tamanho necessário na memória do PC para copiar o conteúdo da série velha na nova. Se alocarmos uma série de tamanho um tanto grande antes, seremos capazes de reduzir essencialmente o tempo gasto por essas operações excessivas. Por exemplo, vamos declarar as "tags" da série da seguinte forma:
string tags[1000000]; // array to store tags
Agora, podemos escrever até milhões de tags sem a necessidade de chamar a função ArrayResize() milhões de vezes!
O outro defeito do script considerado ReportHTMLtoCSV.mq4 é o uso da função recursiva. Cada chamada da função FillTagStructure() é acompanhada por alocações de alguma área de RAM para colocar a variável local necessária nesta cópia local da função. Se o documento contém 10.000 tags, a função FillTagStructure() será chamada 10.000 vezes. A memória para localizar a função recursiva está alocada a partir de uma área reservada preliminarmente a qual o tamanho é especificado pela pilha de tamanho #property diretiva:
#property stacksize 1000000
Neste caso, o compilador é atribuído para alocar um milhão de bytes por pilha. Se a memória da pilha não for suficiente para as chamadas da função, você receberá o erro estouro de pilha. Se precisarmos chamar a função recursiva milhões de vezes, até mesmo a alocação de centenas de megabytes por pilha poderá ser em vão. Então, precisamos modificar um pouco o algoritmo de busca por tag para evitar o uso de chamadas recursivas.
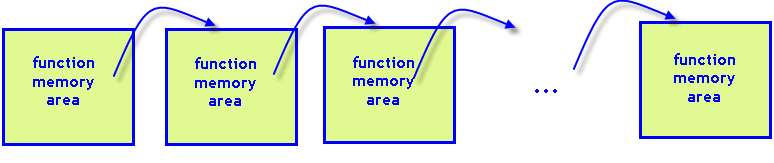
Fig. 8. Cada chamada da função recursiva exige sua própria área de memória na pilha do programa
Vamos por outro caminho - nova função FillTagStructure()
Vamos escrever novamente a função para obter a estrutura de tag. Agora, ela usará explicitamente um ciclo para trabalhar com a série[] de string. O algoritmo da nova função está claro, se você entendeu ele na função antiga.
//+------------------------------------------------------------------+ //| it fills out the tag structure | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// tag structure to be created int & start[][], // tag start (line, position) int & end[][], // tag end (line, position) string array[]) // initial html text { //---- int array_Size = ArraySize(array); ArrayResize(structure, capacity); ArrayResize(start, capacity); ArrayResize(end, capacity); int i=0, line, posOpen, pos_, posClose, tagCounter, currPos = 0; string currString; string tag; int curCapacity = capacity; while (i < array_Size) { if (tagCounter >= curCapacity) // if the number of tags exceeds { // the storage capacity ArrayResize(structure, curCapacity + capacity); // increase the storage in size ArrayResize(start, curCapacity + capacity); // also increase the size of the array of start positions ArrayResize(end, curCapacity + capacity); // also increase the size of the array of end positions curCapacity += capacity; // save the new capacity } currString = array[i]; // take the current string //Print(currString); posOpen = StringFind(currString, "<", currPos); // search for the first entrance of '<' after position currPos if (posOpen == -1) // not found { line = i; // go to the next line currPos = 0; // in the new line, search from the very beginning i++; continue; // return to the beginning of the cycle } // we are in this location, so a '<' has been found pos_ = StringFind(currString, " ", posOpen); // then search for a space, too posClose = StringFind(currString, ">", posOpen); // search for the closing angle bracket if ((pos_ == -1) && (posClose != -1)) // space is not found, but the bracket is { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it into tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } // we are in this location, so both the space and the closing bracket have been found if ((pos_ != -1) && (posClose != -1)) { if (pos_ > posClose) // space is after bracket { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it to the tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } // no, the space is still before the closing bracket if (pos_ < posClose) { tag = StringSubstr(currString, posOpen, pos_ - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it to the tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } } // we are in this location, so neither a space nor a closing bracket have been found if ((pos_ == -1) && (posClose == -1)) { tag = StringSubstr(currString, posOpen) + ">"; // assemble a tag of what we have structure[tagCounter] = tag; // written it to the tags array while (posClose == -1) // and organized a cycle to search for { // the first closing bracket i++; // increase in size the counter of lines currString = array[i]; // count the new line posClose = StringFind(currString, ">"); // and search for a closing bracket in it } setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // it seems to have been found, then set the initial position } // to search for a new tag } ArrayResize(structure, tagCounter); // cut the tags array size down to the number of //---- // tags found return; }
As séries estão agora redimensionadas em porções por capacidade de elementos. O valor da capacidade é especificado pela declaração da constante.
#define capacity 10000
As posições de início e fim de cada tag são agora definidas usando a função setPositions().
//+------------------------------------------------------------------+ //| write the tag coordinates into the corresponding arrays | //+------------------------------------------------------------------+ void setPositions(int & st[][], int & en[][], int counter,int stLine, int stPos, int enLine, int enPos) { //---- st[counter][0] = stLine; st[counter][1] = stPos; en[counter][0] = enLine; en[counter][1] = enPos; //---- return; }
A propósito, não precisamos mais das funções FindInArray() e getTagFromArray(). O código completo é dado no script ReportHTMLtoCSV-2.mq4 anexado aqui.
Conclusão
O algoritmo do passo a passo do documento HTML para as tags é considerado e um exemplo de como extrair informações do relatório do provador de estratégia no terminal do cliente MetaTrader 4 é dado.
Tente não usar as chamadas de função ArrayResize() em massa pois isso pode resultar em consumo de tempo excessivo.
Além disso, o uso de funções recursivas pode consumir recursos RAM essenciais. Se chamadas em massa de tal função forem consideradas, tente escrevê-las novamente para que nenhuma recursão seja necessária.
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/1544
 Como escrever ZigZags rápidos que não são redesenhados
Como escrever ZigZags rápidos que não são redesenhados
 Operações de arquivo agrupadas
Operações de arquivo agrupadas
 A ociosidade é o estímulo do progresso ou como trabalhar com gráficos de maneira interativa
A ociosidade é o estímulo do progresso ou como trabalhar com gráficos de maneira interativa
 Expert Advisors baseado em sistemas de trading populares e alquimia da otimização de robô de trading (Parte II)
Expert Advisors baseado em sistemas de trading populares e alquimia da otimização de robô de trading (Parte II)
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso