
Desenvolvendo um agente de Aprendizado por Reforço em MQL5 com Integração RestAPI (Parte 5): Escolhendo o Algoritmo do agente

Introdução
Bem-vindos ao quinto capítulo de nossa série, onde destacamos avanços cruciais em nosso desenvolvimento. Até o momento, exploramos diversas áreas, desde a integração de APIs REST com MQL5 até a automação de jogos, exemplificada pelo jogo da velha, através do uso do Python.
No primeiro artigo, introduzimos a integração entre MQL5 e APIs REST, um passo fundamental para estabelecer a comunicação entre algoritmos de trading e ambientes externos, como jogos ou mercados financeiros. Demonstramos como usar RestAPIs em MQL5, estabelecendo a base para uma interação robusta com o mundo externo.
Avançando, no segundo artigo, focamos nas funções MQL5 específicas para a interação HTTP, e assim poder se comunicar com a API REST do jogo da velha. Esse passo não apenas solidificou o entendimento de comunicações de rede no contexto do MQL5, mas também preparou o terreno para aplicações mais complexas, como a automação de estratégias de trading que envolvam dados externos, como por exemplo:
- Dados de redes sociais: Algumas APIs permitem acessar dados de redes sociais como Twitter, Facebook, LinkedIn, etc. Isso pode incluir menções de empresas, sentimento do mercado, etc.
- Dados climáticos: Informações meteorológicas podem ser úteis para certos tipos de análise, como commodities agrícolas ou setores sensíveis ao clima.
- Dados de padrões de consumo: Informações sobre padrões de consumo, tendências de compras online, etc., podem ser úteis para análise de varejo ou investimentos relacionados ao consumo.
No terceiro artigo, aprofundamos na criação de jogadas automáticas e scripts de teste em MQL5. Esse desenvolvimento marcou a transição de teoria para prática, onde aplicamos o conhecimento adquirido para criar um agente capaz de jogar automaticamente o jogo da velha, demonstrando a capacidade do MQL5 de executar tarefas complexas além do trading financeiro.
O quarto artigo da série abordou a organização de funções em classes no MQL5, um grande passo em direção à modularidade e à manutenção do código. Essa abordagem não só facilita a gestão de projetos complexos, mas também realça a versatilidade e o poder do MQL5 como linguagem de programação para automação.
Este capítulo marca um ponto crucial em nossa jornada, onde nos voltamos à seleção e aplicação de algoritmos de aprendizado por reforço. Ao invés de abordar a vastidão de algoritmos disponíveis, concentraremos nossa atenção em alguns notáveis, incluindo Q-Learning, Deep Q-Learning, e Proximal Policy Optimization (PPO). Essa escolha se alinha ao nosso objetivo de demonstrar a versatilidade do MQL5, enfatizando como esses algoritmos podem ser harmoniosamente integrados com Python via API Rest para aprimorar a automação financeira.
O Q-Learning, um método de aprendizado por diferença temporal, nos permite otimizar a política de tomada de decisão sem a necessidade de um modelo do ambiente. Seguindo, o Deep Q-Learning amplia esse conceito ao aplicar redes neurais profundas, permitindo o tratamento de estados e ações de alta dimensão com eficiência. Por fim, o PPO, um algoritmo de policy gradient, oferece um equilíbrio entre facilidade de implementação, eficiência de amostragem e estabilidade de treinamento, destacando-se em ambientes de alta complexidade.
Ao explorar esses algoritmos, pretendemos abrir caminho para discussões detalhadas em capítulos futuros. Nossa exploração se concentrará na teoria por trás de cada método, sua aplicabilidade em cenários reais e como a integração do MQL5 com ambientes externos potencializa essas técnicas, reforçando a arquitetura de software e modularidade. Esse enfoque nos permite abraçar a complexidade do aprendizado por reforço enquanto mantemos os conceitos acessíveis, preparando o terreno para aplicações práticas em automação financeira.
Selecionar o algoritmo de aprendizado por reforço adequado é um marco decisivo. Define o caminho de aprendizado e adaptação do nosso agente em MQL5 ao ambiente em que será inserido, sendo essencial para alcançar uma operacionalidade e eficiência sem precedentes. Portanto, é crucial compreender detalhadamente as forças, fraquezas e contextos ideais de cada algoritmo escolhido.
Próximos passos, com a fundação já estabelecida e o terreno preparado, estamos prontos para o próximo grande desafio: selecionar o algoritmo de aprendizado por reforço que maximizará a eficiência e a eficácia do nosso agente em MQL5. Este passo transcende a simples codificação; é a ponte entre teoria e prática, assegurando que nosso agente não apenas execute suas funções com excelência, mas também se destaque em eficiência operacional. À medida que avançamos para esta fase crítica do nosso projeto, nosso objetivo é identificar e implementar o algoritmo de aprendizado por reforço mais adequado, levando em conta tanto a teoria subjacente quanto uma análise detalhada e criteriosa de suas aplicações práticas.
No próximo segmento, iniciaremos nossa exploração detalhada de cada um dos três algoritmos principais - Q-Learning, DQN (Deep Q-Network) e PPO (Proximal Policy Optimization) - com o propósito de fazer uma escolha informada, baseada em um entendimento profundo de suas funcionalidades, vantagens e limitações.
Prosseguindo, vamos agora examinar um poco da essência de cada algoritmo de aprendizado por reforço, destacando suas características distintas, vantagens, limitações e aplicabilidades práticas. Esta análise não só esclarecerá o caminho para a escolha do algoritmo mais adequado mas também ampliará nosso entendimento sobre a aplicação dessas poderosas ferramentas na resolução de problemas complexos.
Q-Learning
A transição do nosso projeto para a exploração dos algoritmos de aprendizado por reforço é um avanço em nosso estudo. Após estabelecermos uma base sólida com os conceitos fundamentais de integração entre MQL5 e ambientes externos, como jogos e APIs REST, estamos agora prontos para adentrar o mundo complexo, mas fascinante, da inteligência artificial aplicada.
Neste contexto, o Q-Learning se destaca como um dos pilares essenciais do aprendizado por reforço. Este método, embora simples em sua formulação matemática, oferece uma abordagem poderosa para aprender a tomar decisões ótimas em ambientes dinâmicos e desconhecidos. Ao contrário de alguns outros algoritmos que exigem um modelo explícito do ambiente, o Q-Learning é capaz de aprender diretamente a partir das interações com o ambiente, o que o torna particularmente adequado para problemas em que o modelo do ambiente é desconhecido ou muito complexo para ser explicitamente representado.
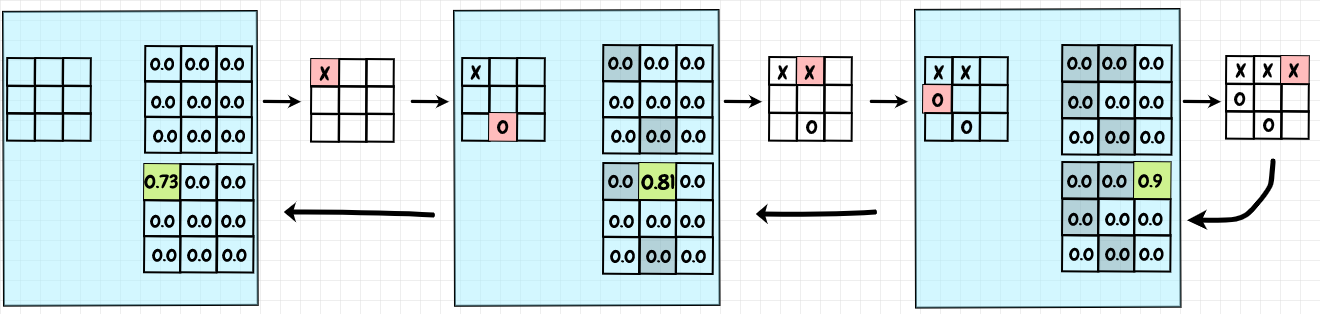
No cerne do Q-Learning está a noção de uma função de valor de ação, denotada como Q(s, a), que representa a utilidade esperada de escolher uma determinada ação a em um determinado estado s. A atualização dessa função de valor é realizada iterativamente, usando uma fórmula de atualização conhecida como equação de Bellman:
Q(s,a)←Q(s,a)+α(r+γmaxa′Q(s′,a′)−Q(s,a))
Onde:
- Q(s,a) é o valor da função de ação para o estado s e a ação a;
- α é a taxa de aprendizado, controlando a rapidez com que o agente incorpora novas informações;
- r é a recompensa obtida ao tomar a ação a no estado s;
- γ é o fator de desconto, refletindo a preferência do agente por recompensas imediatas ou futuras;
- s′ é o estado resultante da transição do estado s através da ação a;
- maxa′Q(s′,a′) é o valor máximo da função de ação para o próximo estado s', representando a melhor ação a ser tomada.
Essencialmente, esta equação expressa a ideia de que o valor da função de ação para um determinado estado e ação deve ser atualizado em direção à soma da recompensa imediata obtida e a estimativa do valor futuro esperado. Ao iterar este processo ao longo de múltiplas interações com o ambiente, o agente gradualmente converge para uma política ótima, ou seja, uma estratégia de ação que maximiza a recompensa cumulativa esperada ao longo do tempo.
Para ilustrar este conceito, consideremos um exemplo prático do mundo real: o treinamento de um agente para navegar em um labirinto. Neste cenário, cada célula do labirinto representa um estado, e as ações possíveis incluem mover-se para cima, para baixo, para a esquerda ou para a direita. O agente inicia em uma posição aleatória e, ao longo do tempo, aprende a explorar o labirinto de forma a maximizar a sua recompensa final, que pode ser definida, por exemplo, como a distância percorrida até a saída.
Durante o treinamento, o agente atualiza continuamente sua estimativa de Q(s,a) com base nas recompensas observadas e nas estimativas de valor futuro, eventualmente aprendendo a tomar decisões ótimas que o levam à saída do labirinto com a maior eficiência possível. Este processo exemplifica a essência do Q-Learning: aprender a tomar decisões ótimas através da exploração e da exploração do ambiente.
Continuando com a exploração do Q-Learning, é crucial entender como o agente decide suas ações durante a exploração do ambiente. Essa exploração é balanceada com a exploração, pois o agente precisa equilibrar entre a escolha de ações que ele já sabe que são boas (exploração) e a experimentação de novas ações para aprender mais sobre o ambiente (exploração).
Uma estratégia comum para equilibrar essa exploração-exploração é a política ε-greedy. Essa política consiste em escolher a melhor ação com probabilidade 1-ε e escolher uma ação aleatória com probabilidade ε. Isso significa que, na maioria das vezes, o agente escolherá a melhor ação conhecida até o momento, mas ocasionalmente tentará ações aleatórias para explorar novas possibilidades.
Essa estratégia é vital para evitar que o agente fique preso em ótimos locais locais e continue a explorar o espaço de ações e estados de maneira abrangente.
Para ilustrar essa estratégia, vamos considerar o exemplo do agente de navegação em um labirinto novamente. Durante o treinamento, o agente pode usar a política ε-greedy para decidir se deve seguir o caminho que ele sabe que leva à saída (exploração) ou tentar um novo caminho aleatoriamente (exploração). Com o tempo, à medida que o agente aprende mais sobre o ambiente e as recompensas associadas a diferentes ações, a probabilidade de escolher a exploração diminui, e o agente se torna mais consistente em suas decisões.
Além disso, é importante destacar que o Q-Learning não é limitado a problemas de navegação em labirintos. Na verdade, sua aplicabilidade é vasta e pode ser estendida a uma variedade de domínios do mundo real. Por exemplo, o Q-Learning pode ser aplicado em robótica, jogos, gerenciamento de tráfego, finanças e muito mais.
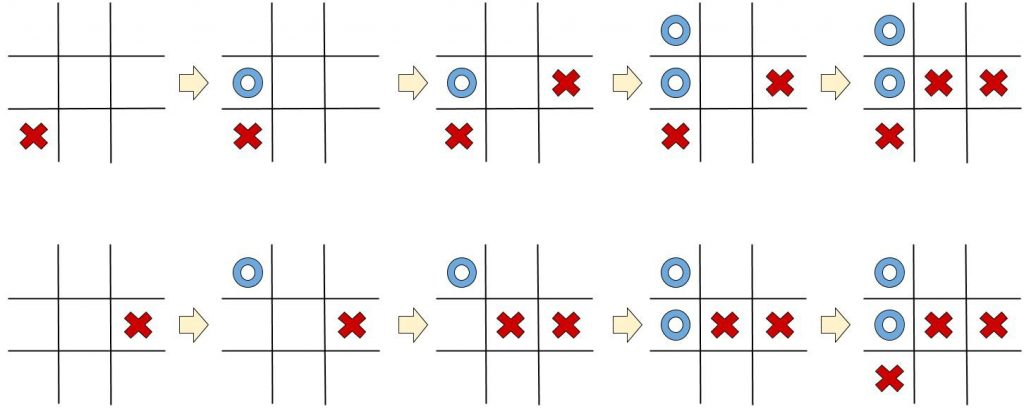
Um exemplo ainda mais relevante para nosso contexto é o uso do Q-Learning no jogo da velha. Nesse caso, os estados representam diferentes disposições do tabuleiro, enquanto as ações são as diferentes jogadas que o agente pode fazer. O objetivo do agente é aprender a tomar as melhores decisões em cada estado, com o objetivo final de ganhar o jogo.
Durante o treinamento, o agente atualiza continuamente sua estimativa de Q(s,a) com base nas recompensas observadas e nas estimativas de valor futuro, eventualmente aprendendo a tomar decisões ótimas que o levam à saída do labirinto com a maior eficiência possível. Este processo exemplifica a essência do Q-Learning: aprender a tomar decisões ótimas através da exploração e da exploração do ambiente.
Deep Q-Network (DQN)
Enquanto o Q-Learning estabeleceu as bases do aprendizado por reforço, o DQN eleva esse conceito a um novo patamar, introduzindo redes neurais profundas para lidar com estados e ações de alta dimensão de maneira eficiente.
O DQN surgiu como uma resposta à necessidade de lidar com problemas de aprendizado por reforço em ambientes complexos, onde o número de estados possíveis é vasto e a relação entre ações e recompensas não é trivial. O uso de redes neurais profundas permite ao DQN aprender representações complexas e abstratas do ambiente, o que é essencial para lidar com tarefas mais desafiadoras.
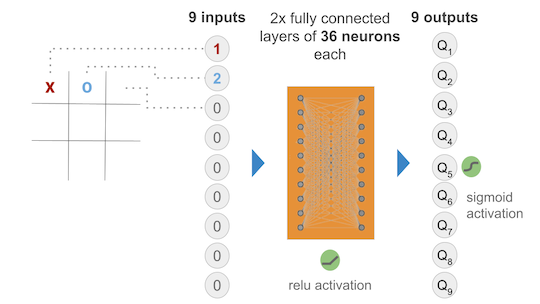
No cerne do DQN está a ideia de aproximar a função Q utilizando uma rede neural, onde a entrada é o estado do ambiente e a saída são os valores Q para cada ação possível. Em vez de atualizar diretamente a função Q como no Q-Learning tradicional, o DQN utiliza uma abordagem de aprendizado supervisionado, onde a rede neural é treinada para minimizar a diferença entre os valores Q preditos e os valores Q observados.
Matematicamente, a função Q é aproximada por uma rede neural Q(s,a;θ) , onde
θ são os parâmetros da rede. Durante o treinamento, a rede neural é ajustada iterativamente para minimizar a seguinte função de perda:
L(θ)=E[(r+γmaxa′Q(s′,a′;θ−)−Q(s,a;θ))2]
Onde:
- r é a recompensa obtida ao tomar a ação
a no estado s; - s′ é o estado resultante da transição do estado s através da ação a;
- γ é o fator de desconto;
- θ− são os parâmetros de uma cópia congelada da rede neural usada para estimar os valores Q futuros, o que estabiliza o treinamento.
Essa abordagem permite ao DQN aprender a função Q de forma mais estável e eficiente, superando muitos dos desafios associados ao treinamento de redes neurais em tarefas de aprendizado por reforço.
Para ilustrar a eficácia do DQN, consideremos um exemplo adaptado ao jogo da velha, um jogo de estratégia simples mas clássico. Neste jogo, dois jogadores se alternam marcando espaços em uma grade de 3x3 com seus respectivos símbolos (um jogador usa 'X' e o outro 'O'). O objetivo é alinhar três de seus símbolos horizontalmente, verticalmente ou diagonalmente antes do adversário.
Treinar um agente para jogar o jogo da velha usando métodos tradicionais de aprendizado por reforço, como o Q-Learning, pode ser um bom ponto de partida devido à simplicidade relativa do jogo e ao número limitado de estados possíveis em comparação com "Breakout". No entanto, a aplicação de DQN pode demonstrar a capacidade desse método em aprender estratégias eficazes em jogos de estratégia baseados em turnos.
Durante o treinamento, o DQN é exposto a milhares de partidas de jogo da velha, onde ele observa o estado do jogo (por exemplo, a configuração atual da grade) e decide qual movimento fazer para maximizar suas chances de ganhar. À medida que o agente joga mais partidas, a rede neural do DQN ajusta-se para melhorar suas previsões dos valores Q e, consequentemente, sua habilidade de jogar o jogo da velha, potencialmente aprendendo a nunca perder e, idealmente, vencer contra adversários humanos ou algoritmos mais simples.
Essa capacidade do DQN de aprender a partir de experiências, combinada com a representação rica e flexível fornecida por redes neurais profundas, o torna uma ferramenta poderosa para uma ampla gama de aplicações do mundo real. Por exemplo, além de jogos de videogame, o DQN foi aplicado com sucesso em robótica, controle de tráfego, finanças e muito mais.
Um exemplo particularmente interessante é o uso do DQN em sistemas de controle de tráfego urbano. Nesse cenário, o agente é responsável por controlar os semáforos em uma interseção para minimizar o congestionamento e melhorar o fluxo de tráfego. Cada estado do ambiente corresponde à configuração atual dos semáforos e ao estado do tráfego nas ruas adjacentes, enquanto as ações possíveis são os diferentes padrões de sinalização que o agente pode escolher.
Ao interagir com o ambiente e receber feedback na forma de recompensas (por exemplo, atraso médio no tráfego, número de veículos que passam pela interseção), o DQN aprende a tomar decisões que resultam em um tráfego mais eficiente e menos congestionado. Isso pode incluir a adaptação dinâmica dos tempos de sinalização com base nas condições em tempo real do tráfego, a fim de minimizar os atrasos e maximizar o fluxo.
Além disso, o DQN também é capaz de lidar com ambientes estocásticos e altamente dinâmicos, onde as condições do ambiente podem mudar rapidamente. Por exemplo, em um sistema de controle de tráfego urbano, o volume de tráfego e as condições das estradas podem variar de hora em hora ou mesmo de minuto em minuto. O DQN pode aprender a adaptar sua política de controle de semáforos para lidar com essas flutuações e garantir um desempenho robusto em uma variedade de condições.
Outra aplicação interessante do DQN é em sistemas de gerenciamento de portfólio financeiro. Nesse contexto, o agente é encarregado de tomar decisões de investimento, como comprar, vender ou manter ativos financeiros, com o objetivo de maximizar o retorno do investimento ao longo do tempo. Cada estado do ambiente representa as condições atuais do mercado financeiro, incluindo os preços dos ativos, as taxas de juros e outros fatores econômicos relevantes.
O agente utiliza o DQN para aprender uma política de investimento que leve em consideração a volatilidade do mercado, as tendências de longo prazo e outros fatores que afetam o desempenho do portfólio. Ao interagir com o ambiente e receber feedback na forma de retornos financeiros, o DQN ajusta suas estratégias de investimento para maximizar os lucros e minimizar os riscos.
Esses exemplos destacam a versatilidade e a eficácia do DQN como uma ferramenta para resolver uma variedade de problemas do mundo real. Ao combinar a capacidade de aprendizado por reforço com a representação poderosa fornecida por redes neurais profundas, o DQN abre novas oportunidades para automatizar tarefas complexas e tomar decisões inteligentes em ambientes dinâmicos e incertos.
Proximal Policy Optimization (PPO)
Após explorar os fundamentos do Q-Learning e do Deep Q-Network (DQN), é hora de direcionarmos nossa atenção para o Proximal Policy Optimization (PPO), um algoritmo de aprendizado por reforço que se destaca por sua estabilidade, eficiência de amostragem e facilidade de implementação.
Enquanto o Q-Learning e o DQN focam na aprendizagem do valor de ação, o PPO adota uma abordagem diferente, concentrando-se na aprendizagem direta da política de ação. Isso significa que o PPO busca aprender uma política que mapeia estados para ações diretamente, sem a necessidade de estimar explicitamente os valores de ação associados a cada par estado-ação.
A principal ideia por trás do PPO é iterativamente otimizar a política de ação, ajustando-a de forma a maximizar a recompensa esperada, enquanto limita as mudanças na política para garantir a estabilidade do treinamento. Isso é alcançado através da formulação de uma função de perda que penaliza desvios significativos da política anterior.
Matematicamente, o objetivo do PPO é maximizar a seguinte função objetivo:
J(θ)=E[min(r(θ)A, clip(r(θ),1−ε,1+ε)A)]
Onde:
- J(θ) é a função objetivo que queremos maximizar, representando a esperança do valor mínimo entre duas expressões, uma delas é o rácio entre as probabilidades das ações sob a nova política (r(θ)) e sob a política anterior, ponderado pelo vantagem estimada (A), e a outra é uma versão clipada desse rácio com um parâmetro de clipagem ε.
- r(θ) é o rácio entre as probabilidades das ações sob a nova política e a política anterior, dado por exp(log πθ(at|st)−log πθold(at|st)), onde πθ representa a nova política e πθold representa a política anterior.
- A é a vantagem estimada, que é uma estimativa da diferença entre o retorno esperado de uma ação e o valor do estado atual, representando o quão melhor é uma ação em comparação com outras ações possíveis no mesmo estado.
Essencialmente, essa função objetivo busca maximizar o desempenho da nova política em relação à política anterior, ao mesmo tempo que limita as mudanças na política para evitar oscilações indesejadas durante o treinamento.

Um aspecto único do PPO é a utilização de uma estratégia de otimização baseada em gradiente, conhecida como gradient descent, para atualizar os parâmetros da política de forma iterativa. Durante o treinamento, os gradientes da função objetivo são calculados em relação aos parâmetros da política, e os parâmetros são ajustados na direção que maximiza a função objetivo.
Para ilustrar a eficácia do PPO, consideremos um exemplo prático do mundo real: o treinamento de um agente para controlar um robô móvel em um ambiente complexo. Neste cenário, o agente é responsável por escolher ações (como mover-se para frente, para trás, girar, etc.) que maximizem sua recompensa acumulada ao longo do tempo, enquanto evita obstáculos e alcança um objetivo específico.
Durante o treinamento, o agente utiliza o PPO para aprender uma política de ação que mapeia os estados do ambiente para ações, com o objetivo de maximizar a recompensa acumulada ao longo do tempo. Através de interações repetidas com o ambiente e feedback na forma de recompensas (por exemplo, alcançar o objetivo desejado sem colisões), o agente ajusta sua política de ação para melhorar seu desempenho ao longo do tempo.
O PPO é especialmente adequado para problemas em que a estabilidade do treinamento é uma preocupação, como no caso de controle de robôs ou jogos de estratégia em tempo real. Sua abordagem conservadora para a atualização da política, combinada com a eficiência de amostragem e a facilidade de implementação, tornam-no uma escolha popular entre os pesquisadores e profissionais de aprendizado por reforço.
Além disso, o PPO tem sido aplicado com sucesso em uma variedade de domínios do mundo real, incluindo robótica, jogos, simulação de tráfego e muito mais. Sua capacidade de lidar com políticas estocásticas e ambientes dinâmicos o torna uma ferramenta poderosa para resolver uma variedade de problemas complexos.
Por exemplo, imagine um sistema de controle de tráfego urbano onde o objetivo é otimizar o fluxo de tráfego em uma rede de ruas e cruzamentos. Utilizando o PPO, um agente pode aprender uma política de controle de semáforos que se adapta dinamicamente às condições em tempo real do tráfego, minimizando os atrasos e maximizando o fluxo de veículos.
Ao interagir com o ambiente e receber feedback na forma de recompensas (por exemplo, atraso médio no tráfego, número de veículos que passam pelos semáforos), o agente ajusta sua política de controle de semáforos para melhorar o desempenho do sistema ao longo do tempo. Esse processo exemplifica a capacidade do PPO de lidar com ambientes estocásticos e altamente dinâmicos, adaptando-se de forma eficaz às mudanças nas condições do ambiente.
Outra aplicação interessante do PPO é em jogos de estratégia em tempo real, onde o agente deve aprender uma política de ação que leve em consideração a incerteza e a dinâmica do ambiente. Por exemplo, em um jogo de estratégia como o xadrez ou o StarCraft, o agente deve aprender a tomar decisões que levem à vitória, considerando as ações dos oponentes, a posição das peças e as condições do ambiente.
Ao interagir com o ambiente e receber feedback na forma de recompensas (por exemplo, vitória ou derrota no jogo), o agente ajusta sua política de ação para melhorar seu desempenho ao longo do tempo. Esse processo exemplifica a capacidade do PPO de aprender políticas complexas em ambientes dinâmicos e incertos, tornando-o uma escolha ideal para uma variedade de problemas do mundo real.
O Proximal Policy Optimization (PPO) é um algoritmo poderoso e versátil para aprendizado por reforço, oferecendo estabilidade, eficiência de amostragem e facilidade de implementação. Sua abordagem direta para a aprendizagem de políticas de ação, combinada com sua capacidade de lidar com políticas estocásticas e ambientes dinâmicos, o torna uma escolha popular para uma ampla gama de aplicações do mundo real.
Conclusão
À medida que concluímos este capítulo da nossa série, refletimos sobre os avanços significativos feitos na compreensão e aplicação dos algoritmos de aprendizado por reforço - Q-Learning, Deep Q-Network (DQN), e Proximal Policy Optimization (PPO). Cada um desses métodos oferece uma abordagem única para enfrentar os desafios da automação e inteligência artificial, destacando a profundidade e a flexibilidade do MQL5 quando combinado com o poder do Python através de APIs REST.
Exploramos o Q-Learning, que se baseia na otimização de decisões sem um modelo explícito do ambiente; o DQN, que eleva a capacidade de tratamento de estados e ações complexas por meio de redes neurais profundas; e o PPO, que busca equilibrar a eficácia da aprendizagem direta de políticas com a estabilidade do treinamento. Cada técnica abriu novas perspectivas sobre como os agentes podem aprender e adaptar-se em um espectro vasto de ambientes dinâmicos e incertos.
Enquanto nos preparamos para avançar, uma questão permanece aberta: Qual desses algoritmos de aprendizado por reforço será o mais adequado para a próxima fase de nossos projetos em MQL5? Esta pergunta não só estimula a curiosidade, mas também destaca a importância de uma escolha informada baseada na análise detalhada das características, vantagens e limitações de cada método.
Nosso próximo passo será dedicado a selecionar o algoritmo que melhor se adapta aos nossos objetivos, considerando a complexidade dos ambientes que pretendemos navegar e a eficiência operacional que aspiramos alcançar. A decisão não é trivial, pois envolve ponderar entre a facilidade de implementação, a estabilidade do treinamento e a capacidade de lidar com a complexidade do ambiente.
Convidamos nossos leitores a permanecerem conosco nesta jornada fascinante, pois o próximo capítulo promete não apenas revelar a nossa escolha, mas também mergulhar mais fundo nas implicações práticas e teóricas dessa decisão. À medida que exploramos o vasto campo do aprendizado por reforço, continuamos comprometidos em desvendar as potencialidades do MQL5 e Python na vanguarda da inovação em automação, sempre com o objetivo de aprimorar nossas estratégias e capacidades de automação.
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso