Quantificação no aprendizado de máquina (Parte 1): Teoria, exemplo de código, análise da implementação no CatBoost

Introdução
Neste artigo, discutiremos a aplicação teórica da quantização ao construir modelos baseados em árvores. O material será apresentado em linguagem acessível, sem fórmulas matemáticas complexas. Ao preparar para escrever este artigo, descobriu-se a falta de terminologia unificada nos trabalhos científicos de diferentes autores, possivelmente devido às traduções; portanto, escolherei os termos que, na minha opinião, refletem melhor o significado e usarei minha própria terminologia nos assuntos que permaneceram sem a devida atenção de outros pesquisadores. Este artigo usará termos e conceitos sobre os quais já escrevi no artigo "Algoritmo de aprendizado de máquina CatBoost da Yandex sem conhecimento prévio de Python ou R", então recomendo que se familiarize com ele antes de ler o material proposto.
Este artigo não considerará a aplicação de quantização em redes neurais treinadas para reduzir seu tamanho, pois atualmente não tenho experiência própria nessa área.
Aqui está o que o leitor encontrará neste artigo:
- A primeira parte do artigo contém material teórico introdutório sobre a quantização e será útil para entender os objetivos e a essência do processo.
- A segunda parte do artigo analisará o método uniforme de quantização com um exemplo de código em MQL5.
- A terceira parte do artigo convida você a se familiarizar com a implementação do processo de quantização no exemplo do CatBoost.
1. Objetivos padrão do uso
Então, o que é quantização e por que é usada? Vamos entender!
Primeiramente, vamos falar um pouco sobre dados. Para a criação de modelos (realização de treinamento), são necessários dados que são meticulosamente coletados em uma tabela, e a fonte desses dados pode ser qualquer informação capaz de explicar a métrica alvo (por exemplo, um sinal de negociação). As fontes de dados são chamadas de diferentes maneiras: preditores, features, atributos, fatores. A periodicidade da aparição de dados é determinada pela ocorrência de uma observação comparável do processo ou fenômeno que está sendo coletado e será estudado através do aprendizado de máquina. O conjunto de dados obtidos é chamado de amostra.
A amostra pode ser representativa, isto é, quando as observações registradas descrevem todo o processo do fenômeno estudado, ou pode ser não representativa, isto é, quando há dados apenas suficientes para descrever parcialmente o processo do fenômeno estudado. Normalmente, ao lidar com mercados financeiros, estamos lidando com amostras não representativas, porque ainda não aconteceu tudo que pode acontecer, e por isso é desconhecido como o instrumento financeiro se comportará diante de novos eventos que nunca ocorreram antes, em sua totalidade. No entanto, todos conhecem o dito "a história se repete", e é nessa observação que um operador de mercado se baseia em sua pesquisa, esperando que entre os novos eventos haja aqueles que se assemelham aos anteriores, e que o resultado deles seja com uma probabilidade identificada similar.
Quanto ao seu conteúdo lógico (na escala de medição), os indicadores numéricos dos preditores podem ser:
- Binários – confirmam ou refutam a presença de uma característica observada no fenômeno;
- Quantitativos (escala métrica) – descrevem o fenômeno com algum indicador de medição, por exemplo, isso pode incluir velocidade, coordenadas de algo, tamanho, tempo transcorrido desde o início de um evento e muitas outras características que podem ser medidas, incluindo derivadas delas.
- Categóricos (escala nominal) – indicam diferentes objetos ou fenômenos observados, mas que fazem parte de um mesmo grupo lógico, geralmente expressos por um número inteiro. Por exemplo, os dias da semana, a direção da tendência de mudança de preço, o número de um nível de suporte ou resistência.
- De ordem (escala ordinal) – caracterizam o grau de superioridade ou ordenação de algo. Raramente são destacados como um grupo separado, pois dependendo do contexto e da lógica podem ser atribuídos a outros tipos de indicadores. Por exemplo, isso pode incluir a sequência de ações, o resultado de um experimento na forma de uma avaliação de seu resultado em relação a outros experimentos semelhantes.
Assim, a amostra contém diferentes preditores com seus indicadores numéricos, e esses dados, em sua totalidade, descrevem o fenômeno observado, cujas características ou tipo são descritos na função alvo (doravante, alvo). A meta na amostra pode ser tanto um indicador numérico quanto categórico, e neste texto, refiro-me especificamente à função alvo categórica, e mais frequentemente binária.
A Wikipédia oferece a seguinte definição:
Quantização (do inglês quantization) — no processamento de sinais — é a divisão da faixa de valores amostrados de um sinal em um número finito de níveis e o arredondamento desses valores para um dos dois níveis mais próximos. Neste contexto, o valor do sinal pode ser arredondado para o nível mais próximo, ou para o nível inferior ou superior, dependendo do método de codificação. Essa quantização é chamada de escalar. Existe também a quantização vetorial, que consiste na divisão do espaço de possíveis valores de uma grandeza vetorial em um número finito de áreas e a substituição desses valores pelo identificador de uma dessas áreas.
Prefiro uma definição mais curta:
A quantização de dados é uma forma de compressão (codificação) de informações sobre uma observação com uma perda aceitável de precisão em sua escala de medição. Tal compressão (codificação) implica a discrepância dos objetos, o que implica sua uniformidade e homogeneidade, ou simplesmente semelhança. O critério de semelhança pode variar, dependendo do algoritmo escolhido e da lógica nele incorporada.
A quantização de dados é utilizada de forma generalizada, especialmente na conversão de sinal analógico para digital e na subsequente compressão do sinal digital. Por exemplo, os dados obtidos de um sensor de câmera podem ser gravados como um arquivo raw e, em seguida, comprimidos em jpg ou outro formato conveniente para armazenamento de dados, seja imediatamente ou após transferidos para um computador.
Olhando para a representação gráfica dos dados, em forma de velas ou barras, no terminal MetaTrader 5, vemos já o resultado da quantização de ticks na escala de tempo que escolhemos. Contudo, o processo de quantização de um fluxo contínuo de dados no tempo é comumente chamado de discretização.
Normalmente, discretização é o processo de captura das características de uma observação com uma frequência definida no tempo. No entanto, se considerarmos que esta é a frequência com que os dados são coletados na amostra, então a definição precisa ser ajustada para "discretização é o processo de registro das características de uma observação, cuja frequência é determinada por uma função de ativação de limiar". Por função, entende-se qualquer algoritmo que, de acordo com sua lógica embutida, sinaliza a coleta de dados. Por exemplo, no MetaTrader 5 vemos exatamente essa abordagem, pois em dias não comerciais, em vez de repetir o preço de fechamento como um processo contínuo no tempo, simplesmente não há informação no gráfico, ou seja, a frequência de discretização cai para zero.
Um exemplo simples de um algoritmo de quantização é a construção de um histograma. O algoritmo deste método é bastante simples:
- Encontramos o valor máximo e mínimo do indicador (no nosso caso, o preditor).
- Calculamos a diferença entre o valor máximo e mínimo.
- Dividimos a delta obtida no item 2 por um número inteiro, por exemplo, dez, ou, como recomenda Karl Pearson, dependendo do número de observações. Obtemos o passo de divisão nas unidades de medida iniciais, que será o marco da nova escala de medição.
- Agora precisamos construir nossa própria escala, com suas próprias divisões, o que é feito simplesmente multiplicando o passo pelo número ordinal da divisão.
- O algoritmo então implica alocar cada valor de observação ao intervalo da nova escala de medição e somar o número de observações em cada intervalo separadamente.
O resultado do trabalho do algoritmo será um histograma, mostrado na figura número 1.
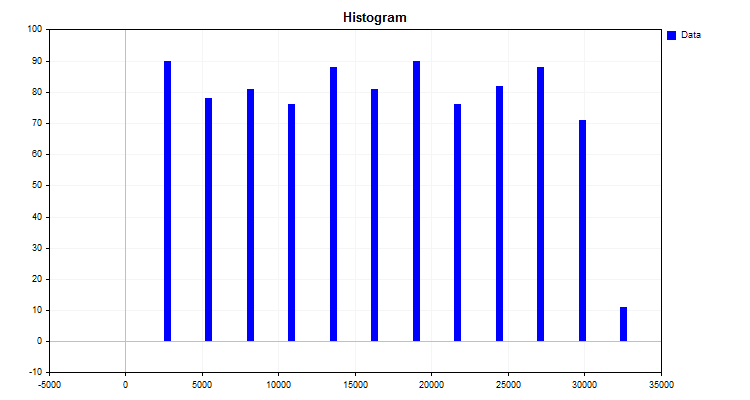
Figura 1.
No histograma, pode-se ver como os dados foram distribuídos na nova escala de medição. Pela aparência da distribuição, por meio do aparelho de estatística descritiva, pode-se inferir o tipo de densidade de distribuição, o que pode ser útil para escolher o método de quantização final. No entanto, sugiro que se familiarize com o tema da densidade de distribuição nos artigos disponíveis em nosso portal favorito:
- Estimativa de densidade de probabilidade desconhecida;
- Distribuição Estatística no MQL5 - tirando o melhor de R e o fazendo mais rápido ;
- Estimativas estatísticas.
Então, o que conseguimos ao construir o histograma:
- Níveis (cortes) ou bordas, que dividiram os dados em grupos. O conjunto de níveis é chamado de grade quântica ou dicionário; é através destes níveis que ocorre o processo de codificação dos dados, que proporciona sua agrupação e compressão. As bordas podem ser definidas de acordo com diferentes regras incorporadas ao algoritmo de quantização. Os níveis (cortes) formam uma nova escala para a medição dos indicadores de observação. Estou acostumado a chamar o intervalo entre dois níveis de "intervalo quântico", embora na literatura encontrem-se outros nomes, como "intervalo", "faixa", "passo de quantização";
- A cada valor de observação (indicador) é atribuída uma categoria conforme o grupo (coluna no histograma). Para a quantização, trata-se do trabalho de um algoritmo de compressão, cuja essência é transformar os dados originais em dados compactados no momento em que o valor da observação é atribuído a um determinado intervalo da grade quântica. O resultado da compressão pode ser uma transformação numérica diferente do valor da variável. Comumente encontram-se duas opções: a primeira consiste em uma transformação em que à variável é atribuído um posto (índice) pelo número do intervalo entre os cortes (bordas), onde o número foi inserido, e a segunda opção é a atribuição à variável do valor da escala de nível, por exemplo, se o valor numérico da observação se enquadra no intervalo entre 1,2 e 1,4, é atribuído o valor à direita – 1,4. No entanto, para aplicar a segunda opção, é necessário definir limites além dos quais os dados não podem passar, enquanto a primeira opção permite trabalhar com quaisquer valores fora dos limites da tabela quântica. Para a segunda opção, uma boa solução pode ser a adição forçada de níveis (bordas/limites) a uma distância significativa, o que permitirá acomodar erros na forma de valores atípicos ou falta de dados.
- A possibilidade de restaurar cada valor numérico com perda de precisão (dequantização), que pode ser realizada das seguintes maneiras:
- No centro do intervalo, que corresponde ao índice do número.
- Pelo valor esquerdo ou direito do nível (limite/corte/borda) do intervalo, mais frequentemente pelo direito. Considerando que para o primeiro e último intervalo as fronteiras na tabela de quantização geralmente não são definidas, para determiná-las pode-se usar o intervalo médio ou o primeiro e último valor da largura do intervalo.
Dependendo da tarefa e da área de aplicação da quantização, deparamo-nos com diferentes denominações de variáveis e estilos de escrita de fórmulas, o que dificulta o entendimento da essência do algoritmo, uma vez que o autor que as descreve pressupõe conhecimento de uma área específica onde o algoritmo é aplicado. A essência de diferentes algoritmos resume-se a diferentes métodos de construção de níveis (cortes), por isso proponho classificá-los segundo uma série de características.
Quantização com intervalo constante:
- Divisão em intervalos fixos por um método semelhante ao histograma de Pearson;
- Transformação para redução do dígito do número.
Quantização com intervalo variável:
- Acumulação de uma percentagem fixa de observações para cada intervalo.
- Uso de um valor fixo da área sob a curva de distribuição teórica ou aproximada.
- Uso de uma função designada, alterando o passo de quantização dependendo do coeficiente. Frequentemente são funções que expandem o intervalo para a borda ou para o centro.
- Uso de coeficientes de peso, influenciando o intervalo, dependendo da densidade dos valores.
- Métodos iterativos, incluindo métodos adaptativos. Para configurar os bordas, usa-se informação sobre a estrutura dos dados, e são realizadas ações para reduzir o erro.
- Outros métodos.
Quantização com intervalo empiricamente definido:
- Sequências numéricas;
- Conhecimento sobre a natureza da observação, que permite agrupar indicadores semanticamente similares;
- Método manual de anotação.
A redução do erro de quantização na métrica escolhida pode ser um processo iterativo ou pode ser calculado uma única vez por uma fórmula específica. Para avaliar o resultado, é conveniente usar a porcentagem média de dispersão do erro em relação ao intervalo total de números que assumem o valor do preditor na amostra.
2. Exemplo de implementação do algoritmo de quantização em MQL5
Anteriormente analisamos um exemplo simples de como ocorre a quantização, mas nele falta uma etapa frequentemente usada na quantização, a saber, a repartição da escala obtida após alguns cálculos, com o objetivo de encontrar o valor médio do intervalo, frequentemente chamado de centroide. Exatamente pela metade da distância entre as fronteiras de dois centroides adjacentes será finalmente definido o intervalo para a quantização.
Vamos, por exemplo, passo a passo fazer a quantização de números reais, do tipo double, que ocupam 8 bytes na memória, em um tipo de dados inteiro uchar, que ocupa apenas 8 bits:
- 1. Encontramos o máximo e o mínimo nos dados de entrada:
- 1.1. Encontramos o valor máximo e mínimo - variável Max e Min no array arr_In_Data.
- 2. Calculamos o tamanho da janela entre os intervalos:
- 2.1. Encontramos a diferença entre máximo e mínimo, e salvamos na variável Delta.
- 2.2. Encontramos o tamanho de uma janela Delta/nQ, onde nQ, número de divisores (bordas), resultado salvo na variável Interval_Size.
- 3. Realizamos a quantização e cálculo do erro:
- 3.1. Fazemos o deslocamento do valor mínimo dos dados de entrada para zero arr_In_Data-Min.
- 3.2. Dividimos o resultado do item 3.1 pelo número de intervalos Interval_Size, que é um mais que o número de divisores.
- 3.3. Agora ao resultado obtido no item 3.2 aplicamos a função round, que arredonda o número para o inteiro mais próximo. O resultado será salvo no array arr_Output_Q_Interval.
- 3.4. O valor do array arr_Output_Q_Interval multiplicamos pelo Interval_Size e adicionamos o mínimo. E assim obtivemos o valor transformado (dequantizado) do número, que será salvo no array arr_Output_Q_Data.
- 3.5. Calculamos o erro acumulado, para isso dividimos a diferença absoluta entre o valor original e o obtido após a quantização pelo intervalo. O total resultante é dividido pelo número de elementos no array arr_In_Data.
- 4. Salvamos os divisores (bordas) no array arr_Output_Q_Book:
- 4.1. Para o primeiro intervalo fazemos um ajuste - ao valor mínimo (Min) adicionamos metade do tamanho do intervalo (Interval_Size).
- 4.2. Os intervalos subsequentes são calculados já adicionando o valor do intervalo ao valor do array arr_Output_Q_Book no passo anterior.
Exemplo de código da função com descrição das variáveis e arrays pode ser visto abaixo.
/+---------------------------------------------------------------------------------+ //|Квантование - типа преобразования (кодирования) в заданную целочисленную битность //+---------------------------------------------------------------------------------+ double Q_Bit( double &arr_Input_Data[],//Массив с данными для квантования int &arr_Output_Q_Interval[],//Исходящий массив с интервалами, в которые попали данные double &arr_Output_Q_Data[],//Исходящий массив с восстановленными значениями исходных данных float &arr_Output_Q_Book[],//Исходящий массив - "Книга с границами" или "Таблица квантования" int N_Intervals=2,//Число интервалов, на которые надо разделить (отквантовать) исходные данные bool Use_Max_Min=false,//Использовать входящие значения максимума и минимума или нет double Min_arr=0.0,//Максимальное значение double Max_arr=100.0//Минимальное значение ) { if(N_Intervals<2)return -1;//Минимум интервалом может быть два, тогда разделитель один //---0. Инициализируем переменные и копируем массив arr_Input_Data double arr_In_Data[]; double Max=0.0;//Максимум double Min=0.0;//Минимум int Index_Max=0;//Индекс максимума в массиве int Index_Min=0;//Индекс минимума в массиве double Delta=0.0;//Разница между максимумом и минимумом int nQ=0;//Число разделителей (бордюров) double Interval_Size=0.0;//Размер интервала int Size_arr_In_Data=0;//Размер массива arr_In_Data double Summ_Error=0.0;//Для расчета ошибки/потерь данных nQ=N_Intervals-1;//Число разделителей Size_arr_In_Data=ArrayCopy(arr_In_Data,arr_Input_Data,0,0,WHOLE_ARRAY); ArrayResize(arr_Output_Q_Interval,Size_arr_In_Data); ArrayResize(arr_Output_Q_Data,Size_arr_In_Data); ArrayResize(arr_Output_Q_Book,nQ); //---1. Находим максимум и минимум во входных данных if(Use_Max_Min==false)//Если не используется принудительные пределы массива { Index_Max=ArrayMaximum(arr_In_Data,0,WHOLE_ARRAY); Index_Min=ArrayMinimum(arr_In_Data,0,WHOLE_ARRAY); Max=arr_In_Data[Index_Max]; Min=arr_In_Data[Index_Min]; } else//Иначе установим принудительно максимум и минимум { Max=Max_arr; Min=Min_arr; } //---2. Рассчитываем размер окна между интервалами Delta=Max-Min;//Разница между максимумом и минимумом Interval_Size=Delta/nQ;//Размер одного окна //---3. Производим квантование и подсчет ошибки for(int i=0; i<Size_arr_In_Data; i++) { arr_Output_Q_Interval[i]=(int)round((arr_In_Data[i]-Min)/Interval_Size); arr_Output_Q_Data[i]=arr_Output_Q_Interval[i]*Interval_Size+Min; Summ_Error=Summ_Error+(MathAbs(arr_Output_Q_Data[i]-arr_In_Data[i]))/Delta; } //---4. Сохраним разделители (бордюры) в массив for(int i=0; i<nQ; i++) { switch(i) { case 0: arr_Output_Q_Book[i]=float(Min+Interval_Size*0.5); break; default: arr_Output_Q_Book[i]=float(arr_Output_Q_Book[i-1]+Interval_Size); break; } } return Summ_Error=Summ_Error/(double)Size_arr_In_Data*100.0; }
O que a quantização de dados proporciona em termos práticos:
- Redução da memória necessária para armazenamento e processamento de dados. Este efeito é alcançado porque é suficiente armazenar apenas o índice do segmento quântico em que o valor numérico do indicador se enquadra. Neste contexto, faz sentido mudar o tipo de dados de double ou float para tipos inteiros, como int ou mesmo uchar.
- Aceleração dos cálculos. Isso é alcançado pelo trabalho com números inteiros e pela redução do conjunto de números usados, o que diminui o número de ciclos nos algoritmos.
- Redução de ruído. A qualidade dos dados originais pode conter ruído, obtido como erros de medição, tanto primários – perda de dados do corretor, quanto na forma de atrasos, erros de arredondamento e medição; a quantização, em essência, média o indicador dentro do intervalo do segmento quântico, o que suaviza esse ruído e impede que o modelo foque nele.
- Compensação pela falta de valores de observação próximos. Às vezes, o valor do preditor é muito raro devido à falta de observações, e não pode ser considerado um outlier; a quantização pode dar a essas observações um intervalo de dispersão suficiente, o que torna o uso do modelo em novos dados, que não estavam na amostra, viável.
- Combate à maldição da dimensionalidade. A redução do número de combinações possíveis diminui a grade de coordenadas possíveis do espaço de medição, o que acelera e melhora o processo de treinamento.
Em dois exemplos, vimos que existem duas estratégias principais de quantização:
- Estratégia voltada para a aproximação dos dados.
- Estratégia voltada para a agregação dos dados.
O primeiro tipo de estratégias é mais adequado para escalas métricas, que medem indicadores cujos valores de características são próximos de uma distribuição contínua. Teoricamente, aqui, quanto mais intervalos dividindo o alcance dos valores, melhor, pois menor será o erro de dispersão do valor restaurado em toda a faixa numérica. Este tipo é bem adequado para a restauração de funções matemáticas.
O segundo tipo de estratégias é direcionado para a agrupação de dados, pode-se imaginar que estão sendo criados valores categóricos generalizados das características, e aqui a tarefa de avaliação correta das fronteiras é muito mais complexa – na minha experiência, deve-se tentar garantir que o intervalo inclua pelo menos 5% das observações da amostra.
Vale ressaltar que características que são por natureza categóricas, sem qualquer condição, devem ser quantizadas com muito cuidado, agrupando apenas aquelas que são realmente semelhantes. Aqui, semelhança implica em similaridade na amostra quando divididas em subamostras.
O script "Q_Trans" anexado ao artigo serve como exemplo do processo de quantização, os dados para quantização são gerados aleatoriamente, ele contém as seguintes funções principais:
- "Q_Bit" - Quantização - tipo de transformação (codificação) em uma bitola inteira específica
- "Book_to_cifra" - Decodificador - restaura o valor aproximado do número da Tabela de Quantização, requer um array com índices.
- "Book_to_cifra_v2" - Decodificador - restaura o valor aproximado do número da Tabela de Quantização, não requer um array com índices.
- "Q_Random" - Quantização – com estabelecimento aleatório de fronteiras.
O script contém as seguintes configurações:
- Número de intervalos nos quais os dados originais devem ser divididos (dequantizados);
- Número inicializador para o gerador de números aleatórios;
- Salvar gráficos;
- Diretório para salvar os gráficos;
- Largura do gráfico;
- Altura do gráfico;
- Tamanho da fonte.
Descrição das etapas do trabalho do script:
- Uma amostra será gerada aleatoriamente.
-
No gráfico do instrumento comercial será exibido o gráfico do histograma, construído como descrito anteriormente no artigo (Figura №1), bem como um gráfico com os valores do preditor gerado, que são distribuídos em ordem cronológica e divididos por fronteiras obtidas após a quantização (Figura №2). Se a configuração "Salvar gráficos" estiver definida como "true", os gráficos serão salvos no diretório de arquivos do usuário do terminal "Files\Q_Trans\Graphics".
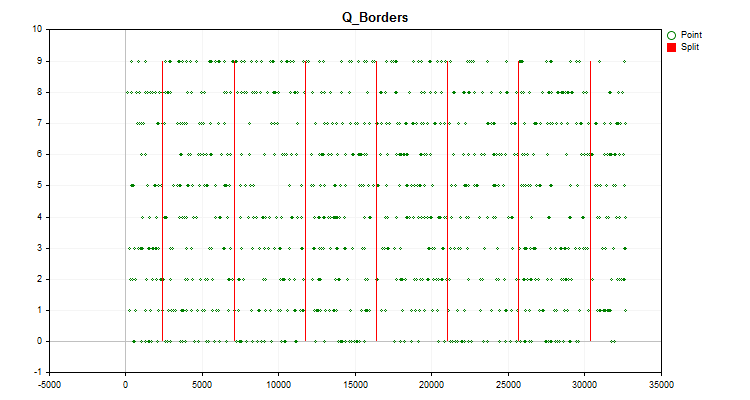 Figura №2.
Figura №2. - Com a função "Q_Bit", a quantização será realizada e o erro será calculado como o desvio do valor restaurado em relação a todo o intervalo de valores da amostra.
- Com a função "Book_to_cifra", a dequantização será realizada pelo centroide e o erro será calculado como o desvio do valor restaurado.
- Com a função "Book_to_cifra", a dequantização será realizada pela borda direita e o erro será calculado como o desvio do valor restaurado.
- Com a função "Book_to_cifra_v2", a dequantização será realizada pelo centroide e o erro será calculado como o desvio do valor restaurado.
- Com a função "Q_Random", serão realizadas 1000 tentativas para encontrar os melhores intervalos para dividir o preditor.
- Com a função "Book_to_cifra", a dequantização será realizada usando a melhor grade obtida aleatoriamente pelo centroide e o erro será calculado como o desvio do valor restaurado.
Se o script for executado com as configurações padrão, então no log do terminal "Especialistas", veremos a seguinte informação na coluna "Mensagem":
Средний размер ошибки восстановления данных = 3.52% от всего диапазона, при использовании 8 интервалов Средний размер ошибки через квантовую таблицу для преобразования по центроиду (Book_to_cifra) = 1145.62263 Средний размер ошибки через квантовую таблицу для преобразования по правой границе (Book_to_cifra) = 2513.41952 Средний размер ошибки через квантовую таблицу для преобразования по центроиду (Book_to_cifra_v2) = 1145.62263 Средний размер ошибки через квантовую таблицу для преобразования по центроиду (Q_Random) = 1030.79216
É interessante notar que o método aleatório de escolha de fronteiras mostrou um resultado até melhor do que o método de quantização uniforme que analisamos anteriormente.
3. Quantização com CatBoost
O CatBoost, sobre o qual escrevi anteriormente em meu artigo "Aprendizado de Máquina pelo Yandex (CatBoost) sem Estudar Python e R", utiliza a quantização para pré-processamento de dados, o que permite acelerar significativamente o trabalho do algoritmo de boosting gradiente. Como antes, usarei a versão console do CatBoost, pois ela não requer a instalação de software adicional quando executada no processador central do computador.
As seguintes configurações serão necessárias:
1. Método de quantização (divisão) – chave "--feature-border-type":
- Median
- Uniform
- UniformAndQuantiles
- MaxLogSum
- MinEntropy
- GreedyLogSum
2. Número de divisores de 1 a 65535 – chave "--border-count"
3. Salvar a tabela de quantização em um arquivo especificado – chave "--output-borders-file"
4. Carregar a tabela de quantização de um arquivo especificado – chave "--input-borders-file"
Se essas chaves não forem especificadas, as configurações padrão para os modelos usados no artigo serão aplicadas:
- Para cálculos em CPU o método de quantização "GreedyLogSum", número de divisores "254";
- Para cálculos em GPU o método de quantização "GreedyLogSum", número de divisores "128".
Exemplificarei como inserir essas chaves:
Configuramos a quantização, definindo o método "Uniform" e o número de divisores como 30, e salvamos a tabela de quantização no arquivo "Quant_CB.csv"
catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description Test_CB_Setup_0_000000000 --has-header --delimiter ; --train-dir ..\Rezultat --feature-border-type Uniform --border-count 30 --output-borders-file Quant_CB.csv
Carregamos a tabela de quantização do arquivo "Quant_CB.csv" e treinamos o modelo
catboost-1.0.6.exe fit --learn-set train.csv --test-set test.csv --column-description Test_CB_Setup_0_000000000 --has-header --delimiter ; --train-dir ..\Rezultat --input-borders-file Quant_CB.csv
Para mais informações sobre as configurações de quantização do desenvolvedor, consulte o seguinte link.
Vamos ver como os métodos de quantização diferem quando aplicados a dados específicos. Abaixo estão gráficos em forma de arquivos gif, cada novo quadro mostra um método diferente, escolhi 16 como o número de divisores.
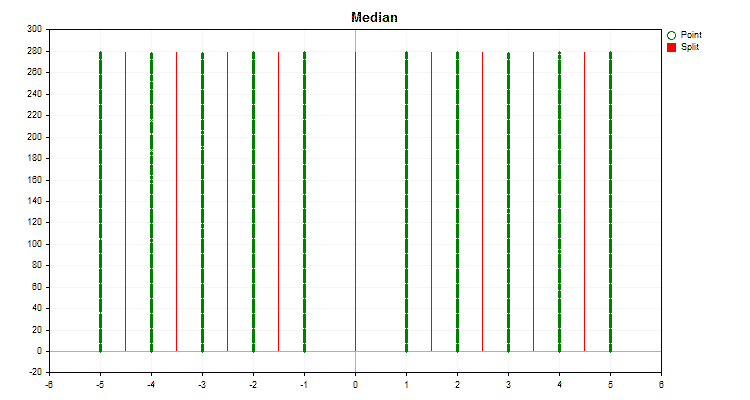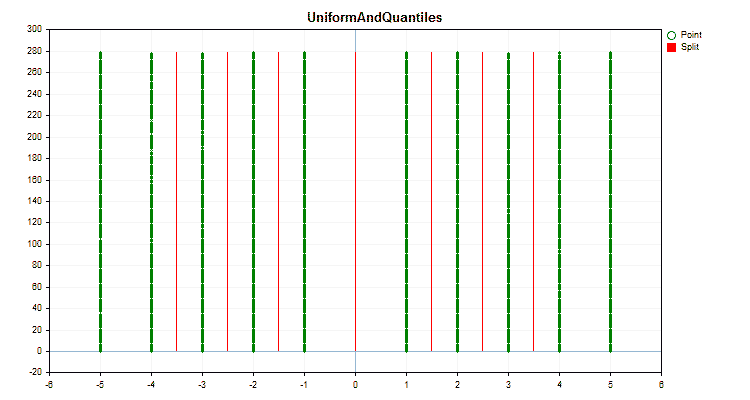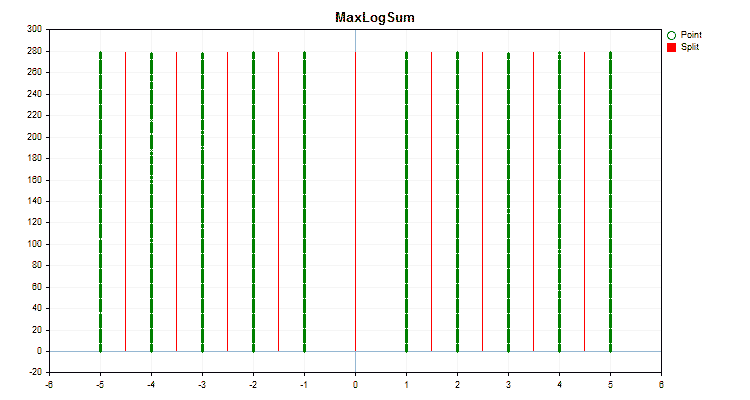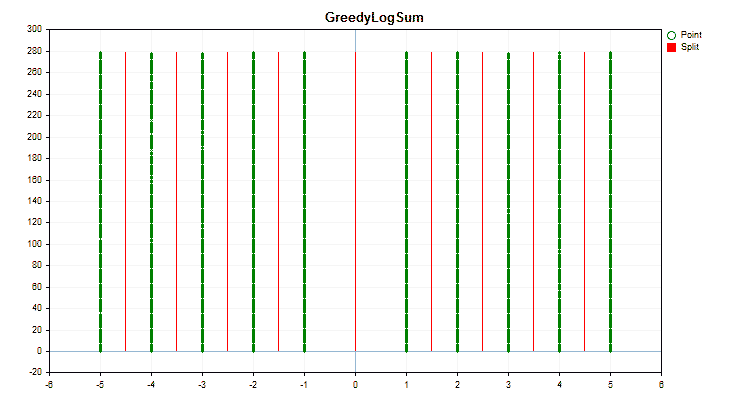
Figura №2 "Gráfico de dados para o preditor categórico"
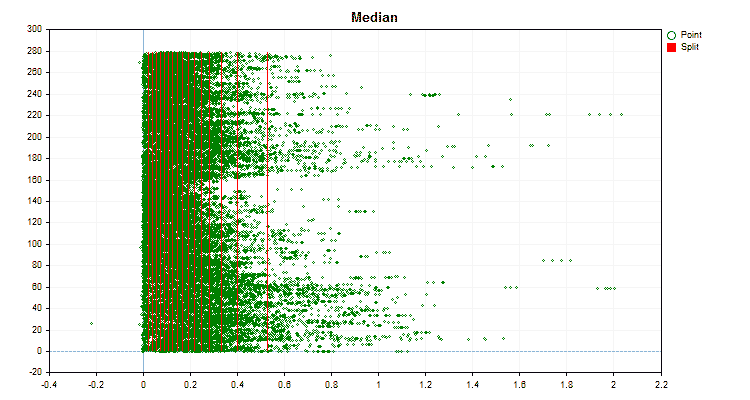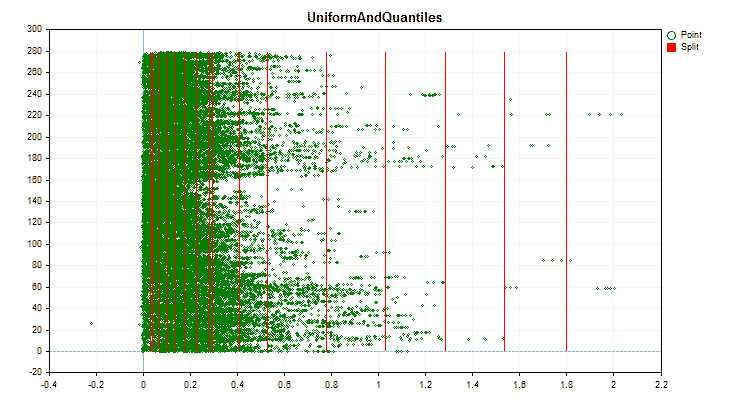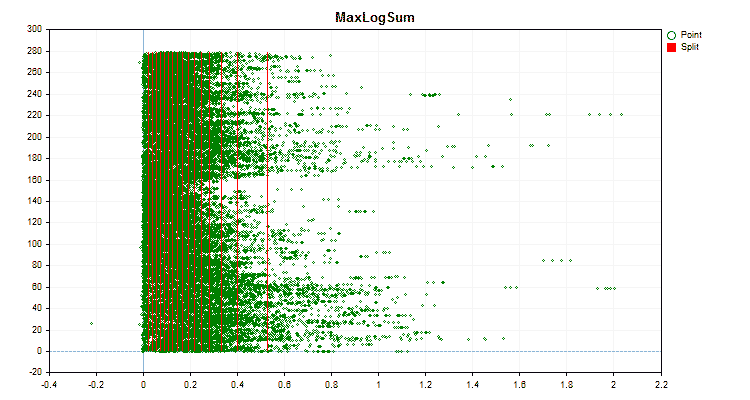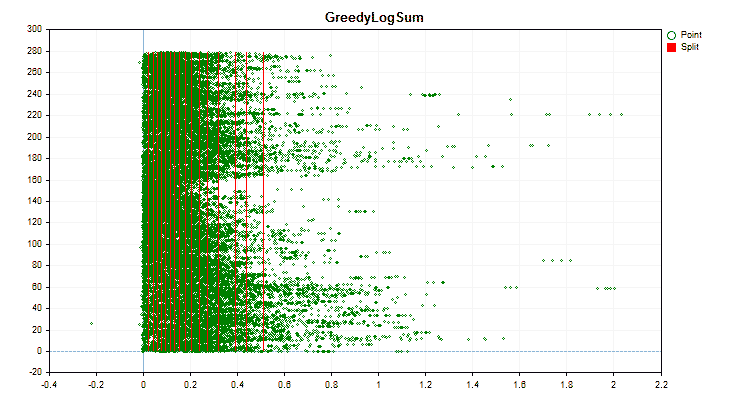
Figura №3 "Gráfico de dados para o preditor com deslocamento de valores para a área esquerda"
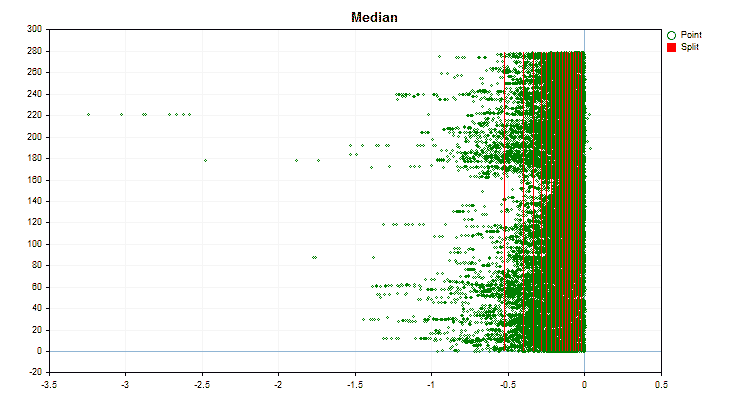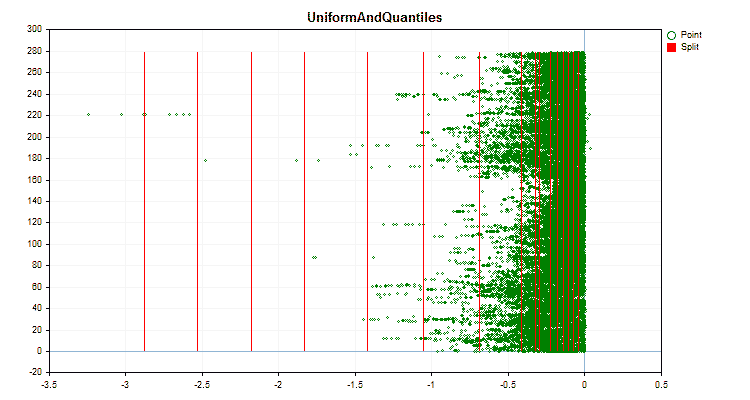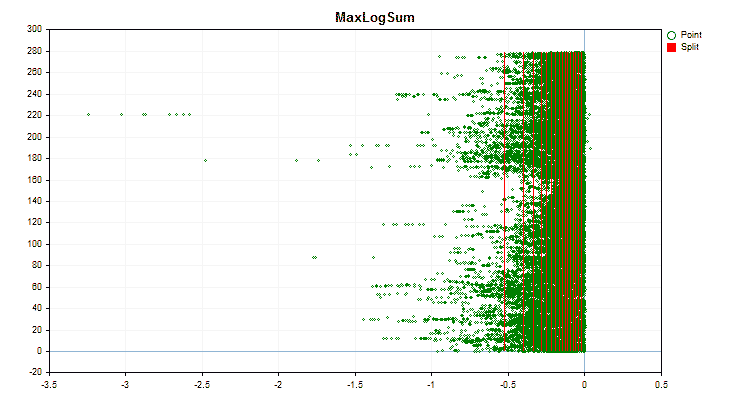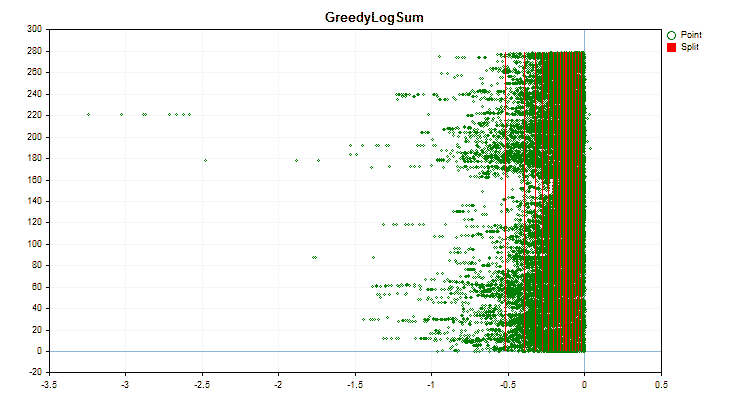
Figura №4 "Gráfico de dados para o preditor com deslocamento de valores para a área direita"
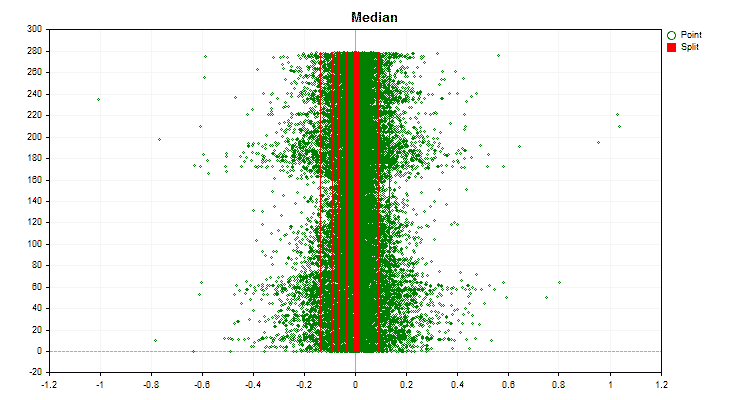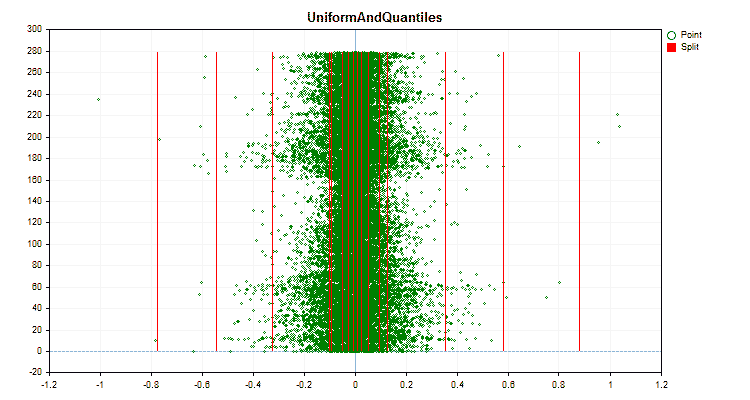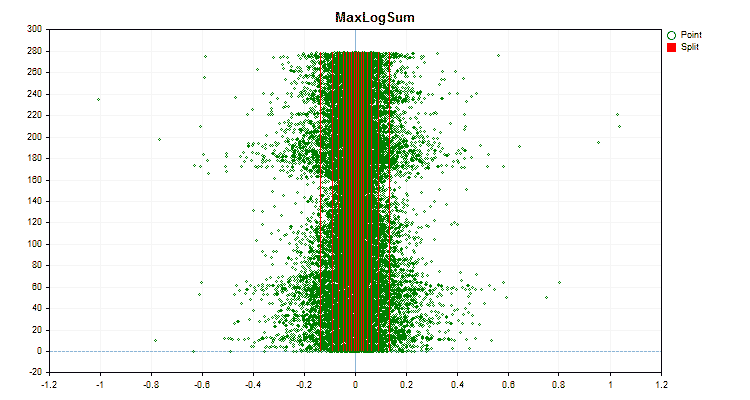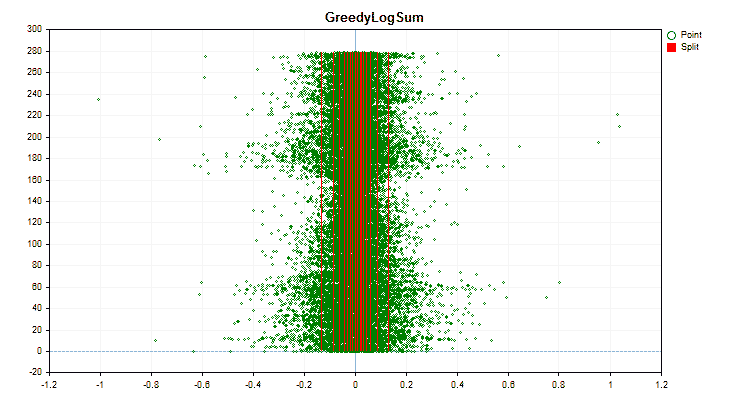
Figura №5 "Gráfico de dados para o preditor com valores posicionados na área central"
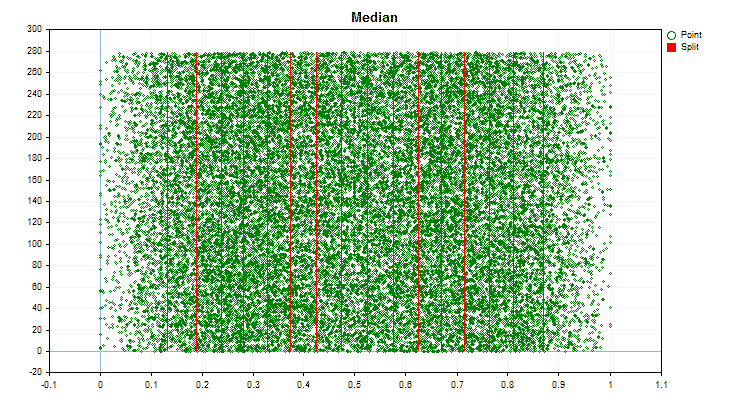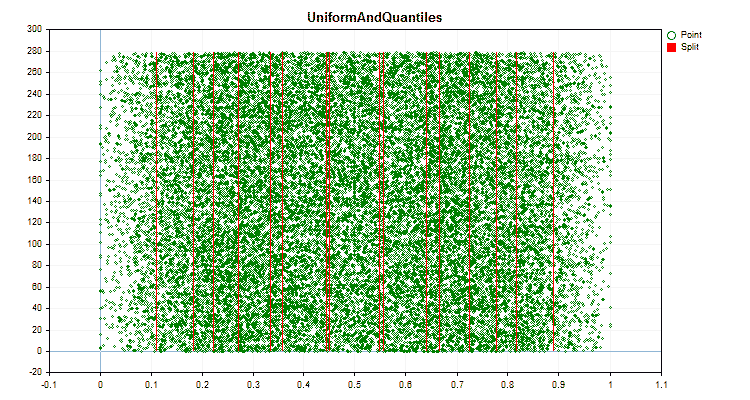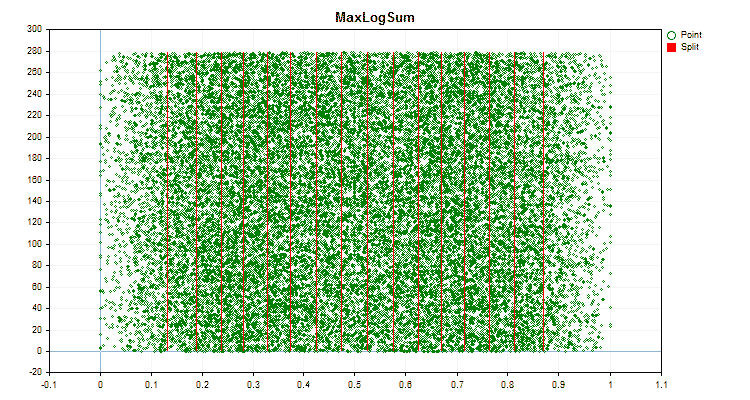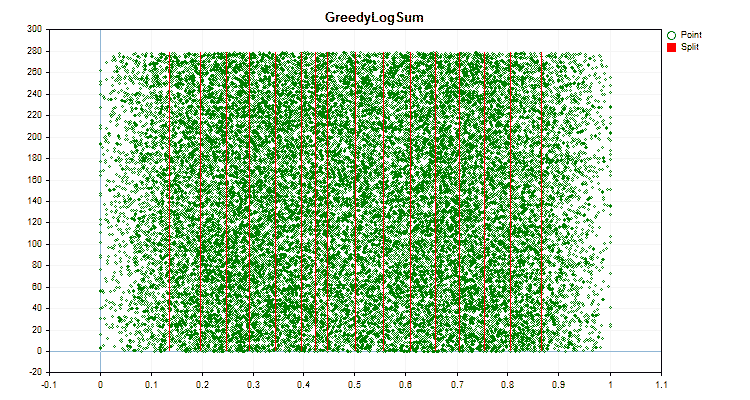
Figura №6 "Gráfico de dados para o preditor com distribuição uniforme de valores"
Se olharmos a estrutura do arquivo com a tabela de quantização, neste caso o arquivo "Quant_CB.csv", veremos duas colunas e muitas linhas. Na primeira coluna é salvo o número ordinal do preditor que será usado no treinamento do modelo, e na segunda o divisor (borda/nível). O número de linhas corresponde ao total de divisores, e o número na primeira coluna muda após todos os divisores serem listados.
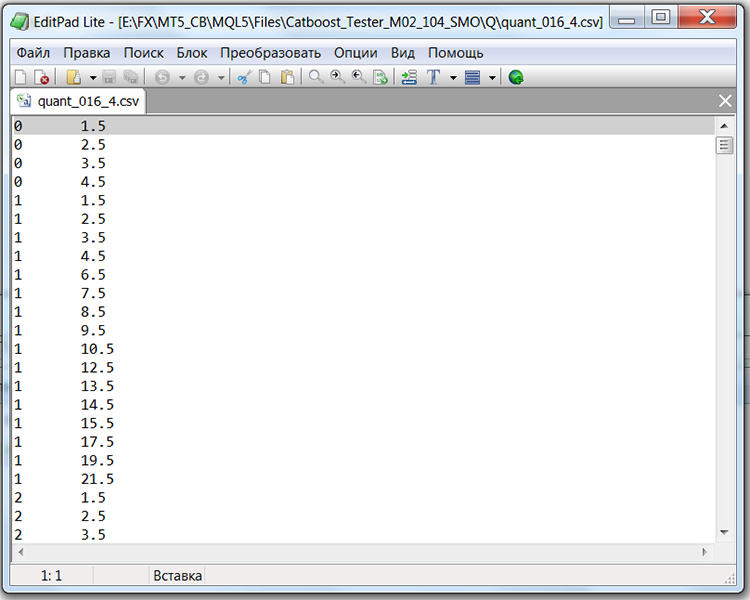
Tabela 1 "Conteúdo do arquivo salvo do CatBoost com divisores"
Considerações finais
Neste artigo, familiarizamo-nos com o conceito de quantização, através de um exemplo de código em MQL5 discutimos o processo de obtenção de valores dequantizados do preditor, e examinamos a implementação da quantização no CatBoost.
Se você, caro leitor, encontrar erros nos termos ou argumentos apresentados no artigo, por favor escreva sobre isso; está em seu poder melhorar o texto apresentado para o benefício de nossa comunidade.
No próximo artigo, exploraremos como selecionar tabelas de quantização para um preditor específico, e também conduziremos um experimento para avaliar a viabilidade dessa atividade.
| № | Apêndice | Descrição |
|---|---|---|
| 1 | Q_Trans.mq5 | Script que contém um exemplo de quantização uniforme em uma amostra aleatória. |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13219
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso