Teoria das Categorias em MQL5 (Parte 16): funtores com perceptrons multicamadas
Introdução
Em nossa série de artigos, mostramos como alguns conceitos fundamentais da teoria das categorias podem ser representados e utilizados no código MQL5 para ajudar os traders a desenvolver sistemas de negociação mais confiáveis. Existem muitos aspectos da teoria das categorias, mas os funtores e as transformações naturais, provavelmente, são os aspectos-chave. Retornando aos funtores (como nos dois artigos anteriores), destacamos uma das ideias fundamentais da teoria.
No entanto, neste artigo, apesar de ainda falarmos sobre funtores, vamos explorar sua aplicação para geração de sinais de entrada e saída, ao contrário do artigo anterior, que focava apenas na configuração do trailing stop. Isso novamente não significa que o código fornecido seja o Santo Graal. Em vez disso, é uma ideia que o leitor deve aprimorar e modificar de acordo com sua visão dos mercados.
Breve revisão do artigo anterior: Funtores e grafos em MQL5
Funtores são um mapeamento (mapping) de categorias, que fixam as relações não apenas entre objetos existentes em duas categorias, mas também entre os morfismos dessas categorias. Isso implica que implementamos uma de duas confrontações no código ao fazer previsões.
Na série na parte 11 foram introduzidos os Grafos, eles podem ser vistos como representações de sistemas interconectados com setas e vértices. No artigo anterior, ilustramos isso com dados do calendário econômico disponíveis no terminal MetaTrader 5, e usamos uma hipótese simples que relaciona 4 diferentes pontos de dados que fazem parte de uma série temporal. Este grafo, como mostrado no artigo, é de fato uma categoria separada.
Por outro lado, os funtores, examinados em nosso último artigo, mapeiam duas categorias usando uma simples equação linear. No código publicado, havia opções para escalar até uma equação quadrática, mas elas não foram implementadas no teste realizado para o artigo. Assim, o mapeamento do funtor, essencialmente, pegava o valor do objeto na categoria do domínio, multiplicava-o por um coeficiente e adicionava uma constante, para obter o valor do objeto no codomínio. Era linear porque o coeficiente e a constante representavam, de fato, a inclinação e o ponto de interseção com o eixo y de uma simples equação linear.
Funtores da teoria das categorias baseados em dados do calendário econômico
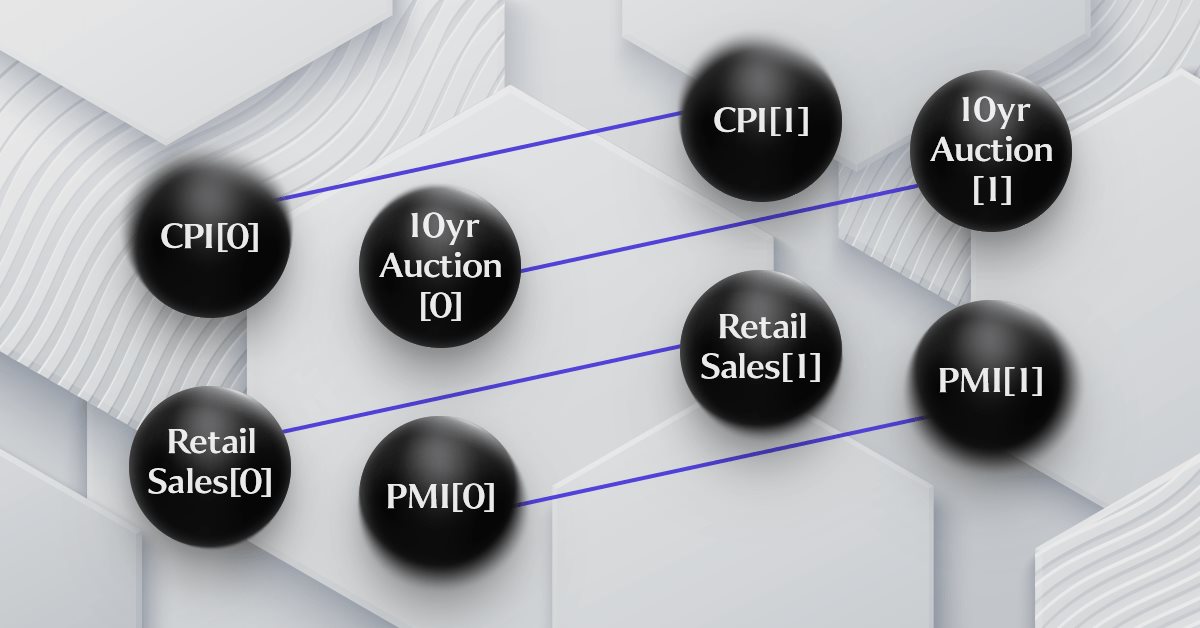
A reformatação dos dados do calendário econômico como uma categoria, alcançada por meio de grafos, provou ser apropriada, dada a complexa interconexão dos dados do calendário. Como pode ser visto na aba do calendário no terminal MetaTrader 5, existem muitos tipos diferentes de dados econômicos. Esse problema foi destacado no artigo anterior, onde a necessidade de mapear ou confrontar esses dados ao tomar decisões de negociação para um par de moedas pode ser complicada devido à dependência da moeda. Para garantir a segurança, não é necessário combinar os dados, embora o fato de alguns desses dados dependerem de outros dados econômicos deva ser levado em consideração, especialmente considerando que estamos trabalhando com o S&P 500. Para resolver esse problema, no último artigo propusemos uma hipótese simples de que o Índice de Preços ao Consumidor (CPI) depende do Índice de Gestão de Compras (PMI), que por sua vez depende do resultado dos leilões de títulos do Tesouro de 10 anos (10-year yield auction), cujos resultados, por sua vez, dependem das vendas no varejo. Assim, em vez de uma série temporal de apenas um desses pontos de dados econômicos, temos uma série de vários pontos que constituem a base da volatilidade do S&P 500.
No entanto, neste artigo, estamos interessados no índice S&P 500 não apenas por sua volatilidade, como nos artigos anteriores, mas também por suas tendências. Queremos fazer previsões sobre suas tendências de curto prazo (mensais) e usar essas previsões para abrir posições com nosso EA. Isso significa que manusearemos a classe de sinais do EA, e não a classe de trailing, como tem sido até agora nesta série. Desse modo, a implementação de transformações baseadas em funtores em dados do calendário econômico levará a uma mudança prevista no índice S&P 500. Tal implementação será alcançada com o uso de um perceptron multicamadas.
No último artigo, apresentei uma representação esquemática da nossa simples hipótese, que liga os quatro pontos de dados econômicos considerados, mas ela era excessivamente simplificada e não era representada como um grafo de série temporal. Tentaremos alcançar isso no esquema abaixo:

Como você pode ver no diagrama, a adição de objetos de série temporal acrescenta alguma complexidade, o que claramente confirma o fato de que é um grafo. A hipótese em que se baseia o esquema é controversa. Alguém poderia dizer, por exemplo, que o Índice de Preços ao Consumidor é o resultado das vendas no varejo, que por sua vez são influenciadas pelo PMI, que depende da massa monetária, medida com base nos resultados dos leilões de 10 anos. Existem até outras variantes com outros dados econômicos ou mais importantes, que podem ter uma influência mais significativa na delta da previsão do S&P 500. A boa notícia é que, apesar de todas essas possíveis permutações e hipóteses, o testador de estratégias no terminal pode refutar todos esses argumentos, por isso é útil articular claramente suas ideias em um formato que possa ser efetivamente testado.
Para ajudar nisso, o assistente MQL5 permite compilar facilmente um Expert Advisor em alguns cliques, mesmo que tudo o que você tenha escrito seja um arquivo de sinal.
Funtores da teoria das categorias para valores do índice S&P 500
No arquivo de sinal, a representação dos valores do índice S&P 500 como um grafo constitui uma categoria, pois, como descrito no último artigo, cada vértice do grafo (ponto de dados) é equivalente a um objeto, e, assim, as setas entre os vértices podem ser consideradas como morfismos. Um objeto pode ter um único elemento, mas neste caso, o ponto de dados inclui mais do que apenas o valor de interesse para nós, pois dados adicionais, não considerados para a nossa categoria, incluem: a data de publicação dos dados econômicos, previsões de consenso para esses dados antes de sua divulgação e outros dados. Todos eles estão listados na aba do calendário no terminal MetaTrader. Este link leva à página com tipos de eventos do calendário, e cada atributo listado será aplicável ao nosso objeto. Todos esses dados então formam um objeto ou o que chamamos de conjunto, na categoria do calendário econômico.
Infelizmente, o uso de funtores para análise e pré-processamento de dados históricos do calendário econômico só pode ser feito no testador de estratégias, não diretamente do(s) servidor(es) MetaQuotes. Este é, sem dúvida, um gargalo que superamos exportando os dados para um arquivo CSV usando um script e, em seguida, lendo este arquivo CSV no testador de estratégias, como no artigo anterior. A diferença aqui é que estamos fazendo isso para uma instância da classe de sinal do EA, e não para a classe de trailing. Como estamos trabalhando com dois funtores, o script usado criou dois arquivos, especificamente um com o prefixo true, o que significa que o funtor é aplicado aos objetos, e outro com o prefixo false, indicando que ele se refere aos morfismos. Arquivos anexados ao artigo.
A representação gráfica dos valores transformados do índice S&P 500 é apresentada no diagrama acima.
Arquitetura de rede neural baseada em funtores
Funtores como perceptrons multicamadas (redes neurais) neste artigo representam um avanço em comparação com as relações lineares ou quadráticas anteriores que usamos para mapear categorias e até objetos dentro de uma categoria (já que as relações de morfismo entre dois elementos podem ser definidas da mesma forma). Como destacado anteriormente, o uso de funtores implica o mapeamento não apenas de objetos de duas categorias, mas também de seus respectivos morfismos. Assim, um pode verificar o outro, ou seja, se você conhece os objetos na categoria do codomínio, os morfismos estão implícitos e vice-versa. Isso significa que estaremos lidando com dois perceptrons entre nossas categorias.
Este artigo não explicará os fundamentos dos perceptrons, pois já existem muitos artigos sobre este assunto, não apenas neste site, mas também na Internet em geral, portanto, sugere-se que o leitor faça sua própria pesquisa preliminar, se isso ajudar a esclarecer o que é apresentado aqui. A arquitetura de rede apresentada aqui foi implementada em grande parte graças ao Alglib, disponível no IDE do MetaTrader na pasta Include\Math. Aqui está como o perceptron é inicializado usando a biblioteca:
//+------------------------------------------------------------------+ //| Function to train Perceptron. | //+------------------------------------------------------------------+ bool CSignalCT::Train(CMultilayerPerceptron &MLP) { CMLPBase _base; CMLPTrain _train; if(!ReadPerceptron(m_training_profit)) { _base.MLPCreate1(__INPUTS,m_hidden,__OUTPUTS,MLP); m_training_profit=0.0; } else { printf(__FUNCSIG__+" read perceptron, with profit: "+DoubleToString(m_training_profit)); } ... return(false); }
Os perceptrons usados desta biblioteca são muito simples e consistem em três camadas: uma camada de entrada, uma camada oculta e uma camada de saída. Nossa categoria de dados econômicos contém simultaneamente quatro pontos de dados (com base em nossa hipótese), portanto, a quantidade de entradas na camada oculta será de quatro. O número de pontos na camada oculta será um dos poucos parâmetros otimizáveis, mas nosso valor padrão é sete. Então, finalmente, na camada de saída, aparecerá um resultado, que é a mudança prevista no índice S&P 500. Conhecer os pesos, viéses e funções de ativação é chave para entender como funcionam os perceptrons de feedforward. Sugere-se que o leitor faça uma pesquisa sobre esses tópicos conforme necessário.
Treinamento da rede neural baseada em funtor
O processo de treinamento nos dados históricos do calendário econômico será realizado usando o algoritmo Levenberg-Marquardt. Assim como no caso da propagação direta e retropropagação de erros, o código é processado pelas funções do AlgLib. Implementaríamos o treinamento usando a biblioteca da seguinte maneira:
int _info=0; CMatrixDouble _xy; CMLPReport _report; TrainingLoad(m_training_stop,_xy,m_training_points,m_testing_points); // if(m_training_points>0) { _train.MLPTrainLM(MLP,_xy,m_training_points,m_decay,m_restarts,_info,_report); if(_info>0){ return(true); } }
A parte crucial aqui é o preenchimento da matriz XY com dados de entrada do arquivo csv no diretório comum. A matriz extrai os quatro pontos de dados definidos em cada linha de dados, como dados históricos, cada vez que uma nova coluna é gerada (ou por um temporizador), e usa isso para treinar a rede para gerar seus pesos e viéses. O preenchimento da matriz de entrada XY seria tratado pela função TrainingLoad, como mostrado abaixo:
//+------------------------------------------------------------------+ //| Function Get Training Points and Initialize Training Matrix. | //+------------------------------------------------------------------+ void CSignalCT::TrainingLoad(datetime Date,CMatrixDouble &XY,int &TrainingPoints,int &TestingPoints) { TrainingPoints=0; TestingPoints=0; ResetLastError(); string _file="_s_"+m_currency+"_"+m_symbol.Name()+"_"+EnumToString(m_period)+"_"+string(m_objects)+".csv"; int _handle=FileOpen(_file,FILE_SHARE_READ|FILE_ANSI|FILE_COMMON,"\n",CP_ACP); if(_handle!=INVALID_HANDLE) { string _line=""; int _line_length=0; while(!FileIsLineEnding(_handle)) { //--- find out how many characters are used for writing the line _line_length=FileReadInteger(_handle,INT_VALUE); //--- read the line _line=FileReadString(_handle,_line_length); string _values[]; ushort _separator=StringGetCharacter(",",0); if(StringSplit(_line,_separator,_values)==6) { datetime _date=StringToTime(_values[0]); _d_economic.Let(); _d_economic.Cardinality(4); //printf(__FUNCSIG__+" initializing for: "+TimeToString(Date)+" at: "+TimeToString(_date)); if(_date<Date) { TrainingPoints++; // XY.Resize(TrainingPoints,__INPUTS+__OUTPUTS); for(int i=0;i<__INPUTS;i++) { XY[TrainingPoints-1].Set(i,StringToDouble(_values[i+1])); } // XY[TrainingPoints-1].Set(__INPUTS,StringToDouble(_values[__INPUTS+1])); } else { TestingPoints++; } } } FileClose(_handle); } else { printf(__FUNCSIG__+" failed to load file. Err: "+IntegerToString(GetLastError())); } }
Vale destacar que, após o treinamento, a razão pela qual as redes neurais funcionam e são populares reside em sua capacidade de desenvolver e reutilizar pesos e viéses. Neste artigo, o armazenamento desses pesos e viéses é realizado por meio de uma função especial, cujo código o autor ainda não está pronto para compartilhar. Portanto, uma referência a ela na forma de uma biblioteca ex5 estará presente na listagem, mas seu código não.
Normalmente, no treinamento de redes, utiliza-se o pré-processamento de dados, que visa a normalização dos dados para valores comparáveis e a divisão deles em conjuntos de treinamento e teste. No entanto, para nossos propósitos, treinamos o conjunto carregado de dados históricos na inicialização do expert e, em seguida, testamos usando uma parte separada dos dados CSV, cuja divisão dos dados de treinamento é determinada pela data de entrada. Como nosso único parâmetro otimizável será o número de pesos na camada oculta (de 5 a 12), registramos os pesos treinados da rede em um arquivo no diretório comum e no final de cada passagem de otimização, apenas se os critérios de otimização dessa passagem excederem os critérios de otimização do arquivo já gravado em uma passagem anterior. Se a gravação for feita, então na inicialização da rede na próxima passagem, os pesos iniciais serão carregados desse arquivo.
Retropropagação do erro e descida de gradiente são processadas pela função MLPTrainLM, que está na classe CMLPTrain da biblioteca AlgLib.
Geração de sinais de negociação usando funtores e redes neurais
A categoria S&P 500, representando uma ordem linear de mudanças no índice, forma o codomínio para nossos "dois" funtores da categoria de dados do calendário econômico. Lembro que são "dois" porque objetos e morfismos estão interligados. Assim, nosso sinal no período de teste, determinado pela data de entrada lida do arquivo CSV, será gerado pelos pesos obtidos ao final de cada treinamento. O treinamento do código anexado a este artigo ocorre a cada inicialização do Expert Advisor. Um arquivo de sinais, assim como os arquivos anexados aos artigos anteriores, está incluído e pode ser usado após a compilação no assistente MQL5 através do MetaEditor IDE. Poderíamos adicionalmente treinar em um temporizador, já que cada nova coluna fornece uma nova linha de dados para o nosso arquivo CSV, no entanto, esta abordagem não é considerada no artigo, e é sugerido que o leitor explore isso por conta própria, pois pode rapidamente descobrir mais sinais emergentes.
Nossa função GetOutput, como nos artigos anteriores, será responsável por obter o valor com base no qual processamos nossa decisão de negociação. Conforme mostrado na listagem abaixo, além de atualizar as categorias com os valores atuais, as entradas de rede são preparadas com base nas leituras atuais do calendário do arquivo csv no diretório comum. Elas são preenchidas no array "_x_inputs", do qual o array é transmitido para a rede usando a função MLPProcess, que faz parte da classe CMLPBase. Isso é mostrado abaixo:
//+------------------------------------------------------------------+ //| Get Output value, forecast for next change in price bar range. | //+------------------------------------------------------------------+ double CSignalCT::GetOutput(datetime Date) { if(Date>=D'2023.07.01') { printf(__FUNCSIG__+" log profit: "+DoubleToString(m_training_profit)+", account profit: "+DoubleToString(m_account.Profit())+", equity: "+DoubleToString(m_account.Equity())+", deposit: "+DoubleToString(m_training_deposit)); if(m_training_profit<m_account.Equity()-m_training_deposit) { printf(__FUNCSIG__+" perceptron write... "); m_training_profit=m_account.Equity()-m_training_deposit; WritePerceptron(m_training_profit,_MLP); } } ... _value="";_e.Let();_e.Cardinality(1); _d_economic.Get(3,_e);_e.Get(0,_value); _x_inputs[3]=StringToDouble(_value);//printf(__FUNCSIG__+" val 4: "+_value); //forward feed?... CMLPBase _base; _base.MLPProcess(_MLP,_x_inputs,_y_inputs); _output=_y_inputs[0]; //printf(__FUNCSIG__+" output is: "+DoubleToString(_output)); return(_output); }
Também existe a possibilidade de incorporar gestão de riscos e definição do tamanho da posição no sistema de negociação que utiliza esses métodos, que podem incluir a determinação do tamanho dependendo da magnitude do sinal. Isso, sem dúvida, exigirá a normalização do valor do sinal e, como sempre, deve-se ter cuidado especial ao alterar o tamanho da posição. Essas mudanças, no entanto, podem ser alcançadas criando uma instância especial da classe ExpertMoney da mesma forma que usamos nossa própria instância da classe ExpertSignal ao determinar pontos de entrada e saída.
Backtesting e avaliação de desempenho
Nosso teste histórico será a otimização do número ideal de pesos na camada oculta. Como eles variam de 5 a 12, existem apenas oito variantes, e ainda assim queremos executar várias corridas para cada número de pesos antes de escolher o número ideal. Portanto, para ter várias corridas, adicionamos um parâmetro que não afeta o desempenho do Expert Advisor, mas precisa ser otimizado, e assim acrescenta corridas adicionais ao processo de otimização, permitindo que cada variante do número de pesos execute várias corridas de teste. Como mencionado anteriormente, se no final de cada corrida o resultado do teste for melhor do que o do último arquivo gravado na pasta comum, então esses pesos substituirão os gravados anteriormente. O critério de otimização será o lucro máximo. Realizamos corridas em um intervalo de tempo mensal, porque os dados econômicos do calendário são atualizados em média com essa mesma frequência. Os testes do índice S&P 500 no intervalo mensal foram realizados de 1 de julho a 1 de agosto de 2022, e nossa melhor corrida para o funtor objeto-objeto deu os seguintes resultados:

Da mesma forma, nosso funtor morfismo-morfismo deu os seguintes resultados:

A análise dos indicadores-chave dos relatórios sobre rebaixamento e relação de lucro mostra uma maior eficácia do funtor morfismo-morfismo. Talvez seja nele que devemos focar para trabalhos futuros? A resposta a essa pergunta dependerá não apenas de testes em outros ativos, mas também do uso de diferentes abordagens de treinamento ao executar testes, como aqueles que consideram se o treinamento deve ser feito em cada nova barra ou trimestralmente.
Considerações finais
Os principais resultados do teste com perceptrons mostram que um sistema de negociação pode ser desenvolvido usando um sinal semelhante ao apresentado no arquivo de sinais. Na fase de desenvolvimento, deve-se ter disponível uma categoria de domínio apropriada com dados em um formato facilmente acessível para o testador de estratégias, e como os testes confiáveis geralmente abrangem vários anos, esses dados devem ser extensos.
A importância do uso de perceptrons multicamadas como funtores não é apenas um passo à frente. Essa aplicação tem um grande potencial, considerando os muitos tipos e formatos que as redes neurais podem usar. O artigo fornece referências para estudos adicionais sobre perceptrons. O tópico é bem conhecido e documentado. Muitos conceitos já discutidos, incluindo limites, colimites e propriedades universais, podem ser formulados usando redes neurais.
Referências
O artigo contém referências a artigos da Wikipédia.
Notas sobre aplicações
Coloque o arquivo SignalCT_16_.mqh na pasta MQL5\include\Expert\Signal\, e o arquivo ct_16.mqh na MQL5\include\.
Você também pode achar úteis as recomendações fornecidas aqui sobre como compilar o Expert Advisor usando o Assistente. Como mencionado no artigo, eu não usei trailing stop e margem fixa para gerenciamento de capital. Ambos são parte da biblioteca MQL5. Como sempre, o objetivo do artigo não é apresentar o Santo Graal, mas sim oferecer uma ideia que você pode adaptar à sua própria estratégia.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/13116
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso