Integración de modelos ML con el simulador de estrategias (Parte 3): Gestión de archivos CSV(II)

Introducción
Nos centraremos, en este artículo, en la tercera parte de la integración del simulador de estrategias con Python. Mostraremos la creación de la clase CFileCSV para la gestión eficiente de archivos CSV, incluyendo ejemplos y código para que los lectores entiendan cómo se puede implementar esta clase en la práctica.
Puede que te estés preguntando: ¿pero qué es un CSV?
CSV (Comma Separated Values) es un formato de archivo sencillo y muy utilizado para almacenar e intercambiar datos. Es como una tabla en la que cada fila representa un conjunto de datos y cada columna representa un campo dentro de esos datos. Los valores están divididos por un delimitador, lo que facilita su lectura y escritura en diversas herramientas y lenguajes de programación.
El formato CSV apareció a principios de los años 70, utilizándose primero en sistemas mainframe. No existe un creador específico para CSV, ya que es una convención ampliamente adoptada.
Se utiliza mucho para importar y exportar datos en diversas aplicaciones, como hojas de cálculo electrónicas, bases de datos y programas de análisis de datos, entre otros. Su popularidad se debe a su sencillez de uso y comprensión, así como a su compatibilidad con numerosos sistemas y herramientas. Resulta especialmente útil cuando se desea compartir datos entre distintas aplicaciones, como por ejemplo para transferir información de un sistema a otro.
Las ventajas de utilizar CSV son su facilidad de uso y su compatibilidad con muchas herramientas. Sin embargo, tiene algunas restricciones, como la falta de soporte para tipos de datos complejos y la reducida capacidad para manejar volúmenes de datos muy grandes. Además, la falta de un estándar universal para el formato CSV puede causar problemas de compatibilidad entre distintas aplicaciones. También es posible que los datos se pierdan o alteren accidentalmente debido a la falta de validación. En resumen, CSV es una opción versátil y fácil de usar para almacenar y compartir datos, pero es importante tener en cuenta sus limitaciones y tomar medidas para garantizar la exactitud de los datos.
Motivación
La necesidad de integrar el entorno del simulador de estrategias de Meta Trade 5 con Python llevó a la creación de la clase CFileCSV. Mientras desarrollaba estrategias de tráding utilizando modelos de aprendizaje automático, me encontré con la dificultad de utilizar estos modelos creados en Python. O bien tendría que construir una biblioteca de aprendizaje automático en MQL5, lo que escapaba a mi objetivo principal, o bien tendría que crear un Expert Advisor enteramente en Python.
Aunque el lenguaje MQL5 dispone de recursos para construir librerías de machine learning, no era mi deseo invertir tiempo y esfuerzo en desarrollar una, porque mi objetivo principal era el análisis de datos y la construcción de modelos de forma ágil y eficiente.
Buscaba una solución intermedia. Quería disfrutar de las ventajas de los modelos de aprendizaje automático construidos en Python, pero también quería poder aplicarlos directamente a mis operaciones con MQL5. Esto me llevó a buscar una forma de superar esta restricción y encontrar una solución para integrar estos dos entornos.
La propuesta era crear un sistema de intercambio de mensajes, donde Meta Trader y Python pudieran interactuar entre sí. Esto permitiría el control de la inicialización, la transmisión de datos de Meta Trader 5 a Python y el envío de previsiones de Python a Meta Trader 5. La clase CFileCSV fue concebida para facilitar esta comunicación, permitiendo almacenar y cargar los datos de forma eficiente.
Introducción a la clase CFileCSV
La clase CFileCSV es una clase de operaciones con ficheros CSV (Comma Separated Values), derivada de CFile, que proporciona funcionalidades específicas para trabajar con ficheros CSV. El objetivo de esta clase es simplificar la lectura y escritura de ficheros CSV, facilitando la manipulación de diversos tipos de datos.
Una de las grandes ventajas de utilizar archivos CSV es la simplicidad para compartir e importar/exportar datos. Se pueden abrir y editar fácilmente en programas como Excel o Google Sheets, y también pueden ser leídos por varios lenguajes de programación. Además, al no tener un formato específico, pueden leerse y escribirse según diversas necesidades.
La clase CFileCSV tiene cuatro métodos públicos principales: Open, WriteHeader, WriteLine y Read. Además, tiene dos métodos privados auxiliares, utilizados paraconvertir arrays o matrices en strings y para registrar estos valores en el fichero.
class CFileCSV : public CFile { private: template<typename T> string ToString(const int, const T &[][]); template<typename T> string ToString(const T &[]); short m_delimiter; public: CFileCSV(void); ~CFileCSV(void); //--- methods for working with files int Open(const string,const int, const short); template<typename T> uint WriteHeader(const T &values[]); template<typename T> uint WriteLine(const T &values[][]); string Read(void); };
Cuando utilices esta clase, recuerda que fue diseñada para trabajar con archivos CSV específicos. Si los datos del fichero no tienen el formato adecuado, los resultados pueden ser inesperados. Además, es crucial asegurarse de que el archivo está abierto antes de intentar escribir en él, y que tiene permiso para ser escrito.
Un ejemplo de cómo se podría utilizar la clase CFileCSV sería en la creación de un archivo CSV a partir de una matriz de datos. Primero, crearíamos una instancia de la clase y abriríamos el fichero con el método Open, determinando el nombre del fichero y las flags de apertura. A continuación utilizaríamos el método WriteHeader para grabar una cabecera en el fichero y el método WriteLine para escribir las filas de datos en el array. A continuación, ilustramos estos pasos en una función:
#include "FileCSV.mqh" void CreateCSVFile(string fileName, string &headers[], string &data[][]) { // Cria um objeto da classe CFileCSV CFileCSV csvFile; // Verifica se o arquivo pode ser aberto para escrita em formato ANSI if(csvFile.Open(fileName, FILE_WRITE|FILE_ANSI)) { int rows = ArrayRange(data, 0); int cols = ArrayRange(data, 1); int headerSize = ArraySize(headers); //Verifica se o número de colunas no array de dados é igual ao número de elementos no array de cabeçalhos e se o número de linhas no array de dados é maior que zero if(cols != headerSize || rows == 0) { Print("Error: Invalid number of columns or rows. Data array must have the same number of columns as the headers array and at least one row."); return; } // Escreve o cabeçalho no arquivo csvFile.WriteHeader(headers); // Escreve as linhas de dados no arquivo csvFile.WriteLine(data); // Fecha o arquivo csvFile.Close(); } else { // Exibe uma mensagem de erro caso o arquivo não possa ser aberto Print("Error opening file!"); } }
El propósito de este método es crear un fichero CSV a partir de un array de cabeceras y un array de datos. Comienza creando un objeto de la clase CFileCSV y luego comprueba si el fichero se puede abrir para escribir en formato ANSI. Si el fichero puede abrirse, comprueba que el número de columnas de la matriz de datos es igual al número de elementos de la matriz de cabecera y que el número de filas de la matriz de datos es mayor que cero. Si se cumplen estas condiciones, el método escribe la cabecera en el fichero mediante el método WriteHeader() y a continuación escribe las filas de datos con el método WriteLine(). Al final, el método cierra el fichero. Si no se puede abrir el fichero, se muestra un mensaje de error.
Este método se demostrará en un ejemplo en breve, pero vale la pena señalar que su implementación puede ampliarse para satisfacer otras necesidades. Por ejemplo, es posible añadir más validaciones, como comprobar si el fichero ya existe antes de intentar abrirlo, o incorporar opciones para elegir el delimitador a utilizar.
La clase CFileCSV ofrece una forma sencilla y práctica de manipular ficheros CSV, facilitando la lectura y escritura de datos en estos ficheros. Sin embargo, es fundamental tener cuidado al utilizarla, asegurándose de que los ficheros tienen el formato esperado y comprobando los retornos de los métodos para asegurarse de que se han ejecutado correctamente.
Implementación
Como se mencionó anteriormente, la clase CFileCSV cuenta con cuatro métodos públicos principales: Open, WriteHeader, WriteLine y Read. Además, tiene dos métodos auxiliares privados, ambos sobrecargados con el nombre ToString.
-
El método Open(const string file_name,const int open_flags, const short delimiter=';') se utiliza para abrir un archivo CSV. Este método recibe como parámetros el nombre del fichero, las flags de apertura (como FILE_WRITE o FILE_READ) y el delimitador a utilizar en el fichero (con ';' por defecto). Invoca el método Open de la clase base CFile y almacena el delimitador especificado en una variable privada. Devuelve un valor entero que indica el éxito o el fracaso de la operación.
int CFileCSV::Open(const string file_name,const int open_flags, const short delimiter=';') { m_delimiter=delimiter; return(CFile::Open(file_name,open_flags|FILE_CSV|delimiter)); }
- El método WriteHeader(const T &values[]) se emplea para registrar una cabecera en el fichero CSV abierto. Recibe como parámetro un array de valores que representan las cabeceras de las columnas del fichero. Utiliza el método ToString para convertir el array en una string y registra esa string en el fichero utilizando el método FileWrite de la clase base CFile. Devuelve un entero que indica el número de bytes registrados en el fichero.
template<typename T> uint CFileCSV::WriteHeader(const T &values[]) { string header=ToString(values); //--- check handle if(m_handle!=INVALID_HANDLE) return(::FileWrite(m_handle,header)); //--- failure return(0); }
-
El método WriteLine(const T &values[][]) se utiliza para registrar filas de datos en un archivo CSV abierto. Este método toma como parámetro un array de valores que representan las filas de datos del fichero. Recorre cada fila del array, utilizando el método ToString para convertir cada fila en una string y concatenar esas strings en una única string. Graba esta string en el fichero utilizando el método FileWrite de la clase base CFile. Devuelve un entero que indica el número de bytes registrados en el fichero.
template<typename T> uint CFileCSV::WriteLine(const T &values[][]) { int len=ArrayRange(values, 0); if(len<1) return 0; string lines=""; for(int i=0; i<len; i++) if(i<len-1) lines += ToString(i, values) + "\n"; else lines += ToString(i, values); if(m_handle!=INVALID_HANDLE) return(::FileWrite(m_handle, lines)); return 0; }
-
El método Read(void) se utiliza para leer el contenido de un archivo CSV abierto. Utiliza el método FileReadString de la clase base CFile para leer el contenido del fichero línea a línea y almacenarlo en una única string. Devuelve la string que contiene el contenido del archivo.
string CFileCSV::Read(void) { string res=""; if(m_handle!=INVALID_HANDLE) res = FileReadString(m_handle); return res;
Los métodos ToString son métodos privados de ayuda de la clase CFileCSV y se empleanpara convertir matrices o arrays en strings y registrar estos valores en el fichero.
-
El método ToString(const int row, const T &values[][]) se utiliza para convertir una matriz en una string. Toma como parámetro la fila de la matriz que se desea convertir y la propia matriz. Recorre cada elemento de la fila del array, añadiéndolo a la string resultante. El delimitador se añade al final de cada elemento, excepto en el último elemento de la fila.
template<typename T> string CFileCSV::ToString(const int row, const T &values[][]) { string res=""; int cols=ArrayRange(values, 1); for(int x=0; x<cols; x++) if(x<cols-1) res+=values[row][x] + ShortToString(m_delimiter); else res+=values[row][x]; return res; }
-
El método ToString(const T &values[]) se emplea para convertir un array en una string. Recorre cada elemento del array y lo añade a la string resultante. El delimitador se añade al final de cada elemento, excepto en el último elemento del array.
template<typename T> string CFileCSV::ToString(const T &values[]) { string res=""; int len=ArraySize(values); if(len<1) return res; for(int i=0; i<len; i++) if(i<len-1) res+=values[i] + ShortToString(m_delimiter); else res+=values[i]; return res; }
Estos métodos son empleadospor los métodos WriteHeader y WriteLine para convertir los valores pasadoscomo parámetros en strings y registrar esos strings en el fichero abierto. Se utilizanpara garantizar que los valores se registran en el fichero en el formato adecuado, separados por el delimitador especificado. Son esenciales para garantizar que los datos se registran de forma correcta y ordenada en el fichero CSV.
Además, estos métodos proporcionan a la clase CFileCSV una gran flexibilidad, permitiéndole manejar diferentes tipos de datos, ya que están implementados como plantillas. Esto significa que estos métodos pueden ser aplicadosa cualquier tipo de datos que puedan ser convertidos a una string, incluyendo enteros, punto flotante, strings y otros. Esto hace que la clase CFileCSV sea increíblemente versátil y fácil de usar.
Fundamentalmente, estos métodos están diseñados para garantizar que los valores se registran en el archivo en el formato correcto. Incluyen el delimitador al final de cada elemento excepto el último de la fila o matriz. Esto garantiza que los valores se separen correctamente en el archivo CSV, lo que es crucial para la posterior lectura e interpretación de los datos almacenados en el archivo.
Ejemplo de uso del método ToString(const int row, const T &values[][]):
int data[2][3] = {{1, 2, 3}, {4, 5, 6}}; string str = csvFile.ToString(1, data); //str -> "4;5;6"
En este ejemplo, la segunda fila de la matriz de datos se pasa al método ToString. El método recorre cada elemento de la fila, añadiéndolo a la string resultante e insertando el delimitador al final de cada elemento, excepto el último de la fila. La string resultante sería '4;5;6'.
Ejemplo de uso del método ToString(const T &values[]):
string headers[] = {"Name", "Age", "Gender"}; string str = csvFile.ToString(headers); //str -> "Name;Age;Gender"
En este ejemplo, el array 'headers' se pasa al método ToString. El método recorre cada elemento del array, añadiéndolo a la string resultante e insertando el delimitador al final de cada elemento excepto el último del array. La string resultante sería 'Name;Age;Gender'.
Estos son sólo ejemplos de cómo se pueden utilizar los métodos ToString y ToString. Se pueden aplicar a cualquier tipo de dato que se pueda convertir a string, pero es importante tener en cuenta que sólo son accesibles dentro de la clase CFileCSV, ya que están declarados como privados.
Complejidad algorítmica
¿Cómo podemos medir la complejidad algorítmica y utilizar esta información para optimizar el rendimiento de algoritmos y sistemas?
La notación Big O es una herramienta esencial en el análisis de algoritmos, reconocida desde los primeros días de la informática. Definido formalmente en los años 60, el concepto de Big O sigue empleándose ampliamente en la actualidad. Permite a los programadores evaluar la complejidad de un algoritmo de forma aproximada, basándose en el tamaño de la entrada y el número de operaciones necesarias para ejecutarlo. Así, es posible comparar distintos algoritmos e identificar los que ofrecen el mejor rendimiento para tareas específicas.
La necesidad de la notación Big O surge del crecimiento exponencial de los datos y de la complejidad de los problemas que tenemos que resolver. Con la evolución tecnológica, la cantidad de datos generados a diario ha aumentado significativamente, así como la necesidad de algoritmos más eficientes para tratar estos datos. Big O permite a los desarrolladores e investigadores comparar y evaluar diferentes algoritmos para encontrar la opción más adecuada en función de las necesidades de cada problema.
El concepto de Big O se basa en la idea de que, para un algoritmo, el tiempo de ejecución crece según una función matemática específica, normalmente una función polinómica. La notación Big O se utiliza para expresar esta función y puede representarse como O(f(n)), donde f(n) es la función que representa la complejidad del algoritmo.
Veamos algunos ejemplos de notación Big O:
- O(1), que representa un algoritmo de tiempo constante, es decir, que no varía con el tamaño de los datos.
- O(n), que simboliza un algoritmo de tiempo lineal, en el que el tiempo de ejecución aumenta proporcionalmente al tamaño de los datos.
- O(n^2), que corresponde a un algoritmo de tiempo cuadrático, donde el tiempo de ejecución crece al cuadrado con el tamaño de los datos.
- O(log n), que denota un algoritmo de tiempo logarítmico, donde el tiempo de ejecución crece en función del logaritmo del tamaño de los datos.
Big O es una herramienta fundamental para comprender y comparar la eficiencia de distintos algoritmos. Ayuda a tomar decisiones informadas sobre qué algoritmo elegir para resolver un problema específico y optimizar el rendimiento de los sistemas.
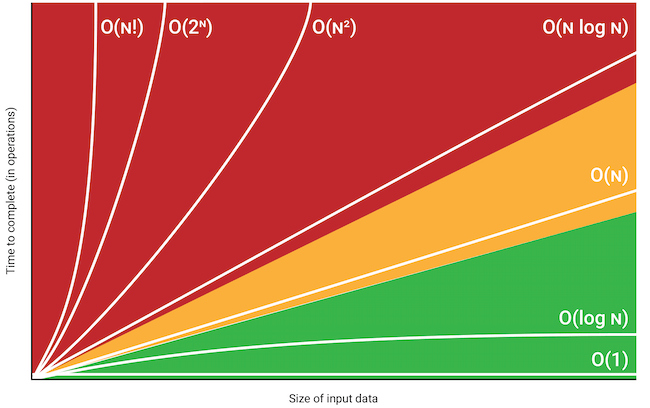
La complejidad temporal de cada método de la clase CFileCSV varía en función del tamaño de los datos proporcionadoscomo parámetro.
- El método Open tiene complejidad O(1), ya que realiza una única operación de apertura del fichero, independientemente del tamaño de los datos.
- El método Read tiene una complejidad O(n), donde n es el tamaño del fichero. Lee todo el contenido del fichero y lo almacena en una string.
- El método WriteHeader también tiene una complejidad O(n), donde n es el tamaño del array proporcionado como parámetro. Convierte el array en una string y la escribe en el fichero.
- El método WriteLine tiene una complejidad O(mn), donde m es el número de filas del array y n es el número de elementos de cada fila. Recorre cada fila de la matriz, la transforma en una string y la escribe en el archivo.
Es importante señalar que estas complejidades son estimaciones, ya que pueden verse influidas por otros factores, como el tamaño del búfer de escritura del archivo, el sistema de archivos y otros. Además, estos impactos de la notación Big O son en el peor de los casos. Si los datos proporcionados a los métodos son demasiado grandes, la complejidad puede ser aún mayor.
En resumen, la clase CFileCSV tiene una complejidad temporal aceptable y es eficaz para trabajar con ficheros de tamaño moderado. Sin embargo, si es necesario manejar ficheros muy grandes, puede ser necesario considerar otros enfoques u optimizar la clase para manejar esos casos de uso específicos.
Ejemplo de uso
//+------------------------------------------------------------------+ //| exemplo_2.mq5 | //| Copyright 2022, Lethan Corp. | //| https://www.mql5.com/pt/users/14134597 | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, Lethan Corp." #property link "https://www.mql5.com/pt/users/14134597" #property version "1.00" #include "FileCSV.mqh" CFileCSV csvFile; string fileName = "dados.csv"; string headers[] = {"Timestamp", "Close", "Last"}; string data[1][3]; //Função OnInit int OnStart(void) { //Preenchendo o array 'data' com os valores de timestamp, Bid, Ask, Indicador1 e Indicador2 data[0][0] = TimeToString(TimeCurrent()); data[0][1] = DoubleToString(iClose(Symbol(), PERIOD_CURRENT, 0), 2); data[0][2] = DoubleToString(SymbolInfoDouble(Symbol(), SYMBOL_LAST), 2); //Abrindo o arquivo CSV if(csvFile.Open(fileName, FILE_WRITE|FILE_ANSI)) { //Escrevendo o cabeçalho csvFile.WriteHeader(headers); //Escrevendo as linhas com os dados csvFile.WriteLine(data); //Fechando o arquivo csvFile.Close(); } else { Print("Erro ao abrir o arquivo!"); } return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+
Este código presenta la implementación de la clase CFileCSV en MQL5. Abarca las siguientes funcionalidades:
- Proporciona manejo de errores para situaciones en las que no se puede abrir el archivo.
- Permite abrir un archivo CSV con el nombre especificado y los permisos de escritura adecuados.
- Permite escribir una cabecera en el archivo, definida como una matriz de strings.
- Permite escribir datos, también definidos como una matriz de strings, en el fichero.
- Garantiza que el archivo se cierre una vez finalizada la escritura.
Conclusión
En resumen, la clase CFileCSV proporciona un medio práctico y eficaz de gestionar archivos CSV, mediante métodos para abrir, escribir cabeceras y filas, y también para leer un archivo CSV. Los métodos Open, WriteHeader, WriteLine y Read son cruciales para garantizar un manejo adecuado de los archivos CSV, asegurando que los datos se registren de forma organizada y puedan leerse correctamente. Gracias por su atención en la lectura y les informo que en la próxima sesión, exploraremos cómo utilizar modelos de aprendizaje automático a través del intercambio de archivos empleando la clase CFileCSV que fue introducida en esta sesión.
Traducción del portugués realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/pt/articles/12069
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso