
Neural networks made easy (Part 66): Exploration problems in offline learning

Introduction
As we move along the series of articles devoted to reinforcement learning methods, we are facing the question related to the balance between environmental exploration and exploitation of learned policies. We have previously considered various methods of stimulating the Agent to explore. But quite often, algorithms that demonstrate excellent results in online learning are not so effective offline. The problem is that for offline mode, information about the environment is limited by the size of the training dataset. Most often, the data selected for model training is narrowly targeted as it is collected within a small subspace of the task. This provides an even more limited idea of the environment. However, in order to find the optimal solution, the Agent needs the most complete understanding of the environment and its patterns. We have earlier noted that learning results often depend on the training dataset.
Furthermore, quite often during the training process, the Agent makes decisions that go beyond the subspace of the training dataset. In such cases it is difficult to predict subsequent results. That is why, after preliminary model training, we additionally collect trajectories into the training dataset, which can adjust the learning process.
Online environmental model training can sometimes mitigate the above problems. However, unfortunately, due to various reasons, it is not always possible to train an environmental model. Quite often, training a model can be even more expensive than training an Agent policy. Sometimes, it is simply impossible.
The second obvious direction is to expand the training dataset. But here we are primarily limited by the physical size of the available resources and the costs of studying the environment.
In this article, we will get acquainted with the Exploratory Data for Offline RL (ExORL) framework, which was presented in the paper "Don't Change the Algorithm, Change the Data: Exploratory Data for Offline Reinforcement Learning". The results presented in that article demonstrate that the correct approach to data collection has a significant impact on the final learning outcomes. This impact is comparable to that of the choice of learning algorithm and model architecture.
1. Exploratory data for Offline RL (ExORL) method
The authors of the Exploratory data for Offline RL (ExORL) method do not offer new learning algorithms or architectural solutions for models. Instead, the focus is on the process of collecting data to train models. They carry out experiments with five different learning methods to evaluate the impact of the training dataset content on the learning outcome.
The ExORL method can be divided into 3 main stages. The first stage is the collection of unlabeled exploratory data. This stage can use various unsupervised learning algorithms. The authors of the method do not limit the range of applicable algorithms. Moreover, in the process of interaction with the environment, at each episode, we use a policy π, depending on the history of previous interactions. Each episode is saved in the dataset as the sequence of a state St, action At and subsequent state St+1. The collection of training data continues until the training dataset is completely filled. The size of this training dataset is limited by the technical specifications or available resources.
In practice, the authors of that paper evaluate nine different unsupervised data collection algorithms:
- A simple baseline that always outputs a uniformly random policy.
- Methods that maximize error of a predictive model: ICM, Disagreement, and RND;
- Algorithms that maximize some estimate of coverage of the state space: APT and Proto-RL;
- Competence-based algorithms that learn a diverse set of skills: DIAYN, SMM, and APS.
After collecting a dataset of states and actions, the next stage is to relable the data using a given reward function. This stage implies the evaluation of the reward for each tuple in the dataset.
In experiments, the authors of the method use standard or manual reward functions. The proposed framework also allows the training of the reward function. That is, it allows the implementation of the inverse RL.
The last stage in ExORL is training the model. The policy is trained using offline reinforcement learning algorithms on a labeled dataset. Offline training is implemented entirely using offline data from the training dataset, by randomly selecting tuples. The final policy is then evaluated in a real environment.
Below is the authors' visualization of the method.
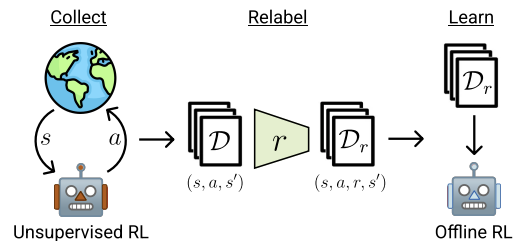
In the paper, the authors demonstrate the results of five different offline reinforcement learning algorithms. The basic option is simple behavior cloning. They also present the results of three offline reinforcement learning algorithms, each of which uses different mechanisms to prevent extrapolation beyond the actions in the data. The classic TD3 is also presented as a baseline test to evaluate the impact of offline mode on methods originally designed for online learning that do not have a mechanism explicitly designed to prevent extrapolation beyond the training dataset.
Based on the results of the experiments, the authors of the method conclude that the use of diverse data can greatly simplify offline reinforcement learning algorithms by eliminating the need to handle the extrapolation problem. The results demonstrate that exploratory data improves the performance of offline reinforcement learning on a variety of problems. In addition, previously developed offline RL algorithms perform well on task-specific data but are inferior to TD3 on unlabeled ExORL data. Ideally, offline reinforcement learning algorithms should automatically adapt to the used dataset to recover the best of both worlds.
2. Implementation using MQL5
The authors of the Exploratory Data for Offline RL (ExORL) method give the general direction for constructing the framework. In that paper, the authors experiment with various model training methods. In the practical part of my article, I decided to build an ExORL implementation as close as possible to the model from the previous articles. However, please pay attention to one constructive point. The DWSL algorithm implies weighing of actions from the S state according to their Advantage. In our implementation, we targeted the closest states of all trajectories by their embedding. The actions were weighed in the selected states according to their impact on the outcome.
However, the ExORL method assumes the maximum diversity of Agent behavior. In this regard, we need to determine the distance between actions in individual states. The use of the distance to the closest State-Action pair as a reward will encourage the Agent to explore the environment. Therefore, we will determine the state embedding based on the action.
As an alternative, it is possible to determine the distance between subsequent states. This seems quite logical when working with a stochastic environment. In this environment, performing one action with some probability can lead to various subsequent states. But the use of such algorithms drives us further from the DWSL method, which we use as the basis for our implementation. Minimal adjustments to the base algorithm will allow us to better assess the impact of the ExORL framework on the model training outcome.
Therefore, I decided to use the first option and increase the size of the source data layer in the Encoder model by the Actor action vector. Otherwise, the architecture of the models remained unchanged. You can find it in the attachment. File "...\ExORL\Trajectory.mqh", the CreateDescriptions method.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *critic, CArrayObj *convolution) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; } if(!convolution) { convolution = new CArrayObj(); if(!convolution) return false; } //--- Actor ........ ........ //--- Critic ........ ........ //--- Convolution convolution.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = (HistoryBars * BarDescr) + AccountDescr + NActions; descr.activation = None; descr.optimization = ADAM; if(!convolution.Add(descr)) { delete descr; return false; } //--- layer 1 ........ ........ //--- return true; }
The process of collecting training data is implemented in the Expert Advisor "...\ExORL\ResearchExORL.mq5".
Pay attention to the indication of the framework in the file name. The attachment contains the file "...\ExORL\Research.mq5" which has been transferred from the previous article. Therefore, we will not discuss its algorithm again.
These two Expert Advisors are intended to populate the training dataset. Oddly enough, we will use the EA during the training process. However, we will talk about this a little later. Now let's consider the algorithm of the Expert Advisor "...\ExORL\ResearchExORL.mq5".
The EA external parameters have been transferred from the basic EA for interaction with the environment.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input double MinProfit = 10; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price input int Agent = 1;
In the process of interaction, we will train the environment study policy for the Actor. In the learning process, we will need Critic and Encoder models. To reduce the cost of training the exploratory policy and, as a result, to increase the speed of collecting training data, I decided to use only 1 Critic.
CNet Actor; CNet Critic; CNet Convolution;
In addition, we will add a flag for loading previously passed trajectories and a matrix of their embeddings to the list of global variables.
bool BaseLoaded; matrix<float> state_embeddings;
In the OnInit EA initialization method, we first initialize the indicators that we analyze.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; }
Indicate the trading operation filling type.
//--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED;
Load the pre-trained models. If there are no pre-trained models, create new ones initialized with random weights. In this EA, I decided to divide model loading into different blocks, which allows me to use a previously trained Critic while there is no trained Actor or Encoder.
Please note that previously we always talked about the need to have a complete set of synchronized models. In this case, we deliberately use a Critic trained separately from the Actor. There's a reason for that. I had an idea of constructing an algorithm for synchronizing weight coefficients between models in different MetaTrader 5 testing agents. However, instead, I decided to create several parallel trained Actor exploratory models. Such models, once initialized with random parameters, will be trained in parallel on historical data. Although they use the same historical segment, each exploratory Actor model will have its individual learning path. This will expand the explored subspace of the environment. Using one buffer of previously completed trajectories will minimize the repetition of trajectories.
To identify exploratory Actor models, we add the suffix 'Ex' and the agent number from external parameters to the name of the model file. Optimization for this parameter allows us to run several exploratory Actors in parallel in the MetaTrader 5 strategy tester.
//--- load models float temp; if(!Actor.Load(StringFormat("%sAct%d.nnw", FileName, Agent), temp, temp, temp, dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); if(!CreateDescriptions(actor, critic, critic)) { delete actor; delete critic; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete critic; return INIT_FAILED; } delete actor; delete critic; //--- }
At the same time, to organize identical training conditions for all exploratory Actors, we use one Critic model. This is why it is important to load the pre-trained Critic model even if there are no exploratory Actor models.
if(!Critic.Load(FileName + "Crt1.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new Critic and Encoder models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); if(!CreateDescriptions(actor, critic, convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } if(!Critic.Create(critic)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } delete actor; delete critic; delete convolution; //--- }
Using a single Encoder model for all agents also allows us to organize a comparison of states and actions in a single subspace. But this is not critical for the learning process since each Agent independently encodes previously passed trajectories. This allows it to correctly evaluate distances and diversify the Actor's behavior.
if(!Convolution.Load(FileName + "CNN.nnw", temp, temp, temp, dtStudied, true)) { Print("Init new Critic and Encoder models"); CArrayObj *actor = new CArrayObj(); CArrayObj *critic = new CArrayObj(); CArrayObj *convolution = new CArrayObj(); if(!CreateDescriptions(actor, critic, convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } if(!Convolution.Create(convolution)) { delete actor; delete critic; delete convolution; return INIT_FAILED; } delete actor; delete critic; delete convolution; //--- }
I agree that the presented code looks cumbersome. Probably, it would be logical to divide the description of the model architecture according to different methods. But this would simplify the code for only this EA. On the other hand, this would complicate the code of other programs used in the article. For this reason, I decided not to fragment the method describing the model architecture.
We transfer all models into a single OpenCL context. This will allow us to synchronize their operation and reduce the amount of data copying between the main memory and OpenCL context memory.
Critic.SetOpenCL(Actor.GetOpenCL());
Convolution.SetOpenCL(Actor.GetOpenCL());
Critic.TrainMode(false);
Please note that we are disabling the Critic training mode. Earlier we discussed the importance of creating the same training conditions for all environment exploring Agents. Keeping the Critic in a fixed state plays an important role in this process.
After that, we implement the standard minimal control of the model architecture.
Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); if(Result.Total() != (HistoryBars * BarDescr)) { PrintFormat("Input size of Actor doesn't match state description (%d <> %d)", Result.Total(), (HistoryBars * BarDescr)); return INIT_FAILED; }
Then, initialize global variables.
PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); BaseLoaded = false; bGradient.BufferInit(MathMax(AccountDescr, NActions), 0); //--- return(INIT_SUCCEEDED); }
After successfully completing all the above operations, we complete the EA initialization method.
In the program initialization method, we do not load previously completed trajectories. Also, we do not create their embeddings. This is because the process of creating embeddings of previously passed states can be quite expensive and time-consuming. Its duration depends on the number of states visited.
As mentioned earlier, unlike the previously discussed EAs interacting with the environment, in this case, we train the exploratory Actor. Upon completion of each pass, we save the trained model.
void OnDeinit(const int reason) { //--- ResetLastError(); if(!Actor.Save(StringFormat("%sActEx%d.nnw", FileName, Agent), 0, 0, 0, TimeCurrent(), true)) PrintFormat("Error of saving Agent %d: %d", Agent, GetLastError()); delete Result; }
Now let's briefly consider the created helper methods. The CreateEmbeddings method implements the process of encoding states and actions. This method has no parameters and returns a state embedding matrix.
In the method body, we first create local variables.
matrix<float> CreateEmbeddings(void) { vector<float> temp; CBufferFloat State; Convolution.getResults(temp); matrix<float> result = matrix<float>::Zeros(0, temp.Size());
Then we try to load the previously collected trajectory database. If data loading fails, return an empty matrix to the caller.
BaseLoaded = LoadTotalBase(); if(!BaseLoaded) { PrintFormat("%s - %d => Error of load base", __FUNCTION__, __LINE__); return result; }
If the trajectory database is successfully loaded, we count the total number of states in all trajectories and change the size of the matrix to be filled.
int total_tr = ArraySize(Buffer); //--- int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total; result.Resize(total_states, temp.Size());
Next comes a system of nested loops for encoding states and actions. In the outer loop, we iterate over the loaded trajectories. In the nested loop, we iterate over states.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state);
In the body of the specified loop system, we first create a buffer of raw data describing the state of the environment. We transfer historical price and indicator data to the specified buffer.
Then we add a description of the account state and open positions.
float prevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float prevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - prevBalance) / prevBalance); State.Add(Buffer[tr].States[st].account[1] / prevBalance); State.Add((Buffer[tr].States[st].account[1] - prevEquity) / prevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / prevBalance); State.Add(Buffer[tr].States[st].account[5] / prevBalance); State.Add(Buffer[tr].States[st].account[6] / prevBalance);
Add a timestamp in the form of a harmonic vector.
double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
Add the Actor's action vector.
State.AddArray(Buffer[tr].States[st].action);
We pass the assembled tensor to the Encoder and call the feed-forward method. The resulting embedding is added to the results matrix.
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp); if(!result.Row(temp, state)) continue; state++; } } }
Then we move on to the next state from the trajectory buffer.
After completing all iterations of the state encoding loop system, we reduce the size of the result matrix to the actual number of saved embeddings and clear the buffer of previously loaded trajectories. After that we will only work with embeddings.
if(state != total_states) result.Reshape(state, result.Cols()); ArrayFree(Buffer);
Return the result to the calling program and terminate the method.
//--- return result; }
Next, we built a method for generating internal reward ResearchReward. Note that in order to create a system for effective exploration of the environment when training exploratory Actors, we will use only internal rewards aimed at encouraging the Agent to perform diverse and non-repetitive actions. Therefore, at this stage, we do not need labeled data or extrinsic rewards which can limit the environmental space. In this regard, special attention should be paid to the formation of internal rewards.
In the parameters of the ResearchReward method, we pass:
- quantile of the closest states and actions used to form internal rewards
- embedding of the analyzed state
- state embedding matrix, which was formed using the method presented above
In the method body, we prepare a zero result vector and check whether the embedding sizes of the analyzed state match the embeddings in the previously created matrix.
vector<float> ResearchReward(double quant, vector<float> &embedding, matrix<float> &state_embedding) { vector<float> result = vector<float>::Zeros(NRewards); if(embedding.Size() != state_embedding.Cols()) { PrintFormat("%s -> %d Inconsistent embedding size", __FUNCTION__, __LINE__); return result; }
After successfully passing the control block, initialize the local variables.
ulong size = embedding.Size(); ulong states = state_embedding.Rows(); ulong k = ulong(states * quant); matrix<float> temp = matrix<float>::Zeros(states, size); vector<float> min_dist = vector<float>::Zeros(k); matrix<float> k_embedding = matrix<float>::Zeros(k + 1, size); matrix<float> U, V; vector<float> S;
In the next step, we calculate the distance between the analyzed State-Action pair which was previously saved in the experience replay buffer. To obtain a soft estimate of distances, we use the LogSumExp function, as proposed by the authors of the DWSL method.
for(ulong i = 0; i < size; i++) temp.Col(MathAbs(state_embedding.Col(i) - embedding[i]), i); float alpha = temp.Max(); if(alpha == 0) alpha = 1; vector<float> dist = MathLog(MathExp(temp / (-alpha)).Sum(1)) * (-alpha);
Next, we select the required number of embeddings of the nearest State-Action pairs.
float max = dist.Quantile(quant); for(ulong i = 0, cur = 0; (i < states && cur < k); i++) { if(max < dist[i]) continue; min_dist[cur] = dist[i]; k_embedding.Row(state_embedding.Row(i), cur); cur++; } k_embedding.Row(embedding, k);
Using the nuclear norms algorithm, we generate an internal reward for the selected Actor action and latent state.
k_embedding.SVD(U, V, S); result[NRewards - 2] = S.Sum() / (MathSqrt(MathPow(k_embedding, 2.0f).Sum() * MathMax(k + 1, size))); result[NRewards - 1] = EntropyLatentState(Actor); //--- return result; }
The result is returned to the calling program.
Note that in the outcome vector, the extrinsic reward elements were left with zero values. Which is consistent with the ExORL framework. The EA in question is designed to organize an uncontrolled exploration of the environment. As mentioned above, the use of extrinsic rewards at this stage will only narrow the subspace under study.
The process of interaction with the environment and exploratory Actor training is implemented in the OnTick tick processing method. Please note that at this stage the learning process was simplified. Only 1 Critic is used in the learning process. In addition, we do eliminate the use of the experience replay buffer in the exploratory Actor model training process. Potentially, the absence of this buffer is compensated for by additional passes in the strategy tester.
We will perform one backpropagation pass on each candlestick. Parameters are adjusted based on the last action of the Actor.
This approach may not be the most effective or easiest to implement. However, it is quite applicable for evaluating the effectiveness of the method.
In the body of the method, first check the emergence of a new bar.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return;
Then we load the historical data.
//--- int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
Next, we create the source data buffers of our exploratory Actor. Here we first populate the environmental state description buffer with the received historical data.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; } bState.AssignArray(sState.state);
Next, we check the current account status and open positions.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
Based on the received data, we create a buffer describing the account status.
bAccount.Clear(); bAccount.Add((float)((sState.account[0] - PrevBalance) / PrevBalance)); bAccount.Add((float)(sState.account[1] / PrevBalance)); bAccount.Add((float)((sState.account[1] - PrevEquity) / PrevEquity)); bAccount.Add(sState.account[2]); bAccount.Add(sState.account[3]); bAccount.Add((float)(sState.account[4] / PrevBalance)); bAccount.Add((float)(sState.account[5] / PrevBalance)); bAccount.Add((float)(sState.account[6] / PrevBalance));
To this buffer, we add the timestamp harmonic vector.
double x = (double)Rates[0].time / (double)(D'2024.01.01' - D'2023.01.01'); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_MN1); bAccount.Add((float)MathCos(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_W1); bAccount.Add((float)MathSin(2.0 * M_PI * x)); x = (double)Rates[0].time / (double)PeriodSeconds(PERIOD_D1); bAccount.Add((float)MathSin(2.0 * M_PI * x));
The generated data is sufficient to run a feed-forward pass of the Actor.
if(bAccount.GetIndex() >= 0) if(!bAccount.BufferWrite()) return; //--- if(!Actor.feedForward(GetPointer(bState), 1, false, GetPointer(bAccount))) return;
As a result of a successful feed-forward pass of the Actor, we obtain a vector of predictive actions, which we decrypt and transmit to the environment.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1]; //--- vector<float> temp; Actor.getResults(temp); //--- double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
First, we interact with the environment as part of a long position.
//--- buy control if(temp[0] < min_lot || (temp[1] * MaxTP * Symb.Point()) <= stops || (temp[2] * MaxSL * Symb.Point()) <= stops) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()); double buy_sl = NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Repeat for the short position.
//--- sell control if(temp[3] < min_lot || (temp[4] * MaxTP * Symb.Point()) <= stops || (temp[5] * MaxSL * Symb.Point()) <= stops) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()); double sell_sl = NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
The results of interaction with the environment are then collected into a structure for describing state and actions. Then we add the extrinsic reward. After that, add all this to the trajectory, which, based on the pass results, will be added to the experience replay buffer.
//--- sState.rewards[0] = bAccount[0]; sState.rewards[1] = 1.0f - bAccount[1]; if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove();
Pay attention to the reward vector. So far we have been talking about uncontrolled exploration, while the vector is filled with external rewards. The elements of internal reward, on the contrary, are left with zero values. Note that the saved trajectories will be used to train the main Actor policy at stage 3 of the ExORL framework. However, the population of the reward buffer is the implementation of stage 2 related to the revaluation of states and actions. Therefore, all our actions fit within the framework of the ExORL algorithm.
As you can see, the algorithm presented above is almost identical to the methods of interaction with the environment that we discussed earlier. But here we do not complete the method operation, as before. Instead, we move on to the implementation of the learning process for the exploratory Actor policy.
First of all, we need embedding of the current state and the completed action. To obtain them, we add information about the account status and the Actor's performed action to the buffer of the current environment state. We feed the resulting buffer to the Encoder input and call the feed-forward method.
bState.AddArray(GetPointer(bAccount)); bState.AddArray(temp); bActions.AssignArray(temp); if(!Convolution.feedForward(GetPointer(bState), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return; } Convolution.getResults(temp);
As a result of successful operations, we receive an embedding of the current state.
Next, we check if there is any loaded data about previously traveled trajectories and, if necessary, encode them by calling the CreateEmbeddings method presented above.
if(!BaseLoaded) { state_embeddings = CreateEmbeddings(); BaseLoaded = true; }
Please note that regardless of the result of the operations, we set the data loading flag to true. This will allow us to eliminate repeated attempts to load the database of passed states in the future.
Next, we check the size of the state embedding matrix. The zero size of this matrix may indicate the absence of previously traveled trajectories. In this case, we do not have data to update the model parameters at this stage. Therefore, we simply add embedding of the current state to the matrix. Then we move on to waiting for the opening of the next candlestick.
ulong total_states = state_embeddings.Rows(); if(total_states <= 0) { ResetLastError(); if(!state_embeddings.Resize(total_states + 1, state_embeddings.Cols()) || !state_embeddings.Row(temp, total_states)) PrintFormat("%s -> %d: Error of adding new embedding %", __FUNCTION__, __LINE__, GetLastError()); return; }
If there is data in the passed state embedding matrix, we generate an internal reward and add the current state embedding to the matrix.
vector<float> rewards = ResearchReward(Quant, temp, state_embeddings); ResetLastError(); if(!state_embeddings.Resize(total_states + 1, state_embeddings.Cols()) || !state_embeddings.Row(temp, total_states)) PrintFormat("%s -> %d: Error of adding new embedding %", __FUNCTION__, __LINE__, GetLastError());
It is very important to add the current state embedding to the matrix of passed state embeddings only after generating an internal reward. Otherwise, the current embedding will be taken into account twice when calculating the internal reward, which can distort the data.
On the other hand, complete exclusion of the process of adding embeddings to the matrix will not allow taking into account the current pass state when generating internal rewards.
We transfer the generated internal reward to the data buffer. After that, we run the feed-forward and backpropagation passes for the Critic. This is followed by the backpropagation pass for the exploratory Actor.
Result.AssignArray(rewards); if(!Critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(bActions)) || !Critic.backProp(Result, GetPointer(bActions), GetPointer(bGradient)) || !Actor.backPropGradient(GetPointer(bAccount), GetPointer(bGradient), LatentLayer)) PrintFormat("%s -> %d: Error of backpropagation %", __FUNCTION__, __LINE__, GetLastError()); }
Please note that in this case, within one operation, we implement sequential calls of the feed-forward and backpropagation methods of the Critic. This is because in this case, we do not train the Critic and do not evaluate the results of its feed-forward pass. We only need it to transmit the error gradient to the Actor. Therefore, both methods are called as part of the Actor's backpropagation procedure. This led to such an unusual arrangement of method calls that, in other respects, does not affect the final result.
This concludes the description of the method of interaction with the environment and online learning of the exploratory Actor policy. Other EA methods are used without changes. You can find them in the attachment.
We move on to adjusting the model training Expert Advisor. Even though the authors of the method used basic methods for training models in their experiments, the implementation of our approach required some changes to the training EA from the previous article. The changes were mainly due to changes in the Encoder architecture, which resulted in changes related to the interaction with the model. But first things first.
The changes made are not global. Therefore, we will focus only on considering the model training method 'Train'. In the method body, we check the number of loaded trajectories.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount();
Then we count the total number of states in these trajectories.
int total_states = Buffer[0].Total; for(int i = 1; i < total_tr; i++) total_states += Buffer[i].Total;
Next, we prepare local variables.
vector<float> temp, next; Convolution.getResults(temp); matrix<float> state_embedding = matrix<float>::Zeros(total_states, temp.Size()); matrix<float> rewards = matrix<float>::Zeros(total_states, NRewards); matrix<float> actions = matrix<float>::Zeros(total_states, NActions);
After that, we organize a system of loops to encode previously passed states and compile an embedding matrix. This process resembles the process described above. But there is one caveat.
As before, in the body of the loop system, we fill the current environment state buffer.
int state = 0; for(int tr = 0; tr < total_tr; tr++) { for(int st = 0; st < Buffer[tr].Total; st++) { State.AssignArray(Buffer[tr].States[st].state);
Add to it the account status and open positions.
float PrevBalance = Buffer[tr].States[MathMax(st - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(st - 1, 0)].account[1]; State.Add((Buffer[tr].States[st].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[st].account[1] / PrevBalance); State.Add((Buffer[tr].States[st].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[st].account[2]); State.Add(Buffer[tr].States[st].account[3]); State.Add(Buffer[tr].States[st].account[4] / PrevBalance); State.Add(Buffer[tr].States[st].account[5] / PrevBalance); State.Add(Buffer[tr].States[st].account[6] / PrevBalance);
Fill the harmonics of the timestamp.
double x = (double)Buffer[tr].States[st].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_MN1); State.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_W1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[st].account[7] / (double)PeriodSeconds(PERIOD_D1); State.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
But instead of an action vector, we pass a zero vector of the appropriate length.
State.AddArray(vector<float>::Zeros(NActions));
This solution eliminates the influence of completed actions on the state embedding. It thereby returns us to the implementation of the DWSL method from the previous article, leveling out the changes in the Encoder architecture. Thus, in accordance with the recommendations of the authors of the ExORL method, we use unchanged methods for training models. In this case, in the process of training all models, we use one State-Action Encoder. This enables correct training of both the exploratory Actor policy and the main Actor policy.
Next, we execute a feed-forward pass of the Encoder. The result of the operations in the form of state embedding is added to the matrix.
if(!Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); return; } Convolution.getResults(temp); if(!state_embedding.Row(temp, state)) continue;
Simultaneously, we populate the action and reward matrices that will be used in the learning process in accordance with the DWSL algorithm. As before, the reward matrix is filled with the values of the advantages of the actions taken.
if(!temp.Assign(Buffer[tr].States[st].rewards) || !next.Assign(Buffer[tr].States[st + 1].rewards) || !rewards.Row(temp - next * DiscFactor, state)) continue; if(!temp.Assign(Buffer[tr].States[st].action) || !actions.Row(temp, state)) continue; state++;
Inform the user about the state encoding progress and move on to the next iteration of the loop system.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %6.2f%%", "Embedding ", state * 100.0 / (double)(total_states)); Comment(str); ticks = GetTickCount(); } } }
After successfully completing all state encoding iterations, we reduce the matrix sizes to the amount of data actually saved. However, unlike the CreateEmbeddings coding method discussed above, we do not clear the trajectory array, since we will still need it when training models.
if(state != total_states)
{
rewards.Resize(state, NRewards);
actions.Resize(state, NActions);
state_embedding.Reshape(state, state_embedding.Cols());
total_states = state;
}
Next, we need to organize the learning process. First, we create local variables and form a vector of trajectories selection probabilities.
vector<float> rewards1, rewards2, target_reward; STarget target; //--- vector<float> probability = GetProbTrajectories(Buffer, 0.9); int bar = (HistoryBars - 1) * BarDescr;
Then we create a training loop. In the body of the loop, we sample the trajectory and the state on it.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = SampleTrajectory(probability); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2)); if(i < 0) { iter--; continue; }
We then check whether the reward needs to be generated before the end of the episode. If it needs to be generated, we fill the buffer of the subsequent state of the environment.
target_reward = vector<float>::Zeros(NRewards); //--- Target if(iter >= StartTargetIter) { State.AssignArray(Buffer[tr].States[i + 1].state);
We immediately populate the buffer describing the subsequent account state and open positions.
float PrevBalance = Buffer[tr].States[i].account[0]; float PrevEquity = Buffer[tr].States[i].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i + 1].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i + 1].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i + 1].account[2]); Account.Add(Buffer[tr].States[i + 1].account[3]); Account.Add(Buffer[tr].States[i + 1].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i + 1].account[6] / PrevBalance);
Add to it the harmonics of the timestamp.
double x = (double)Buffer[tr].States[i + 1].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i + 1].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
The generated data is enough to perform the feed-forward pass of the Actor, which will generate an action in accordance with the updated policy.
//--- if(Account.GetIndex() >= 0) Account.BufferWrite(); if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
The resulting action is evaluated by 2 target Critics.
if(!TargetCritic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor)) || !TargetCritic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } TargetCritic1.getResults(rewards1); TargetCritic2.getResults(rewards2);
We use the lower of the estimates as the expected reward and add the entropy of the latent state to it.
target_reward.Assign(Buffer[tr].States[i + 1].rewards); if(rewards1.Sum() <= rewards2.Sum()) target_reward = rewards1 - target_reward; else target_reward = rewards2 - target_reward; target_reward *= DiscFactor; target_reward[NRewards - 1] = EntropyLatentState(Actor); }
In the next step, we train the Critics model. To do this, we form a vector describing the current state of the environment.
//--- Q-function study
State.AssignArray(Buffer[tr].States[i].state);
Form a vector describing the account state and open positions, supplemented with harmonics of the timestamp.
float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; Account.Clear(); Account.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); Account.Add(Buffer[tr].States[i].account[1] / PrevBalance); Account.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); Account.Add(Buffer[tr].States[i].account[2]); Account.Add(Buffer[tr].States[i].account[3]); Account.Add(Buffer[tr].States[i].account[4] / PrevBalance); Account.Add(Buffer[tr].States[i].account[5] / PrevBalance); Account.Add(Buffer[tr].States[i].account[6] / PrevBalance); double x = (double)Buffer[tr].States[i].account[7] / (double)(D'2024.01.01' - D'2023.01.01'); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_MN1); Account.Add((float)MathCos(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_W1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0)); x = (double)Buffer[tr].States[i].account[7] / (double)PeriodSeconds(PERIOD_D1); Account.Add((float)MathSin(x != 0 ? 2.0 * M_PI * x : 0));
After that the feed-forward pass for the Actor.
if(Account.GetIndex() >= 0) Account.BufferWrite(); //--- if(!Actor.feedForward(GetPointer(State), 1, false, GetPointer(Account))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
As you may remember, we use actual actions taken while interacting with the environment to train Critics. But we need the feed-forward pass of the Actor to form the latent state.
Next, we copy the actual actions from the training set into the data buffer and perform a feed-forward pass of the Critics.
Actions.AssignArray(Buffer[tr].States[i].action); if(Actions.GetIndex() >= 0) Actions.BufferWrite(); //--- if(!Critic1.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions)) || !Critic2.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actions))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
After that, we take the buffer with the current environment state description and add to it data on the account state and a zero vector to replace the actions of the Actor. Then we generate an embedding of the analyzed state of the environment.
if(!State.AddArray(GetPointer(Account)) || !State.AddArray(vector<float>::Zeros(NActions)) || !Convolution.feedForward(GetPointer(State), 1, false, NULL)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Convolution.getResults(temp);
Based on the received embedding, we generate a structure of targets to train models. The algorithm of the method that generates target values was described in the previous article.
target = GetTargets(Quant, temp, state_embedding, rewards, actions);
In this step, we have all the necessary data for the backpropagation pass of the Critics. But since we will correct the error gradient vector using the CAGrad method, we need to train the models sequentially.
Critic1.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); if(!Critic1.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } Critic2.getResults(rewards2); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards2) + rewards2); if(!Critic2.backProp(Result, GetPointer(Actions), GetPointer(Gradient)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient), LatentLayer)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
In this step, we train the basic policy of the Actor. As before, we will use combinations of approaches to train policy. First, we use the DWSL algorithm and train the Actor to repeat actions, weighted by their impact on the final result.
//--- Policy study Actor.getResults(rewards1); Result.AssignArray(CAGrad(target.actions - rewards1) + rewards1); if(!Actor.backProp(Result, GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; }
After that, we adjust the Actor's actions in the return increase direction. Only the second stage of training is used when we are quite confident in the correctness of the Critic's assessment of actions.
//--- CNet *critic = NULL; if(Critic1.getRecentAverageError() <= Critic2.getRecentAverageError()) critic = GetPointer(Critic1); else critic = GetPointer(Critic2); if(MathAbs(critic.getRecentAverageError()) <= MaxErrorActorStudy) { if(!critic.feedForward(GetPointer(Actor), LatentLayer, GetPointer(Actor))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); break; } critic.getResults(rewards1); Result.AssignArray(CAGrad(target.rewards + target_reward - rewards1) + rewards1); critic.TrainMode(false); if(!critic.backProp(Result, GetPointer(Actor)) || !Actor.backPropGradient(GetPointer(Account), GetPointer(Gradient))) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); critic.TrainMode(true); break; } critic.TrainMode(true); }
At the end of the iterations of the training process, we adjust the parameters of the target models.
//--- Update Target Nets if(iter >= StartTargetIter) { TargetCritic1.WeightsUpdate(GetPointer(Critic1), Tau); TargetCritic2.WeightsUpdate(GetPointer(Critic2), Tau); } else { TargetCritic1.WeightsUpdate(GetPointer(Critic1), 1); TargetCritic2.WeightsUpdate(GetPointer(Critic2), 1); }
Inform the user about the progress of the learning process and move on to the next iteration of the learning loop.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic1", iter * 100.0 / (double)(Iterations), Critic1.getRecentAverageError()); str += StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Critic2", iter * 100.0 / (double)(Iterations), Critic2.getRecentAverageError()); str += StringFormat("%-14s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
After completing the full model training loop, clear the comments field on the graph. Output the training results to the log and initiate the process of terminating the EA operation.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic1", Critic1.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Critic2", Critic2.getRecentAverageError()); PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
This concludes the description of the algorithms of the programs used. The full code of all programs used in the article is available in the attachment. We are now moving on to testing the work done.
3. Testing
In the previous sections of this article, we got acquainted with the Exploratory data for Offline RL method and implemented our vision of the presented method using MQL5. Now it's time to evaluate the results. As always, training and testing of models is carried out on EURUSD H1. Indicators are used with default parameters. The models are trained on historical data for the first 7 months of 2023. To test the trained model, we use historical data from August 2023.
The algorithm presented in the article enables the training of completely new models. That is training from scratch. However, the method also allows for fine-tuning of previously trained models. So, I decided to test the second option. As I said at the very beginning of the article, I used EAs from the previous article as the basis for this work. Ao, we will optimize this model. First, we need to rename the model files.
| DWSL.bd | ==> | ExORL.bd |
| DWSLAct.nnw | ==> | ExORLAct.nnw |
| DWSLCrt1.nnw | ==> | ExORLCrt1.nnw |
| DWSLCrt2.nnw | ==> | ExORLCrt2.nnw |
We are not transferring the Encoder model because we have changed its architecture.
After renaming the files, we launch the EA ResearchExORL.mq5 for additional study of the environment on the training data. In my work, I collected 100 additional passes from 5 testing agents.
Practical experience shows the possibility of parallel use in one replay buffer collected by different methods. I used both the trajectories collected by the previously discussed EA Research.mq5 and the EA ResearchExORL.mq5. The first one indicates the advantages and disadvantages of the learned Actor policy. The second allows us to explore the environment as much as possible and evaluate unaccounted opportunities.
In the process of iterative model training, I managed to improve its performance.


While there was a general decrease in the number of trades during the test period by 3 times (56 versus 176), profits increased almost 3 times. The amount of the maximum profitable trade has more than doubled. And the average profitable trade increased by 5 times. Furthermore, we observe an increase in the balance throughout the entire testing period. As a result, the profit factor of the model has increased from 1.3 to 2.96.
Conclusion
In this article, we introduced a new method, Exploratory data for Offline RL, which mainly focuses on the approach to collecting data for the training dataset for offline model training. The experiments conducted by the authors of the method make the problem of choosing source data one of the key ones, which influences the result on a par with the selection of model architecture and its training method.
In the practical part of our article, we implemented our vision of the proposed method and tested it using historical data from the MetaTrader 5 strategy tester. The tests confirm the conclusions of the method authors about the influence of the training sample collection algorithm on the model training result. Thus, by changing the approach to collecting training trajectories, we managed to optimize the performance of the model presented in the previous article.
However, once again, I would like to remind you that all the programs presented in the article are intended only to demonstrate the technology and are not prepared for use in real trading.
References
Programs used in the article
| # | Name | Type | Description |
|---|---|---|---|
| 1 | Research.mq5 | EA | Example collection EA |
| 2 | ResearchExORL.mq5 | EA | EA for collecting examples using the ExORL method |
| 3 | Study.mq5 | EA | Agent training EA |
| 4 | Test.mq5 | EA | Model testing EA |
| 5 | Trajectory.mqh | Class library | System state description structure |
| 6 | NeuroNet.mqh | Class library | A library of classes for creating a neural network |
| 7 | NeuroNet.cl | Code Base | OpenCL program code library |
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/13819
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
I don't know how MetaTrader Tester selects inputs for each core. Main idea in online study use pretrained model from one pass to another. But if Tester run Optimithation 1..4 to Agent 1 at one pass the they all use random (not pretrained) model.
I don't know how MetaTrader Tester selects inputs for each core. Main idea in online study use pretrained model from one pass to another. But if Tester run Optimithation 1..4 to Agent 1 at one pass the they all use random (not pretrained) model.
I also added some indicators and Parameters, total 27 BarDescr.... Momentum, Bands & Ichimoku Kinko Hyo =)
int OnInit()
{
Set symbol and refresh
if(! Symb.Name(_Symbol))
return INIT_FAILED;
Symb.Refresh();
//---
if(! RSI. Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice))
return INIT_FAILED;
//---
if(! CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice))
return INIT_FAILED;
//---
if(! ATR. Create(Symb.Name(), TimeFrame, ATRPeriod))
return INIT_FAILED;
//---
if(! MACD. Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)))
return INIT_FAILED;
//---
if (! Momentum.Create(Symb.Name(), TimeFrame, MomentumMaPeriod, MomentumApplied))
return INIT_FAILED;
Initialise the Ichimoku Kinko Hyo indicator
if (! Ichimoku.Create(Symb.Name(), TimeFrame, Ichimokutenkan_senPeriod, Ichimokukijun_senPeriod, Ichimokusenkou_span_bPeriod)))
return INIT_FAILED;
//---
if (! Bands.Create(Symb.Name(), TimeFrame, BandsMaPeriod, BandsMaShift, BandsDeviation, BandsApplied))
return INIT_FAILED;
//---
if(! RSI. BufferResize(HistoryBars) || ! CCI.BufferResize(HistoryBars) ||
! ATR. BufferResize(HistoryBars) || ! MACD. BufferResize(HistoryBars))
{
PrintFormat("%s -> %d", __FUNCTION__, __LINE__);
return INIT_FAILED;
}
//---
void OnTick()
{
//---
if(! IsNewBar())
return;
//---
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates);
if(! ArraySetAsSeries(Rates, true))
return;
//---
RSI. Refresh();
CCI.Refresh();
ATR. Refresh();
MACD. Refresh();
Symb.Refresh();
Momentum.Refresh();
Bands.Refresh();
Symb.RefreshRates();
Refresh Ichimoku values for the current bar
Ichimoku.Refresh();
--- History Data
float atr = 0;
for (int b = 0; b < (int)HistoryBars; b++)
{
float open = (float)Rates[b].open;
float close = (float)Rates[b].close;
float rsi = (float)RSI. Main(b);
float cci = (float)CCI.Main(b);
atr = (float)ATR. Main(b);
float macd = (float)MACD. Main(b);
float sign = (float)MACD. Signal(b);
float mome = (float)Momentum.Main(b);
float bandzup = (float)Bands.Upper(b);
float bandzb = (float)Bands.Base(b);
float bandzlo = (float)Bands.Lower(b);
float tenkan = (float)Ichimoku.TenkanSen(0); Use the calculated value
float kijun = (float)Ichimoku.KijunSen(1); Use the calculated value
float senkasa = (float)Ichimoku.SenkouSpanA(2); Use the calculated value
float senkb = (float)Ichimoku.SenkouSpanB(3); Use the calculated value
Check for EMPTY_VALUE and division by zero
if (rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE ||
sign == EMPTY_VALUE || mome == EMPTY_VALUE || bandzup == EMPTY_VALUE || bandzb == EMPTY_VALUE || bandzb == EMPTY_VALUE ||
bandzlo == EMPTY_VALUE || tenkan == EMPTY_VALUE || kijun == EMPTY_VALUE || senkasa == EMPTY_VALUE || senkasa == EMPTY_VALUE ||
senkb == EMPTY_VALUE || kijun == 0.0 || senkb == 0.0)
{
continue;
}
Ensure buffers are not resized within the loop
int shift = b * BarDescr;
sState.state[shift] = (float)(Rates[b].close - open);
sState.state[shift + 1] = ((float)(Rates[b].close - open) + (tenkan - kijun)) / 2.0f;
sState.state[shift + 2] = (float)(Rates[b].high - open);
sState.state[shift + 3] = (float)(Rates[b].low - open);
sState.state[shift + 4] = (float)(Rates[b].high - close);
sState.state[shift + 5] = (float)(Rates[b].low - close);
sState.state[shift + 6] = (tenkan - kijun);
sState.state[shift + 7] = (float)(Rates[b].tick_volume / 1000.0f);
sState.state[shift + 8] = ((float)(Rates[b].high) - (float)(Rates[b].low));
sState.state[shift + 9] = (bandzup - bandzlo);
sState.state[shift + 10] = rsi;
sState.state[shift + 11] = cci;
sState.state[shift + 12] = atr;
sState.state[shift + 13] = macd;
sState.state[shift + 14] = sign;
sState.state[shift + 15] = mome;
sState.state[shift + 16] = (float)(Rates[b].open - tenkan);
sState.state[shift + 17] = (float)(Rates[b].open - kijun);
sState.state[shift + 18] = (float)(Rates[b].open - bandzb);
sState.state[shift + 19] = (float)(Rates[b].open - senkasa);
sState.state[shift + 20] = (float)(Rates[b].open - senkb);
sState.state[shift + 21] = (float)(Rates[b].close - tenkan);
sState.state[shift + 22] = (float)(Rates[b].close - kijun);
sState.state[shift + 23] = (float)(Rates[b].close - bandzb);
sState.state[shift + 24] = (float)(Rates[b].close - senkasa);
sState.state[shift + 25] = (float)(Rates[b].close - senkb);
sState.state[shift + 26] = senkasa - senkb;
//---
RSI.Refresh();
CCI.Refresh();
ATR.Refresh();
MACD.Refresh();
Symb.Refresh();
Momentum.Refresh();
Bands.Refresh();
Symb.RefreshRates();
// Refresh Ichimoku values for the current bar
Ichimoku.Refresh();
//---
Print("State 0: ", sState.state[shift]);
Print("State 1: ", sState.state[shift + 1]);
Print("State 2: ", sState.state[shift + 2]);
Print("State 3: ", sState.state[shift + 3]);
Print("State 4: ", sState.state[shift + 4]);
Print("State 5: ", sState.state[shift + 5]);
Print("State 6: ", sState.state[shift + 6]);
Print("State 7: ", sState.state[shift + 7]);
Print("State 8: ", sState.state[shift + 8]);
Print("State 9: ", sState.state[shift + 9]);
Print("State 10: ", sState.state[shift + 10]);
Print("State 11: ", sState.state[shift + 11]);
Print("State 12: ", sState.state[shift + 12]);
Print("State 13: ", sState.state[shift + 13]);
Print("State 14: ", sState.state[shift + 14]);
Print("State 15: ", sState.state[shift + 15]);
Print("State 16: ", sState.state[shift + 16]);
Print("State 17: ", sState.state[shift + 17]);
Print("State 18: ", sState.state[shift + 18]);
Print("State 19: ", sState.state[shift + 19]);
Print("State 20: ", sState.state[shift + 20]);
Print("State 21: ", sState.state[shift + 21]);
Print("State 22: ", sState.state[shift + 22]);
Print("State 23: ", sState.state[shift + 23]);
Print("State 24: ", sState.state[shift + 24]);
Print("State 25: ", sState.state[shift + 25]);
Print("State 26: ", sState.state[shift + 26]);
Print("Tenkan Sen: ", tenkan);
Print("Kijun Sen: ", kijun);
Print("Senkou Span A: ", senkasa);
Print("Senkou Span B: ", senkb);
}
bState.AssignArray(sState.state);
I also added some indicators and Parameters, total 27 BarDescr.... Momentum, Bands & Ichimoku Kinko Hyo =)
int OnInit()
{
Set symbol and refresh
if(! Symb.Name(_Symbol))
return INIT_FAILED;
Symb.Refresh();
//---
if(! RSI. Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice))
return INIT_FAILED;
//---
if(! CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice))
return INIT_FAILED;
//---
if(! ATR. Create(Symb.Name(), TimeFrame, ATRPeriod))
return INIT_FAILED;
//---
if(! MACD. Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice))
return INIT_FAILED;
//---
if (! Momentum.Create(Symb.Name(), TimeFrame, MomentumMaPeriod, MomentumApplied))
return INIT_FAILED;
Initialize the Ichimoku Kinko Hyo indicator
If (! Ichimoku.Create(Symb.Name(), TimeFrame, Ichimokutenkan_senPeriod, Ichimokukijun_senPeriod, Ichimokusenkou_span_bPeriod))
return INIT_FAILED;
//---
if (! Bands.Create(Symb.Name(), TimeFrame, BandsMaPeriod, BandsMaShift, BandsDeviation, BandsApplied))
return INIT_FAILED;
//---
if(! RSI. BufferResize(HistoryBars) || ! CCI.BufferResize(HistoryBars) ||
! ATR. BufferResize(HistoryBars) || ! MACD. BufferResize(HistoryBars))
{
PrintFormat("%s -> %d", __FUNCTION__, __LINE__);
return INIT_FAILED;
}
//---
void OnTick()
{
//---
if(! IsNewBar())
return;
//---
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates);
if(! ArraySetAsSeries(Rates, true))
return;
//---
RSI. Refresh();
CCI.Refresh();
ATR. Refresh();
MACD. Refresh();
Symb.Refresh();
Momentum.Refresh();
Bands.Refresh();
Symb.RefreshRates();
Refresh Ichimoku values for the current bar
Ichimoku.Refresh();
--- History Data
float atr = 0;
for (int b = 0; b < (int)HistoryBars; b++)
{
float open = (float)Rates[b].open;
float close = (float)Rates[b].close;
float rsi = (float)RSI. Main(b);
float cci = (float)CCI.Main(b);
atr = (float)ATR. Main(b);
float macd = (float)MACD. Main(b);
float sign = (float)MACD. Signal(b);
float mome = (float)Momentum.Main(b);
float bandzup = (float)Bands.Upper(b);
float bandzb = (float)Bands.Base(b);
float bandzlo = (float)Bands.Lower(b);
float tenkan = (float)Ichimoku.TenkanSen(0); Use the calculated value
float kijun = (float)Ichimoku.KijunSen(1); Use the calculated value
float senkasa = (float)Ichimoku.SenkouSpanA(2); Use the calculated value
float senkb = (float)Ichimoku.SenkouSpanB(3); Use the calculated value
Check for EMPTY_VALUE and division by zero
if (rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE ||
sign == EMPTY_VALUE || mome == EMPTY_VALUE || bandzup == EMPTY_VALUE || bandzb == EMPTY_VALUE || bandzb == EMPTY_VALUE ||
bandzlo == EMPTY_VALUE || tenkan == EMPTY_VALUE || kijun == EMPTY_VALUE || senkasa == EMPTY_VALUE || senkasa == EMPTY_VALUE ||
senkb == EMPTY_VALUE || kijun == 0.0 || senkb == 0.0)
{
continue;
}
Ensure buffers are not resized within the loop
int shift = b * BarDescr;
sState.state[shift] = (float)(Rates[b].close - open);
sState.state[shift + 1] = ((float)(Rates[b].close - open) + (tenkan - kijun)) / 2.0f;
sState.state[shift + 2] = (float)(Rates[b].high - open);
sState.state[shift + 3] = (float)(Rates[b].low - open);
sState.state[shift + 4] = (float)(Rates[b].high - close);
sState.state[shift + 5] = (float)(Rates[b].low - close);
sState.state[shift + 6] = (tenkan - kijun);
sState.state[shift + 7] = (float)(Rates[b].tick_volume / 1000.0f);
sState.state[shift + 8] = ((float)(Rates[b].high) - (float)(Rates[b].low));
sState.state[shift + 9] = (bandzup - bandzlo);
sState.state[shift + 10] = rsi;
sState.state[shift + 11] = cci;
sState.state[shift + 12] = atr;
sState.state[shift + 13] = macd;
sState.state[shift + 14] = sign;
sState.state[shift + 15] = mome;
sState.state[shift + 16] = (float)(Rates[b].open - tenkan);
sState.state[shift + 17] = (float)(Rates[b].open - kijun);
sState.state[shift + 18] = (float)(Rates[b].open - bandzb);
sState.state[shift + 19] = (float)(Rates[b].open - senkasa);
sState.state[shift + 20] = (float)(Rates[b].open - senkb);
sState.state[shift + 21] = (float)(Rates[b].close - tenkan);
sState.state[shift + 22] = (float)(Rates[b].close - kijun);
sState.state[shift + 23] = (float)(Rates[b].close - bandzb);
sState.state[shift + 24] = (float)(Rates[b].close - senkasa);
sState.state[shift + 25] = (float)(Rates[b].close - senkb);
sState.state[shift + 26] = senkasa - senkb;
//---
RSI.Refresh();
CCI.Refresh();
ATR.Refresh();
MACD.Refresh();
Symb.Refresh();
Momentum.Refresh();
Bands.Refresh();
Symb.RefreshRates();
// Refresh Ichimoku values for the current bar
Ichimoku.Refresh();
//---
Print("State 0: ", sState.state[shift]);
Print("State 1: ", sState.state[shift + 1]);
Print("State 2: ", sState.state[shift + 2]);
Print("State 3: ", sState.state[shift + 3]);
Print("State 4: ", sState.state[shift + 4]);
Print("State 5: ", sState.state[shift + 5]);
Print("State 6: ", sState.state[shift + 6]);
Print("State 7: ", sState.state[shift + 7]);
Print("State 8: ", sState.state[shift + 8]);
Print("State 9: ", sState.state[shift + 9]);
Print("State 10: ", sState.state[shift + 10]);
Print("State 11: ", sState.state[shift + 11]);
Print("State 12: ", sState.state[shift + 12]);
Print("State 13: ", sState.state[shift + 13]);
Print("State 14: ", sState.state[shift + 14]);
Print("State 15: ", sState.state[shift + 15]);
Print("State 16: ", sState.state[shift + 16]);
Print("State 17: ", sState.state[shift + 17]);
Print("State 18: ", sState.state[shift + 18]);
Print("State 19: ", sState.state[shift + 19]);
Print("State 20: ", sState.state[shift + 20]);
Print("State 21: ", sState.state[shift + 21]);
Print("State 22: ", sState.state[shift + 22]);
Print("State 23: ", sState.state[shift + 23]);
Print("State 24: ", sState.state[shift + 24]);
Print("State 25: ", sState.state[shift + 25]);
Print("State 26: ", sState.state[shift + 26]);
Print("Tenkan Sen: ", tenkan);
Print("Kijun Sen: ", kijun);
Print("Senkou Span A: ", senkasa);
Print("Senkou Span B: ", senkb);
}
bState.AssignArray(sState.state);
JimReaper - How many cycles did you study your version before getting the result in your picture? (data collection - training). And how long did it take?
What is your computer configuration (processor, video card, RAM)?
Thank you
then set agent to 5 and Optimisation to 20
Total of 100...
I see Agent referenced in the code, but I don't see Optimisation. Was there a further addition to the code, which you made, to use this new parameter?
Thanks
Paul