
Evaluation of Trade Systems - the Effectiveness of Entering, Exiting and Trades in General

Introduction
There are a lot of measures that determine the effectiveness of a trade system; and traders choose the ones they like. This article tells about the approaches described in the "Statistika dlya traderov" ("Statistics for Traders") book by S.V. Bulashev. Unfortunately, the number of copies of this book is too small and it has not been republished for a long time; however, its electronic version is still available at many websites.
Prologue
I remind you that the book was published in 2003. And that was the time of MetaTrader 3 with the MQL-II programming language. And the platform was rather progressive for that time. Thus, we can track the changes of the trade conditions themselves by comparing it to the modern MetaTrader 5 client terminal. It should be noted, that the book author has become a guru for many generations of traders (considering the fast change of generations in this area). But the time doesn't stand still; despite the principles described in the book are still applicable, the approaches should be adapted.
S.V. Bulashev wrote his book, first of all, on the basis of trade conditions actual for that time. That's why we cannot use the statistics described by the author without a transformation. For making it clearer, let's remember the possibilities of trading of those times: marginal trading on a spot market implies that buying a currency to get a speculative profit turns into selling it after a while.
Those are the basics, and they're are worth of being reminded, that exact interpretation was used when the "Statistics for Traders" book was written. Each deal of 1 lot should have been closed by the reverse deal of the same volume. However, after two years (in 2005), the use of such statistics needed a reorganization. The reason is the partial closing of deals became possible in MetaTrader 4. Thus, to use the statistics described by Bulashev we need to enhance the system of interpretation, notably the interpretation should be done the fact of closing and not by opening.
After another 5 years the situation changed significantly. Where is the so habitual term Order? It has gone. Considering the flow of questions at this forum, it's better to describe the exact system of interpretation in MetaTrader 5.
So, today there's no classic term Order anymore. An order now is a trade request to a broker's server, which is made by a trader or MTS for opening or changing a trade position. Now it is a position; to understand its meaning I have mentioned the marginal trading. The matter of fact is the marginal trading is performed on borrowed money; and a position exists until that money exist.
As soon as you settle accounts with the borrower by closing the position and as a result fixing a profit/loss, your position stops existing. By the way, this fact explains the reason why a reverse of position doesn't close it. The matter of fact is the borrow stays anyway and there's no difference if you borrowed money for buying or for selling. A deal is just a history of an executed order.
Now let's talk about the features of trading. Currently, in MetaTrader 5, we can both close a trade position partially or increase an existing one. Thus, the classic system of interpretation, where each opening of a position of a certain volume is followed by the closing with the same volume, has gone to the past. But is it really impossible to recover it from the information stored in MetaTrader 5? So, first of all, we're going to reorganize the interpretation.
The Effectiveness of Entering
It's not a secret that many people want to make their trading more effective, but how to describe (formalize) this term? If you assume that a deal is a path passed by the price, then it becomes obvious that there are two extreme points on that path: minimum and maximum of price within the observed section. Everyone strives to enter the market as close to the minimum as it's possible (when buying). This can be considered as a main rule of any trading: buy at a low price, sell at a high price.
The effectiveness of entering determines how close to the minimum you buy. In other words, the effectiveness of entering is the ratio of distance between the maximum and the price of entering to the whole path. Why do we measure the distance to minimum through the difference of maximum? We need the effectiveness to be equal to 1 when entering at minimum (and to be equal to 0 when entering at maximum).
That's why for our ratio we take the rest of distance, and not the distance between the minimum and entrance itself. Here we need to point out that the situation for selling is mirrored in comparison with buying.
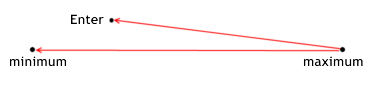
The effectiveness of entering position shows how good a MTS realizes the potential profit relatively to the price of entering during certain trade. It is calculated by the following formulas:
for long positions enter_efficiency=(max_price_trade-enter_price)/(max_price_trade-min_price_trade); for short positions enter_efficiency=(enter_price-min_price_trade)/(max_price_trade-min_price_trade); The effectiveness of entering can have a value within the range from 0 to 1.
The Effectiveness of Exiting
The situation with exiting is similar:
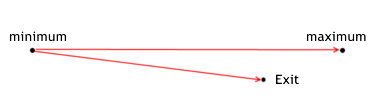
The effectiveness of exiting from a position shows how good a MTS realizes the potential profit relatively to the price of exiting from the position during certain trade. It is calculated by the following formulas:
for lone positions exit_efficiency=(exit_price - min_price_trade)/(max_price_trade - min_price_trade); for short positions exit_efficiency=(max_price_trade - exit_price)/(max_price_trade - min_price_trade); The effectiveness of exiting can have a value withing the range from 0 to 1.
The Effectiveness of a Trade
In whole, the effectiveness of a trade is determined by both entering and exiting. It can be calculated as the ratio of the path between entering and exiting to the maximum distance during the trade (i.e. the difference between minimum and maximum). Thus, the effectiveness of a trade can be calculated in two ways - directly using the primary information about the trade, or using already calculated results of previously evaluated entrances and exits (with a shift of interval).
The effectiveness of trade shows how good a MTS realizes the total potential profit during certain trade. It is calculated by following formulas:
for long positions trade_efficiency=(exit_price-enter_price)/(max_price_trade-min_price_trade); for short positions trade_efficiency=(enter_price-exit_price)/(max_price_trade-min_price_trade); general formula trade_efficiency=enter_efficiency+exit_efficiency-1; The effectiveness of trade can have a value within the range from -1 to 1. The effectiveness of trade must be greater than 0,2. The analysis of effectiveness visually shows the direction for enhancing the system, because it allows evaluating the quality of signals for entering and exiting a position separately from each other.
Transformation of Interpretation
First of all, to avoid any kind of confusion, we need to clarify the names of objects of interpretation. Since the same terms - order, deal, position are used in MetaTrader 5 and by Bulachev, we need to separate them. In my article, I'm going to use the name "trade" for the Bulachev's object of interpretation, i.e. trade is a deal; he also uses the term "order" for it, in that context these terms are identical. Bulachev calls an unfinished deal a position, and we are going to call it as unclosed trade.
Here you can see that all 3 terms are easily fit in the single word "trade". And we're not going to rename the interpretation in MetaTrader 5, and the meaning of these three terms stays the same as designed by the developers of the client terminal. As a result, we have 4 words that we're going to use - Position, Deal, Order and Trade.
Since an Order is a command to the server for opening/changing a position and it doesn't concern the statistics directly, but it does it ndirectly through a deal (the reason is sending an order doesn't always result in execution of the corresponding deal of specified volume and price), then it is right to collect the statistics by deals and not by orders.
Lets' consider an example of interpretation of the same position (to make the above description clearer):
interpretation in МТ-5 deal[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 deal[ 1 ] in/out 0.2 buy 1.22261 2010.06.14 13:36 deal[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 deal[ 3 ] out 0.2 sell 1.22310 2010.06.14 13:41
interpretation by Bulachev trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 out 1.22261 2010.06.14 13:36 trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36 out 1.22310 2010.06.14 13:41 trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 out 1.22310 2010.06.14 13:41
Now I'm going to describe the way those manipulations were conducted. Deal[ 0 ] opens the position, we write it as the start of the new trade:
trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33
Then comes the reverse of the position; it means the all previous trades should be closed. Correspondingly, the information about the reversing deal[ 1 ] will both considered in closing and in opening the new trade. Once all the unclosed trades before the deal with the in/out direction are closed, we need to open the new trade. I.e. we use only the price and time information about the selected deal for closing, as opposite to opening of a trade, when the type and volume are additionally used. Here we need to clarify that a term that hasn't been used before it appeared in the new interpretation - it is the direction of deal. Earlier, we meant a buy or sell by saying the "direction", the same meaning had the "type" term. From now and then type and direction are different terms.
Type is a buy or sell, whereas direction is entering or exiting a position. That is why a position is always opened with a deal of the in direction, and is closed with an out deal. But the direction is not limited with only opening and closing of positions. This terms also includes increasing of volume of a position (if the "in" deal is not the first in the list) and partial closing of a position (the "out" deals are not last in the list). Since the partial closing has become available, it's logical to introduce the reverse of position as well; a reverse occurs when an opposite deal of a size bigger than the current position is performed, i.e. it is an in/out deal.
So, we have closed the previously opened trades (to reverse the position):
trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 out 1.22261 2010.06.14 13:36
The rest volume is 0.1 lots, and it is used for opening the new trade:
trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36
Then come the deal[ 2 ] with the in direction, open another trade:
trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39
And finally, the deal that closes the position - deal[ 3 ] closes all the trades in the position that are not closed yet:
trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36 out 1.22310 2010.06.14 13:41 trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 out 1.22310 2010.06.14 13:41
The interpretation described above shows the gist of interpretation used by Bulachev - each open trade has a certain entry point and a certain exit point, it has its volume and type. But this system of interpretation doesn't consider one nuance - partial closing. If you look closer, you'll see that the number of trades is equal to the number of in deals (considering the in/out deals). In this case, it's worth to interpret by in deals, but there'll be more out deals at partial closing (there may be a situation when the number of in and out deals is the same, but they don't correspond each other by the volume).
To process all out deals, we should interpret by the out deals. And this contradiction seems to be insoluble if we perform a separate processing of deals, at first - all the in, and the all the out deals (or vice versa). But if we process the deals sequentially and apply a special processing rule to each one, then there are no contradictions.
Here is an example, where the number of out deals is greater than the number of in deals (with description):
interpretation in МТ-5 deal[ 0 ] in 0.3 sell 1.22133 2010.06.15 08:00 deal[ 1 ] out 0.2 buy 1.22145 2010.06.15 08:01 deal[ 2 ] in/out 0.4 buy 1.22145 2010.06.15 08:02 deal[ 3 ] in/out 0.4 sell 1.22122 2010.06.15 08:03 deal[ 4 ] out 0.1 buy 1.2206 2010.06.15 08:06
interpretation by Bulachev trade[ 0 ] in 0.2 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:01 trade[ 1 ] in 0.1 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:02 trade[ 2 ] in 0.3 buy 1.22145 2010.06.15 08:02 out 1.22122 2010.06.15 08:03 trade[ 3 ] in 0.1 sell 1.22122 2010.06.15 08:03 out 1.2206 2010.06.15 08:06
We have a situation, when a closing deal comes after opening, but it doesn't have the whole volume, but only a part of it (0.3 lots are opened and 0.2 are closed). How to handle such situation? If each trade is closed with the same volume, then the situation can be considered as opening of several trades with a single deal. Thus, they'll have the same points of opening and different points of closing (it's clear that the volume of each trade is determined by the closing volume). For example, we choose the deal[ 0 ] for processing, open the trade:
trade[ 0 ] in 0.3 sell 1.22133 2010.06.15 08:00
Then we select the deal[ 1 ], close the open trade, and during closing we find out that the closing volume is not enough. Make a copy of the previously opened trade and specify the lack of volume in its "volume" parameter. After that close the initial trade with the deal volume (i.e. we change the volume of initial trade specified at opening with the closing volume):
trade[ 0 ] in 0.2 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:01 trade[ 1 ] in 0.1 sell 1.22133 2010.06.15 08:00
Such transformation may appear not suitable for a trader, since trader may want to close another trader, not this one. But anyway, the evaluation of systems won't be harmed as a result of correct transformation. The only thing that can be hurt is trader's confidence in trading without loss trades in MetaTrader 4; this system of recalculation will reveal all delusions.
The system of statistical interpretation described in Bulachev's book doesn't have emotions and allows to honestly evaluate decisions from the position of entering, exiting and both rates in total. And the possibility of transformation of interpretation (one into another without loss of data) proves that it's wrong to say that a MTS developed for MetaTrader 4 cannot be remade for the interpretation system of MetaTrader 5. The only loss when transforming the interpretation can be the belonging of volume to different orders (MetaTrader 4). But in fact, if there are no more orders (in the old meaning of this term) to be accounted, then it's just a trader's subjective estimation.
Code for Transformation of Interpretation
Let's take a look into the code itself. To prepare a translator we need the inheritance feature of OOP. That's why I suggest those, who are note acquainted with it yet, opening the MQL5 User Guide and learning theory. First of all, let's describe a structure of interpretation of a deal (we could speed up the code by getting those values directly using the standard functions of MQL5, but it's less readable and may confuse you).
//+------------------------------------------------------------------+ //| structure of deal | //+------------------------------------------------------------------+ struct S_Stat_Deals { public: ulong DTicket; // ticket of deal ENUM_DEAL_TYPE deals_type; // type of deal ENUM_DEAL_ENTRY deals_entry; // direction of deal double deals_volume; // volume of deal double deals_price; // price of opening of deal datetime deals_date; // time of opening of deal S_Stat_Deals(){}; ~S_Stat_Deals(){}; };
This structure contains all main details about a deal, derived details are not included since we can calculate them if necessary. Since the developers have already implemented many methods of Bulachev's statistics in the strategy tester, we are only left to supplement it with custom methods. So let's implement such methods as the effectiveness of a trade in whole, and the effectiveness of opening and closing.
And to get these values we need to implement the interpretation of primary information such as open/close price, open/close time, minimum/maximum price during a trade. If we have such primary information we can get a lot of derivative information. Also I want to draw your attention to the structure of trade described below, it's the main structure, all the transformations of interpretation are based on it.
//+------------------------------------------------------------------+ //| structure of trade | //+------------------------------------------------------------------+ struct S_Stat_Trades { public: ulong OTicket; // ticket of opening deal ulong CTicket; // ticket of closing deal ENUM_DEAL_TYPE trade_type; // type of trade double trade_volume; // volume of trade double max_price_trade; // maximum price of trade double min_price_trade; // minimum price of trade double enter_price; // price of opening of trade datetime enter_date; // time of opening of trade double exit_price; // price of closing of trade/s22> datetime exit_date; // time of closing of trade double enter_efficiency;// effectiveness of entering double exit_efficiency; // effectiveness of exiting double trade_efficiency;// effectiveness of trade S_Stat_Trades(){}; ~S_Stat_Trades(){}; };
Now, as we've created two main structures, we can define the new class C_Pos, which transforms the interpretation. First of all, let's declare the pointers to the structures of interpretation of deals and trades. Since the information can be necessary in inherited functions, declare it as public; and since there can be a lot of deals and trades, use an array as a pointer to the structure instead of a variable. Thus, the information will be structured and available from any place.
Then we need to divide the history into separate positions and perform all the transformations inside a position as in a complete trading cycle. To do it, declare the variables for interpretation of the attributes of position(id of position, symbols of position, number of deals, number of trades).
//+------------------------------------------------------------------+ //| class for transforming deals into trades | //+------------------------------------------------------------------+ class C_Pos { public: S_Stat_Deals m_deals_stats[]; // structure of deals S_Stat_Trades m_trades_stats[]; // structure of trades long pos_id; // id of position string symbol; // symbol of position int count_deals; // number of deals int count_trades; // number of trades int trades_ends; // number of closed trades int DIGITS; // accuracy of minimum volume by the symbols of position C_Pos() { count_deals=0; count_trades=0; trades_ends=0; }; ~C_Pos(){}; void OnHistory(); // creation of history of position void OnHistoryTransform();// transformation of position history into the new system of interpretation void efficiency(); // calculation of effectiveness by Bulachev's method private: void open_pos(int c); void copy_pos(int x); void close_pos(int i,int c); double nd(double v){return(NormalizeDouble(v,DIGITS));};// normalization to minimum volume void DigitMinLots(); // accuracy of minimum volume double iHighest(string symbol_name,// symbol name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ); double iLowest(string symbol_name,// symbol name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ); };
The class has three public methods that process positions.
OnHistory() creates position history://+------------------------------------------------------------------+ //| filling the structures of history deals | //+------------------------------------------------------------------+ void C_Pos::OnHistory() { ArrayResize(m_deals_stats,count_deals); for(int i=0;i<count_deals;i++) { m_deals_stats[i].DTicket=HistoryDealGetTicket(i); m_deals_stats[i].deals_type=(ENUM_DEAL_TYPE)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_TYPE); // type of deal m_deals_stats[i].deals_entry=(ENUM_DEAL_ENTRY)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_ENTRY);// direction of deal m_deals_stats[i].deals_volume=HistoryDealGetDouble(m_deals_stats[i].DTicket,DEAL_VOLUME); // volume of deal m_deals_stats[i].deals_price=HistoryDealGetDouble(m_deals_stats[i].DTicket,DEAL_PRICE); // price of opening m_deals_stats[i].deals_date=(datetime)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_TIME); // time of opening } };
For each deal the method creates a copy of structure and fills it with the information about the deal. That's exactly what I meant when saying above that we can do without it, but it's more convenient with it (the ones who pursue the microseconds of shortening of time can replace the call of these structures with the line that stands to the right of the equality sign).
OnHistoryTransform() transforms position history into the new system of interpretation:
- I've described before how the information should be transformed, now let's consider an example of it. For the transformation we need a value to the accuracy of which we should calculate the volume of a deal (min. volume); DigitMinLots() deals with it; however, if a programmer is sure that this code won't be executed under any other conditions, then this parameter can be specified in the constructor and the function can be skipped.
- Then zeroize the count_trades and trades_ends counters. After that, reallocate the memory for the structure of interpretation of trades. Since we don't know for sure the exact number of trades, we should reallocate the memory according to the number of deals in position. If further it appear that there are more trades, then we will reallocate the memory for several times again; but at the same time most of trades will have enough memory, and the allocation of memory for the whole array saves our machine time significantly.
I recommend using this method everywhere when necessary; allocate the memory each time a new object of interpretation appears. If there is no precise information about the amount of memory required, then we need to allocate it to an approximate value. In any case, it is more economical than reallocating the whole array at each step.
Then comes the loop where all deals of a position are filtered using three filters: if the deal is in, in/out, out. Specific actions are implemented for each variant. The filters are sequential, nested. In other words, if one filter returns false, then only in this case we check the next filter. Such construction is economical with resources, because the unnecessary actions are cut. To make the code more readable, many actions are taken to the functions declared in the class as private ones. By the way, these functions were public during the development, but further I've realized that there is no need in them in the other parts of the code, thus they were redeclared as private ones. That is how easy one can manipulate the scope of data in OOP.
So, in the in filter the creation of a new trade is performed (the open_pos() function), that's why we increase the size of the array of pointers by one and copy the structure of deal to the corresponding fields of the structure of trade. In addition, since the structure of trade have two times more fields of price and time, then only fields of opening are filled when a trade is opened, so it is counted as uncompleted; you can understand it by the difference of count_trades and trades_ends. The matter is in the counters have zero values in the beginning. As soon as a trade appears, the count_trades counter is increased, and when the trade is closed, the trades_ends counter is increased. Thus, the difference between count_trades and trades_ends can tell you how many trades are not closed at any point of time.
The open_pos() function is pretty simple, it only opens trades and triggers the corresponding counter; other suchlike functions are not so simple. So, if a deal is not of the in type, then it can be either in/out or out. From two variants, first of all, check the one that is executed easier (this is not a fundamental issue, but I've build up the check in the order of ascending difficulty of execution).
The function that processes the in/out filter sums the open positions by all unclosed trades (I've already mentioned how to know which trades are not closed using the difference between count_trades and trades_ends). Thus, we calculate the total volume which is closed by the given deal (and the rest of volume will be reopened but with the type of the current deal). Here we need to note that the deal has the in/out direction, what means that its volume does exceed the total volume of the previously opened position. That's why it's logical to calculate the difference between the position and the in/out deal, to know the volume of the new trade to be reopened.
If a deal has the out direction, then everything is even more complicated. First of all, the last deal in a position always has the out direction, so here we should make an exception - if it's the last deal, close everything we have. Otherwise (if the deal is not the last one), two variants are possible. Since the deal is not in/out, but the out, then the variants are: the first variant is the volume is exactly the same as the opening one, i.e. the volume of opening deal is equal to the volume of the closing deal; the second variant is those volumes are not the same.
The first variant is processed by closing. The second variant is more complicated, two variants are possible again: when the volume is greater and when the volume is less than the opening one. When the volume is greater, close the next trade until the volume of closing becomes equal to or less than the volume of opening. If the volume is not enough to close the whole next trade (there is less volume), it means the partial closing. Here we need to close the trade with the new volume (the one that is left after previous operations), but before it, make a copy of trade with the missing volume. And of course, don't forget about the counters.
In trading, there can be a situation when there's already a queue of later trades at partial closing after reopening of a trade. To avoid confusion, all of them should be shifted by one, to keep the chronology of closing.
//+------------------------------------------------------------------+ //| transformation of deals into trades (engine classes) | //+------------------------------------------------------------------+ void C_Pos::OnHistoryTransform() { DigitMinLots();// fill the DIGITS value count_trades=0;trades_ends=0; ArrayResize(m_trades_stats,count_trades,count_deals); for(int c=0;c<count_deals;c++) { if(m_deals_stats[c].deals_entry==DEAL_ENTRY_IN) { open_pos(c); } else// else in { double POS=0; for(int i=trades_ends;i<count_trades;i++)POS+=m_trades_stats[i].trade_volume; if(m_deals_stats[c].deals_entry==DEAL_ENTRY_INOUT) { for(int i=trades_ends;i<count_trades;i++)close_pos(i,c); trades_ends=count_trades; open_pos(c); m_trades_stats[count_trades-1].trade_volume=m_deals_stats[c].deals_volume-POS; } else// else in/out { if(m_deals_stats[c].deals_entry==DEAL_ENTRY_OUT) { if(c==count_deals-1)// if it's the last deal { for(int i=trades_ends;i<count_trades;i++)close_pos(i,c); trades_ends=count_trades-1; } else// if it's not the last deal { double out_vol=nd(m_deals_stats[c].deals_volume); while(nd(out_vol)>0) { if(nd(out_vol)>=nd(m_trades_stats[trades_ends].trade_volume)) { close_pos(trades_ends,c); out_vol-=nd(m_trades_stats[trades_ends].trade_volume); trades_ends++; } else// if the remainder of closed position is less than the next trade { // move all trades forward by one count_trades++; ArrayResize(m_trades_stats,count_trades); for(int x=count_trades-1;x>trades_ends;x--)copy_pos(x); // open a copy with the volume equal to difference of the current position and the remainder m_trades_stats[trades_ends+1].trade_volume=nd(m_trades_stats[trades_ends].trade_volume-out_vol); // close the current trade with new volume, which is equal to remainder close_pos(trades_ends,c); m_trades_stats[trades_ends].trade_volume=nd(out_vol); out_vol=0; trades_ends++; } }// while(out_vol>0) }// if it's not the last deal }// if out }// else in/out }// else in } };
Calculation of Effectiveness
Once the system of interpretation is transformed, we can evaluate the effectiveness of trades by Bulachev's methodology. Functions that are necessary for such evaluation are in the efficiency() method, filling of structure of trade with the calculated data is performed there as well. The effectiveness of entering and exiting is measured from 0 to 1, and for the entire trade it's measured from -1 to 1.
//+------------------------------------------------------------------+ //| calculation of effectiveness | //+------------------------------------------------------------------+ void C_Pos::efficiency() { for(int i=0;i<count_trades;i++) { m_trades_stats[i].max_price_trade=iHighest(symbol,PERIOD_M1,m_trades_stats[i].enter_date,m_trades_stats[i].exit_date); // maximal price of trade m_trades_stats[i].min_price_trade=iLowest(symbol,PERIOD_M1,m_trades_stats[i].enter_date,m_trades_stats[i].exit_date); // minimal price of trade double minimax=0; minimax=m_trades_stats[i].max_price_trade-m_trades_stats[i].min_price_trade;// difference between maximum and minimum if(minimax!=0)minimax=1.0/minimax; if(m_trades_stats[i].trade_type==DEAL_TYPE_BUY) { //Effectiveness of entering a position m_trades_stats[i].enter_efficiency=(m_trades_stats[i].max_price_trade-m_trades_stats[i].enter_price)*minimax; //Effectiveness of exiting from a position m_trades_stats[i].exit_efficiency=(m_trades_stats[i].exit_price-m_trades_stats[i].min_price_trade)*minimax; //Effectiveness of trade m_trades_stats[i].trade_efficiency=(m_trades_stats[i].exit_price-m_trades_stats[i].enter_price)*minimax; } else { if(m_trades_stats[i].trade_type==DEAL_TYPE_SELL) { //Effectiveness of entering a position m_trades_stats[i].enter_efficiency=(m_trades_stats[i].enter_price-m_trades_stats[i].min_price_trade)*minimax; //Effectiveness of exiting from a position m_trades_stats[i].exit_efficiency=(m_trades_stats[i].max_price_trade-m_trades_stats[i].exit_price)*minimax; //Effectiveness of trade m_trades_stats[i].trade_efficiency=(m_trades_stats[i].enter_price-m_trades_stats[i].exit_price)*minimax; } } } }
The method uses two private methods iHighest() and iLowest(), they are similar and the only difference is the requested data and the search function fmin or fmax.
//+------------------------------------------------------------------+ //| searching maximum within the period start_time --> stop_time | //+------------------------------------------------------------------+ double C_Pos::iHighest(string symbol_name,// symbols name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ) { double buf[]; datetime start_t=(start_time/60)*60;// normalization of time of opening datetime stop_t=(stop_time/60+1)*60;// normaliztion of time of closing int period=CopyHigh(symbol_name,timeframe,start_t,stop_t,buf); double res=buf[0]; for(int i=1;i<period;i++) res=fmax(res,buf[i]); return(res); }
The method searches the maximum within the period between two specified dates. The dates are passed to the function as the start_time and stop_time parameters. Since the dates of trades are passed to the function and a trade request may come even at the middle of 1 minute bar, the normalization of date to the closest value of bar is performed inside the function. The same is done in the iLowest() function. With the developed method efficiency() we have the whole functionality for working with a position; but there is no treatment of the position itself yet. Let's overtake this by determining a new class, to which all the previous methods will be available; in other words, declare it as a derivative of C_Pos.
Derivative Class (engine classes)
class C_PosStat:public C_Pos
To consider the statistical information, create a structure that will be given to the new class.
//+------------------------------------------------------------------+ //| structure of effectiveness | //+------------------------------------------------------------------+ struct S_efficiency { double enter_efficiency; // effectiveness of entering double exit_efficiency; // effectiveness of exiting double trade_efficiency; // effectiveness of trade S_efficiency() { enter_efficiency=0; exit_efficiency=0; trade_efficiency=0; }; ~S_efficiency(){}; };
And the body of the class itself:
//+------------------------------------------------------------------+ //| class of statistics of trade in whole | //+------------------------------------------------------------------+ class C_PosStat:public C_Pos { public: int PosTotal; // number of positions in history C_Pos pos[]; // array of pointers to positions int All_count_trades; // total number of trades in history S_efficiency trade[]; // array of pointers to the structure of effectiveness of entering, exiting and trades S_efficiency avg; // pointer to the structure of average value of effectiveness of entering, exiting and trades S_efficiency stdev; // pointer to the structure of standard deviation from // average value of effectiveness of entering, exiting and trades C_PosStat(){PosTotal=0;}; ~C_PosStat(){}; void OnPosStat(); // engine classes void OnTradesStat(); // gathering information about trades into the common array // functions of writing information to a file void WriteFileDeals(string folder="deals"); void WriteFileTrades(string folder="trades"); void WriteFileTrades_all(string folder="trades_all"); void WriteFileDealsHTML(string folder="deals"); void WriteFileDealsHTML2(string folder="deals"); void WriteFileTradesHTML(string folder="trades"); void WriteFileTradesHTML2(string folder="trades"); string enum_translit(ENUM_DEAL_ENTRY x,bool latin=true);// transformation of enumeration into string string enum_translit(ENUM_DEAL_TYPE x,bool latin=true); // transformation of enumeration into string (overloaded) private: S_efficiency AVG(int count); // arithmetical mean S_efficiency STDEV(const S_efficiency &mo,int count); // standard deviation S_efficiency add(const S_efficiency &a,const S_efficiency &b); //add S_efficiency take(const S_efficiency &a,const S_efficiency &b); //subtract S_efficiency multiply(const S_efficiency &a,const S_efficiency &b); //multiply S_efficiency divided(const S_efficiency &a,double b); //divide S_efficiency square_root(const S_efficiency &a); //square root string Head_style(string title); };
I suggest analyzing this class in reverse direction, from the end to the beginning. Everything ends with writing a table of deals and trades into files. A row of functions is written for this purpose (you can understand the aim of each other from the name). The functions make a csv report on deals and trades as well as html reports of two types (they differ only visually, but have the same content).
void WriteFileDeals(); // writing csv report on deals void WriteFileTrades(); // writing csv report on trade void WriteFileTrades_all(); // writing summary csv report of fitness functions void WriteFileDealsHTML2(); // writing html report on deals, 1 variant void WriteFileTradesHTML2();// writing html report on trades, 2 variant
The enum_translit() function are intended for transforming the values of enumerations into string type for writing them to log file. The private section contains several function of the S_efficiency structure. All the functions make up the disadvantages of the language, notably the arithmetic operations with structures. Since the opinions on implementation of these methods vary, they can be realized in different ways. I've realized them as methods of arithmetic operations with the fields of structures. Someone may say that it's better to process each field of structure using an individual method. Summing up, I would say that there are as many opinions as the programmers. I hope that in future we'll have a possibility to perform such operations using in-built methods.
The AVG() method calculates arithmetical mean value of passed array, but it doesn't show the whole picture of distribution, that's why it is supplied with another method that calculates the standard deviation STDEV(). The OnTradesStat() function gets the values of effectiveness (previously calculated in OnPosStat())and processes them with statistical methods. And finally, the main function of the class - OnPosStat().
This function should be considered in details. It consists of two parts, so it can be easily divided. The first part searches for all positions and processes their id with saving it in the temporary array id_pos. Stepwise: select the entire available history, calculate the number of deals, run the cycle of processing deals. The cycle: if the type of deal is balans, skip it (there is no need to interpret the starting deal), otherwise - save id of position into the variable and perform the search. If the same id already exists in the base (the id_pos array), go for the next deal, otherwise write id to the base. In such a manner, after processing all the deals we have the array filled with all existing id's of positions and the number of positions.
long id_pos[];// auxiliary array for creating the history of positions if(HistorySelect(0,TimeCurrent())) { int HTD=HistoryDealsTotal(); ArrayResize(id_pos,PosTotal,HTD); for(int i=0;i<HTD;i++) { ulong DTicket=(ulong)HistoryDealGetTicket(i); if((ENUM_DEAL_TYPE)HistoryDealGetInteger(DTicket,DEAL_TYPE)==DEAL_TYPE_BALANCE) continue;// if it's a balance deal, skip it long id=HistoryDealGetInteger(DTicket,DEAL_POSITION_ID); bool present=false; // initial state, there's no such position for(int j=0;j<PosTotal;j++) { if(id==id_pos[j]){ present=true; break; } }// if such position already exists break if(!present)// write id as a new position appears { PosTotal++; ArrayResize(id_pos,PosTotal); id_pos[PosTotal-1]=id; } } } ArrayResize(pos,PosTotal);
In the second part, we realize all methods described in the base class C_Pos previously. It consists from a cycle that goes over positions and runs the corresponding methods of processing the positions. Description of the method is given in the code below.
for(int p=0;p<PosTotal;p++) { if(HistorySelectByPosition(id_pos[p]))// select position { pos[p].pos_id=id_pos[p]; // assigned id of position to the corresponding field of the class C_Pos pos[p].count_deals=HistoryDealsTotal();// assign the number of deal in position to the field of the class C_Pos pos[p].symbol=HistoryDealGetString(HistoryDealGetTicket(0),DEAL_SYMBOL);// the same actions with symbol pos[p].OnHistory(); // start filling the structure sd with the history of position pos[p].OnHistoryTransform(); // transformation of interpretation, filling the structure st. pos[p].efficiency(); // calculation of the effectiveness of obtained data All_count_trades+=pos[p].count_trades;// save the number of trades for displaying the total number } }
Calling Methods of the Class
So, we have considered the whole class. It's left to give an example of calling. To keep the possibilities of constructing, I didn't declare the call explicitly in one function. In addition you can enhance the class for your needs, implement new methods of statistical processing of data. Here is an example of calling the method of the class from a script:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ #include <Bulaschev_Statistic.mqh> void OnStart() { C_PosStat start; start.OnPosStat(); start.OnTradesStat(); start.WriteFileDeals(); start.WriteFileTrades(); start.WriteFileTrades_all(); start.WriteFileDealsHTML2(); start.WriteFileTradesHTML2(); Print("cko tr ef=" ,start.stdev.trade_efficiency); Print("mo tr ef=" ,start.avg.trade_efficiency); Print("cko out ef=",start.stdev.exit_efficiency); Print("mo out ef=",start.avg.exit_efficiency); Print("cko in ef=" ,start.stdev.enter_efficiency); Print("mo in ef=" ,start.avg.enter_efficiency); }
The script creates 5 report files according to the amount of functions that write data into the file in the Files\OnHistory directory. The following main functions are present here - OnPosStat() and OnTradesStat(),they are used for calling all necessary methods. The script ends with printing the obtained value of effectiveness of trading in whole. Each of those values can be used for genetic optimization.
Since there is no need to write each report to a file during the optimization, the call of the class in an Expert Advisor looks a bit different. Firstly, as opposed to a script, an Expert Advisor can be run in the tester (that's what we prepare it for). Working in the strategy tester has its peculiarities. When optimizing, we have the access to the OnTester() function, at that its execution is performed before the execution of the OnDeinit() function. Thus, the call of main methods of transformation can be separated. For the convenience of modification of the fitness function from the parameters of an Expert Advisor, I've declared an enumeration globally, not as a part of the class. At that the enumeration is at the same sheet with the methods of the class C_PosStat.
//+------------------------------------------------------------------+ //| enumeration of fitness functions | //+------------------------------------------------------------------+ enum Enum_Efficiency { avg_enter_eff, stdev_enter_eff, avg_exit_eff, stdev_exit_eff, avg_trade_eff, stdev_trade_eff };
This is what should be added to the heading of the Expert Advisor.
#include <Bulaschev_Statistic.mqh> input Enum_Efficiency result=0;// Fitness function
Now we can just describe passing of the necessary parameter using the switch operator.
//+------------------------------------------------------------------+ //| Expert optimization function | //+------------------------------------------------------------------+ double OnTester() { start.OnPosStat(); start.OnTradesStat(); double res; switch(result) { case 0: res=start.avg.enter_efficiency; break; case 1: res=-start.stdev.enter_efficiency; break; case 2: res=start.avg.exit_efficiency; break; case 3: res=-start.stdev.exit_efficiency; break; case 4: res=start.avg.trade_efficiency; break; case 5: res=-start.stdev.trade_efficiency; break; default : res=0; break; } return(res); }
I want to draw your attention to the fact that the OnTester() function is used for maximization of the custom function. If you need to find the minimum of the custom function, then it's better to reverse the function itself multiplying it by -1. Like in the example with the standard deviation, everybody understands that the smaller the stdev is, the smaller is the difference between the effectiveness of trades, thus the stability of trades is higher. That's why stdev should be minimized. Now, as we've dealt with calling of the class method, let's consider writing the reports to a file.
Previously, I've mentioned the class methods that create the report. Now we're going to see where and when they should be called. The reports should be created only when the Expert Advisor is launched for a single run. Otherwise, the Expert Advisor will create the files in the optimization mode; i.e. instead of one file it will create a lot of files (if different file names are passed each time) or one, but the last one with the same name for all runs, what is absolutely meaningless, since it wastes the resource for the information that is further erased.
Anyway, you shouldn't create report files during optimization. If you get a lot of files with different names, probably you won't open most of them. The second variant has a waste of resources for getting the information that is deleted right away.
That's why the best variant is to make filter (start the report only in the Optimization[disabled] mode). Thus, the HDD won't be littered with reports that are never viewed. Moreover, the optimization speed increases (it's not a secret that the slowest operations are the file operations); in addition, the possibility to quickly get a report with the necessary parameters is kept. Actually, it doesn't matter where to place the filter, in the OnTester or in the OnDeinit function. The important this is the class methods, which create the report, should be called after the main methods that perform transformation. I've placed the filter to OnDeinit() not to overload the code:
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if(!(bool)MQL5InfoInteger(MQL5_OPTIMIZATION)) { start.WriteFileDeals(); // writing csv report on deals start.WriteFileTrades(); // writing csv report on trades start.WriteFileTrades_all(); // writing summary csv report on fitness functions start.WriteFileDealsHTML2(); // writing html report on deals start.WriteFileTradesHTML2();// writing html report on trades } } //+------------------------------------------------------------------+
The sequence of calling the methods is not important. Everything that is necessary for making the reports is prepared in the OnPosStat and OnTradesStat methods. Also, it doesn't matter if you call all the methods of writing reports or just some of them; operation of each of them is individual; it's an interpretation of information that is already stored in the class.
Check in the Strategy Tester
The result of a single run in the strategy tester is given below:
Trades Report Moving Averages Statistic | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| # | Ticket | type | volume | Open | Close | Price | Efficiency | ||||||
| open | close | price | time | price | time | max | min | enter | exit | trade | |||
| pos[0] | id 2 | EURUSD | |||||||||||
| 0 | 2 | 3 | buy | 0.1 | 1.37203 | 2010.03.15 13:00:00 | 1.37169 | 2010.03.15 14:00:00 | 1.37236 | 1.37063 | 0.19075 | 0.61272 | -0.19653 |
| pos[1] | id 4 | EURUSD | |||||||||||
| 1 | 4 | 5 | sell | 0.1 | 1.35188 | 2010.03.23 08:00:00 | 1.35243 | 2010.03.23 10:00:00 | 1.35292 | 1.35025 | 0.61049 | 0.18352 | -0.20599 |
| pos[2] | id 6 | EURUSD | |||||||||||
| 2 | 6 | 7 | sell | 0.1 | 1.35050 | 2010.03.23 12:00:00 | 1.35343 | 2010.03.23 16:00:00 | 1.35600 | 1.34755 | 0.34911 | 0.30414 | -0.34675 |
| pos[3] | id 8 | EURUSD | |||||||||||
| 3 | 8 | 9 | sell | 0.1 | 1.35167 | 2010.03.23 18:00:00 | 1.33343 | 2010.03.26 05:00:00 | 1.35240 | 1.32671 | 0.97158 | 0.73842 | 0.71000 |
| pos[4] | id 10 | EURUSD | |||||||||||
| 4 | 10 | 11 | sell | 0.1 | 1.34436 | 2010.03.30 16:00:00 | 1.33616 | 2010.04.08 23:00:00 | 1.35904 | 1.32821 | 0.52384 | 0.74213 | 0.26597 |
| pos[5] | id 12 | EURUSD | |||||||||||
| 5 | 12 | 13 | buy | 0.1 | 1.35881 | 2010.04.13 08:00:00 | 1.35936 | 2010.04.15 10:00:00 | 1.36780 | 1.35463 | 0.68261 | 0.35915 | 0.04176 |
| pos[6] | id 14 | EURUSD | |||||||||||
| 6 | 14 | 15 | sell | 0.1 | 1.34735 | 2010.04.20 04:00:00 | 1.34807 | 2010.04.20 10:00:00 | 1.34890 | 1.34492 | 0.61055 | 0.20854 | -0.18090 |
| pos[7] | id 16 | EURUSD | |||||||||||
| 7 | 16 | 17 | sell | 0.1 | 1.34432 | 2010.04.20 18:00:00 | 1.33619 | 2010.04.23 17:00:00 | 1.34491 | 1.32016 | 0.97616 | 0.35232 | 0.32848 |
| pos[8] | id 18 | EURUSD | |||||||||||
| 8 | 18 | 19 | sell | 0.1 | 1.33472 | 2010.04.27 10:00:00 | 1.32174 | 2010.04.29 05:00:00 | 1.33677 | 1.31141 | 0.91916 | 0.59267 | 0.51183 |
| pos[9] | id 20 | EURUSD | |||||||||||
| 9 | 20 | 21 | sell | 0.1 | 1.32237 | 2010.05.03 04:00:00 | 1.27336 | 2010.05.07 20:00:00 | 1.32525 | 1.25270 | 0.96030 | 0.71523 | 0.67553 |
Effectiveness Report | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fitness Func | Average Value | Standard Deviation | |||||||||||
| Enter | 0.68 | 0.26 | |||||||||||
| Exit | 0.48 | 0.21 | |||||||||||
| Trades | 0.16 | 0.37 | |||||||||||
And the balance graph is:
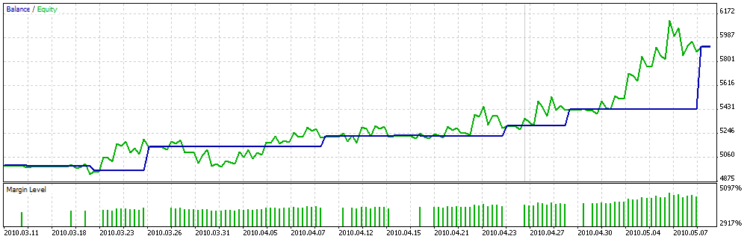
You can clearly see on the chart that the custom function of optimization doesn't try to choose the parameters with the greater amount of deals, but the deals with long duration, at that the deals have nearly the same profit, i.e. the dispersion is not high.
Since the code of Moving Averages doesn't contain the features of increasing volume of position or partial closing of it, the result of transformation doesn't seem to be close to the one described above. Below, you can find another result of launching the script at the account opened especially for testing codes:
| pos[286] | id 1019514 | EURUSD | |||||||||||
| 944 | 1092288 | 1092289 | buy | 0.1 | 1.26733 | 2010.07.08 21:14:49 | 1.26719 | 2010.07.08 21:14:57 | 1.26752 | 1.26703 | 0.38776 | 0.32653 | -0.28571 |
| pos[287] | id 1019544 | EURUSD | |||||||||||
| 945 | 1092317 | 1092322 | sell | 0.2 | 1.26761 | 2010.07.08 21:21:14 | 1.26767 | 2010.07.08 21:22:29 | 1.26781 | 1.26749 | 0.37500 | 0.43750 | -0.18750 |
| 946 | 1092317 | 1092330 | sell | 0.2 | 1.26761 | 2010.07.08 21:21:14 | 1.26792 | 2010.07.08 21:24:05 | 1.26782 | 1.26749 | 0.36364 | -0.30303 | -0.93939 |
| 947 | 1092319 | 1092330 | sell | 0.3 | 1.26761 | 2010.07.08 21:21:37 | 1.26792 | 2010.07.08 21:24:05 | 1.26782 | 1.26749 | 0.36364 | -0.30303 | -0.93939 |
| pos[288] | id 1019623 | EURUSD | |||||||||||
| 948 | 1092394 | 1092406 | buy | 0.1 | 1.26832 | 2010.07.08 21:36:43 | 1.26843 | 2010.07.08 21:37:38 | 1.26882 | 1.26813 | 0.72464 | 0.43478 | 0.15942 |
| pos[289] | id 1019641 | EURUSD | |||||||||||
| 949 | 1092413 | 1092417 | buy | 0.1 | 1.26847 | 2010.07.08 21:38:19 | 1.26852 | 2010.07.08 21:38:51 | 1.26910 | 1.26829 | 0.77778 | 0.28395 | 0.06173 |
| 950 | 1092417 | 1092433 | sell | 0.1 | 1.26852 | 2010.07.08 21:38:51 | 1.26922 | 2010.07.08 21:39:58 | 1.26916 | 1.26829 | 0.26437 | -0.06897 | -0.80460 |
| pos[290] | id 1150923 | EURUSD | |||||||||||
| 951 | 1226007 | 1226046 | buy | 0.2 | 1.31653 | 2010.08.05 16:06:20 | 1.31682 | 2010.08.05 16:10:53 | 1.31706 | 1.31611 | 0.55789 | 0.74737 | 0.30526 |
| 952 | 1226024 | 1226046 | buy | 0.3 | 1.31632 | 2010.08.05 16:08:31 | 1.31682 | 2010.08.05 16:10:53 | 1.31706 | 1.31611 | 0.77895 | 0.74737 | 0.52632 |
| 953 | 1226046 | 1226066 | sell | 0.1 | 1.31682 | 2010.08.05 16:10:53 | 1.31756 | 2010.08.05 16:12:49 | 1.31750 | 1.31647 | 0.33981 | -0.05825 | -0.71845 |
| 954 | 1226046 | 1226078 | sell | 0.2 | 1.31682 | 2010.08.05 16:10:53 | 1.31744 | 2010.08.05 16:15:16 | 1.31750 | 1.31647 | 0.33981 | 0.05825 | -0.60194 |
| pos[291] | id 1155527 | EURUSD | |||||||||||
| 955 | 1230640 | 1232744 | sell | 0.1 | 1.31671 | 2010.08.06 13:52:11 | 1.32923 | 2010.08.06 17:39:50 | 1.33327 | 1.31648 | 0.01370 | 0.24062 | -0.74568 |
| 956 | 1231369 | 1232744 | sell | 0.1 | 1.32584 | 2010.08.06 14:54:53 | 1.32923 | 2010.08.06 17:39:50 | 1.33327 | 1.32518 | 0.08158 | 0.49938 | -0.41904 |
| 957 | 1231455 | 1232744 | sell | 0.1 | 1.32732 | 2010.08.06 14:58:13 | 1.32923 | 2010.08.06 17:39:50 | 1.33327 | 1.32539 | 0.24492 | 0.51269 | -0.24239 |
| 958 | 1231476 | 1232744 | sell | 0.1 | 1.32685 | 2010.08.06 14:59:47 | 1.32923 | 2010.08.06 17:39:50 | 1.33327 | 1.32539 | 0.18528 | 0.51269 | -0.30203 |
| 959 | 1231484 | 1232744 | sell | 0.2 | 1.32686 | 2010.08.06 15:00:20 | 1.32923 | 2010.08.06 17:39:50 | 1.33327 | 1.32539 | 0.18655 | 0.51269 | -0.30076 |
| 960 | 1231926 | 1232744 | sell | 0.4 | 1.33009 | 2010.08.06 15:57:32 | 1.32923 | 2010.08.06 17:39:50 | 1.33327 | 1.32806 | 0.38964 | 0.77543 | 0.16507 |
| 961 | 1232591 | 1232748 | sell | 0.4 | 1.33123 | 2010.08.06 17:11:29 | 1.32850 | 2010.08.06 17:40:40 | 1.33129 | 1.32806 | 0.98142 | 0.86378 | 0.84520 |
| 962 | 1232591 | 1232754 | sell | 0.4 | 1.33123 | 2010.08.06 17:11:29 | 1.32829 | 2010.08.06 17:42:14 | 1.33129 | 1.32796 | 0.98198 | 0.90090 | 0.88288 |
| 963 | 1232591 | 1232757 | sell | 0.2 | 1.33123 | 2010.08.06 17:11:29 | 1.32839 | 2010.08.06 17:43:15 | 1.33129 | 1.32796 | 0.98198 | 0.87087 | 0.85285 |
| pos[292] | id 1167490 | EURUSD | |||||||||||
| 964 | 1242941 | 1243332 | sell | 0.1 | 1.31001 | 2010.08.10 15:54:51 | 1.30867 | 2010.08.10 17:17:51 | 1.31037 | 1.30742 | 0.87797 | 0.57627 | 0.45424 |
| 965 | 1242944 | 1243333 | sell | 0.1 | 1.30988 | 2010.08.10 15:55:03 | 1.30867 | 2010.08.10 17:17:55 | 1.31037 | 1.30742 | 0.83390 | 0.57627 | 0.41017 |
| pos[293] | id 1291817 | EURUSD | |||||||||||
| 966 | 1367532 | 1367788 | sell | 0.4 | 1.28904 | 2010.09.06 00:24:01 | 1.28768 | 2010.09.06 02:53:21 | 1.28965 | 1.28710 | 0.76078 | 0.77255 | 0.53333 |
That's how the transformed information looks like; to give the readers a possibility to consider everything deliberately (and cognition comes through comparison), I save the original history of deals to a separate file; that's the history which is now missed by many traders, who is used to seeing it in the [Results] section of MetaTrader 4.
Conclusion
In conclusion, I want to suggest developers to add a possibility to optimize Expert Advisors not only by a custom parameter, but to make it in combination with the standard ones as it's done with the other functions of optimization. Summarizing this article, I can say that it contains only the basics, the initial potential; and I hope that readers will be able to enhance the class according to their own needs. Good luck!
Translated from Russian by MetaQuotes Ltd.
Original article: https://www.mql5.com/ru/articles/137
 Interview with Berron Parker (ATC 2010)
Interview with Berron Parker (ATC 2010)
 Analyzing Candlestick Patterns
Analyzing Candlestick Patterns
 Technical Analysis: What Do We Analyze?
Technical Analysis: What Do We Analyze?
 Controlling the Slope of Balance Curve During Work of an Expert Advisor
Controlling the Slope of Balance Curve During Work of an Expert Advisor
- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use
Hi,
I've been trying to use your code for months. The problem is it only write the header for the html . And for excel it only came up with "yb" on the first cell. I have repeated your article many times and I couldn't fix this problem. I find your article very useful. Can you help me with this issue. I'm quite a newbie here. Your help would be very meaningful to me. Thank you so much.
Where can I open the html file? I did not see how it is generated