
Redes neurais de maneira fácil (Parte 67): Aprendendo com experiências passadas para resolver novos problemas

Introdução
O aprendizado por reforço é baseado na maximização da recompensa obtida do ambiente durante a interação com ele. É claro que o processo de aprendizado requer constante interação com o ambiente. Mas as situações podem variar. Ao resolver algumas tarefas podem surgir certas restrições durante essa interação com o ambiente. Nessas situações, os algoritmos de aprendizado por reforço off-line vêm em nosso auxílio. Eles permitem treinar modelos em um arquivo limitado de trajetórias coletadas durante interações prévias com o ambiente quando ele estava acessível.
Naturalmente, o aprendizado por reforço off-line tem suas desvantagens. Especificamente, o problema de estudar o ambiente se torna ainda mais complicado devido à limitação da amostra de treinamento, que simplesmente não pode abranger toda a complexidade do ambiente. Isso é especialmente problemático em ambientes estocásticos complexos. Um dos métodos de resolver esse problema (ExORL) foi introduzido no artigo anterior.
No entanto, às vezes as restrições na interação com o ambiente podem ser bastante críticas. O processo de pesquisa do ambiente pode ser acompanhado por recompensas positivas e negativas. As recompensas negativas podem ser altamente indesejáveis e estar associadas a perdas financeiras ou outros tipos de perdas que você não pode aceitar. Mas os problemas raramente surgem do nada. Na maioria das vezes, otimizamos um processo existente. E na nossa "era da tecnologia da informação", quase sempre é possível encontrar experiências de interação com o ambiente estudado durante a resolução de problemas semelhantes ao que enfrentamos. É possível usar dados de interações reais com o ambiente, que podem cobrir de alguma forma o espaço necessário de ações e estados. Os experimentos com o uso dessa experiência para resolver novos problemas ao controlar robôs reais são discutidos no artigo "Real World Offline Reinforcement Learning with Realistic Data Source". Os autores do artigo propõem um novo framework de treinamento de modelos chamado Real-ORL.
1. Framework Real-ORL
O aprendizado por reforço off-line (ORL) modela o ambiente como um processo de decisão de Markov. Isso pressupõe acesso a um conjunto de dados previamente gerado em forma de trajetórias, coletadas usando uma política comportamental ou uma mistura delas. O objetivo do ORL é usar o conjunto de dados off-line para treinar uma política quase ótima π. Geralmente, não é possível treinar a política ótima π* devido à insuficiência de pesquisa e à limitação do conjunto de dados de treinamento. Nesse caso, buscamos a melhor política que possa ser treinada com base no conjunto de dados disponível.
A maioria dos algoritmos de aprendizado por reforço off-line inclui alguma forma de regulamentação ou conservadorismo, que podem assumir as seguintes formas, entre outras:
- Regulamentação do gradiente da política;
- Programação dinâmica aproximada;
- Treinamento usando o modelo do ambiente.
Os autores do framework Real-ORL não propõem novos algoritmos de treinamento de modelos. Eles exploram uma série de algoritmos ORL anteriormente representativos e avaliam sua desempenho com um robô físico em cenários de uso realistas. Os autores do framework ressaltam que os algoritmos de aprendizado analisados no artigo são, em sua maioria, orientados para simulação, usando conjuntos de dados ideais, independentes e simultâneos. No entanto, essa abordagem não é adequada para o mundo real estocástico, onde as ações são acompanhadas por atrasos operacionais. Isso geralmente limita o uso de políticas treinadas em robôs físicos. Afinal, não está claro se os resultados de benchmarks simulados ou avaliações limitadas de equipamentos podem ser generalizados para processos no mundo real. O trabalho "Real World Offline Reinforcement Learning with Realistic Data Source" visa preencher essa lacuna. Ele apresenta estudos empíricos de vários algoritmos de aprendizado por reforço off-line em tarefas do mundo real, com ênfase na generalização fora do conjunto de treinamento.
Por outro lado, o aprendizado por imitação representa uma abordagem alternativa ao treinamento de políticas de controle para robótica. Ao contrário do RL, que treina políticas otimizando recompensas, o aprendizado por imitação foca na repetição de demonstrações de especialistas. E na maioria dos casos, explora abordagens de aprendizado supervisionado, excluindo a função de recompensa do processo de treinamento. Também é interessante a combinação de aprendizado por reforço e aprendizado por imitação.
Em seu trabalho, os autores do framework Real-ORL usam um conjunto de dados off-line composto por trajetórias de uma política heurística manual. As trajetórias foram coletadas sob supervisão de um especialista e representam um conjunto de dados de alta qualidade. Os autores do método consideram o aprendizado por imitação off-line (clonagem de comportamento, em particular), como um algoritmo base em seu estudo empírico.
Para a máxima objetividade na avaliação dos métodos de treinamento, o artigo considera quatro tarefas clássicas de manipulação, que representam um conjunto de desafios comuns de manipulação. Cada tarefa é modelada como um MDP com uma função de recompensa única. E cada um dos métodos de treinamento analisados é aplicado para resolver todas as 4 tarefas, colocando todos os algoritmos em condições absolutamente iguais.
Como mencionado anteriormente, a coleta de dados de treinamento foi realizada usando uma política desenvolvida sob supervisão de um especialista. Principalmente, foram coletadas trajetórias bem-sucedidas em todas as quatro tarefas. Os autores do framework Real-ORL acreditam que coletar trajetórias subótimas ou distorcer trajetórias de especialistas com diferentes tipos de ruído não é aceitável para robótica, pois comportamentos distorcidos ou aleatórios são inseguros e prejudiciais para a condição técnica dos equipamentos. Ao mesmo tempo, o uso de dados coletados de várias tarefas oferece um ambiente mais realista para a aplicação do aprendizado por reforço off-line em robôs reais por três razões:
- Coletar dados "aleatórios/pesquisadores" em um robô real autonomamente exigiria extensivas restrições de segurança, supervisão e acompanhamento de especialistas.
- Envolver especialistas para registrar esses dados aleatórios em grandes quantidades faz menos sentido do que usá-los para coletar trajetórias significativas de uma tarefa real.
- Desenvolver estratégias específicas para a tarefa e testar a capacidade de stress do ORL com base em um conjunto de dados robusto é mais viável do que usar um conjunto de dados comprometido.
Para evitar viés a favor da tarefa (ou algoritmo), os autores do Real-ORL pré-congelaram o conjunto de dados coletado.
Para o treinamento das políticas dos agentes em todas as tarefas, os autores do Real-ORL dividem cada tarefa em etapas mais simples, marcadas com sub-objetivos. O agente executa pequenos passos em direção aos sub-objetivos até que alguns critérios específicos da tarefa sejam cumpridos. As políticas treinadas dessa maneira não alcançaram os resultados teoricamente máximos possíveis devido ao ruído dos controladores e ao erro de rastreamento. No entanto, eles completam a tarefa com alta sucesso e têm desempenho comparável ao de demonstrações humanas.
Os autores do Real-ORL realizaram experimentos usando mais de 3000 trajetórias de treinamento, mais de 3500 trajetórias de avaliação e mais de 270 horas-homem de trabalho. E como resultado de seus estudos, chegaram às seguintes conclusões:
- Para tarefas fora do domínio de aplicação, os algoritmos de aprendizado por reforço poderiam ser generalizados para áreas de tarefas com falta de dados e para tarefas dinâmicas.
- A mudança no desempenho do ORL após o uso de dados heterogêneos tende a variar dependendo dos agentes, do design da tarefa e das características dos dados.
- Certas trajetórias heterogêneas, independentes da tarefa, podem fornecer suporte de dados sobreposto e promover um melhor treinamento, permitindo que os agentes do ORL melhorem seu desempenho.
- O melhor agente para cada tarefa é ou um algoritmo ORL ou um empate entre ORL e BC (clonagem de comportamento). As avaliações apresentadas no artigo indicam que, mesmo em modo de dados fora do domínio de aplicação, mais realista para o mundo real, o aprendizado por reforço off-line é uma abordagem eficaz.
Abaixo está uma representação autoral do framework Real-ORL.
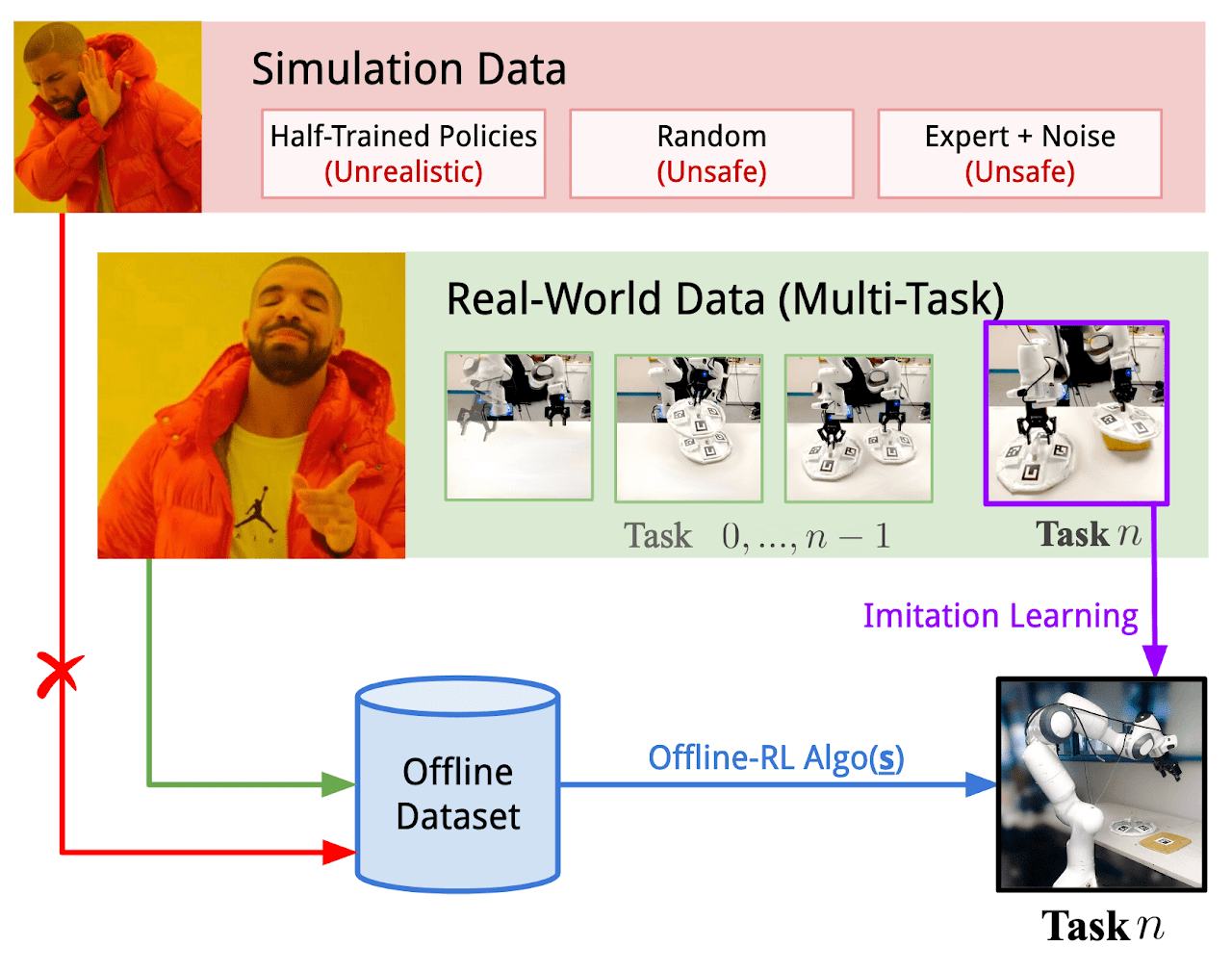
2. Implementação com MQL5
No artigo "Real World Offline Reinforcement Learning with Realistic Data Source", a eficácia dos métodos de aprendizado por reforço off-line para resolver tarefas reais é empiricamente comprovada. O uso de dados sobre a resolução de tarefas semelhantes ou parecidas para construir a política do Agente chamou minha atenção. A única condição para os dados é o ambiente ao qual eles pertencem. Ou seja, eles devem ter sido coletados como resultado da interação com o ambiente que estamos analisando.
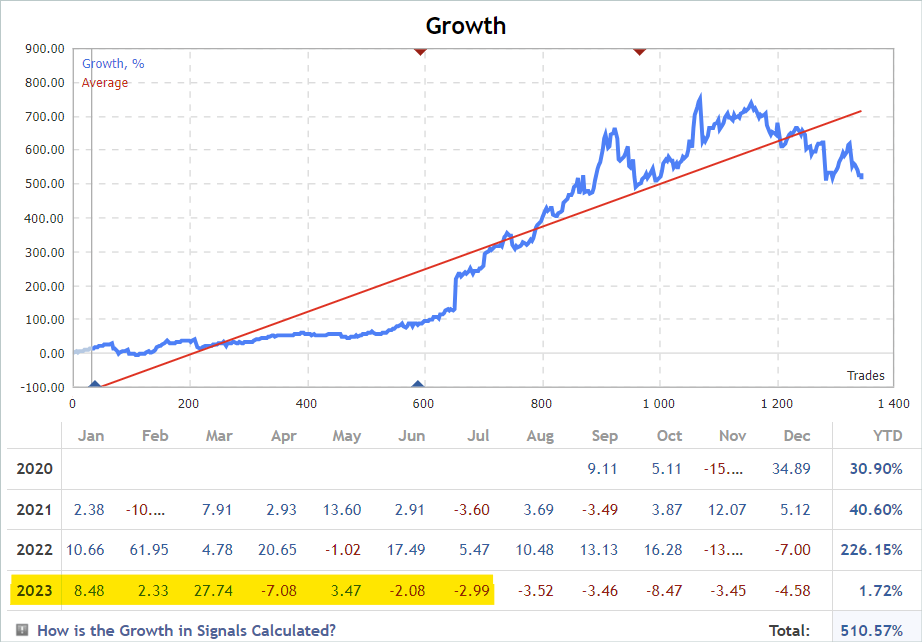
O que isso nos dá? No mínimo, obtemos uma vasta quantidade de informações sobre o estudo do ambiente, no nosso caso, os mercados financeiros. Falamos várias vezes sobre um dos principais problemas do aprendizado por reforço: a exploração do ambiente. E, ao mesmo tempo, sempre tivemos uma enorme quantidade de informações que não estávamos utilizando. Estou falando dos sinais. Na captura de tela abaixo, removi intencionalmente os autores e o nome dos sinais. Em nosso experimento, o único critério para os sinais é a presença de transações no período histórico de estudo para o instrumento financeiro no qual estamos interessados.

Treinamos os modelos no período de tempo dos primeiros 7 meses de 2023 do instrumento EURUSD. Selecionaremos os sinais de acordo com esses critérios. Estes podem ser tanto pagos quanto gratuitos. Note que, nos sinais pagos, parte do histórico está oculta. Mas são as transações mais recentes que estão ocultas. Nos interessa o histórico que está aberto.
Na aba "Conta", verificamos a presença de operações no período de interesse.
E na aba "Estatísticas", verificamos a presença de operações para o instrumento financeiro de interesse. Não estamos procurando sinais que operem exclusivamente com o instrumento de interesse. Eliminaremos transações desnecessárias posteriormente.
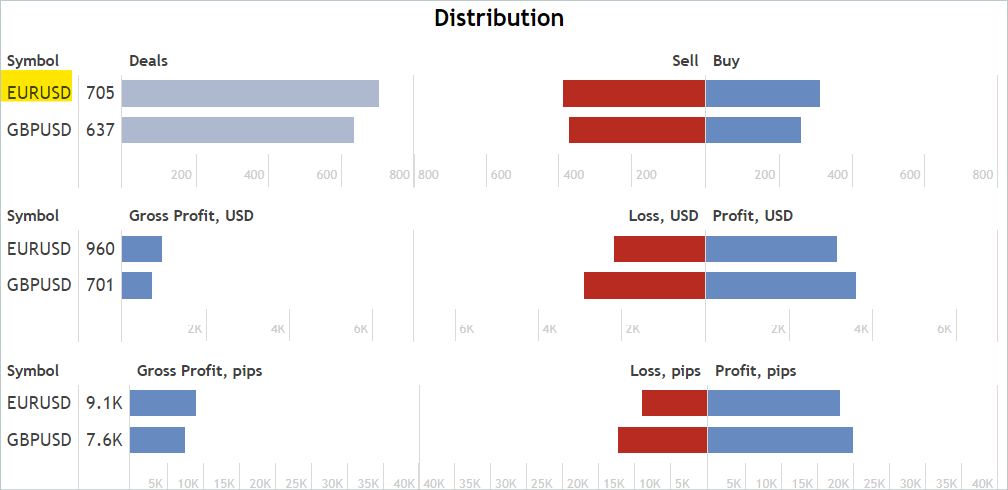
Concordo que esta é uma análise aproximada e indireta. E ela não garante a presença de transações para o instrumento financeiro analisado no período histórico de interesse. Mas a probabilidade de sua existência é bastante alta. Esta análise é bastante simples e fácil de executar.
Ao encontrar um sinal apropriado, passamos para a aba "Histórico de transações" do sinal e baixamos o arquivo csv com o histórico das operações.

Note que os arquivos baixados devem ser salvos na pasta comum do MetaTrader 5 "...\AppData\Roaming\MetaQuotes\Terminal\Common\Files\". Para facilitar o uso, criei o subdiretório "Signals" e renomeei os arquivos de todos os sinais para "SignalX.csv", onde X é o número de ordem do histórico do sinal salvo.
É importante notar que o framework Real-ORL implica o uso de trajetórias selecionadas como alguma experiência de interação com o ambiente. E, certamente, não promete um clone completo das trajetórias. Portanto, ao selecionar trajetórias, não verificamos a correlação (ou qualquer outra análise estatística) das transações com os indicadores que usamos. Pela mesma razão, não se deve esperar que o modelo treinado repita completamente as ações dos sinais mais lucrativos ou de qualquer outro sinal usado.
Assim, selecionei 20 sinais. No entanto, os arquivos csv puros que obtivemos não podem ser usados diretamente para treinar nossos modelos. Precisamos correlacionar as transações com os dados históricos dos preços e as leituras dos indicadores no momento das operações, e coletar as trajetórias usuais para cada um dos sinais usados. Este funcional será implementado no Expert Advisor "...\RealORL\ResearchRealORL.mq5", mas antes realizaremos um pequeno trabalho preparatório.
Para registrar cada operação de negociação do histórico de negociação do sinal, criaremos a classe CDeal. Esta classe é destinada apenas para uso interno. E para excluir operações desnecessárias, omitiremos os wrappers de acesso às variáveis da classe. Declararemos todas as variáveis publicamente.
class CDeal : public CObject { public: datetime OpenTime; datetime CloseTime; ENUM_POSITION_TYPE Type; double Volume; double OpenPrice; double StopLos; double TakeProfit; double point; //--- CDeal(void); ~CDeal(void) {}; //--- vector<float> Action(datetime current, double ask, double bid, int period_seconds); };
As variáveis da classe correspondem aos campos da transação no MetaTrader 5. Apenas omitimos a variável para o nome do instrumento, pois se assume trabalho com um único título financeiro. No entanto, se você estiver construindo um modelo multimoeda, recomendo adicionar o nome do instrumento.
E mais uma coisa, na transação, especificamos stop-loss e take-profit em termos de preço, enquanto o modelo gera a ação do Agente em unidades relativas. Para possibilitar a conversão dos dados, salvaremos o tamanho de um ponto do instrumento na variável point.
No construtor da classe, preencheremos as variáveis com valores iniciais. O destruidor da classe permanece vazio.
void CDeal::CDeal(void) : OpenTime(0), CloseTime(0), Type(POSITION_TYPE_BUY), Volume(0), OpenPrice(0), StopLos(0), TakeProfit(0), point(1e-5) { }
Para converter a transação em um vetor de ações do Agente, criaremos o método Action, nos parâmetros do qual passaremos a data e hora de abertura da barra atual, os preços de compra e venda, bem como o intervalo do time-frame analisado em segundos. Lembro que a análise de mercado e todas as operações de negociação são realizadas na abertura de cada barra.
Aqui, vale destacar que o tempo das operações de negociação no histórico dos sinais coletados pode diferir do tempo de abertura da barra do time-frame usado por nós. E, embora possamos fechar uma posição dentro da barra por stop-loss ou take-profit, só podemos abrir uma posição na abertura da barra. Portanto, aqui fazemos uma suposição e uma pequena correção no preço e no tempo de abertura da posição — abrimos a posição na abertura da barra se no histórico do sinal ela for aberta antes de seu fechamento.
Seguindo a lógica mencionada, no código do método, se o tempo atual for menor que o tempo de abertura da posição considerando a correção ou maior que o tempo de fechamento da posição, então o método retornará um vetor de ações do Agente nulo.
vector<float> CDeal::Action(datetime current, double ask, double bid, int period_seconds) { vector<float> result = vector<float>::Zeros(NActions); if((OpenTime - period_seconds) > current || CloseTime <= current) return result;
Note que primeiro criamos um vetor de resultados nulo e só depois realizamos o controle do tempo e retornamos o resultado. Essa abordagem nos permite operar posteriormente com o vetor de resultados nulo já formado. Consequentemente, se necessário preencher o vetor de ações, apenas preenchemos os elementos que não são nulos.
O vetor de ações é preenchido no corpo do operador de escolha switch, dependendo do tipo de posição. No caso de uma posição longa, registramos o volume da operação no elemento com índice "0". Então, verificamos o take-profit e o stop-loss por diferenças de "0" e, se necessário, convertemos o preço em um valor relativo. Os valores obtidos são registrados nos elementos com os índices "1" e "2", respectivamente.
switch(Type) { case POSITION_TYPE_BUY: result[0] = float(Volume); if(TakeProfit > 0) result[1] = float((TakeProfit - ask) / (MaxTP * point)); if(StopLos > 0) result[2] = float((ask - StopLos) / (MaxSL * point)); break;
Operações semelhantes são realizadas para uma posição curta, mas com um deslocamento dos índices dos elementos do vetor por 3.
case POSITION_TYPE_SELL: result[3] = float(Volume); if(TakeProfit > 0) result[4] = float((bid - TakeProfit) / (MaxTP * point)); if(StopLos > 0) result[5] = float((StopLos - bid) / (MaxSL * point)); break; }
O vetor formado é então retornado ao programa chamador.
//--- return result; }
Todas as transações de um sinal serão combinadas na classe CDeals. Esta classe conterá um array dinâmico de objetos, no qual adicionaremos instâncias da classe criada anteriormente, CDeal, e 2 métodos:
- LoadDeals — carregar transações de um arquivo CSV de histórico;
- Action — formar um vetor de ações do Agente.
class CDeals { protected: CArrayObj Deals; public: CDeals(void) { Deals.Clear(); } ~CDeals(void) { Deals.Clear(); } //--- bool LoadDeals(string file_name, string symbol, double point); vector<float> Action(datetime current, double ask, double bid, int period_seconds); };
No construtor e no destruidor da classe, limpamos o array dinâmico de transações.
Sugiro começar a discussão dos métodos da classe com o carregamento do histórico de transações do arquivo CSV LoadDeals. Nos parâmetros do método, passamos o nome do arquivo, a denominação do instrumento financeiro analisado e o tamanho do ponto. Intencionalmente, coloquei a denominação do instrumento nos parâmetros, pois frequentemente há variações nos nomes dos instrumentos financeiros entre diferentes corretoras. Consequentemente, mesmo ao iniciar o Expert Advisor no gráfico do instrumento analisado, seu nome pode diferir do padronizado no arquivo de histórico de sinais.
bool CDeals::LoadDeals(string file_name, string symbol, double point) { if(file_name == NULL || !FileIsExist(file_name, FILE_COMMON)) { PrintFormat("File %s not exist", file_name); return false; }
No corpo do método, primeiro verificamos o nome do arquivo e sua presença na pasta comum dos terminais. Se o arquivo necessário estiver ausente, informamos o usuário e encerraremos o método com o resultado false.
bool CDeals::LoadDeals(string file_name, string symbol, double point) { if(file_name == NULL || !FileIsExist(file_name, FILE_COMMON)) { PrintFormat("File %s not exist", file_name); return false; }
O próximo passo é verificar o nome do instrumento financeiro especificado. E se ele faltar, registramos o nome do instrumento do gráfico em que o Expert Advisor foi iniciado.
if(symbol == NULL) { symbol = _Symbol; point = _Point; }
Após passar com sucesso pelo bloco de controle, abrimos o arquivo especificado nos parâmetros do método e imediatamente verificamos o resultado da operação usando o valor do handle recebido. Se, por algum motivo, não conseguirmos abrir o arquivo, informamos o usuário sobre o erro ocorrido e encerraremos o método com um resultado negativo.
ResetLastError(); int handle = FileOpen(file_name, FILE_READ | FILE_ANSI | FILE_CSV | FILE_COMMON, short(';'), CP_ACP); if(handle == INVALID_HANDLE) { PrintFormat("Error of open file %s: %d", file_name, GetLastError()); return false; }
Nesse ponto, o trabalho preparatório está concluído e passamos à organização do ciclo de leitura de dados. Antes de cada iteração do ciclo, verificamos se o final do arquivo foi alcançado.
FileSeek(handle, 0, SEEK_SET); while(!FileIsEnding(handle)) { string s = FileReadString(handle); datetime open_time = StringToTime(s); string type = FileReadString(handle); double volume = StringToDouble(FileReadString(handle)); string deal_symbol = FileReadString(handle); double open_price = StringToDouble(FileReadString(handle)); volume = MathMin(volume, StringToDouble(FileReadString(handle))); datetime close_time = StringToTime(FileReadString(handle)); double close_price = StringToDouble(FileReadString(handle)); s = FileReadString(handle); s = FileReadString(handle); s = FileReadString(handle);
No corpo do ciclo, primeiro lemos todas as informações de uma transação e as registramos em variáveis locais. De acordo com a estrutura do arquivo, os últimos 3 elementos contêm a comissão, o swap e o lucro da transação. Em nossa trajetória, não usamos esses dados, pois o tempo e o preço de abertura podem diferir dos indicados no histórico. E com eles, os valores de lucro também serão diferentes. Além disso, a comissão e os swaps dependem das configurações da corretora.
Em seguida, verificamos se o instrumento financeiro da operação corresponde com o que analisamos, que foi passado nos parâmetros. Caso os instrumentos não correspondam, passamos para a próxima iteração do ciclo.
if(StringFind(deal_symbol, symbol, 0) < 0) continue;
Se, no entanto, a transação foi realizada com o instrumento financeiro em que estamos interessados, então criamos uma instância do objeto de descrição da transação.
ResetLastError(); CDeal *deal = new CDeal(); if(!deal) { PrintFormat("Error of create new deal object: %d", GetLastError()); return false; }
E a preenchemos, mas aqui há um nuance. Podemos facilmente salvar:
- o tipo de posição;
- o tempo de abertura e fechamento;
- o preço de abertura;
- o volume da transação;
- o tamanho de 1 ponto.
Só que no histórico das operações, os preços de stop-loss e take-profit não são especificados. Em vez disso, apenas o preço de fechamento real da posição é indicado. Aqui usamos uma lógica bastante simples:
- Assumimos que a posição foi fechada por stop-loss ou take-profit.
- Nesse caso, se a posição foi fechada com lucro, o fechamento ocorreu por take-profit. Caso contrário, o fechamento ocorreu por stop-loss. No campo correspondente, indicamos o preço de fechamento.
- O campo oposto permanece vazio.
deal.OpenTime = open_time; deal.CloseTime = close_time; deal.OpenPrice = open_price; deal.Volume = volume; deal.point = point; if(type == "Sell") { deal.Type = POSITION_TYPE_SELL; if(close_price < open_price) { deal.TakeProfit = close_price; deal.StopLos = 0; } else { deal.TakeProfit = 0; deal.StopLos = close_price; } } else { deal.Type = POSITION_TYPE_BUY; if(close_price > open_price) { deal.TakeProfit = close_price; deal.StopLos = 0; } else { deal.TakeProfit = 0; deal.StopLos = close_price; } }
Entendo completamente os riscos de negociar sem stop-losses, mas, ainda assim, espero minimizar esse risco durante o refinamento do modelo.
A descrição da transação criada é adicionada ao array dinâmico e prosseguimos para a próxima iteração do ciclo.
ResetLastError(); if(!Deals.Add(deal)) { PrintFormat("Error of add new deal: %d", GetLastError()); return false; } }
Após alcançar o fim do arquivo, fechamos o mesmo e encerramos o método com o resultado true.
FileClose(handle); //--- return true; }
O algoritmo do método para formar o vetor de ações do Agente é bastante simples. Simplesmente percorremos todo o array de transações e chamamos os métodos (que têm o mesmo nome) de cada transação.
vector<float> CDeals::Action(datetime current, double ask, double bid, int period_seconds) { vector<float> result = vector<float>::Zeros(NActions); for(int i = 0; i < Deals.Total(); i++) { CDeal *deal = Deals.At(i); if(!deal) continue; vector<float> action = deal.Action(current, ask, bid, period_seconds);
No entanto, existem algumas nuances neste ponto. Admitimos que no histórico de sinais podem haver várias posições abertas simultaneamente, inclusive em direções opostas. Por isso, precisamos somar os vetores obtidos de todas as transações do arquivo. Porém, só podemos somar os volumes. A simples adição dos níveis de stop-loss e take-profit seria incorreta. Lembre-se que, como stop-loss e take-profit no vetor de ações do Agente, é indicado um deslocamento em unidades relativas ao preço atual. Considerando isso, ao somar os vetores para os níveis de stop-loss e take-profit, tomamos o maior desvio. Os volumes não fechados a tempo serão fechados pelo Expert Advisor na abertura de uma nova vela, pois nesse caso esperamos uma redução no volume total da posição agregada.
result[0] += action[0]; result[3] += action[3]; result[1] = MathMax(result[1], action[1]); result[2] = MathMax(result[2], action[2]); result[4] = MathMax(result[4], action[4]); result[5] = MathMax(result[5], action[5]); } //--- return result; }
Passamos o vetor de ações do Agente final para o programa chamador e encerramos o método.
Com isso, concluímos o trabalho preparatório e passamos a trabalhar no Expert Advisor "...\RealORL\ResearchRealORL.mq5". Aqui, devemos dizer que o EA foi criado com base nos EAs anteriores "...\...\Research.mq5" e herdou seu modelo de construção. E, ao mesmo tempo, todos os parâmetros externos foram herdados.
//+------------------------------------------------------------------+ //| Input parameters | //+------------------------------------------------------------------+ input ENUM_TIMEFRAMES TimeFrame = PERIOD_H1; input double MinProfit = -10000; //--- input group "---- RSI ----" input int RSIPeriod = 14; //Period input ENUM_APPLIED_PRICE RSIPrice = PRICE_CLOSE; //Applied price //--- input group "---- CCI ----" input int CCIPeriod = 14; //Period input ENUM_APPLIED_PRICE CCIPrice = PRICE_TYPICAL; //Applied price //--- input group "---- ATR ----" input int ATRPeriod = 14; //Period //--- input group "---- MACD ----" input int FastPeriod = 12; //Fast input int SlowPeriod = 26; //Slow input int SignalPeriod = 9; //Signal input ENUM_APPLIED_PRICE MACDPrice = PRICE_CLOSE; //Applied price //--- input int Agent = 1;
Porém, este Expert Advisor não utiliza nenhum modelo, pois a decisão sobre as operações de negociação já foi tomada por nós, e usamos o histórico de transações de sinais. Daí que removemos todos os objetos de modelos e adicionamos um objeto do array de transações de sinais CDeals.
SState sState; STrajectory Base; STrajectory Buffer[]; STrajectory Frame[1]; CDeals Deals; //--- float dError; datetime dtStudied; //--- CSymbolInfo Symb; CTrade Trade; //--- MqlRates Rates[]; CiRSI RSI; CiCCI CCI; CiATR ATR; CiMACD MACD; //--- double PrevBalance = 0; double PrevEquity = 0;
Da mesma forma, no método de inicialização do EA, em vez de carregar um modelo previamente treinado, carregamos o histórico de operações de negociação.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- if(!Symb.Name(_Symbol)) return INIT_FAILED; Symb.Refresh(); //--- if(!RSI.Create(Symb.Name(), TimeFrame, RSIPeriod, RSIPrice)) return INIT_FAILED; //--- if(!CCI.Create(Symb.Name(), TimeFrame, CCIPeriod, CCIPrice)) return INIT_FAILED; //--- if(!ATR.Create(Symb.Name(), TimeFrame, ATRPeriod)) return INIT_FAILED; //--- if(!MACD.Create(Symb.Name(), TimeFrame, FastPeriod, SlowPeriod, SignalPeriod, MACDPrice)) return INIT_FAILED; if(!RSI.BufferResize(HistoryBars) || !CCI.BufferResize(HistoryBars) || !ATR.BufferResize(HistoryBars) || !MACD.BufferResize(HistoryBars)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); return INIT_FAILED; } //--- if(!Trade.SetTypeFillingBySymbol(Symb.Name())) return INIT_FAILED; //--- load history if(!Deals.LoadDeals(SignalFile(Agent), "EURUSD", SymbolInfoDouble(_Symbol, SYMBOL_POINT))) return INIT_FAILED; //--- PrevBalance = AccountInfoDouble(ACCOUNT_BALANCE); PrevEquity = AccountInfoDouble(ACCOUNT_EQUITY); //--- return(INIT_SUCCEEDED); }
Observe que, ao carregar os dados das transações de sinais, em vez do nome do arquivo, indicamos SignalFile(Agent). Aqui, usamos uma macro substituição e é por isso que anteriormente criamos nomes de arquivos de sinais unificados "SignalX.csv". A substituição de macro retorna o nome unificado do arquivo de histórico de sinais com a indicação do valor do parâmetro externo Agent como identificador.
#define SignalFile(agent) StringFormat("Signals\\Signal%d.csv",agent)
Isso nos permite, posteriormente, executar "...\RealORL\ResearchRealORL.mq5" no modo de otimização do testador de estratégias MetaTrader 5. A otimização pelo parâmetro Agent permitirá que cada execução trabalhe com seu próprio arquivo de histórico de sinais. Assim, poderemos processar vários arquivos de sinais paralelamente e coletar as trajetórias de interação com o ambiente.
A interação com o ambiente é realizada no método OnTick. Aqui, como de costume, primeiro verificamos a ocorrência do evento de abertura de uma nova barra.
void OnTick() { //--- if(!IsNewBar()) return;
E, se necessário, carregamos os dados históricos do movimento de preços. Também atualizamos os buffers de objetos que trabalham com indicadores.
int bars = CopyRates(Symb.Name(), TimeFrame, iTime(Symb.Name(), TimeFrame, 1), HistoryBars, Rates); if(!ArraySetAsSeries(Rates, true)) return; //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh(); Symb.Refresh(); Symb.RefreshRates();
A ausência de modelos para tomada de decisão elimina a necessidade de preencher os buffers de dados. No entanto, para manter informações na trajetória de interação com o ambiente, precisaremos preencher a estrutura de estado com os dados necessários. Inicialmente, coletaremos dados sobre movimento de preços e indicadores.
float atr = 0; for(int b = 0; b < (int)HistoryBars; b++) { float open = (float)Rates[b].open; float rsi = (float)RSI.Main(b); float cci = (float)CCI.Main(b); atr = (float)ATR.Main(b); float macd = (float)MACD.Main(b); float sign = (float)MACD.Signal(b); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) continue; //--- int shift = b * BarDescr; sState.state[shift] = (float)(Rates[b].close - open); sState.state[shift + 1] = (float)(Rates[b].high - open); sState.state[shift + 2] = (float)(Rates[b].low - open); sState.state[shift + 3] = (float)(Rates[b].tick_volume / 1000.0f); sState.state[shift + 4] = rsi; sState.state[shift + 5] = cci; sState.state[shift + 6] = atr; sState.state[shift + 7] = macd; sState.state[shift + 8] = sign; }
Então, inseriremos informações sobre o estado da conta e posições abertas. Aqui também indicaremos o tempo de abertura da barra atual. Observe que, neste estágio, estamos salvando apenas um valor de tempo sem criar harmônicos de marcação temporal. Isso nos permite reduzir o volume de dados armazenados sem perda de informação.
sState.account[0] = (float)AccountInfoDouble(ACCOUNT_BALANCE); sState.account[1] = (float)AccountInfoDouble(ACCOUNT_EQUITY); //--- double buy_value = 0, sell_value = 0, buy_profit = 0, sell_profit = 0; double position_discount = 0; double multiplyer = 1.0 / (60.0 * 60.0 * 10.0); int total = PositionsTotal(); datetime current = TimeCurrent(); for(int i = 0; i < total; i++) { if(PositionGetSymbol(i) != Symb.Name()) continue; double profit = PositionGetDouble(POSITION_PROFIT); switch((int)PositionGetInteger(POSITION_TYPE)) { case POSITION_TYPE_BUY: buy_value += PositionGetDouble(POSITION_VOLUME); buy_profit += profit; break; case POSITION_TYPE_SELL: sell_value += PositionGetDouble(POSITION_VOLUME); sell_profit += profit; break; } position_discount += profit - (current - PositionGetInteger(POSITION_TIME)) * multiplyer * MathAbs(profit); } sState.account[2] = (float)buy_value; sState.account[3] = (float)sell_value; sState.account[4] = (float)buy_profit; sState.account[5] = (float)sell_profit; sState.account[6] = (float)position_discount; sState.account[7] = (float)Rates[0].time;
E imediatamente preencheremos no vetor de recompensas os elementos que influenciam a mudança do saldo e do patrimônio.
sState.rewards[0] = float((sState.account[0] - PrevBalance) / PrevBalance); sState.rewards[1] = float(1.0 - sState.account[1] / PrevBalance);
E salvaremos os valores do saldo e do patrimônio que precisaremos na próxima barra para calcular a recompensa.
PrevBalance = sState.account[0]; PrevEquity = sState.account[1];
Em vez de executar a propagação do Agente, solicitamos um vetor de ações do histórico de negociações.
vector<float> temp = Deals.Action(TimeCurrent(), SymbolInfoDouble(_Symbol, SYMBOL_ASK), SymbolInfoDouble(_Symbol, SYMBOL_BID), PeriodSeconds(TimeFrame) );
O processamento e a decodificação do vetor de ações são realizados de acordo com o algoritmo que já desenvolvemos. Primeiro, excluímos volumes contraditórios.
double min_lot = Symb.LotsMin(); double step_lot = Symb.LotsStep(); double stops = MathMax(Symb.StopsLevel(), 1) * Symb.Point(); if(temp[0] >= temp[3]) { temp[0] -= temp[3]; temp[3] = 0; } else { temp[3] -= temp[0]; temp[0] = 0; }
Depois, ajustamos a posição longa. Mas até agora não permitíamos a abertura de posições sem especificar stop-loss ou take-profit. Agora, isso é uma medida forçada. Por isso, fazemos ajustes na verificação do fechamento de posições abertas anteriormente e nos preços de stop-loss/take-profit.
//--- buy control if(temp[0] < min_lot || (temp[1] > 0 && (temp[1] * MaxTP * Symb.Point()) <= stops) || (temp[2] > 0 && (temp[2] * MaxSL * Symb.Point()) <= stops)) { if(buy_value > 0) CloseByDirection(POSITION_TYPE_BUY); } else { double buy_lot = min_lot + MathRound((double)(temp[0] - min_lot) / step_lot) * step_lot; double buy_tp = (temp[1] > 0 ? NormalizeDouble(Symb.Ask() + temp[1] * MaxTP * Symb.Point(), Symb.Digits()) : 0); double buy_sl = (temp[2] > 0 ? NormalizeDouble(Symb.Ask() - temp[2] * MaxSL * Symb.Point(), Symb.Digits()) : 0); if(buy_value > 0) TrailPosition(POSITION_TYPE_BUY, buy_sl, buy_tp); if(buy_value != buy_lot) { if(buy_value > buy_lot) ClosePartial(POSITION_TYPE_BUY, buy_value - buy_lot); else Trade.Buy(buy_lot - buy_value, Symb.Name(), Symb.Ask(), buy_sl, buy_tp); } }
Fazemos ajustes semelhantes no bloco de ajuste da posição curta.
//--- sell control if(temp[3] < min_lot || (temp[4] > 0 && (temp[4] * MaxTP * Symb.Point()) <= stops) || (temp[5] > 0 && (temp[5] * MaxSL * Symb.Point()) <= stops)) { if(sell_value > 0) CloseByDirection(POSITION_TYPE_SELL); } else { double sell_lot = min_lot + MathRound((double)(temp[3] - min_lot) / step_lot) * step_lot;; double sell_tp = (temp[4] > 0 ? NormalizeDouble(Symb.Bid() - temp[4] * MaxTP * Symb.Point(), Symb.Digits()) : 0); double sell_sl = (temp[5] > 0 ? NormalizeDouble(Symb.Bid() + temp[5] * MaxSL * Symb.Point(), Symb.Digits()) : 0); if(sell_value > 0) TrailPosition(POSITION_TYPE_SELL, sell_sl, sell_tp); if(sell_value != sell_lot) { if(sell_value > sell_lot) ClosePartial(POSITION_TYPE_SELL, sell_value - sell_lot); else Trade.Sell(sell_lot - sell_value, Symb.Name(), Symb.Bid(), sell_sl, sell_tp); } }
No final do método, complementamos o vetor de recompensas, copiamos o vetor de ações e passamos a estrutura para adição à trajetória.
if((buy_value + sell_value) == 0) sState.rewards[2] -= (float)(atr / PrevBalance); else sState.rewards[2] = 0; for(ulong i = 0; i < NActions; i++) sState.action[i] = temp[i]; sState.rewards[3] = 0; sState.rewards[4] = 0; if(!Base.Add(sState)) ExpertRemove(); }
Com isso, concluímos a revisão dos métodos do EA "...\RealORL\ResearchRealORL.mq5", já que os outros métodos foram transferidos sem alterações. E com o código completo do EA, assim como todos os programas usados no artigo, você pode se familiarizar no anexo.
Os autores do método Real-ORL não propõem um novo método de treinamento da política do Ator. E para nosso experimento, não fizemos alterações nem no algoritmo de treinamento da política, nem na arquitetura do modelo. Damos esse passo conscientemente para tornar as condições comparáveis com o treinamento do modelo do artigo anterior . O que, em última análise, permitirá avaliar o impacto direto do framework Real-ORL nos resultados do treinamento da política.
3. Testes
Acima, realizamos a coleta de informações sobre operações de negociação de diferentes sinais e preparamos um EA para converter as informações coletadas em trajetórias de interação com o ambiente. Agora, passamos ao teste do trabalho realizado e à avaliação do impacto das trajetórias selecionadas nos resultados do treinamento do modelo. Neste trabalho, estaremos treinando modelos completamente novos, inicializados com parâmetros aleatórios. Lembre-se de que no artigo anterior, otimizamos modelos previamente treinados.
Inicialmente, executaremos o EA de conversão de histórico de sinais em trajetórias "...\RealORL\ResearchRealORL.mq5". Vamos executar o EA em modo de otimização completa.
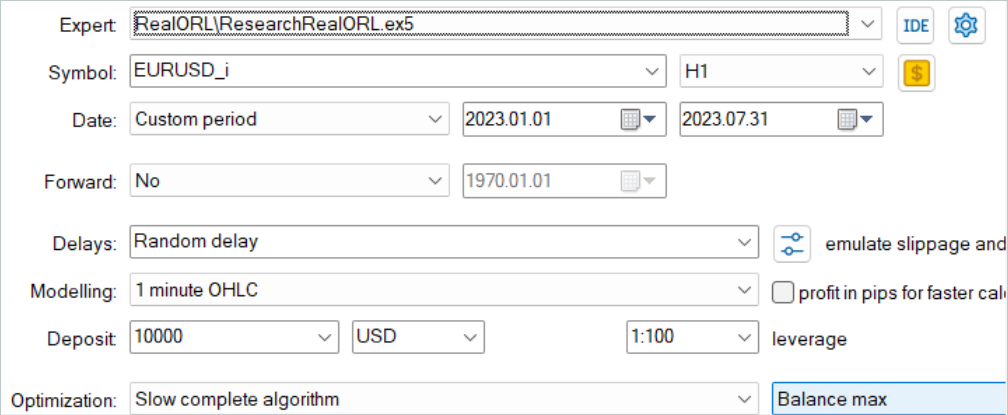
Otimizaremos apenas pelo parâmetro Agent. No intervalo de parâmetros, indicaremos o primeiro e o último identificador de arquivos de sinais com um passo de "1".
Devo dizer que, como resultado, obtivemos trajetórias bastante interessantes.
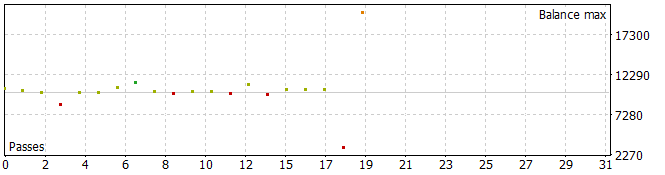
Cinco das passagens durante o período analisado fecharam com perda, enquanto uma dobrou o saldo.
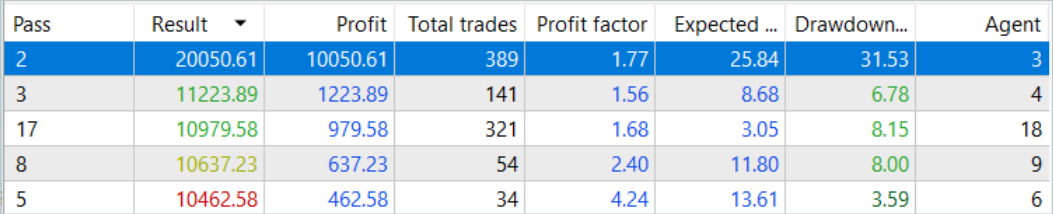
Uma única passagem da trajetória mais lucrativa mostrou uma retração significativa em 7.02.2023 e 25.07.2023. Não discutirei a estratégia usada pelo autor do sinal, pois não estou familiarizado com ela. Além disso, é bem possível que a retração tenha sido causada por uma abertura precoce da posição, provocada pelo deslocamento do ponto de abertura da posição para o início da barra do timeframe analisado. E, claro, o uso de stop-losses, que conscientemente zeramos, levaria à fixação de perdas em tais situações.
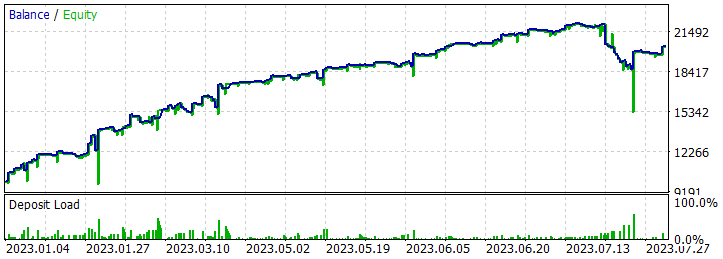
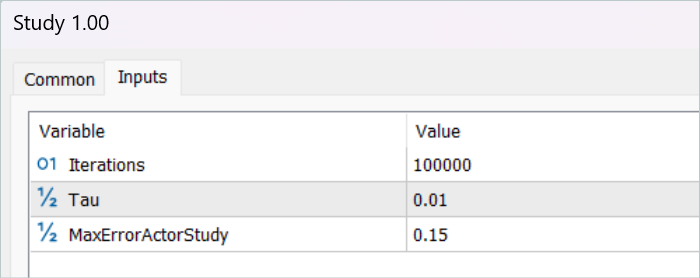
Após salvar as trajetórias, passamos para o treinamento do modelo. Para isso, lançamos o EA "...\RealORL\Study.mq5".
O treinamento inicial foi realizado apenas com dados de trajetórias coletadas a partir dos resultados dos sinais. E devo dizer que nenhum milagre aconteceu. Os resultados do modelo após o treinamento inicial estavam longe do desejado. A política treinada gerou perdas tanto no período de treinamento nos primeiros 7 meses de 2023 quanto no intervalo histórico de teste em agosto de 2023. Mas, honestamente, eu não diria que o framework Real-ORL proposto é ineficaz. As 20 trajetórias selecionadas estão longe das 3000 trajetórias usadas pelos autores do framework. E certamente 20 trajetórias não cobrem nem uma pequena parte da variedade de ações possíveis do agente.
Antes de continuar o treinamento, o buffer de trajetórias de treinamento foi reabastecido usando o EA "...\RealORL\Research.mq5". Lembro que este EA realiza passagens tomando decisões com base na política do Agente previamente treinada. E o estudo do ambiente é realizado graças à estocasticidade do estado latente e da política do Agente. As duas estocasticidades criam uma variedade bastante grande de ações do Agente, o que permite estudar o ambiente. À medida que a política do Agente é treinada, ambas as estocasticidades são reduzidas, graças à diminuição da variância de cada parâmetro. Isso torna as ações do Agente mais previsíveis e conscientes.
Adicionamos ao buffer 200 novas trajetórias e repetimos o processo de treinamento dos modelos.
Desta vez, o processo de treinamento da política do Agente foi bastante longo. Precisei atualizar várias vezes o buffer de reprodução de experiência usando o EA "...\RealORL\Research.mq5" antes de obter uma política lucrativa. No entanto, devo indicar que no processo de atualização do buffer de reprodução de experiência, após seu completo preenchimento, substituímos as trajetórias com o maior prejuízo (menor lucro) por outras mais lucrativas. Consequentemente, apenas as trajetórias coletadas com o EA "...\RealORL\Research.mq5" foram substituídas. As trajetórias dos sinais, devido à sua rentabilidade geral, permaneceram constantemente no buffer de reprodução de experiência.
Como já mencionei, após um longo período de treinamento, conseguimos desenvolver uma política capaz de gerar lucro na amostra de treinamento. Além disso, a política obtida é capaz de generalizar a experiência adquirida para novos dados. Isso é evidenciado pelo lucro obtido em dados históricos fora do período de treinamento.


Nos dados históricos da amostra de teste, o Agente realizou 131 transações, das quais 48,85% foram fechadas com lucro. A transação mais lucrativa foi quase 10% menor que a maior perda (379,89 contra 398,49, respectivamente). Ao mesmo tempo, a transação lucrativa média foi 40% maior que a perda média. Como resultado, o fator de lucro durante o período de teste foi de 1,34, e o fator de recuperação foi de 0,94.
Também vale a pena notar o equilíbrio quase perfeito entre as operações longas (70) e curtas (61). Isso demonstra a capacidade do Agente de identificar tendências locais, não apenas seguindo a tendência global.
Considerações finais
Neste artigo, exploramos o framework Real-ORL, que foi adaptado da robótica. Os autores do framework realizaram extensas pesquisas empíricas usando um robô real, o que lhes permite fazer as seguintes conclusões:
- Para tarefas fora do domínio de aplicação, os algoritmos de aprendizado por reforço poderiam ser generalizados para áreas de tarefas com falta de dados e para tarefas dinâmicas.
- A mudança no desempenho do ORL após o uso de dados heterogêneos tende a variar dependendo dos agentes, do design da tarefa e das características dos dados.
- Certas trajetórias heterogêneas, independentes da tarefa, podem fornecer suporte de dados sobreposto e promover um melhor treinamento, permitindo que os agentes do ORL melhorem seu desempenho.
- O melhor agente para cada tarefa é ou um algoritmo ORL ou um empate entre ORL e BC (clonagem de comportamento). As avaliações apresentadas no artigo indicam que, mesmo em modo de dados fora do domínio de aplicação, mais realista para o mundo real, o aprendizado por reforço off-line é uma abordagem eficaz.
Em nosso trabalho, consideramos a possibilidade de usar o framework proposto na área de mercados financeiros. Em particular, as abordagens propostas pelos autores do framework Real-ORL nos permitem explorar o histórico de uma ampla gama de sinais disponíveis no mercado para treinar modelos. No entanto, para representar ao máximo a diversidade do ambiente, precisamos de um grande número de trajetórias. E, portanto, o trabalho deve ser feito para coletar o maior número possível de trajetórias diversas. Usar apenas 20 trajetórias neste trabalho pode ser considerado um erro. Os autores do Real-ORL usaram mais de 3000 trajetórias em seu trabalho.
Minha opinião pessoal é que o método pode e deve ser usado para o treinamento inicial de modelos e tem uma vantagem sobre a coleta de trajetórias aleatórias. No entanto, usar apenas dados "congelados" de trajetórias não é suficiente para construir a política ótima do Agente. É difícil esperar resultados sérios de um pequeno número de trajetórias que selecionei. Mas os autores do método também não conseguiram obter os resultados teóricos máximos possíveis em seu trabalho. Além disso, as informações sobre os sinais são limitadas e não permitem considerar todos os riscos. Por exemplo, não há informações sobre stop-losses e take-profits nos sinais. A ausência deles não permite avaliar e controlar completamente os riscos. Por isso, o modelo treinado em trajetórias de sinais precisa de um ajuste fino subsequente em trajetórias adicionais, obtidas já considerando a política previamente treinada.
Referências
Programas usados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Research.mq5 | EA | EA para coleta de exemplos |
| 2 | ResearchRealORL.mq5 | EA | EA para coleta de exemplos pelo método Real-ORL |
| 3 | ResearchExORL.mq5 | EA | EA para coleta de exemplos pelo método ExORL |
| 4 | Study.mq5 | EA | EA para treinamento do agente |
| 5 | Test.mq5 | EA | EA para teste do modelo |
| 6 | Trajectory.mqh | Biblioteca de Classe | Estrutura de descrição do estado do sistema |
| 7 | NeuroNet.mqh | Biblioteca de Classe | Biblioteca de classes para criação de redes neurais |
| 8 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/13854
 Criando um Expert Advisor simples multimoeda usando MQL5 (Parte 5): Bandas de Bollinger no canal de Keltner — Sinais dos indicadores
Criando um Expert Advisor simples multimoeda usando MQL5 (Parte 5): Bandas de Bollinger no canal de Keltner — Sinais dos indicadores
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso