Машинное обучение в трейдинге: теория, модели, практика и алготорговля - страница 851
Вы упускаете торговые возможности:
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Регистрация
Вход
Вы принимаете политику сайта и условия использования
Если у вас нет учетной записи, зарегистрируйтесь
2 класса
Загружалось 1 ядро
Установка , rfeControl = rfeControl(number = 1,repeats = 1) - сократило время до 10-15 минут. Изменения в результатах - 2 пары предикторов поменялись местами, но в целом похоже, на то, что по умолчанию было.
Ну, вот, Ваши 10 минут на одном ядре - это мои 2 на 4-х, а две минуты я не помню.
Я никогда не жду что-то часами, если 10-15 минут не сработало, значит что-то не так, значит затраты большего времени никакой пользы не дадут. Любая оптимизация при построении модели, которая длится часами - это полное не понимание идеологии моделирования, которая говорит, что модель должна минимально грубой и ни в коем случае максимально точной.
Теперь про отбор предикторов.
Почему Вы этим занялись и зачем? Какую проблему Вы пытаетесь решить?
Самое главное в отборе - это попытка решить проблему переобучения. Ваша модель переобучена? Если нет, то отбор может ускорить обучение за счет меньшего количества предикторов. Но уменьшить количество гораздо эффективнее за счет выделения главных компонент. Они ни на что не влияют, но могут на порядок уменьшить количество предикторов и соответственно увеличить скорость подгонки модели.
Поэтому для начала: зачем это Вам?
Нашёл ещё один интересный пакет для отсева предикторов. Называется FSelector. Предлагает около десятка методов для отсева предикторов , в том числе с помощью энтропии.
Файл с предикторами и таргетом взял отсюда - https://www.mql5.com/ru/forum/86386/page6#comment_2534058
Оценку предиктора каждым методом я в конце показал на графике -
Синенький цвет это хорошо, красненький - плохо (для corrplot результаты были масштабированы в [-1:1], для точной оценки смотрите результаты вызова самих функций cfs(targetFormula, trainTable), chi.squared(targetFormula, trainTable), итд)
Видно что X3, X4, X5, X19, X20 хорошо оценены почти всеми методами, для начала можно взять их, потом пробовать добавить/убрать ещё.
Однако, модели в rattle не прошли тест с этими 5 предикторами на Rat_DF2, чуда опять не произошло. Т.е. даже с оставшимися предикторами нужно подбирать параметры модели, делать кроссвалидацию, самому добавлять/убирать предикторы.
Сделал такую же вещь на CORElearn на данных из статей Владимира.
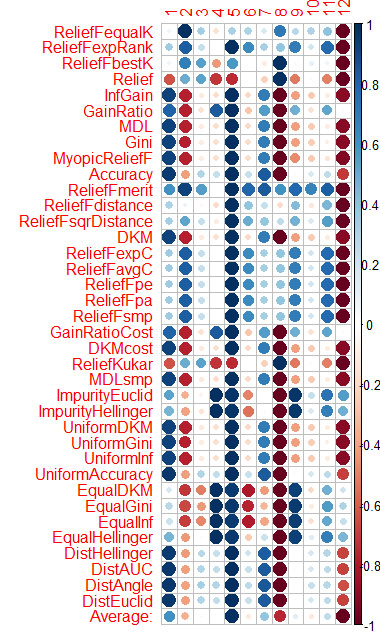
Посчитал среднее по столбцам (нижняя строка Average) и отсортировал по ней. Так проще воспринимать суммарную важность.
Считало 1.6 минуты - и это 37 алгоритмов отработали. По скорости гораздо лучше Caret (16 минут), при близких результатах.
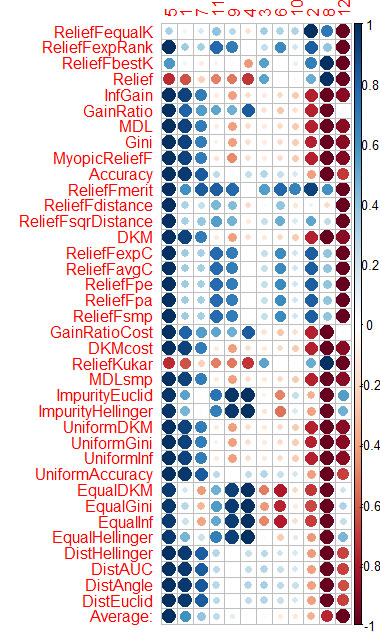
Сделал такую же вещь на CORElearn на данных из статей Владимира.
Посчитал среднее по столбцам (нижняя строка Average) и отсортировал по ней. Так проще воспринимать суммарную важность.
Считало 1.6 минуты - и это 37 алгоритмов отработали.
Ну и каков итог??? Ответили на вопрос о важности предикторов или нет, а то я не понимаю немного этих картинок.
Для меня сейчас вообще проблем нет при построении и выборе модели, втритом отбираю предикторы, потмом строю на них 10 моделей, потом мутуал информацией отбираю ту моедлеь которая работает лучше всего. А знаете как это делается. Задачка для ума!!! Ладно кто решит тот молодец!!!!!
Удалось мне на медне получить знамо вот такой набор моделей. И собственно впорос: Какая из моделей является рабочей и почему??????
Вернее они все рабочие, но только одна из них сможет набрать. И объясните почему???
Ну и каков итог??? Ответили на вопрос о важности предикторов или нет, а то я не понимаю немного этих картинок.
Для меня сейчас вообще проблем нет при построении и выборе модели, втритом отбираю предикторы, потмом строю на них 10 моделей, потом мутуал информацией отбираю ту моедлеь которая работает лучше всего. А знаете как это делается. Задачка для ума!!! Ладно кто решит тот молодец!!!!!
Удалось мне на медне получить знамо вот такой набор моделей. И собственно впорос: Какая из моделей является рабочей и почему??????
Вернее они все рабочие, но только одна из них сможет набрать. И объясните почему???
Vtreat очень похоже сортирует предикторы (важные вначале)
5 1 7 11 4 10 3 9 6 2 12 8
А вот сортировка по среднему в CORElearn
5 1 7 11 9 4 3 6 10 2 8 12
Думаю больше с пакетами по отбору предикторов не буду заморачиваться.
Так что и Vtreat вполне достаточно. Разве что взаимодействие предикторов не учитывается. В CORElearn наверное тоже.
я просто слезами обливаюсь когда вижу, что вы продолжаете подбирать важность предикторов для каких-то кусков истории рынка. Зачем? это же профанация стат. методов
На практике проверил, что если в НС подать предиктор № 2 - то ошибка с 30% поднимается до почти 50%
а на ООС как ошибка меняется?
а на ООС как ошибка меняется?
аналогично. Как и в статьях Владимира - данные оттуда.
а если на другой ООС?
На практике проверил, что если в НС подать предиктор № 2 - то ошибка с 30% поднимается до почти 50%
Плюньте на предикторы, и подавайте на НС нормированных временной ряд. Предикторы НС сама найдёт - +1-2 слоя, и вот вам предикторы