Графический анализ множества показателей одного объекта относительно других объектов или многомерный анализ результатов оптимизации
Пару дней назад, меня посетила мысль, а что если представить показатели в виде звезды, где длина каждого отрезка, исходящего из центра звезды, будет символизировать показатель.
Длину можно представить как процентное отношение к заданному желаемому значению, либо как отношение к лучшему значению из выборки. Для ТС важна сбалансированность, подумал дальше я, а это значит, что надо учитывать два показателя системы - тождество отрезков и их абсолютную длину. Тогда следует представить идеальный круг, который будет символизировать 100%, и узнать какую площадь занимает наша звезда в этом кругу и на сколько она имеет окружную форму (сбалансированность). Зная количество показателей (отрезков) мы можем условно определить число кусков не полных кругов и найти площадь куска каждого круга, а потом сложить эту площадь. Зная сумму площадей мы можем определить какой процент площади занимает звезда в идеальной окружности. Дальше мы можем определить радиус нашей звезды (тут либо из площади, либо по средней - надо смотреть, что будет правильней/точней/удобней). Зная радиус мы можем оценить отклонения от радиуса каждого луча, а после найти коэффициент СКО, который и скажет на сколько сбалансированы показатели.
Га графике мы сможем разместить либо сами звезды, раскрасив их в зависимости от их сбалансированности или размера, либо иные фигуры, к примеру можно так и разместить звезду в окружности - и окружности описывающей звезду будет виден процент заполнения, а цветом подсветить её гладкость или ещё что-то возможно варианты.
Конечно, такой график эффективен при детальном анализе, после удаления заведомо плохих показателей, так-как количество объектов очень много не уместить на плоскости, но думаю, этого и не надо, когда речь идет в выборе лучших вариантов.
Как думаете, есть ли в этом смысл? Нет ли у меня логических ошибок? Реализуемо ли это в MQL5? Может есть делание сделать это у кого?
Решил произвести пример расчета
Исходные данные:
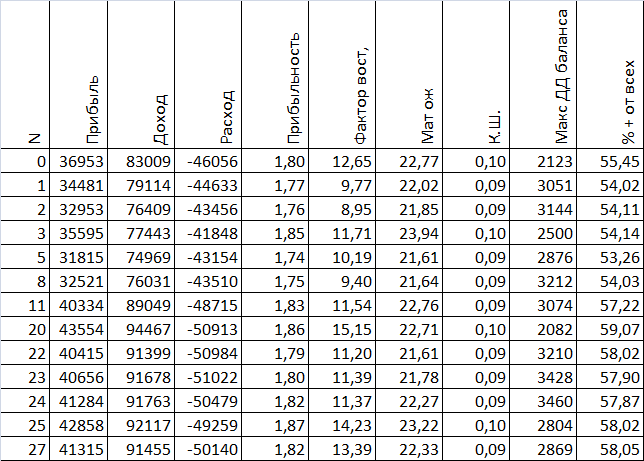
Какой вариант Вам видится самым лучшим?
Теперь представим данные в процентном виде, т.е. лучший показатель будет равен 100%, а остальные будут составлять какой либо процент от лучшего показателя, при этом надо учесть что показатель "Расход" и "Макс ДД баланса" имеют обратное логическое значение, т.е. лучшим будет то значение, которое меньше, а не больше. Прибыль в дальнейшем не будет учавствовать в расчетах.
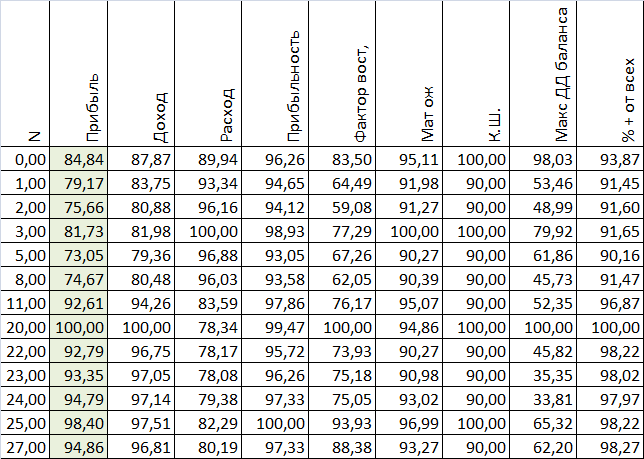
В принципе из этих процентов я и хочу строить отрезки звезды - т.е. представим что из центра выходит отрезок раный 1см*процент для каждой строки, и теперь это можно нанести на график для визуализации, чего я сделать по техническим причинам не могу, ну да ладно, поехали дальше.
Теперь представим, что каждый отрезок является радиусом отдельно взятого круга, тогда найдем площадь для каждого отдельного круга (отрезка), суммируем её и узнаем, каким радиусом был бы круг этой площади (т.е. слепим все куски в один комок).
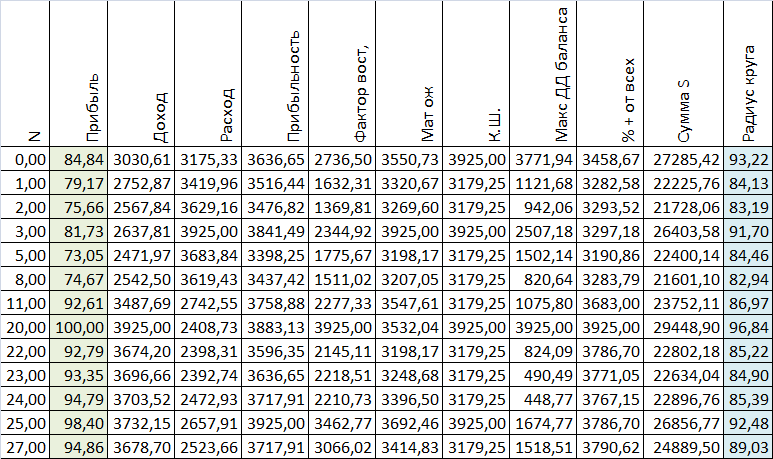
Итак зная радиус суммарного круга, найдем дельты, которые находятся за пределами суммарного радиуса - т.е. некие впадины и пики для каждого показателя, при этом положительная дельта подразумевает нахождение за суммовым радиусом, а отрицательная внутри этого радиуса.
Зная дельты мы можем рассчитать СКО для каждого набора показателей.
Из показателя "Радиус круга" и СКО можно сделать сводный коэффициент, путем деления радиуса круга на СКО (может это и не совсем верное решение - выслушаю мнения).
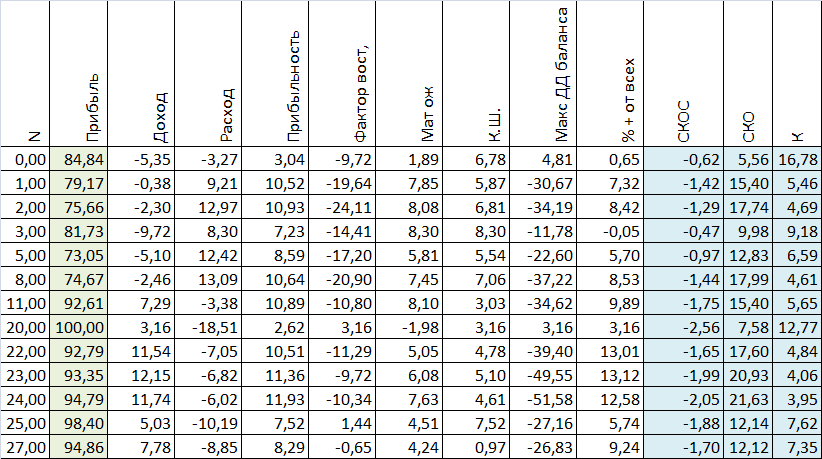
Лучшим коэффициентом оказался N "0" - т.е. первый по порядку в нашей таблице.
Построив график зависимость СКО от радиуса круга можно увидеть следующую динамику

данная динамика свидетельствует о почти линейной зависимости СКО от расчетного радиуса на данной выборке.
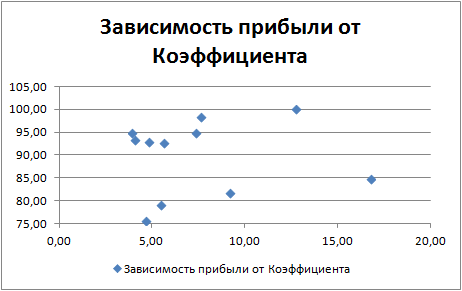
Построив график зависимости Прибыли от коэффициента можно видеть, что прибыль с малым коэффициентом более распрастраненное явление. Следует ли от сюда вывод, что высокий коэффициент скорей случайность, чем закономерность, сказать нельзя, поскольку выборка крайне мала. Но, данный график по кучности показателей позволяет судить об устойчивости системы на оптимизируемый показатель. Саму прибыль, возможно, следует включить в расчет коэффициента, и искать зависимости по оптимизируемым параметрам.
Ниже на графике показано, как распределились коэффициента в зависимости от порядкового номера набора показателей (прохода оптимизатора).
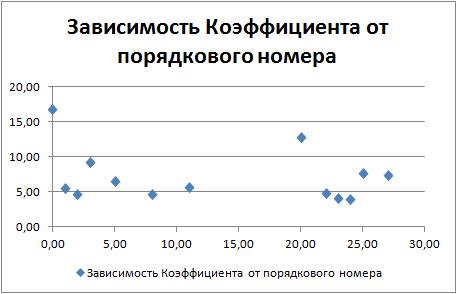
Из графика видно, что лучшим оказался вариант под номером "0", на втором месте "20", ну а на третьем вариант под номером "3"!
Думаю, что не лишним будет сравнить данный метод с другим методом - сестемой среднего балла, которую я так же ранее придумал (ну врядли я первый, кто это придумал, просто не знаю кто её придумал - просветите, если знаете). Её метод очень прост - находим среднее значение показателя в столбце и сверяем его с каждым значением в столбе, если значение положительное по логике, то ставим единицу, а если отрицательное, то ставим ноль, а потом суммируем полученный результат по строкам. Таким образом получим такую сводную таблицу.
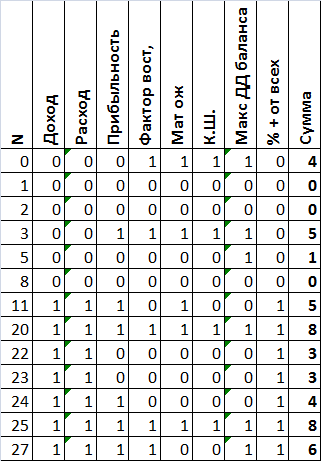
Из этой таблицы видно, что 20 и 25 вариант набрали по 8 баллов, что является максимумом, а на втором месте вариант 27 с 6 балами, а вот вариант 0 набрал всего 4 балла!
Упорядочим результаты по возрастанию и посмотри на два метода
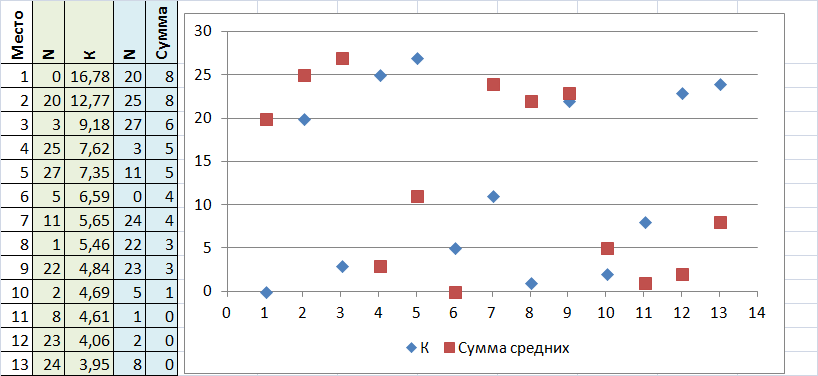
Как видно из графика совпадение результатов почти отсутствует (из таблицы видно, что два первых результата по методу средних сумм набрали одинаковое колличество балов, а значит можно считать, что 20 вариант оказался на втором месте по двум методикам), т.е. методы совершенно разные и дают разный результат.
Какой из методов лучше - сказать пока сложно - тебуется методика проверки - предлагайте варианты, если есть идеи!
Относительно варианта под номером "0", его выводит в лидерство при использовании "Звездного метода" то обстоятельство, что его показатели весьма сбалансированы и при этом радиус суммарного круга был вторым по показателю.
Что думаете про данный метод?
Ну а схематично (это грубый набросок) объект будет выглядеть примерно так:

Круг белого цвета - радиусом 100% - идеальный результат
Красные линии - отрезки-радиусы каждого показателя
Зеленые линии - фрагмент круга (в реалии более закруглен)
Пространство из красного и зеленого отрезка - площадь части круга (1/8 в данном случае), можно назвать лепестком
Желтый круг - сумма площадей из лепестков, образовавшая новый круг.
Интересно, что если мы уберем такие показатели, как доход и расход и будем фактически оценивать только относительные показатели, то у нас будет такие итоговые таблицы
Таблица с расчетом радиуса круга
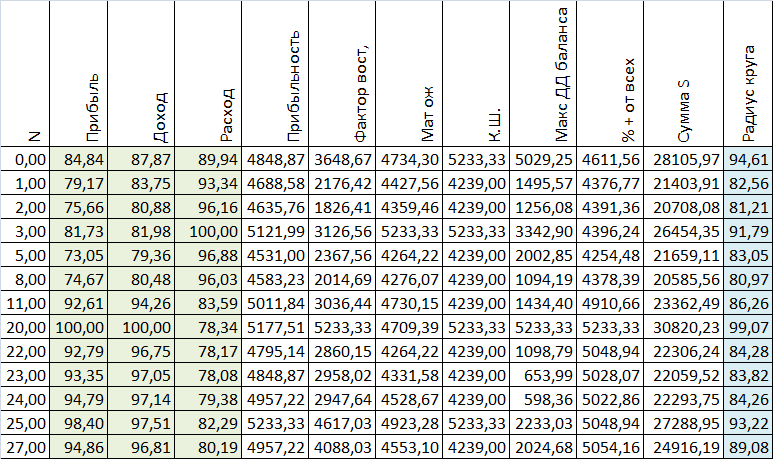
Таблица с расчетом СКО и коэффициента

Ниже прелставлены аналогичные графики, как и ранее.
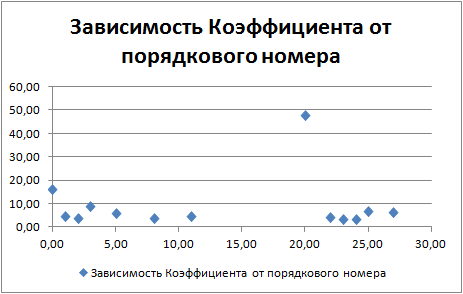
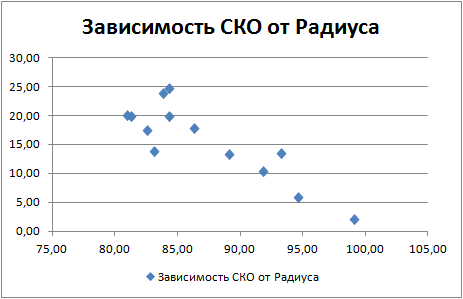
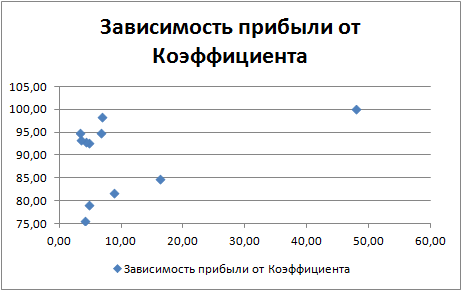
Теперь отчетлево видно, что набор данных под номером 20 вырвался вперед - второе и третье место осталось неизменным.
Видимо, следует ставить жесткий фильтр по доходу/расходу (иным показателям, по которым хотелось бы получить абсолютный вариант), и включать только те показатели, значимость которых велика. Ну а с другой стороны, если нам важен убыток (а именно за счет него в прошлый раз нулевой набор данных победил), то следует его учитывать для поиска более сбалансированного варианта. Так же возможно применение кожффициентов в момент определения доли каждого отрезка в круге, т.е. сейчас все делится на равноменые части, но вполне можно в зависимости от значимости показателя переложить долю, взяв к примеру не 1/6, а (1-0,5)/6, а на другой показатель напротив увеличить вес сделав его (1+0,5)/6.
Интересно, что если мы уберем такие показатели, как доход и расход и будем фактически оценивать только относительные показатели, то у нас будет такие итоговые таблицы
Таблица с расчетом радиуса круга
Таблица с расчетом СКО и коэффициента
Ниже прелставлены аналогичные графики, как и ранее.
Теперь отчетлево видно, что набор данных под номером 20 вырвался вперед - второе и третье место осталось неизменным.
Видимо, следует ставить жесткий фильтр по доходу/расходу (иным показателям, по которым хотелось бы получить абсолютный вариант), и включать только те показатели, значимость которых велика. Ну а с другой стороны, если нам важен убыток (а именно за счет него в прошлый раз нулевой набор данных победил), то следует его учитывать для поиска более сбалансированного варианта. Так же возможно применение кожффициентов в момент определения доли каждого отрезка в круге, т.е. сейчас все делится на равноменые части, но вполне можно в зависимости от значимости показателя переложить долю, взяв к примеру не 1/6, а (1-0,5)/6, а на другой показатель напротив увеличить вес сделав его (1+0,5)/8.
Будем думать.
В данной теме предлагаю обсудить способы анализа объекта, обладающего множеством показателей относительно других объектов, такая потребность возникает при работе с результатами оптимизации. Интересует возможность представления более 5 показателей, так как 5 можно получить (разложить) за счет 3D графика - 3 , цвета и формы маркера - ещё два.
Из известных мне:
1. Самоорганизующаяся карта Кохонена почитать можно тут https://www.mql5.com/ru/articles/283
2. Лепестковая диаграмма
3. Нормирование показателей к 100% (или иное шкалирование) и смещение каждого показателя на 100% относительно последнего (научное название такого подхода не знаю).
4. Кластерный анализ - применим как предварительно сделанный расчет показателей, формерующий коэффициент, который разбили на диапазоны, а сами диапазоны представили в виде фигур разного цвета/формы. Либо опять же нормализация/шкалирование, тогда каждый показатель представлен в виде фигур разных цветов, но при таком подходе надо тратить одну из осей (х или y) на формерование связи - она должна быть порядковым номером в выборке.
5. Есть ещё некий кубизм - сам не применял, но так понимаю, что это вариация на тему 3D
Первая удобна для поиска крупных закономерностей-границ, но при множестве показателей надо делать разные карты иначе - будет замусаренность, а второй вариант не удобен по причине масштабности - т.е. по лепесткам много объектов не разместить - будет так же зашумленность, что сделает анализ невозможным.
В интернете нашел ещё интересные варианты
Что ещё можно использовать для получение визуально большей информации о результатах оптмизации?
Какие программы и алгоритмы позволяют это сделать?
Все это почти бессмысленно, пока не будет волк-форварда в оптимизаторе. А его не будет, т.к. создатель платформы уверен, что он уже есть :)
Разработчик - продавец конструктора, а мы самоделкины - поэтому предполагается, что это можно реализовать самому, и некоторые это пробуют сделать https://www.mql5.com/ru/blogs/post/668374 .
Однако, мне было бы штатного волк-форварда недостаточно, точней даже он не нужен, а нужна именно технология, с помощью которой можно поделить участки графика на разные периоды рынка и уже выделять каждый отдельно, так-как важно учить ТС определять смену такого периода и соответственно перенастраиватся под новые реалии.
- 2016.04.18
- Igor Volodin
- www.mql5.com
Разработчик - продавец конструктора, а мы самоделкины - поэтому предполагается, что это можно реализовать самому, и некоторые это пробуют сделать https://www.mql5.com/ru/blogs/post/668374 .
Однако, мне было бы штатного волк-форварда недостаточно, точней даже он не нужен, а нужна именно технология, с помощью которой можно поделить участки графика на разные периоды рынка и уже выделять каждый отдельно, так-как важно учить ТС определять смену такого периода и соответственно перенастраиватся под новые реалии.
это и есть волк-форвард %)
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
В данной теме предлагаю обсудить способы анализа объекта, обладающего множеством показателей относительно других объектов, такая потребность возникает при работе с результатами оптимизации. Интересует возможность представления более 5 показателей, так как 5 можно получить (разложить) за счет 3D графика - 3 , цвета и формы маркера - ещё два.
Из известных мне:
1. Самоорганизующаяся карта Кохонена почитать можно тут https://www.mql5.com/ru/articles/283
2. Лепестковая диаграмма
3. Нормирование показателей к 100% (или иное шкалирование) и смещение каждого показателя на 100% относительно последнего (научное название такого подхода не знаю).
4. Кластерный анализ - применим как предварительно сделанный расчет показателей, формерующий коэффициент, который разбили на диапазоны, а сами диапазоны представили в виде фигур разного цвета/формы. Либо опять же нормализация/шкалирование, тогда каждый показатель представлен в виде фигур разных цветов, но при таком подходе надо тратить одну из осей (х или y) на формерование связи - она должна быть порядковым номером в выборке.
5. Есть ещё некий кубизм - сам не применял, но так понимаю, что это вариация на тему 3D
Первая удобна для поиска крупных закономерностей-границ, но при множестве показателей надо делать разные карты иначе - будет замусаренность, а второй вариант не удобен по причине масштабности - т.е. по лепесткам много объектов не разместить - будет так же зашумленность, что сделает анализ невозможным.
В интернете нашел ещё интересные варианты
Что ещё можно использовать для получение визуально большей информации о результатах оптмизации?
Какие программы и алгоритмы позволяют это сделать?