Машинное обучение от Яндекс (CatBoost) без изучения Python и R
Aleksey Vyazmikin | 9 ноября, 2020
Предисловие
Уважаемый читатель, в настоящей статье я опишу процесс создания моделей, описывающих закономерность рынка при ограниченном наборе переменных и наличии гипотезы о закономерности его поведения, являющихся результатом работы алгоритма машинного обучения CatBoost от Яндекса. Для получения моделей не потребуется знание таких языков программирования, как Python или R, знание языка MQL5 будут востребованы неглубокие, впрочем, как и в наличии у автора этой статьи, поэтому смею надеяться, что данная статья послужит хорошим руководством для широкого круга заинтересованных лиц, желающих экспериментальным путем оценить возможности машинного обучения и внедрить их в свои разработки. В статье будет изложен минимум академических знаний, за ними я предлагаю обратиться к серии статей от Vladimir Perervenko.
О разнице классического подхода и машинном обучении в трейдинге
Начав активно заниматься трейдингом, многие успевают познакомится с понятием "Торговая стратегия", а если этим трейдерам посчастливилось торговать при помощи продуктов от MetaQuotes Ltd., то вопрос автоматизации торговли быстро выходит на первый план. Если откинуть торговое окружение из кода, то в большей степени все стратегии сводятся к подбору неравенств, как правило цена противопоставляется индикатору на чарте, или же используются показатели индикатора и их границы для активации решения на вход в рынок (открытие позиции) и выход из него.
Каждый, кто занимался разработкой торговой стратегией, мог испытать на себе череду эвристических озарений, которые выражались в добавлении всё новых и новых торговых условий, новых неравенств. Каждое добавление нового условия отражалось изменением финансовых результатов на участке времени, но беря другой интервал времени или переходя на другой тайм фрейм, не говоря уже о смене торгового инструмента, приходило обычно разочарование — торговая система переставала работать и нужно было искать новые и новые закономерности, новые условности, при добавлением каждого из которых снижается число сделок.
Далее, как правило, следует процесс оптимизации переменных неравенств, используемых для принятия торговых решений. Сам процесс такой оптимизации сводится к перебору параметров, часто выходящих за пределы значений исходных данных, либо генерируемые перебором значения неравенств возникают столь редко, что их можно считать скорей статистическим отклонением, чем найденной закономерностью, хотя они и могут улучшить кривую баланса или любую иную оптимизируемую функцию. В результате этих действий при оптимизации параметров происходит подгонка заложенной нами в торговой стратегии эвристики под имеющиеся рыночные данные. Данный подход имеет право на существование, но он не очень эффективен с точки зрения потраченных вычислительных ресурсов на поиск оптимального решения, если наличие переменных и их число значений велико.
Методы машинного обучения позволяют ускорить задачу оптимизации параметров и поиска закономерности между ними за счет генерации правил неравенств и перебора только тех значений переменных, которые существовали на исследуемых данных. В разных способах создания моделей используется разный подход, но суть их в том, что бы ограничить поиск решения задачи по имеющимся для обучения данным. Вместо создание неравенств, отвечающих за логику торговых решений, в машинном обучении предоставляются только значения переменных, содержащих информацию о цене, и факторах, влияющих на её формирование. Такие данные называются признаками (предикторами, фичами).
Признаки должны оказывать влияние на результат, который мы хотим получить, опрашивая их. Результат, как правило, выражается в виде цифрового значения: так для классификации это номер класса, а для регрессии это значение заданной точки. Такой результат обычно называется "целевой" от сокращения "целевая функция". Есть методы машинного обучения без целевой, к примеру — различная кластеризация, но тут мы их затрагивать не будем.
Итак, нам понадобятся предикторы и их целевая.
Предикторы
В качестве предикторов можно использовать время, цену OHLC торгового инструмента и производные от них — разного рода индикаторы. Можно использовать и иные предикторы, такие как экономические показатели, объем сделок, открытый интерес, паттерны в стакане, греки страйков опционов, и иные источники информации, оказывающие влияние на рынок. Я придерживаюсь мнения, что информация должна поступать не только та, что сформировалась к текущему моменту времени, но и та, что описывает движение к этому моменту времени. Строго говоря, предикторы должны давать информацию о движении цены за определенный участок времени.
Я выделяю следующие типы предикторов, описывающих:
- Значимые уровни, которые могут быть:
- Горизонтальными (к примеру, цена открытия торговой сессии)
- Линейными (к примеру, канал регрессии)
- Ломанные (рассчитанные не по линейной функции, к примеру скользящие средние)
- Положение цены и уровня:
- В фиксированном диапазоне в пунктах
- В фиксированном диапазоне в процентах:
- Относительно цены открытия дня или уровня
- Относительно уровня волатильности
- Относительно трендовых отрезков разных TF
- Описывающие колебание цены (волатильность)
- Информация о времени события:
- Число баров, прошедших с момента начала значимого события (от текущего бара или с начала иного периода, к примеру дня)
- Число баров, прошедших с момента окончания значимого события (от текущего бара или с начала иного периода, к примеру дня)
- Число баров, прошедших с начала и окончания события — время длительности события
- Текущее время в виде номера часа, день недели, номер декады, месяца, иное
- Информация о динамики события:
- Число пересечений значимых уровней (в том числе подсчет с учетом частоты затухания/повторения события)
- Максимальная/минимальная цена в моменте первого/последнего события (цена относительная)
- Скорость протекания события в виде пунктов на единицу времени
- Конвертирование данных OHLC в другие координатные плоскости
- Показатели индикаторов типа осциллятор.
Информацию для предикторов можно брать с разных таймфреймов и торговых инструментов, связанных с тем, по которому будет происходить торговля. Конечно, это не все вариации, и можно придумать иные способы предоставления информации, но желательно её предоставить столько, что по ней можно будет воспроизвести основную динамику цены торгуемого инструмента. Плюсом тут является то, что сделав один раз предикторы, их можно в дальнейшем использовать для разных целевых, что значительно упрощает процесс поиска модели, работающей по базовым условиям торговой стратегии.
Целевая
В данной статье будем использовать бинарную целевую классификации, т. е. 0 и 1, это вызвано ограничением, о котором будет сказано позже. Итак, какой смысл можно заложить в ноль и единицу? На ум приходит два варианта:
- первый вариант: "1" — совершать открытие позиции (иное действие) и "0" — не совершать открытие позиции (иное действие);
- второй вариант: "1" — совершать открытие позиции на покупку (первое действие) и "0" — совершать открытие позиции на продажу (второе действие).
Для генерации сигнала целевой можно использовать простые базовые стратегии, которые позволят получать достаточное число сигналов для машинного обучения:
- Открытие позиции при пересечении ценового уровня на покупку или продажу — уровнем может быть любой индикатор;
- Открытие позиции на N баре с начала часа или игнорирования открытия в зависимости от положения цены относительно цены открытия текущего дня;
Отмечу, что желательно найти такую базовую стратегию, которая позволит генерировать примерно сходное количество нулей и единиц, что будет способствовать лучшему обучению.
Инструмент для машинного обучения
В качестве инструмента для машинного обучения предлагаю взять программный продукт CatBoost, последнюю версию которого можно скачать по этой ссылке. Так как в статье идет речь о самодостаточной версии, не требующей иных языков программирования, то достаточно загрузить надо файл последней версии с расширением "exe", например, файл "catboost-0.24.1.exe".
CatBoost — продукт, используемый для решения реальных задач в области машинного обучения известной фирмой Яндекс, что позволяет ожидать поддержку продукта, его улучшение и исправление ошибок, несмотря на то, что код продукта доступен для всех желающих.
Лучше меня расскажут о продукте его создатели на видеоролике ниже или в презентации тут.
Вкратце, CatBoost — строит ансамбль деревьев решений таким образом, чтобы каждое последующее дерево улучшало показатели суммарного вероятностного ответа всех предыдущих деревьев, всё это действие называется градиентным бустингом.
Подготовка данных для машинного обучения
Данные, содержащие предикторы и "целевую", принято называть выборкой, сама же она представляет массив данных, содержащий перечень предикторов в виде столбцов, где каждая строка является моментом снятия показателей и содержит показания предикторов в этот момент. Измерения, записанные в строке, могут быть получены как с определенной частотой времени, так и представлять собой разные объекты, например изображения. Формат файла часто используется типа CSV, в котором описаны условным разделителем показатели столбцов и их заголовки (не обязательно).
В качестве примера будем использовать следующие предикторы:
- Время / часы / доли часов/ день недели;
- Относительное положение баров;
- Осцилляторы.
В качестве целевой возьмем сигнал пересечения скользящего среднего и не касание его на следующем баре, если выше скользящего среднего — покупаем, а ниже — продаем, каждый раз закрываем открытую позицию при приходе сигнала, целевая будет отвечать на вопрос — открывать позицию или нет.
Я не рекомендую использовать скрипт для генерации целевой и предикторов, а воспользоваться советником, что позволит отлавливать логически ошибки в коде при генерации выборки, и более детально имитировать получение данных, как это происходило бы при реальной торговли, в том числе учесть рассинхронизацию открытия разных инструментов по времени, если целевая будет работать на разных инструментах, учесть задержку на получение и обработку информации, предотвратить заглядывание в будущее, отловить перерисовку и недопустимую для обучения логику индикаторов, да и в итоге предикторы должны будут вычисляться на баре в реальном времени при применении модели на практике.
В последнее время в сообществе алготрейдеров, в частности занимающихся машинном обучением, укрепилось мнение, что индикаторы из стандартной поставки бесполезны в большинстве своем, аргументируется данный довод тем, что у них есть существенные недостатки — они запаздывают и являются производной от цены, что подразумевает отсутствие новой информации о цене, а главное — нейросеть способна создать любой расчетный индикатор. Действительно, нейросети способны на очень многое, но за математическим аппаратом, что в большинстве своем был разработан ещё в 20 веке, стоят вычислительные мощности, обладание которыми недоступно частному трейдеру, да и сложность топологии таких сетей не позволит их быстро освоить. Методы машинного обучения, основанные на деревьях решений не могут конкурировать с нейросетями по созданию новых математических сущностей, так как в них не заложен процесс преобразования входных данных, но они эффективней нейросетей в процессе выявления прямых зависимостей, особенно в больших и разнородных массивах данных. По сути предназначение нейросетей — генерация новых паттернов — параметров описывающих рынок, а моделей, построенных на деревьях решений — выявление закономерностей среди множеств таких паттернов. Применяя в качестве предиктора индикаторы из стандартной поставки, мы по сути своих действий берем паттерн, который используют в своей работе тысячи трейдеров на разных биржевых и внебиржевых ранках в разных странах, поэтому есть теоретическое основание полагать, что мы сможем выявить обратную зависимость от индикаторов — поведения трейдеров от показателей индикаторов, влияющего на торгуемый инструмент. Ранее я не использовал осцилляторы, поэтому в этой статье мне будет интересно вместе с читателями посмотреть, что из этого выйдет.
Используются следующие индикаторы из стандартной поставки:
- Accelerator Oscillator,
- Average Directional Movement Index,
- Average Directional Movement Index by Welles Wilder,
- Average True Range,
- Bears Power,
- Bulls Power,
- Commodity Channel Index,
- Chaikin Oscillator,
- DeMarker,
- Force Index,
- Gator,
- Market Facilitation Index,
- Momentum,
- Money Flow Index,
- Moving Average of Oscillator,
- Moving Averages Convergence/Divergence,
- Relative Strength Index,
- Relative Vigor Index,
- Standard Deviation,
- Stochastic Oscillator,
- Triple Exponential Moving Averages Oscillator,
- Williams' Percent Range,
- Variable Index Dynamic Average,
- Volume.
Индикаторы рассчитываются по всем тайм фреймам, доступным в MetaTrader 5, до дневного фрейма включительно.
В процессе написания статьи выяснилось, что показатели индикаторов из списка ниже сильно зависят от даты начала тестирования в терминале, поэтому было принято решение их исключить. Но можно попробовать использовать разницу показателей между разными барами индикатора, что для упрощения тут делать не будем.
Список исключенных индикаторов:
- Awesome Oscillator,
- On Balance Volume,
- Accumulation/Distribution,
Для работы с таблицами CSV воспользуемся замечательной библиотекой "CSV fast.mqh" от Aliaksandr Hryshyn, данная библиотека позволяет:
- Создавать таблицы, считывать их из файла и сохранять их в файл.
- По адресу читать и записывать информацию в любую ячейку таблицы.
- Столбцы таблицы могут хранить разный тип данных, что экономит оперативную память для их размещения.
- Участки таблицы могут копироваться целиком по заданным адресам в заданный адрес указанной иной таблицы.
- Имеется фильтрация по любому столбцу таблицы.
- Имеется многоуровневая сортировка по убыванию и возрастанию таблицы по указанным значениям в ячейках столбца таблицы.
- Есть возможность переиндексации столбцов и их сокрытия.
- И много разных полезных мелочей, делающих работу с таблицей очень приятной и удобной.
Компоненты советника
Базовая стратегия:
В качестве базовой стратегии, генерирующей сигнал, я решил использовать стратегию с простыми условиями — входим в рынок, если соблюдаются следующие условия:
- Цена пересекла индикатор скользящего среднего значения цены,
- Цена первый раз, после соблюдения пункта 1, не коснулась пересеченного скользящего среднего на прошлом баре.
Признаюсь, что это была первая моя стратегия, придуманная во второй половине первого десятилетия 21 века. Несмотря на свою простоту, данная стратегия относится к классу трендовых и показывает хорошие результаты на соответствующих отрезках торговой истории — попробуем с помощью машинного обучения уменьшать число ошибочных входов на флэтовых участках.
Генератор сигнала представим в следующем виде:
//+-----------------------------------------------------------------+ //| Возвращает сигнал на покупку или продажу - базовая стратегия //+-----------------------------------------------------------------+ bool Signal() { //Сбрасываем Флаг блокировки открытия позиций SellPrIMA=false; //Открывать отложенный ордер на продажу BuyPrIMA=false; //Открывать отложенный ордер на покупку SellNow=false; //Открывать ордер с рынка на продажу BuyNow=false; //Открывать ордер с рынка на покупку bool Signal=false;//результат работы функции int BarN=0; //Число баров без касания МА if(iOpen(Symbol(),Signal_MA_TF,0)>MA_Signal(0) && iLow(Symbol(),Signal_MA_TF,1)>MA_Signal(1)) { for(int i=2; i<100; i++) { if(iLow(Symbol(),Signal_MA_TF,i)>MA_Signal(i))break;//На этом цикле уже был отработан сигнал if(iClose(Symbol(),Signal_MA_TF,i+1)<MA_Signal(i+1) && iClose(Symbol(),Signal_MA_TF,i)>=MA_Signal(i)) { for(int x=i+1; x<100; x++) { if(iLow(Symbol(),Signal_MA_TF,x)>MA_Signal(x))break;//На этом цикле уже был отработан сигнал if(iHigh(Symbol(),Signal_MA_TF,x)<MA_Signal(x)) { BarN=x; BuyNow=true; break; } } } } } if(iOpen(Symbol(),Signal_MA_TF,0)<MA_Signal(0) && iHigh(Symbol(),Signal_MA_TF,1)<MA_Signal(1)) { for(int i=2; i<100; i++) { if(iHigh(Symbol(),Signal_MA_TF,i)<MA_Signal(i))break;//На этом цикле уже был отработан сигнал if(iClose(Symbol(),Signal_MA_TF,i+1)>MA_Signal(i+1) && iClose(Symbol(),Signal_MA_TF,i)<=MA_Signal(i)) { for(int x=i+1; x<100; x++) { if(iHigh(Symbol(),Signal_MA_TF,x)<MA_Signal(x))break;//На этом цикле уже был отработан сигнал if(iLow(Symbol(),Signal_MA_TF,x)>MA_Signal(x)) { BarN=x; SellNow=true; break; } } } } } if(BuyNow==true || SellNow==true)Signal=true; return Signal; }
Получение значений предикторов:
Предикторы будем получать с помощью функций — их код приложен к статье. Однако покажу, как просто это сделать для большого числа индикаторов. Отмечу, что будем брать показатели индикаторов в 3 точках — это 1 и 2 сформировавшийся бар, что теоретически позволит найти так называемой сигнальный уровень на индикаторе, и бар со смещением 15, что позволит примерно представлять динамику движения индикатора. Безусловно — это упрощенный вариант получения информации и он может быть значительно расширен.
Все предикторы будем писать в таблицу, формирующуюся в оперативной памяти компьютера. Таблица содержит одну строку, она будет использована в дальнейшем как входной числовой вектор данных в интерпретатор модели CatBoost
#include "CSV fast.mqh"; //Класс по работе с таблицами CSV *csv_CB=new CSV(); //Создаем экземпляр класса таблицы, где будем хранить текущие показатели предикторов //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { CB_Tabl();//Создание таблицы с предикторами return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //|Создание таблицы с предикторами | //+------------------------------------------------------------------+ void CB_Tabl() { //---Столбцы для осцилляторов Size_arr_Buf_OSC=ArraySize(arr_Buf_OSC); Size_arr_Name_OSC=ArraySize(arr_Name_OSC); Size_TF_OSC=ArraySize(arr_TF_OSC); for(int n=0; n<Size_arr_Buf_OSC; n++)SummBuf_OSC=SummBuf_OSC+arr_Buf_OSC[n]; Size_OSC=3*Size_TF_OSC*SummBuf_OSC; for(int S=0; S<3; S++)//Цикл по числу сдвигов { string Shift="0"; if(S==0)Shift="1"; if(S==1)Shift="2"; if(S==2)Shift="15"; for(int T=0; T<Size_TF_OSC; T++)//Цикл по числу тайм фреймов { for(int o=0; o<Size_arr_Name_OSC; o++)//Цикл по числу индикаторов { for(int b=0; b<arr_Buf_OSC[o]; b++)//Цикл по числу буферов индикаторов { name_P=arr_Name_OSC[o]+"_B"+IntegerToString(b,0)+"_S"+Shift+"_"+arr_TF_OSC[T]; csv_CB.Add_column(dt_double,name_P);//Добавляем новую колонку с названием для идентификации предиктора } } } } } //+------------------------------------------------------------------+ //---Вызов расчета предикторов //+------------------------------------------------------------------+ void Pred_Calc() { //---Получение информации с индикаторов типа осциллятор double arr_OSC[]; iOSC_Calc(arr_OSC); for(int p=0; p<Size_OSC; p++) { csv_CB.Set_value(0,s(),arr_OSC[p],false); } } //+------------------------------------------------------------------+ //| Получение значений индикаторов - осцилляторов | //+------------------------------------------------------------------+ void iOSC_Calc(double &arr_OSC[]) { ArrayResize(arr_OSC,Size_OSC); int n=0;//Номер хэндла индикатора int x=0;//Общее число итерация for(int S=0; S<3; S++)//Цикл по числу сдвигов { n=0; int Shift=0; if(S==0)Shift=1; if(S==1)Shift=2; if(S==2)Shift=15; for(int T=0; T<Size_TF_OSC; T++)//Цикл по числу тайм фреймов { for(int o=0; o<Size_arr_Name_OSC; o++)//Цикл по числу индикаторов { for(int b=0; b<arr_Buf_OSC[o]; b++)//Цикл по числу буферов индикаторов { arr_OSC[x++]=iOSC(n, b,Shift); } n++;//Отметим переход к следующему хэндлу индикатора для расчета } } } } //+------------------------------------------------------------------+ //|Получение значения буфера индикатора | //+------------------------------------------------------------------+ double iOSC(int OSC, int Bufer,int index) { double MA[1]= {0.0}; int handle_ind=arr_Handle[OSC];//Хэндл индикатора ResetLastError(); if(CopyBuffer(handle_ind,0,index,1,MA)<0) { PrintFormat("Failed to copy data from the OSC indicator, error code %d",GetLastError()); return(0.0); } return (MA[0]); }
Накопление и разметка выборки:
Для создания и последующего сохранения выборки будем накапливать показатели предикторов, копируя их из таблицы "csv_CB" в таблицу "csv_Arhiv".
Прочитав дату прошлого сигнала и определив цену входа и выхода в сделку, мы можем теперь узнать его исход и присвоить соответствующую метку: "1" — положительный, а "0" — отрицательный, так же пометим тип сделки по сигналу, это поможет в дальнейшем построить график баланса: "1" — покупка и "-1" — продажа. Здесь же делаем расчет финансового результата от торговой операции, для финансового результата используем отдельно столбцы с результатом от покупки и продажи — это удобно, если базовая стратегия чуть сложней, чем описана в настоящей статье, или имеет элементы сопровождения позиции, приводящие к разным финансовым результатом по модулю от торговой сделки.
//+-----------------------------------------------------------------+ //| Функция копирует предикторы в архив //+-----------------------------------------------------------------+ void Copy_Arhiv() { int Strok_Arhiv=csv_Arhiv.Get_lines_count();//Количество строк в таблице int Stroka_Load=0;//Начальная строка в таблице источника int Stolb_Load=1;//Начальный столбец в таблице источника int Stroka_Save=0;//Начальная строка записи в таблице int Stolb_Save=1;//Начальный столбец записи в таблице int TotalCopy_Strok=-1;//Сколько копируем строк из источника. -1 копируем до последней строки int TotalCopy_Stolb=-1;//Сколько копируем столбцов из источника -1 копируем до последнего столбца Stroka_Save=Strok_Arhiv;//копируем в последнюю строку csv_Arhiv.Copy_from(csv_CB,Stroka_Load,Stolb_Load,TotalCopy_Strok,TotalCopy_Stolb,Stroka_Save,Stolb_Save,false,false,false);//Функция копирования //---Посчитаем финансовый результат и сделаем разметку целевой, если это не первый вход в рынок int Stolb_Time=csv_Arhiv.Get_column_position("Time",false);//Узнаем индекс столба "Time" int Vektor_P=0;//Укажем направление входа - "+1" - покупка и "-1" - продажа if(BuyNow==true)Vektor_P=1;//Вход на покупку else Vektor_P=-1;//Вход на продажу csv_Arhiv.Set_value(Strok_Arhiv,Stolb_Time+1,Vektor_P,false); if(Strok_Arhiv>0) { int Stolb_Target_P=csv_Arhiv.Get_column_position("Target_P",false);//Узнаем индекс столба "Time" int Load_Vektor_P=csv_Arhiv.Get_int(Strok_Arhiv-1,Stolb_Target_P,false);//Узнаем тип прошлой операции datetime Load_Data_Start=StringToTime(csv_Arhiv.Get_string(Strok_Arhiv-1,Stolb_Time,false));//Прочтем дату открытия позиции datetime Load_Data_Stop=StringToTime(csv_Arhiv.Get_string(Strok_Arhiv,Stolb_Time,false));//Прочтем дату закрытия позиции double F_Rez_Buy=0.0;//Финансовый результат в случае покупки double F_Rez_Sell=0.0;//Финансовый результат в случае продажи double P_Open=0.0;//Цена открытия позиции double P_Close=0.0;//Цена закрытия позиции int Metka=0;//Метка для целевой P_Open=iOpen(Symbol(),Signal_MA_TF,iBarShift(Symbol(),Signal_MA_TF,Load_Data_Start,false)); P_Close=iOpen(Symbol(),Signal_MA_TF,iBarShift(Symbol(),Signal_MA_TF,Load_Data_Stop,false)); F_Rez_Buy=P_Close-P_Open;//Прошлый вход был на покупку F_Rez_Sell=P_Open-P_Close;//Прошлый вход был на продажу if((F_Rez_Buy-comission*Point()>0 && Load_Vektor_P>0) || (F_Rez_Sell-comission*Point()>0 && Load_Vektor_P<0))Metka=1; else Metka=0; csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+2,Metka,false);//Запишем метку в ячейку csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+3,F_Rez_Buy,false);//Запишем финансовый результат от условной покупки в ячейку csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+4,F_Rez_Sell,false);//Запишем финансовый результат от условной продажи в ячейку csv_Arhiv.Set_value(Strok_Arhiv,Stolb_Time+2,-1,false);//Сделаем отрицательную метку в ячейки для контроля разметки } }
Применение модели:
При помощи класса "Catboost.mqh" от Aliaksandr Hryshyn, который размещен тут, будем интерпретировать данные с помощью полученной модели CatBoost.
Для отладки я добавил таблицу "csv_Chek" — в неё при нашей необходимости будем сохранять показатель модели CatBoost.
//+-----------------------------------------------------------------+ //| Функция применяет предикторы на модели CatBoost //+-----------------------------------------------------------------+ void Model_CB() { CB_Siganl=1; csv_CB.Get_array_from_row(0,1,Solb_Copy_CB,features); double model_result=Catboost::ApplyCatboostModel(features,TreeDepth,TreeSplits,BorderCounts,Borders,LeafValues); double result=Logistic(model_result); if (result<Porog || result>Pridel) { BuyNow=false; SellNow=false; CB_Siganl=0; } if(Use_Save_Result==true) { int str=csv_Chek.Add_line(); csv_Chek.Set_value(str,1,TimeToString(iTime(Symbol(),PERIOD_CURRENT,0),TIME_DATE|TIME_MINUTES)); csv_Chek.Set_value(str,2,result); } }
Сохранение выборки в файл:
Сохраним таблицу по окончанию тестового прохода, укажем разделитель целого в виде запятой
//+------------------------------------------------------------------+ //--Функция записи предикторов в файл //+------------------------------------------------------------------+ void Save_Pred_All() { //---Сохраним предикторы в файл if(Save_Pred==true) { int Stolb_Target=csv_Arhiv.Get_column_position("Target_100",false);//Узнаем индекс столба "Target_100" csv_Arhiv.Filter_rows_add(Stolb_Target,op_neq,-1,true);//Исключим строки с "-1" разметкой целевой csv_Arhiv.Filter_rows_apply(true);//Применим фильтр csv_Arhiv.decimal_separator=',';//Устанавливаем разделитель целого и десятичного числа string name=Symbol()+"CB_Save_Pred.csv";//Имя для файла csv_Arhiv.Write_to_file("Save_Pred\\"+name,true,true,true,true,false,5);//Сохраняем файл с точностью до 5 знака } //---Сохраним показатели модели в файл для отладки - по требованию if(Use_Save_Result==true) { csv_Chek.decimal_separator=',';//Устанавливаем разделитель целого и десятичного числа string name=Symbol()+"Chek.csv";//Имя для файла csv_Chek.Write_to_file("Save_Pred\\"+name,true,true,true,true,false,5);//Сохраняем файл с точностью до 5 знака } }
Пользовательский показатель качества настроек стратегии:
Дальше нам понадобиться искать подходящие настройки индикатора, используемого базовой моделью, поэтому будем считать свой показатель для тестера стратегий, который определяет минимум трейдов и возвращает процент прибыльных сделок. Чем больше объектов для обучения — трейдов — и чем лучше сбалансирована выборка (то есть процент прибыльных сделок ближе к 50%), тем лучше будет проходить обучение. Расчет пользовательского показателя происходит в функции, представленной ниже.
//+------------------------------------------------------------------+ //| Функция расчета пользовательского показателя | //+------------------------------------------------------------------+ double CustomPokazatelf(int VariantPokazatel) { double custom_Pokazatel=0.0; if(VariantPokazatel==1) { double Total_Tr=(double)TesterStatistics(STAT_TRADES); double Pr_Tr=(double)TesterStatistics(STAT_PROFIT_TRADES); if(Total_Tr>0 && Total_Tr>15000)custom_Pokazatel=Pr_Tr/Total_Tr*100.0; } return(custom_Pokazatel); }
Контроль частоты исполнения основной части кода:
Торговые решения нам нужно получать на открытии нового бара, поэтому будем проверять это обстоятельство с помощью функции
//+-----------------------------------------------------------------+ //| Возвращает TRUE, если появился новый бар на текущем ТФ //+-----------------------------------------------------------------+ bool isNewBar() { datetime tm[]; static datetime prevBarTime=0; if(CopyTime(Symbol(),Signal_MA_TF,0,1,tm)<0) { Print("%s CopyTime error = %d",__FUNCTION__,GetLastError()); } else { if(prevBarTime!=tm[0]) { prevBarTime=tm[0]; return true; } return false; } return true; }
Торговые функции:
В советнике используется торговый класс "cPoza6", его идеи были разработаны мной, а основная реализация Vasiliy Pushkaryov. Класс был проверен в работе на Московской бирже, но его концепция до конца не реализована. Поэтому приглашаю всех, кому он кажется удобным, к его доработке, а именно, реализации функций по работе с историей. Для статьи была отключена проверка на тип счета, поэтому будьте внимательны, класс изначально делался для неттинг счетов, но для этого советника он будет работать в достаточной мере для изучения машинного обучения в рамках данной статьи.
Код советника для наглядности без описания функций:
Если не считать ряд вспомогательных функций и вынести выше описанные функции "за скобки", то код советника на данном этапе можно представить в следующем виде:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //---Проверка на корректность значений интерпретации отклика модели if(Porog>=Pridel || Pridel<=Porog)return(INIT_PARAMETERS_INCORRECT); if(Use_Pred_Calc==true) { if(Init_Pred()==INIT_FAILED)return(INIT_FAILED);//Инициализируем хэндлы предикторов CB_Tabl();//Создание таблицы с предикторами Solb_Copy_CB=csv_CB.Get_columns_count()-3;//Количество столбцов в таблице с предикторами } //---объявляем handle_MA_Slow handle_MA_Signal=iMA(Symbol(),Signal_MA_TF,Signal_MA_Period,1,Signal_MA_Metod,Signal_MA_Price); if(handle_MA_Signal==INVALID_HANDLE) { PrintFormat("Failed to create handle of the handle_MA_Signal indicator for the symbol %s/%s, error code %d", Symbol(),EnumToString(Period()),GetLastError()); return(INIT_FAILED); } //---Создадим таблицу для записи показателей модели - для отладки if(Use_Save_Result==true) { csv_Chek.Add_column(dt_string,"Data"); csv_Chek.Add_column(dt_double,"Rez"); } return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if(Save_Pred==true)Save_Pred_All();//Вызываем функцию для записи предикторов в файл delete csv_CB;//Удаляем экземпляр класса delete csv_Arhiv;//Удаляем экземпляр класса delete csv_Chek;//Удаляем экземпляр класса } //+------------------------------------------------------------------+ //| Обработчик события окончания тестирования | //+------------------------------------------------------------------+ double OnTester() { return(CustomPokazatelf(1)); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //---Операции выполняются только при появлении следующего бара if(!isNewBar()) return; //---Получаем информацию по торговому окружению (сделки/ордера) OpenOrdersInfo(); //---Получаем сигнал от базовой стратегии if(Signal()==true) { //---Рассчитываем предикторы if(Use_Pred_Calc==true)Pred_Calc(); //---Применяем модель CatBoost if(Use_Model_CB==true)Model_CB(); //---Если есть открытая позиция в момент сигнала, то закроем её if(PosType!="0")ClosePositions("Close Signal"); //---Откроем новую позицию if (BuyNow==true)OpenPositions(BUY,1,0,0,"Open_Buy"); if (SellNow==true)OpenPositions(SELL,1,0,0,"Open_Sell"); //---Скопируем таблицу с текущими предикторами в архивную таблицу if(Save_Pred==true)Copy_Arhiv(); } }
Внешние настройки советника:
После того как мы ознакомились с кодом функций советника, стоит пояснить, какими настройками он обладает:
1. Настройка действий с предикторами:
- "Рассчитывать предикторы" — устанавливаем "true", если хотим сохранить выборку или применять модель CatBoost на данных;
- "Сохранять предикторы" — устанавливаем "true", если хотим сохранить предикторы в файл для дальнейшего обучения;
- "Тип объема в индикаторах" — устанавливаем тип объема – по тикам или по реальному биржевому объему;
- "Отображать на графике индикаторы предикторов" — если хотим посмотреть на индикаторы, поставим "true" ;
- "Комиссия и спред в пунктах для учета в целевой" — предусмотрено для учета в разметке целевой комиссий и спреда, а так же фильтрации незначительных положительных сделок;
2. Параметры индикатора MA для сигнала базовой стратегии:
- "Период";
- "Тайм Фрейм";
- "Методы скользящих";
- "Ценовая база расчета";
3. Параметры применения модели CatBoost:
- "Применять на данных модель CatBoost" — после обучения и компиляции советника с обученной моделью можно ставить "true";
- "Порог классификации единицы моделью" — порог, при котором значении модели будет интерпретироваться как единица;
- "Предел классификации единицы моделью" — прeдел, до которого значение модели будет идентифицироваться как единица;
- "Сохранять в файл показатель модели" — установить "true", если хотим получить файл с для проверки корректности работы модели.
Поиск подходящих настроек базовой стратегии
Разобравшись с кодом и настройками советника, проведем оптимизацию индикатора базовой стратегии. Выберем пользовательский критерий оценки качества настроек стратегии. В рамках статьи тестирование проводилось на склейке фьючерсных контрактов Si на базовый актив USDRUB_TOM Брокера Открытие, инструмент называется "Si Splice", диапазон дат с 01.06.2014 по 31.10.2020, таймфрейм в настройках M1. Режим моделирования цен OHLC на M1.
Оптимизируемые параметры советника:
- "Период": от 8 до 256, шаг 8;
- "Тайм Фрейм": от M1 до D1, шаг отсутствует;
- "Методы скользящих": от SMA до LWMA, шаг отсутствует;
- "Ценовая база расчета": от CLOSE до WEIGHTED.

Рис. 1 "Результаты оптимизации"
Из полученных результатов нам следует искать и отбирать настройки с высоким пользовательским показателем — желательно от 35%, с числом сделок не менее 15000, а лучше больше, и по желанию можно смотреть на другие эконометрические показатели.
Для того чтобы показать потенциал метода создания торговых стратегий с помощью машинного обучения, я выбрал сет со следующими настройками:
- "Период": 8;
- "Тайм Фрейм": 2 Minutes;
- "Методы скользящих": Linear weighted;
- "Ценовая база расчета": High price.
Сделаем одиночный проход и посмотрим на график.

Рис. 2 "Баланс перед обучением"
В здравом уме никому из трейдеров не придет в голову применять такие настройки стратегии в торговле. Сигнал сильно зашумлен ошибочными входами в сделку — попробуем немного его "почистить". Но в отличии от тех, кто использует перебор множества параметров разных фильтрующих сигнал индикаторов, и тратящих вычислительные ресурсы на области перебора в диапазонах, где показатель индикатора не был или был редко и статистически незначимо, мы будем работать только с теми участками, где показатели индикатора фактически предоставляли информацию.
Изменим настройки советника, что бы посчитать и сохранить предикторы и сделаем одиночный проход:
Настройка действий с предикторами:
- "Рассчитывать предикторы" — устанавливаем "true";
- "Сохранять предикторы" — устанавливаем "true";
- "Тип объема в индикаторах" — устанавливаем тип объема по тикам или по реальному биржевому объему;
- "Отображать на графике индикаторы предикторов" — оставим "false";
- "Комиссия и спред в пунктах для учета в целевой" — установим 50.
Остальные настройки оставим без изменения и сделаем одиночный проход в тестере стратегий. Вычисления будут идти медленней, ведь теперь идет расчет и сбор данных с почти 2000 тысяч буферов индикаторов и вычисление иных предикторов.
Найдем наш файл по адресу работы агента(я работаю в портативном режиме и у меня это адрес "F:\FX\Открытие Брокер_Demo\Tester\Agent-127.0.0.1-3002\MQL5\Files", " 3002" означает, что использовался 3 поток для работы агента) и проверим его содержимое. Если получилось открыть файл с таблицей — всё идет по плану.
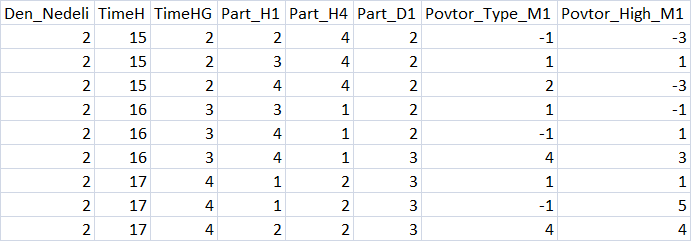
Рис. 3 "Краткое содержание таблицы с предикторами"
Разбиение выборки
Для обучения нам понадобится разбить выборку на 3 части и сохранить их в файлы:
- train.csv — выборка по которой будет происходить обучение
- test.csv — выборка по которой будет контролироваться результат обучения и происходить его остановка
- exam.csv — выборка для оценки результата обучения
Воспользуемся для этих целей скриптом "CB_CSV_to3x.mq5".
Следует указать путь к директории, в которой будет происходить действие по созданию торговой модели и имя файла с выборкой.
Так же создается файл " Test_CB_Setup_0_000000000" в котором указаны номера столбцов с нуля, к которым можно применить условие — отключить лейбл "Auxiliary" и пометить столбец, который является целевой лейбл "Label". Для нашей выборки файл будет иметь следующее содержание:
2408 Auxiliary 2409 Auxiliary 2410 Label 2411 Auxiliary 2412 Auxiliary
Файл будет размещен там же, где и подготовленная скриптом выборка.
Параметры CatBoost
CatBoost имеет множество параметров и настроек, некоторые сильно влияют на результат обучение, а иные слабо, со всеми параметрами для обучения модели можно ознакомится по ссылке. Я отмечу основные параметры (и их ключи в скобках при наличии), оказывающие более выраженное влияние на результаты обучения модели и доступные для настроек в скрипте "CB_Bat":
- "Директория проекта" — тут следует указать путь к директории, где находится выборка до директории "Setup";
- "Имя exe файла CatBoost" — в данной статье использовалась версия файла catboost-0.24.1.exe, если вы скачали с сайта проекта CatBoost более новую версия - укажите её;
- "Тип бустинга (Схема форсирования модели)" (boosting-type) - выбирается два варианта типа бустинга:
- Ordered — Качественное, но медленное обучение на малой выборке.
- Plain — Классическая схема градиентного бустинга.
- "Глубина дерева" (depth) — указывается глубина симметричного дерева решений, разработчики рекомендуют параметры в диапазоне от 6 до 10;
- "Максимальное число итераций (деревьев)" (iterations) — указывается максимальное число последовательно построенных деревьев в модели, число деревьев в модели после обучения может быть меньше, если улучшения модели не происходит на тестовой (валидационной выборке) — число итераций нужно менять пропорционально изменению параметра "Шаг обучения" (learning-rate);
- "Шаг обучения" (learning-rate) — скорость шага по градиенту, т.е. критерий обобщения при построении каждого последующего дерева решений, чем меньше значение, тем медленней и тщательней происходит обучение, но тем дольше оно будет идти и потребуется больше итераций, поэтому меняйте этот показатель вместе "Максимальное число итераций (деревьев)" (iterations);
- "Выбор метода автоматического вычисления веса классов целевой" (class-weights) - данный параметр позволяет улучшить обучение несбалансированной выборки по числу примеров в каждом классе, существуют разные методы этой балансировки:
- None — Все веса классов устанавливаются равными 1
- Balanced — Вес класса на основе общего веса
- SqrtBalanced — Вес класса на основе общего количества объектов в каждом классе
- "Метод выбора весов объектов" (bootstrap-type) - параметр отвечает за способ расчет объектов при поиске предикторов для построения нового дерева, на выбор предлагаются следующие варианты:
- Bayesian;
- Bernoulli;
- MVS;
- No;
- "Диапазон случайных весовых коэффициентов для выбора объектов" (bagging-temperature) - используется, если выбран способ расчет объектов при поиске предикторов для построения нового дерева "Bayesian" - данный параметр добавляет случайности при выборе предикторов для построения дерева, такая случайность позволяет меньше переобучатся (запоминать данные) и лучше выявлять закономерности, парметр может принимать значение от нуля до бесконечности, согласно инструкции.
- "Частота выборки Весов и объектов при построении деревьев" (sampling-frequency) - данный параметр позволяет менять частоту переоценки предикторов для построения дерева, может принимать одно из значений:
- PerTree — Перед построением каждого нового дерева;
- PerTreeLevel — Перед выбором каждого нового раскола дерева;
- "Процент предикторов, анализируемых за шаг обучения 1=100%" (rsm) - данный параметр влияет на число предикторов, которые случайным образом будут взяты для поиска лучших из них при построении отдельного дерева, уменьшение параметра позволяет ускорить процесс обучения, добавить немного случайности, но увеличит число итераций (деревьев) в итоговой модели;
- "L2 регуляризация" (l2-leaf-reg) - в теории данный параметр позволяет уменьшить подгонку под выборку, влияет на качество итоговой модели;
- "Случайное значение (семя) используемое для обучения" (random-seed) - в документации нет четкого описания, обычно это генератор случайных весовых коэффициентов в начале обучения. Данный параметр, из моего опыта, существенно влияет на обучение модели, его необходимо перебирать;
- "Количество случайности для оценки древовидной структуры (random-strength)" - данный параметр влияет на оценку сплита при построении дерева, его рекомендуется перебирать, что может улучшить качество модели;
- "Число шагов по градиенту для выбора значения в листе" (leaf-estimation-iterations)- когда уже выбрано и построено дерево считаются значения в листьях, их можно считать вперед на несколько шагов по градиенту - данный параметр влияет на качество и скорость обучения;
- "Режим квантования для числовых объектов" (feature-border-type) - данный параметр отвечает за разные алгоритмы квантования (построения сетки) на объектах выборки, параметр сильно влияет на обучаемость модели, доступны следующие варианты:
- Median,
- Uniform,
- UniformAndQuantiles,
- MaxLogSum,
- MinEntropy,
- GreedyLogSum,
- "Число разбиений сетки на диапазоны" (border-count) — данный параметр отвечает за число разбиений всего диапазона показателей каждого предиктора, по факту число разбиений бывает меньше, чем больше параметр, тем уже сетка, а значит меньше процент примеров, данный параметр стоит подбирать — существенно влияет на качество и скорость обучения;
- "Сохранить файл с границами" (output-borders-file) — существует возможность сохранения сеток квантования (разбиения) для отдельного анализа или использования при последующем обучении - влияет на скорость обучения, так как сохраняет в файл данные при создании каждой новой модели;
- "Функция метрики оценки ошибки для корректировки обучения" (loss-function) — выбирается функция по которой происходит оценка ошибки при обучении модели - особой разницы, влияющей на качество, не заметил, но существует два варианта:
- Logloss;
- CrossEntropy;
- "Число деревьев без улучшения для остановки обучения" (od-wait) — название полностью отражает содержание, если обучение быстро прекращается, то стоит попробовать увеличить число ожидания на порядок - бывают выборки сильно отличающиеся для обучения и контроля тестирования(валидации), и это им может помочь для обучения. Так же следует увеличивать этот параметр при изменении скорости обучения, чем меньше скорость, тем дольше ждем улучшений до остановки обучения;
- "Функция метрики оценки ошибки для остановки обучения" (eval-metric) — позволяет указать метрику из списка по которой будет произведено усечение дерева и остановка обучения, доступны следующие метрики:
- Logloss;
- CrossEntropy;
- Precision;
- Recall;
- F1;
- BalancedAccuracy;
- BalancedErrorRate;
- MCC;
- Accuracy;
- CtrFactor;
- NormalizedGini;
- BrierScore;
- HingeLoss;
- HammingLoss;
- ZeroOneLoss;
- Kappa;
- WKappa;
- LogLikelihoodOfPrediction;
- "Объект перебора" — позволяет выбрать параметр модели для перебора, доступны следующие параметры:
- Не перебирать;
- Random-seed — Случайное значение (семя) используемое для обучения;
- Random-strength — Количество случайности для оценки древовидной структуры;
- Border-count — Число разбиений сетки на диапазоны;
- l2-Leaf-reg — L2 регуляризация;
- Bagging-temperature — Диапазон случайных весовых коэффициентов для выбора объектов;
- Leaf_estimation_iterations — Число шагов по градиенту для выбора значения в листе;
- "Начальное значение переменной" — устанавливаем начальное значение переменной для перебора;
- "Конечное значение переменной" — устанавливаем конечное значение переменной для перебора;
- "Шаг изменения" — устанавливаем шаг изменения значения переменной для перебора;
- "Тип представления результатов классификации"(prediction-type) — выбираем, как будут записаны ответы модели на выборках - не оказывает влияния на обучение и используется после обучения при применении модели на выборках:
- Probability — Вероятность;
- Class — Класс;
- RawFormulaVal;
- Exponent;
- LogProbability;
- "Число деревьев модели, 0 - все" — число деревьев в модели, которые будут использованы для классификации - позволяет оценить изменение качества классификации при применении модели на выборках;
- "Способ анализа модели" (fstr-type) — доступны разные способы анализа модели, позволяющие оценить значимость предикторов для конкретной модели - предлагаю читателям изучить их самостоятельно, и поделится результатами применения со мной, доступны следующие варианты:
- PredictionValuesChange — как изменяется прогноз при изменении значения объекта;
- LossFunctionChange — как изменяется прогноз при исключении объекта;
- InternalFeatureImportance;
- Interaction;
- InternalInteraction;
- ShapValues.
Скрипт позволяет обеспечить перебор ряда параметров настройки модели, для этого нужно выбрать Объект перебора отличный от "NONE" и указать начальное значение переменной, конечное значение переменной и шаг изменения параметра.
Стратегия обучения
Стратегию обучения я разделяю на три этапа:
- Базовые настройки — параметры, отвечающие за глубину и количество деревьев в модели, а так же за темп обучения, вес классов в модели и иные настройки для начала процесса обучения. Эти параметры, как правило, не перебираются, в большинстве случаев настроек по умолчанию, формируемых скриптом, будет достаточно.
- Поиск оптимальной сетки разбиения параметров — CatBoost делает предобработку таблицы с предикторами для перебора диапазона значений по границам сетки, поэтому следует найти ту сетку, на которой происходит лучшее обучение. Имеет смысл перебрать все типы сеток с диапазоном 8-512 — я использую увеличения шага на каждом значении — 8, 16, 32 и так далее.
- Настраиваем снова скрипт, устанавливаем в настройках найденную сетку разбиения (квантования) предикторов и можем перебирать остальные доступные параметры - я обычно ограничиваюсь "Seed" от 1-1000.
В рамках данной статьи, используем для первого этапа "стратегии обучения" настройки скрипта "CB_Bat" по умолчанию, метод разбиения установим "MinEntropy" и сделаем перебор сетки с 16 до 512 с шагом 16.
Для настроек вышеописанных параметров воспользуемся скриптом "CB_Bat", который создаст текстовые файлы, содержащие необходимые ключи для обучения моделей и вспомогательный файл:
- _00_Dir_All.txt - вспомогательный файл
- _01_Train_All.txt - Настройки для обучения
- _02_Rezultat_Exam.txt - Настройки для записи классификации моделями экзаменационной выборки
- _02_Rezultat_test.txt - Настройки для записи классификации моделями тестовой выборки
- _02_Rezultat_Train.txt - Настройки для записи классификации моделями учебной выборки
- _03_Metrik_Exam.txt - Настройки для записи метрик каждого дерева моделей экзаменационной выборки
- _03_Metrik_Test.txt - Настройки для записи метрик каждого дерева моделей тестовой выборки
- _03_Metrik_Train.txt - Настройки для записи метрик каждого дерева моделей учебной выборки
- _04_Analiz_Exam.txt - Настройки для записи оценки значимости предикторов моделей экзаменационной выборки
- _04_Analiz_Test.txt - Настройки для записи оценки значимости предикторов моделей тестовой выборки
- _04_Analiz_Train.txt - Настройки для записи оценки значимости предикторов моделей учебной выборки
Можно было бы создать один файл, который выполнял бы действия после обучения последовательно, но для оптимальной загрузки процессора, что особенно актуально было в ранних версиях CatBoost, я использую запуск сразу 6 файлов после обучения.
Обучение моделей
После того, как мы получили файлы, переименуем файл "_00_Dir_All.txt" на "_00_Dir_All.bat" и запустим его — он создаст необходимые директории для размещения моделей и изменит расширение оставшихся файлов на "bat".
Теперь у нас в директории проекта имеется директория "Setup" со следующим содержанием:
- _00_Dir_All.bat — вспомогательный файл
- _01_Train_All.bat — Настройки для обучения
- _02_Rezultat_Exam.bat — Настройки для записи классификации моделями экзаменационной выборки
- _02_Rezultat_test.bat — Настройки для записи классификации моделями тестовой выборки
- _02_Rezultat_Train.bat — Настройки для записи классификации моделями учебной выборки
- _03_Metrik_Exam.bat — Настройки для записи метрик каждого дерева моделей экзаменационной выборки
- _03_Metrik_Test.bat — Настройки для записи метрик каждого дерева моделей тестовой выборки
- _03_Metrik_Train.bat — Настройки для записи метрик каждого дерева моделей учебной выборки
- _04_Analiz_Exam.bat — Настройки для записи оценки значимости предикторов моделей экзаменационной выборки
- _04_Analiz_Test.bat — Настройки для записи оценки значимости предикторов моделей тестовой выборки
- _04_Analiz_Train.bat — Настройки для записи оценки значимости предикторов моделей учебной выборки
- catboost-0.24.1.exe — Исполняемый файл для обучения моделей CatBoost
- train.csv — выборка по которой будет происходить обучение
- test.csv — выборка по которой будет контролироваться результат обучения и происходить его остановка
- exam.csv — выборка для оценки результата обучения
- Test_CB_Setup_0_000000000//Файл с информацией о столбцах выборки, используемых для обучения
Запускаем файл "_01_Train_All.bat" и наблюдаем начавшийся процесс обучения.
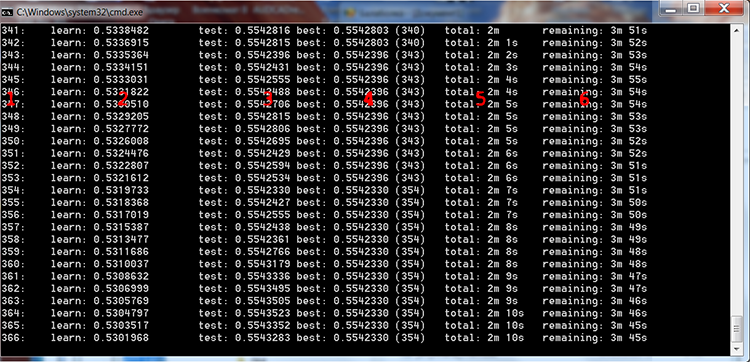
Рис. 4 "Процесс обучения CatBoost"
Красным цветом на рисунке выше я пронумеровал столбцы для описания значений в них:
- Число построенных деревьев — равно числу итераций;
- Результат вычисления выбранной функции потерь на выборке для обучения;
- Результат вычисления выбранной функции потерь на выборке для контроля;
- Лучший результат вычисления выбранной функции потерь на выборке для контроля, в скобках указан номер итерации;
- Фактическое время, прошедшее с момента начала обучения модели;
- Расчетное время, оставшееся до конца обучения, если будут обучены все деревья, установленные настройками.
Если мы выбрали в настройках скрипта диапазон перебора, то модели в цикле будут обучаться столько раз, сколько это требуется, согласно содержимому файла:
FOR %%a IN (*.) DO ( catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_16\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 16 --feature-border-type MinEntropy --output-borders-file quant_4_00016.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_32\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type MinEntropy --output-borders-file quant_4_00032.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_48\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 48 --feature-border-type MinEntropy --output-borders-file quant_4_00048.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_64\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 64 --feature-border-type MinEntropy --output-borders-file quant_4_00064.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_80\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 80 --feature-border-type MinEntropy --output-borders-file quant_4_00080.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_96\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 96 --feature-border-type MinEntropy --output-borders-file quant_4_00096.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_112\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 112 --feature-border-type MinEntropy --output-borders-file quant_4_00112.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_128\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 128 --feature-border-type MinEntropy --output-borders-file quant_4_00128.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_144\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 144 --feature-border-type MinEntropy --output-borders-file quant_4_00144.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_160\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 160 --feature-border-type MinEntropy --output-borders-file quant_4_00160.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 )
После окончания обучения запустим сразу 6 оставшихся bat файлов для получения результатов обучения в виде меток и статистических показателей.
Экспресс оценка результатов обучения
Для получения метрических показателей моделей и их финансового результата воспользуемся скриптом "CB_Calc_Svod.mq5".
Данный скрипт имеет фильтр для отбора моделей по итоговому балансу на экзаменационной выборке, если баланс выше заданной величины, то по выборке может быть построен график баланса и преобразована в mqh и помещена в отдельную директорию проекта модель CatBoost.
После запуска скрипта ждем окончания его работы, должна создастся директория "Analiz", в которой будет файл "CB_Svod.csv" и графики баланса по названию модели, если их построение было выбрано в настройках, а так же директория "Models_mqh", где находятся сами модели, конвертированные в формат mqh.
Открыв файл "CB_Svod.csv" мы увидим метрические показатели каждом модели по каждой выборке отдельно, включая финансовый результат.
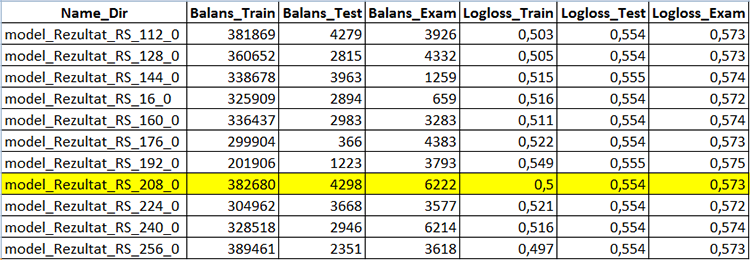
Рис. 5 "Фрагмент таблицы с результатами построения моделей - файл "CB_Svod.csv""
Выберем понравившуюся модель из поддиректории "Models_mqh" директории в которой проходило обучение наших моделей, и поместим в директорию с советником. Поставим знак комментария "//" перед строкой с пустыми буферами в самом начале кода советника, как в коде ниже, и теперь нам осталось только подключить файл с моделью в нашем советнике:
//Если есть модель CatBoost в файле mqh, то нужно комментировать эту строку ниже: //uint TreeDepth[];uint TreeSplits[];uint BorderCounts[];float Borders[];double LeafValues[];double Scale[];double Bias[]; #include "model_RS_208_0.mqh"; //Файл с моделью
После компиляции советника переводим настройку "Применять на данных модель CatBoost" в "true", отключаем сохранение выборки, и запускаем тестер стратегий со следующими параметрами.
1. Настройка действий с предикторами:
- "Рассчитывать предикторы" — устанавливаем "true";
- "Сохранять предикторы" — устанавливаем "false";
- "Тип объема в индикаторах" — устанавливаем тот тип объёма, что был и при обучении;
- "Отображать на графике индикаторы предикторов" — установим "false";
- "Комиссия и спред в пунктах для учета в целевой" — оставим значение, что уже стоит - оно не влияет на готовую модель;
2. Параметры индикатора MA для сигнала базовой стратегии:
- "Период": 8;
- "Тайм Фрейм": 2 Minutes;
- "Методы скользящих": Linear weighted;
- "Ценовая база расчета": High price.
3. Параметры применения модели CatBoost:
- "Применять на данных модель CatBoost" — установим "true";
- "Порог классификации единицы моделью" — оставим 0,5;
- "Предел классификации единицы моделью" — оставим 1;
- "Сохранять в файл показатель модели" — оставим "false".
Получаем следующий результат за весь период выборки.
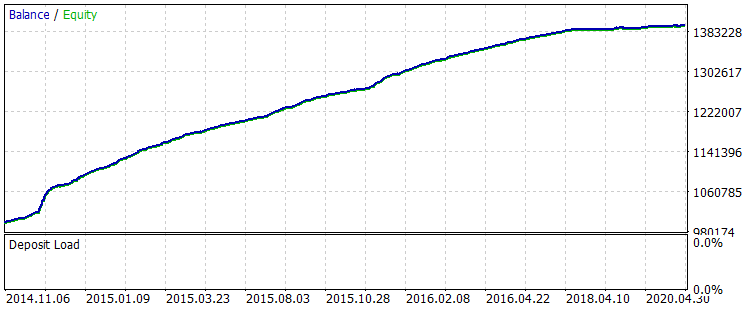
Рис. 6 "Баланс после обучения за период с 01.06.2014 по 31.10.2020
Сравним два графика баланса на интервале (с 01.08.2019 по 31.10.2020) вне обучения, что соответствует выборке "exam.csv" до обучения и после.
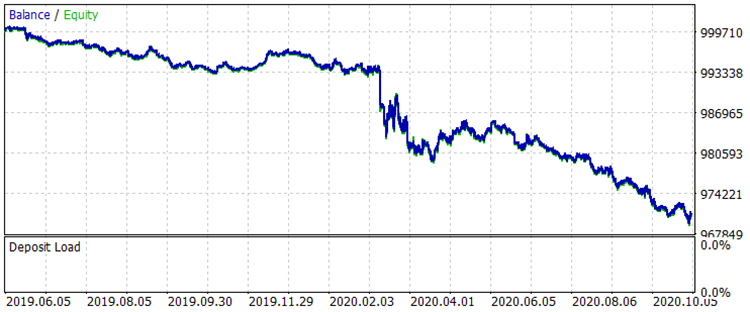
Рис. 7 "Баланс до обучения за период с 01.08.2019 по 31.10.2020"
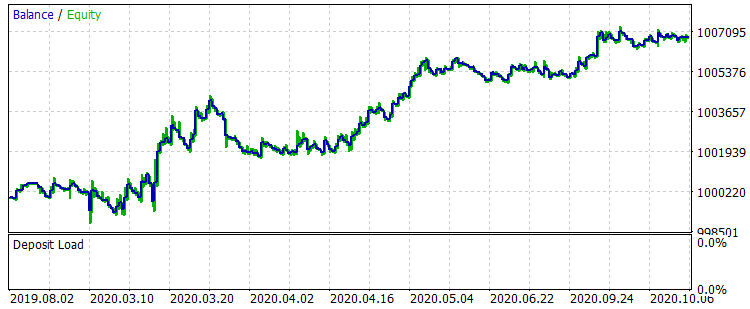
Рис. 8 "Баланс после обучения за период с 01.08.2019 по 31.10.2020"
Результаты не выдающиеся, но можно отметить, что главное правило в трейдинге "не терять деньги" соблюдается. Даже если бы выбор пал не на эту модель, а на другую из файла "CB_Svod.csv", то всё равно эффект был бы положительным, ведь финансовый результат самой неудачной модели, что мы получили, составляет -25 пунктов, а средний показатель финансового результата всех моделей составляет 3889,9 пунктов.
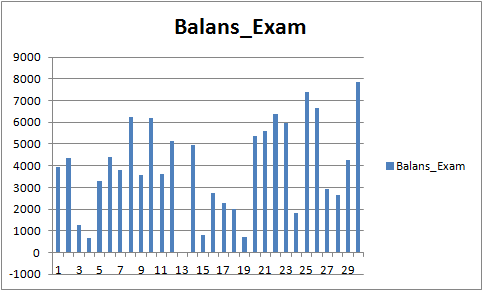
Рис. 9 "Финансовый результат обученных моделей за период с 01.08.2019 по 31.10.2020"
Анализ предикторов
В каждой директории модели (у автора MQL5\Files\CB_Stat_03p50Q\Rezultat\RS_208\result_4_Test_CB_Setup_0_000000000) имеется 3 файла:
- Analiz_Train — Анализ значимости предикторов на выборке обучения
- Analiz_Test — Анализ значимости предикторов на тестовой(валидационной) выборке
- Analiz_Exam — Анализ значимости предикторов на экзаменационной(вне обучения) выборке
В зависимости от выбранной настройки "Способ анализа модели" при формировании файлов для обучения, содержание будет разным, рассмотрим содержание при настройке "PredictionValuesChange".
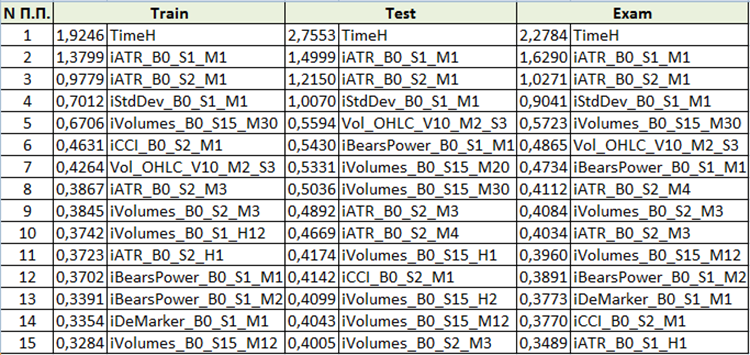
Рис. 10 "Сводная таблица анализа значимости предикторов"
Исходя из оценки важности предикторов можно сделать вывод, что первые 4 предиктора являются устойчиво важными для полученной модели. Стоит заметить, что важность предикторов зависит не только от самой модели, но и от выборки, на которой она применяется. Ведь если у предиктора не было в этой выборке достаточно значений, по которому он имеет сплит (разделение) при построении дерева, то он не может объективно быть оценен. Для примерного понимания значимости предикторов данный метод подходит, но следует с ним быть внимательней при работе с выборками на основе торговых инструментов.
Выводы
- Методы машинного обучения, такие как градиентный бустинг, могут быть не менее эффективны, чем бесконечный перебор параметров и ручное создание дополнительных торговых условий для улучшения показателей стратегии.
- Индикаторы, идущие с поставкой MetaTrader 5, могут быть полезны для машинного обучения.
- CatBoost — качественная библиотека, имеющая свою обертку, позволяющая эффективно использовать градиентный бустинг без изучения Python и R.
Послесловие
В данной статье я постарался привлечь интерес читателя к машинному обучению. Очень надеюсь, что после детального описания методики и предоставления инструментов для её воспроизведения, появятся новые энтузиасты машинного обучения. Предлагаю объединиться для поиска новых идей в данном направлении, в том числе для поиска предикторов, ведь не стоит забывать, что качество модели зависит от входных данных и целевой, а объединение усилий в их изыскании позволит быстрей добиться желаемого результата.
Приветствуется описание моих ошибок, как в статье, так и в коде.