Градиентный бустинг (CatBoost) в задачах построения торговых систем. Наивный подход
Maxim Dmitrievsky | 4 ноября, 2020
Введение
Градиентный бустинг является сильным алгоритмом машинного обучения. Суть метода заключается в построении ансамбля слабых моделей (например, деревьев принятия решений), в которых (в отличие от бэггинга) модели строятся не независимо (параллельно), а последовательно. Говоря простым языком, это означает, что следующее дерево учится на ошибках предыдущего, затем этот процесс повторяется, наращивая количество слабых моделей. Таким образом, получается сильная модель, способная к обобщению на разнородных данных. В данном эксперименте я решил использовать библиотеку CatBoost от компании Яндекс, как одну из самых популярных, наряду с XGboost и LightGBM.
Целью статьи является демонстрация рабочего цикла создания модели на основе машинного обучения, состоящего из нескольких этапов:
- получение и предобработка данных,
- обучение модели на подготовленных данных,
- тестирование модели в кастомном тестере стратегий,
- перенос модели в MetaTrader 5.
Для подготовки данных и обучения модели используется язык программирования Python и библиотека MetaTrader5.
Подготавливаем данные
Импортируем необходимые Python модули:
import MetaTrader5 as mt5 import pandas as pd import numpy as np from datetime import datetime import random import matplotlib.pyplot as plt from catboost import CatBoostClassifier from sklearn.model_selection import train_test_split mt5.initialize() # check for gpu devices is availible from catboost.utils import get_gpu_device_count print('%i GPU devices' % get_gpu_device_count())
Затем инициализируем глобальные переменные:
LOOK_BACK = 250 MA_PERIOD = 15 SYMBOL = 'EURUSD' MARKUP = 0.0001 TIMEFRAME = mt5.TIMEFRAME_H1 START = datetime(2020, 5, 1) STOP = datetime(2021, 1, 1)
Параметры, по порядку, отвечают за:
- look_back — глубина анализируемой истории, в барах;
- ma_period — период скользящего среднего для вычисления ценовых приращений;
- symbol — котировки по какому символу следует загрузить из терминала MetaTrader 5;
- markup — размер спреда для кастомного тестера;
- timeframe — тайм-фрейм, данные которого будут загружены;
- start, stop — диапазон данных.
Напишем функцию, непосредственно получающую сырые данные и создающую датафрейм, содержащий необходимые для обучения модели колонки:
def get_prices(look_back = 15): prices = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START, STOP), columns=['time', 'close']).set_index('time') # set df index as datetime prices.index = pd.to_datetime(prices.index, unit='s') prices = prices.dropna() ratesM = prices.rolling(MA_PERIOD).mean() ratesD = prices - ratesM for i in range(look_back): prices[str(i)] = ratesD.shift(i) return prices.dropna()
Функция получает цены закрытия за указанный временной интервал указанного тайм-фрейма и вычисляет скользящее среднее, после чего считает приращения (разницу между ценами и скользящим средним). На финальном этапе создаются дополнительные колонки со смещенными рядами на глубину look_back, что означает добавление дополнительных (запаздывающих, лаговых) признаков в модель.
Например, для look_back = 10 датафрейм будет содержать 10 дополнительных столбцов с приращениями цен:
>>> pr = get_prices(look_back=LOOK_BACK) >>> pr close 0 1 2 3 4 5 6 7 8 9 time 2020-05-01 16:00:00 1.09750 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 0.000285 2020-05-01 17:00:00 1.10074 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 2020-05-01 18:00:00 1.09976 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 2020-05-01 19:00:00 1.09874 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 2020-05-01 20:00:00 1.09817 0.000759 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 ... ... ... ... ... ... ... ... ... ... ... ... 2020-11-02 23:00:00 1.16404 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 -0.000326 0.000501 2020-11-03 00:00:00 1.16392 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 -0.000326 2020-11-03 01:00:00 1.16402 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 -0.000773 2020-11-03 02:00:00 1.16423 0.000465 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 -0.000344 2020-11-03 03:00:00 1.16464 0.000885 0.000465 0.000270 0.000217 0.000400 0.000105 -0.000581 -0.001212 -0.000999 -0.000547 [3155 rows x 11 columns]
Желтым маркером помечено, что каждый столбец имеет тот же набор данных, но со смещением. Таким образом, каждая строка является отдельным обучающим примером.
Создаем обучающие метки (случайный семплинг)
Обучающие примеры являются наборами признаков (или фичей) и соответствующим им метками. На выход модели должна подаваться некоторая информация, которую она должна научиться предсказывать. Мы рассмотрим случай бинарной классификации, модель будет предсказывать вероятность отнесения обучающего примера к классу 0 или 1. Логически вытекает, что нулям и единицам можно присвоить направления сделок: покупка или продажа. Иными словами, модель должна научиться прогнозировать направление сделки при заданных параметрах среды (наборе признаков).
def add_labels(dataset, min, max): labels = [] for i in range(dataset.shape[0]-max): rand = random.randint(min, max) if dataset['close'][i] >= (dataset['close'][i + rand]): labels.append(1.0) elif dataset['close'][i] <= (dataset['close'][i + rand]): labels.append(0.0) else: labels.append(0.0) dataset = dataset.iloc[:len(labels)].copy() dataset['labels'] = labels dataset = dataset.dropna() return dataset
Функция add_labels случайным образом (в диапазоне min, max) задает продолжительность каждой сделки, в барах. Меняя максимальную и минимальную продолжительность, можно менять частоту семплирования сделок. Таким образом, если текущая цена больше будущей на rand баров вперед, то это метка на продажу (единица). В противоположной ситуации метка равна нолю. Посмотрим, как будет выглядеть датасет после применения к нему этой функции:
>>> pr = add_labels(pr, 10, 25) >>> pr close 0 1 2 3 4 5 6 7 8 9 labels time 2020-05-01 16:00:00 1.09750 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 0.000285 1.0 2020-05-01 17:00:00 1.10074 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 0.000566 1.0 2020-05-01 18:00:00 1.09976 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 0.001190 1.0 2020-05-01 19:00:00 1.09874 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 0.001477 1.0 2020-05-01 20:00:00 1.09817 0.000759 0.001577 0.002900 0.004227 0.001405 0.002169 0.001600 0.002595 0.002794 0.002442 1.0 ... ... ... ... ... ... ... ... ... ... ... ... ... 2020-10-29 20:00:00 1.16700 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 -0.002719 -0.002075 1.0 2020-10-29 21:00:00 1.16743 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 -0.002719 0.0 2020-10-29 22:00:00 1.16731 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 -0.003769 0.0 2020-10-29 23:00:00 1.16740 -0.001648 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 -0.003475 0.0 2020-10-30 00:00:00 1.16695 -0.001655 -0.001648 -0.002276 -0.002699 -0.003651 -0.005429 -0.005767 -0.006750 -0.004699 -0.004328 1.0
Была добавлена колонка labels, которая содержит номер класса (0 или 1) для покупки и продажи соответственно. Теперь каждый обучающий пример или набор признаков (здесь их 10) имеет свою собственную метку, говорящую, при каких условиях нужно покупать, а при каких продавать (или, к какому классу он относится). Модель должна иметь способность запомнить и обобщить эти примеры, что будет рассмотрено далее.
Пишем кастомный тестер
Поскольку речь идет о торговой системе, было бы неплохо иметь под рукой тестер для оперативного тестирования модели. Пример такого тестера приведен ниже:
def tester(dataset, markup = 0.0): last_deal = int(2) last_price = 0.0 report = [0.0] for i in range(dataset.shape[0]): pred = dataset['labels'][i] if last_deal == 2: last_price = dataset['close'][i] last_deal = 0 if pred <=0.5 else 1 continue if last_deal == 0 and pred > 0.5: last_deal = 1 report.append(report[-1] - markup + (dataset['close'][i] - last_price)) last_price = dataset['close'][i] continue if last_deal == 1 and pred <=0.5: last_deal = 0 report.append(report[-1] - markup + (last_price - dataset['close'][i])) last_price = dataset['close'][i] return report
Функция тестера принимает датасет и маркап (опционально) и проходится по всему датасету точно так же, как это происходит в тестере MetaTrader 5. На каждом новом баре проверяется сигнал (метка) и, при изменении её на противоположную, сделка переворачивается. Таким образом, сигнал на продажу является сигналом на закрытие позиции на покупку и открытия позиции на продажу. Теперь можно протестировать полученный выше датасет:
pr = get_prices(look_back=LOOK_BACK) pr = add_labels(pr, 10, 25) rep = tester(pr, MARKUP) plt.plot(rep) plt.show()
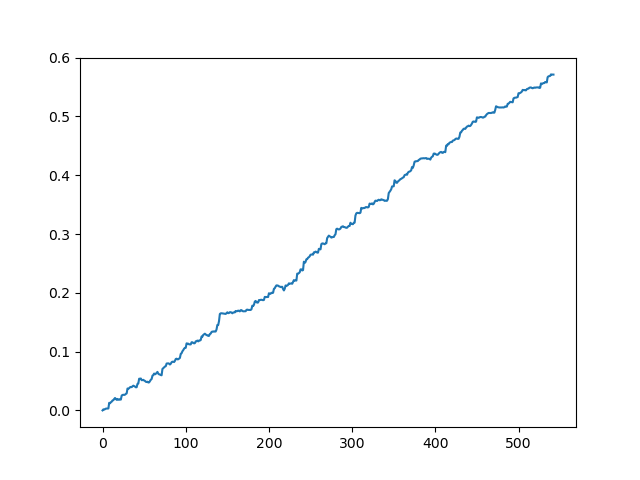
Тестирование исходного датасета без спреда
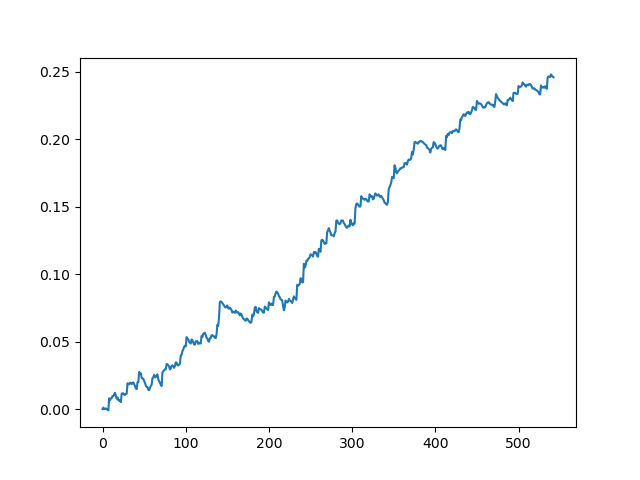
Тестирование исходного датасета со спредом 70 пятизначных пунктов
Мы получили некую идеализированную картину (как бы нам хотелось, чтобы было). Поскольку семплинг меток является случайным и зависит от диапазона параметров, отвечающих за минимальную и максимальную продолжительность сделок, то кривые всегда будут разными, однако, все они будут показывать хороший прирост в пунктах (по оси Y) и разное количество сделок (по оси Х).
Обучаем модель CatBoost
Перейдем, непосредственно, к обучению модели. Сначала нужно разделить датасет на тренировочную и валидационную подвыборки. Такое разделение необходимо для уменьшения переобучения модели. В то время как модель продолжает обучаться на тренировочной подвыборке, минимизируя ошибку классификации, ошибка также замеряется на валидационном сабсете. При большой разнице этих ошибок можно говорить, что модель переобучена, тогда как близкие значения говорят о том, что модель обучается хорошо.
#splitting on train and validation subsets X = pr[pr.columns[1:-1]] y = pr[pr.columns[-1]] train_X, test_X, train_y, test_y = train_test_split(X, y, train_size = 0.5, test_size = 0.5, shuffle=True)
Разобьём данные на два датасета равной длины, предварительно случайно перемешав обучающие примеры. Далее необходимо создать и обучить модель:
#learning with train and validation subsets model = CatBoostClassifier(iterations=1000, depth=6, learning_rate=0.01, custom_loss=['Accuracy'], eval_metric='Accuracy', verbose=True, use_best_model=True, task_type='CPU') model.fit(train_X, train_y, eval_set = (test_X, test_y), early_stopping_rounds=50, plot=False)
Модель принимает ряд параметров, здесь показаны не все параметры. Для более тонкой настройке модели вы можете обратиться к документации, но, как правило, она не требуется. CatBoost хорошо работает из коробки, с минимальным тюнингом.
Кратко опишем параметры модели:
- iterations — максимальное количество деревьев в модели. Поскольку с каждой итерацией модель наращивает количество слабых моделей (деревьев), то этот параметр следует выставлять с запасом. Из практики, для данного конкретного примера, 1000 итераций являются достаточными и даже избыточными.
- depth — глубина каждого дерева. Чем меньше, тем модель получается более грубой, уменьшая количество сделок на выходе. Глубина в диапазоне 6-10 является оптимальным решением.
- learning_rate — величина шага градиента, принцип тот же что в нейронных сетях. Разумный диапазон параметров 0.01 - 0.1. Чем ниже, тем дольше модель обучается, но может найти более оптимальный вариант.
- custom_loss, eval_metric — метрика, по которой происходит оценка модели. Для классификации классической метрикой является accuracy
- use_best_model — на каждом шаге обучения модель оценивает accuracy, который может изменяться со временем. Данный флаг позволяет сохранять модель с наименьшей ошибкой, иначе будет сохранена модель, полученная на последней итерации.
- task_type — позволяет обучать модель на видеокарте, по умолчанию 'CPU'. Актуально только в случае очень больших данных, иначе на ядрах видеокарты обучается медленнее, чем на процессоре.
- early_stopping_rounds — в модель встроен так называемый overfitting detector (детектор переобучения), который работает по простому принципу. Если метрика перестала уменьшаться\увеличиваться (в случае accuracy — увеличиваться) в течение заданного количества итераций, то обучение останавливается.
После запуска обучения, в консоль будет выводиться текущее состояние модели, на каждой итерации:
170: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.2s remaining: 21.5s 171: learn: 1.0000000 test: 0.7726330 best: 0.7767795 (165) total: 11.2s remaining: 21.4s 172: learn: 1.0000000 test: 0.7733241 best: 0.7767795 (165) total: 11.3s remaining: 21.3s 173: learn: 1.0000000 test: 0.7740152 best: 0.7767795 (165) total: 11.3s remaining: 21.3s 174: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.4s remaining: 21.2s 175: learn: 1.0000000 test: 0.7726330 best: 0.7767795 (165) total: 11.5s remaining: 21.1s 176: learn: 1.0000000 test: 0.7712509 best: 0.7767795 (165) total: 11.5s remaining: 21s 177: learn: 1.0000000 test: 0.7740152 best: 0.7767795 (165) total: 11.6s remaining: 21s 178: learn: 1.0000000 test: 0.7719419 best: 0.7767795 (165) total: 11.7s remaining: 20.9s 179: learn: 1.0000000 test: 0.7747063 best: 0.7767795 (165) total: 11.7s remaining: 20.8s 180: learn: 1.0000000 test: 0.7705598 best: 0.7767795 (165) total: 11.8s remaining: 20.7s Stopped by overfitting detector (15 iterations wait) bestTest = 0.7767795439 bestIteration = 165
В данном примере сработал overfitting detector, остановив обучение на 180 итерации. Также, приведена статистика для тренировочной подвыборки (learn) и валидационной (test), а также общее время обучения модели, которое составило всего 20 секунд. На выходе мы получили лучший accuracy 1.0 на трейне (что соответствует идеальному результату) и 0.78 на валидационной подвыборке, что хуже, но выше 0.5 (что является рандомом). Лучшая итерация - 165, именно эта модель была сохранена. Теперь мы можем ее протестировать в тестере:
#test the learned model p = model.predict_proba(X) p2 = [x[0]<0.5 for x in p] pr2 = pr.iloc[:len(p2)].copy() pr2['labels'] = p2 rep = tester(pr2, MARKUP) plt.plot(rep) plt.show()
X - это исходный датасет с признаками, но без меток. Для того, чтобы получить метки, необходимо получить их из обученной модели и предсказать вероятности 'p' отнесения к классу 0 или 1. Поскольку модель выдает вероятности для двух классов, а нам нужны просто ноли или единицы, то переменная 'p2' получает вероятности только по первому (нулевому измерению). Далее, метки в исходном датасете заменяются на предсказанные моделью метки. Посмотрим на результаты в тестере:
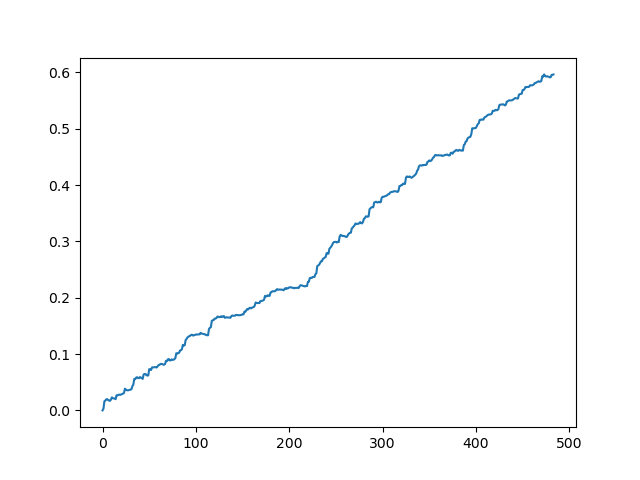
Идеальный результат после семплинга сделок
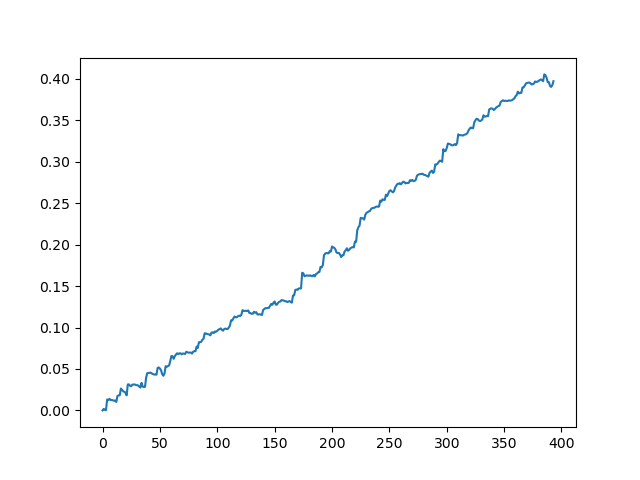
Результат, полученный на выходе модели
Как видно, модель неплохо обучилась, т. е. смогла не только запомнить обучающие примеры, но и показать результат выше случайного на валидационном сете. Перейдем к заключительному этапу — экспорту модели и созданию торгового робота.
Переносим модель в MetaTrader 5
MetaTrader 5 python api позволяет торговать непосредственно из python программы, поэтому перенос модели не является необходимостью. Однако, мне захотелось проверить свой кастомный тестер на адекватность и сравнить его со штатным. Кроме того, наличие готового скомпилированного бота может быть удобно во многих ситуациях, в том числе в случае развертывания на VPS (не придется устанавливать Python). Для этого была написана вспомогательная функция, которая сохраняет готовую модель в MQH-файл. Рассмотрим её:
def export_model_to_MQL_code(model):
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None)
code = 'double catboost_model' + '(const double &features[]) { \n'
code += ' '
with open('catmodel.h', 'r') as file:
data = file.read()
code += data[data.find("unsigned int TreeDepth"):data.find("double Scale = 1;")]
code +='\n\n'
code+= 'return ' + 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
code += 'double ApplyCatboostModel(const double &features[],uint &TreeDepth_[],uint &TreeSplits_[],uint &BorderCounts_[],float &Borders_[],double &LeafValues_[]) {\n\
uint FloatFeatureCount=ArrayRange(BorderCounts_,0);\n\
uint BinaryFeatureCount=ArrayRange(Borders_,0);\n\
uint TreeCount=ArrayRange(TreeDepth_,0);\n\
bool binaryFeatures[];\n\
ArrayResize(binaryFeatures,BinaryFeatureCount);\n\
uint binFeatureIndex=0;\n\
for(uint i=0; i<FloatFeatureCount; i++) {\n\
for(uint j=0; j<BorderCounts_[i]; j++) {\n\
binaryFeatures[binFeatureIndex]=features[i]>Borders_[binFeatureIndex];\n\
binFeatureIndex++;\n\
}\n\
}\n\
double result=0.0;\n\
uint treeSplitsPtr=0;\n\
uint leafValuesForCurrentTreePtr=0;\n\
for(uint treeId=0; treeId<TreeCount; treeId++) {\n\
uint currentTreeDepth=TreeDepth_[treeId];\n\
uint index=0;\n\
for(uint depth=0; depth<currentTreeDepth; depth++) {\n\
index|=(binaryFeatures[TreeSplits_[treeSplitsPtr+depth]]<<depth);\n\
}\n\
result+=LeafValues_[leafValuesForCurrentTreePtr+index];\n\
treeSplitsPtr+=currentTreeDepth;\n\
leafValuesForCurrentTreePtr+=(1<<currentTreeDepth);\n\
}\n\
return 1.0/(1.0+MathPow(M_E,-result));\n\
}'
file = open('C:/Users/dmitrievsky/AppData/Roaming/MetaQuotes/Terminal/D0E8209F77C8CF37AD8BF550E51FF075/MQL5/Include/' + 'cat_model' + '.mqh', "w")
file.write(code)
file.close()
print('The file ' + 'cat_model' + '.mqh ' + 'has been written to disc') В листинге функция смотрится достаточно неразборчиво, но я не сошел с ума. На вход она получает объект обученной модели, после чего сохраняет его в c++ формате:
model.save_model('catmodel.h',
format="cpp",
export_parameters=None,
pool=None) Потом создается строка и парсится c++ код в mql5 штатными средствами языка Python:
code = 'double catboost_model' + '(const double &features[]) { \n' code += ' ' with open('catmodel.h', 'r') as file: data = file.read() code += data[data.find("unsigned int TreeDepth"):data.find("double Scale = 1;")] code +='\n\n' code+= 'return ' + 'ApplyCatboostModel(features, TreeDepth, TreeSplits , BorderCounts, Borders, LeafValues); } \n\n'
После вышеприведенных манипуляций, вставляется функция 'ApplyCatboostModel' из данной библиотеки, которая возвращает посчитанный результат в диапазоне (0;1) на основе сохраненной модели и переданного вектора признаков.
Далее следует указать путь до \\Include папки терминала MetaTrader 5, куда модель будет сохранена. Таким образом, после настройки всех параметров, модель обучается в один клик и сохраняется сразу в виде MQH-файла, что очень удобно. Такой вариант хорош еще и потому, что обучать модели на языке Python — это классика жанра и мировая практика.
Пишем бота, который торгует в MetaTrader 5
После обучения и сохранения модели CatBoost, необходимо написать простого бота для проверки:
#include <MT4Orders.mqh> #include <Trade\AccountInfo.mqh> #include <cat_model.mqh> sinput int look_back = 50; sinput int MA_period = 15; sinput int OrderMagic = 666; //Orders magic sinput double MaximumRisk=0.01; //Maximum risk sinput double CustomLot=0; //Custom lot input int stoploss = 500; static datetime last_time=0; #define Ask SymbolInfoDouble(_Symbol, SYMBOL_ASK) #define Bid SymbolInfoDouble(_Symbol, SYMBOL_BID) int hnd;
Подключим сохраненную cat_model.mqh и MT4Orders.mqh от fxsaber.
Параметры look_back и MA_period необходимо выставить точно такими, какими они были указаны при обучении в Python программе, иначе будет ошибка.
Далее, на каждом баре проверяется сигнал модели, в которую передается вектор приращений (разницы цен и скользящего среднего):
if(!isNewBar()) return; double ma[]; double pr[]; double ret[]; ArrayResize(ret, look_back); CopyBuffer(hnd, 0, 1, look_back, ma); CopyClose(NULL,PERIOD_CURRENT,1,look_back,pr); for(int i=0; i<look_back; i++) ret[i] = pr[i] - ma[i]; ArraySetAsSeries(ret, true); double sig = catboost_model(ret);
Логика открытия сделок аналогична логике кастомного тестера, но в mql5 + MT4Orders стиле:
for(int b = OrdersTotal() - 1; b >= 0; b--) if(OrderSelect(b, SELECT_BY_POS) == true) { if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5) if(OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red)) { } } if(countOrders(0) == 0 && countOrders(1) == 0) { if(sig < 0.5) OrderSend(Symbol(),OP_BUY,LotsOptimized(), Ask, 0, Bid-stoploss*_Point, 0, NULL, OrderMagic); else if(sig > 0.5) OrderSend(Symbol(),OP_SELL,LotsOptimized(), Bid, 0, Ask+stoploss*_Point, 0, NULL, OrderMagic); return; }
Тестируем бота на машинном обучении
Скомпилировав бота, можно проверить его в штатном MetaTrader 5 тестере. Не забывайте правильно выбрать тайм-фрейм (должен быть таким же как при обучении модели), а также про инпуты look_back и MA_period, которые также аналогичны параметрам из Python программы. Проверим модель на периоде обучения (тренировочная + валидационная выборки):
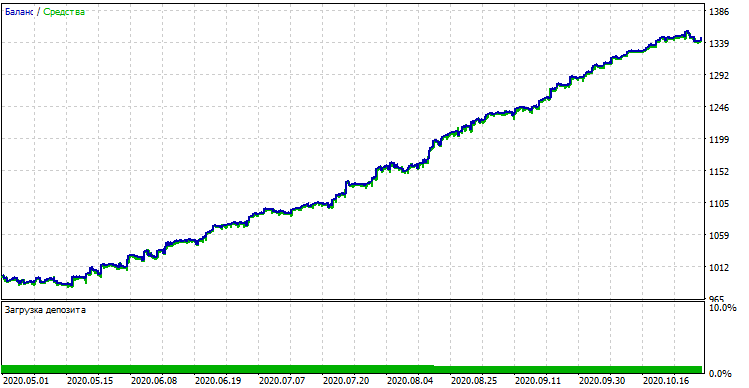
Производительность модели (тренировочная + валидационная выборки)
Если сравнить результат с результатом кастомного тестера, то они одинаковы, за исключением некоторых отклонений в спредах. Теперь протестируем модель на совершенно новых данных, с начала года:
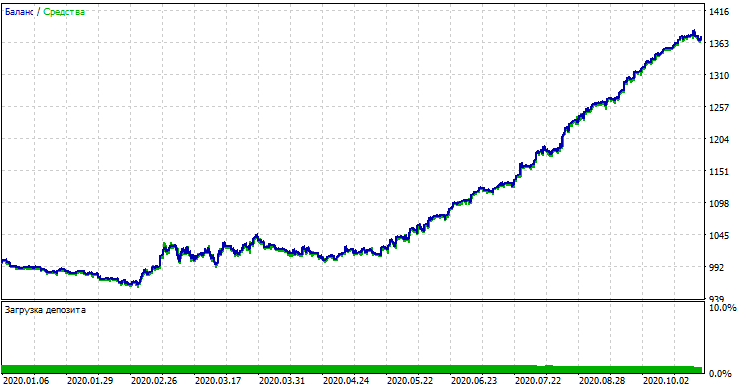
Производительность модели на новых данных
На новых данных модель показала себя значительно хуже. Это обусловлено объективными причинами, которые я постараюсь описать ниже.
От наивных моделей к осмысленным (предстоящий ресерч)
Статья была озаглавлена как "Наивный подход". Наивным он является по ряду причин:
- В модель не заложено никаких априорных данных о закономерностях. Выявление таковых полностью возложено на плечи градиентного бустинга, который не всесилен.
- Сэмплинг сделок случайный, поэтому результаты могут разниться от обучения к обучению. Это является не только минусом, но и плюсом, поскольку можно делать брутфорс.
- При обучении неизвестны никакие характеристики генеральной совокупности. Никогда неизвестно, как модель поведет себя на новых данных.
Вероятные подходы к улучшению производительности моделей (тема отдельной статьи):
- Перебор моделей по некоторому внешнему критерию (например, производительности на новых данных)
- Другие подходы к сэмплингу и обучению моделей, стакинг классификаторов
- Подбор признаков разного характера на основе априорных знаний и\или предположений
Заключение
В статье рассмотрена великолепная модель машинного обучения CatBoost, затронуты основные аспекты её настройки и обучения бинарной классификации в задачах прогнозирования временных рядов. Подготовлена, обучена и протестирована модель, а также перенесена на язык MQL в виде готового бота. Python и MQL программы приложены к статье.