Redes neurais de maneira fácil (Parte 31): Algoritmos evolutivos
Dmitriy Gizlyk | 19 janeiro, 2023
Conteúdo
- Introdução
- 1. Princípios básicos para a construção de um algoritmo
- 2. Implementação usando MQL5
- 3. Teste
- Considerações finais
- Referências
- Programas utilizados no artigo
Introdução
Nós continuamos a estudar técnicas de otimização de modelos sem gradientes, pois elas possibilitam otimizar modelos que não podem ser otimizados por meio de métodos gradientes. Essas são tarefas para as quais não é possível calcular a derivada da função ou o cálculo é complexo. No artigo anterior, apresentamos o algoritmo de otimização genética, cuja ideia é baseada nas ciências naturais. Cada peso do modelo é representado como um gene individual no genoma do modelo. O processo de otimização avalia várias populações de modelos inicializados aleatoriamente. A população tem uma duração limitada e, no final de cada ciclo, os melhores membros são selecionados para gerar a próxima geração (época). Um par de "pais" é escolhido aleatoriamente para cada indivíduo e os "genes pais" também são herdados aleatoriamente.
1. Princípios básicos para a construção de um algoritmo
Como mencionado anteriormente, o algoritmo de otimização genética contém uma grande quantidade de aleatoriedade. Enquanto selecionamos propositalmente os melhores representantes de cada população, a maioria dos indivíduos é descartada, resultando em um trabalho "vazio" desnecessário. Além disso, a evolução da população modelo de uma época para outra, na direção desejada, é altamente dependente do acaso, e não há garantia de movimento em direção ao objetivo.
Em comparação, o método de descida de gradiente move propositalmente a cada iteração em direção ao antigradiente, minimizando o erro do modelo e guiando o aprendizado do modelo na direção desejada. No entanto, é importante notar que para aplicar este método, é necessário calcular analiticamente a derivada da função a cada iteração.
Mas e se não tivermos essa oportunidade? Podemos de alguma forma combinar as duas abordagens?
Vamos primeiro relembrar o significado geométrico da derivada de uma função. A derivada de uma função é uma medida da taxa de variação do valor da função em relação a um determinado ponto. É definida como o limite da razão entre a variação do valor da função e a variação do seu argumento quando essa variação tende a zero, desde que esse limite exista.
Além de calcular a derivada analiticamente, também é possível obter uma aproximação através de experimentos. Para determinar a derivada do argumento x experimentalmente, basta alterar ligeiramente o valor do parâmetro x e calcular o valor da função, a relação entre a variação do valor da função e a variação do argumento dará uma aproximação da derivada.
Como os nossos modelos são não-lineares, para obter uma definição precisa da derivada experimentalmente, recomendamos realizar as seguintes operações para cada argumento: adicionar um determinado valor e, em seguida, subtrair o mesmo valor. A média dessas duas operações fornecerá uma aproximação mais precisa do valor da derivada da nossa função em relação ao argumento analisado em um determinado ponto.
É importante mencionar que essa abordagem é frequentemente utilizada para avaliar a precisão da derivada de um modelo analítico. Algoritmos evolutivos também aproveitam essa propriedade, utilizando gradientes obtidos experimentalmente para determinar a direção de otimização dos parâmetros do modelo.
Entretanto, como é fácil de observar, o principal problema ao utilizar gradientes experimentais é a necessidade de uma grande quantidade de operações. Para determinar a influência de um único parâmetro no resultado do modelo, é preciso realizar três propagações do modelo com os mesmos dados de entrada. Dessa forma, aumentar o número de parâmetros do modelo acarreta um aumento correspondente de três vezes no número de iterações.
Isso não é eficiente e deve ser considerado ao utilizar essa técnica.
Por exemplo, é possível mudar não apenas um parâmetro, mas também dois. No entanto, como é possível determinar o efeito de cada um deles? E como os parâmetros selecionados devem ser alterados, de forma síncrona ou não? E se a influência dos parâmetros selecionados sobre o resultado não for a mesma, eles precisam ser modificados com intensidade diferente?
Claro, é possível ignorar essas questões e apenas buscar um modelo que atenda às nossas exigências, mesmo que ele não seja o ideal. A noção de otimização envolve equilibrar todos os requisitos o melhor possível.
Nesse caso, podemos considerar o modelo e o conjunto de seus parâmetros como um todo. Podemos utilizar algum tipo de algoritmo para alterar todos os parâmetros do modelo de uma só vez, pois o algoritmo para alterar os parâmetros pode ser qualquer um, incluindo distribuições aleatórias.
Para avaliar a influência dessas mudanças, podemos utilizar o único método disponível: testar o modelo com a amostra de treinamento. Se o novo conjunto de parâmetros melhorar o resultado anterior, aceitamos essa mudança, caso contrário, rejeitamos e voltamos ao conjunto anterior de parâmetros e repetimos o processo com novos parâmetros.
Não parece um algoritmo genético? E onde está a estimativa do gradiente experimental que foi discutida acima?
Vamos nos aproximar ainda mais de um algoritmo genético. Assim como nele, vamos utilizar uma população de modelos cuja eficiência será testada em uma amostra de treinamento finita. Porém, em vez de criar modelos aleatoriamente, vamos usar parâmetros que estejam próximos entre si. Na verdade, pegaremos um modelo e adicionaremos uma pequena quantidade de ruído aleatório aos seus parâmetros. Esse uso de ruído aleatório nos permitirá ter uma população onde nenhum modelo é idêntico, mas uma pequena variação nos permitirá obter resultados em um mesmo subespaço com pouca variação. Isso significa que os resultados dos modelos serão comparáveis.
![]()
onde w' - parâmetros do modelo na população;
w - parâmetros do modelo inicial;
ɛ - ruído aleatório.
Podemos avaliar o desempenho de cada modelo da população usando uma função de perda ou um sistema de recompensa. A escolha dependerá da formulação do problema a ser resolvido. Consideramos a política de otimização, em que minimizamos a função de perda e maximizamos a recompensa total. Na prática, vamos maximizar a recompensa total, semelhante à solução de um problema de aprendizado de reforço.
Após testarmos o desempenho da nova população na amostra de treinamento, determinaremos agora como otimizar os parâmetros do modelo inicial. Para fazer isso, podemos usar técnicas matemáticas para deduzir o impacto de cada parâmetro sobre o resultado. No entanto, como concordamos anteriormente em considerar o modelo como um todo, podemos estimar todo o conjunto de ruídos adicionados em cada modelo individual pela recompensa total resultante ao testar a eficácia do modelo na amostra de treinamento. Portanto, adicionaremos aos parâmetros do modelo inicial o valor médio ponderado de ruído do parâmetro correspondente de todos os modelos da população, ponderando os valores de ruído pela recompensa total e multiplicando a média ponderada obtida pelo fator de aprendizado do modelo. A fórmula para atualizar os parâmetros do modelo pode ser vista abaixo. Ela é semelhante à fórmula de atualização de pesos quando se utiliza descida por gradiente.
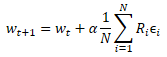
Este algoritmo evolutivo para otimização de modelos, proposto pela equipe do OpenAI em setembro de 2017, é apresentado no artigo "Evolution Strategies as a Scalable Alternative to Reinforcement Learning". Ele é apresentado como uma alternativa aos métodos de Q-learning e Policy Gradient, mostrando sua viabilidade e eficácia. Além disso, o método de escala proposto permite aumentar a velocidade de resolução do problema com dependência praticamente linear, usando vários computadores paralelos. Assim, utilizando mais de 10 mil computadores paralelos, a equipe foi capaz de resolver o desafio da caminhada humanóide em 3-D em apenas 10 minutos. No entanto, este artigo não discutirá problemas relacionados à escalabilidade.
2. Implementação usando MQL5
Após considerarmos os aspectos teóricos do algoritmo, avançaremos para a parte prática deste artigo, na qual analisaremos a implementação do algoritmo proposto utilizando o MQL5. É importante notar que não estaremos implementando o algoritmo de forma 100% original. Realizamos algumas modificações, preservando completamente a ideia principal do mesmo. Em particular, os autores sugeriram usar um algoritmo ganancioso para selecionar a ação. No entanto, mantivemos o algoritmo probabilístico para a seleção de ação. Além disso, adicionamos parâmetros de mutação, semelhantes aos utilizados no algoritmo genético. A mutação não estava incluída no algoritmo original.
Para implementar o algoritmo proposto, podemos criar uma nova classe de rede neural, chamada CNetEvolution, que herda de uma classe modelo de algoritmo genético. Utilizaremos herança de classe, especificamente herança pública, para herdar os métodos existentes da classe pai e substituir os que precisam ser modificados. Isso nos permitirá reutilizar alguns métodos sem precisar redefini-los, redirecionando-os para os métodos da classe pai. No entanto, utilizaremos herança não pública para bloquear o acesso a métodos não utilizados, o que evitará confusões desnecessárias para o usuário. Isso também será útil ao sobrecarregar métodos. Assim, o usuário não verá os métodos sobrecarregados das classes pai, o que evitará confusões desnecessárias.
class CNetEvolution : protected CNetGenetic { protected: virtual bool GetWeights(uint layer) override; public: CNetEvolution() {}; ~CNetEvolution() {}; //--- virtual bool Create(CArrayObj *Description, uint population_size) override; virtual bool SetPopulationSize(uint size) override; virtual bool feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) override; virtual bool Rewards(CArrayFloat *rewards) override; virtual bool NextGeneration(float mutation, float &average, float &mamximum); virtual bool Load(string file_name, uint population_size, bool common = true) override; virtual bool Save(string file_name, bool common = true); //--- virtual bool GetLayerOutput(uint layer, CBufferFloat *&result) override; virtual void getResults(CBufferFloat *&resultVals); };
No corpo da nova classe, não declaramos novas instâncias da classe. Além disso, não declaramos nenhuma variável interna. Basta usarmos objetos e variáveis das classes pai. Portanto, o construtor e o destruidor da classe permanecem vazios.
Observe aqui que não criamos objetos para conter os pesos do modelo inicial antes de adicionarmos o ruído. E isso também é um afastamento do algoritmo original. Mas voltaremos a esta questão durante a implementação.
Em seguida, consideramos o método Create para criar a população de modelos. Nos parâmetros, o método recebe um array dinâmico com a descrição do modelo e o tamanho da população, de forma semelhante ao método da classe pai. Implementaremos a funcionalidade principal usando o método da classe pai. Para fazer isso, basta chamá-lo e passar os parâmetros recebidos.
Lembre que no método da classe do algoritmo genético CNetGenetic::Create, criamos uma população de modelos com a mesma arquitetura e coeficientes de peso aleatórios. Agora precisamos criar uma população semelhante, só que os parâmetros de nossos modelos devem estar próximos. Para isso, chamaremos o método NextGeneration (falaremos sobre ele um pouco mais adiante).
Verificamos o resultado das operações em cada etapa. E ao final do método, retornaremos o resultado lógico das operações.
bool CNetEvolution::Create(CArrayObj *Description, uint population_size) { if(!CNetGenetic::Create(Description, population_size)) return false; float average, maximum; return NextGeneration(0,average, maximum); }
O método NextGeneration foi mencionado acima. Não vamos deixar para depois o que pode ser feito de imediato, por isso olhemos para seu algoritmo. O funcionamento do método em questão é semelhante ao do método de mesmo nome da classe pai, mas há algumas especificidades relacionadas às necessidades do algoritmo.
Nos parâmetros, o método recebe a probabilidade de mutação e 2 variáveis, onde escreveremos o valor da recompensa média e máxima.
No corpo do método, armazenamos imediatamente os valores de recompensa necessários e limitamos o valor máximo da mutação. A limitação do valor máximo de mutação é causada pelo desejo de obter um modelo treinado. Se utilizarmos um valor de mutação elevado, os parâmetros do modelo serão gerados aleatoriamente em cada iteração, sem levar em conta os resultados obtidos. Como resultado, a nossa população será constantemente composta por modelos aleatórios não treinados.
bool CNetEvolution::NextGeneration(float mutation, float &average, float &maximum) { maximum = v_Rewards.Max(); average = v_Rewards.Mean(); mutation = MathMin(mutation, MaxMutation);
Em seguida, nos concentraremos em preparar a base para atualizar os pesos do modelo. Como mencionado na parte teórica deste artigo, a medida de ponderação do tamanho do ruído na atualização dos parâmetros é a recompensa total de um modelo individual na amostra de treinamento. No entanto, dependendo da política de recompensa utilizada, a recompensa total pode ser positiva ou negativa. É provável que obtenhamos uma situação em que as recompensas totais de todos os membros da população tenham o mesmo sinal, seja positivo ou negativo
Ao mesmo tempo, nem todas as adições de ruído aos parâmetros do modelo têm um efeito positivo ou negativo. Nesse caso, a influência positiva de alguns componentes pode ser cancelada pela influência negativa de outros. E, na melhor das hipóteses, isso pode atrasar nosso progresso na direção correta. E, no pior dos casos, pode levar ao treinamento do modelo na direção oposta. Para minimizar o impacto desse efeito, calculamos a diferença entre a recompensa total de um determinado modelo e a recompensa total média de toda a população no vetor de probabilidade v_Probability.
Aqui, partimos do pressuposto de que o ruído adicionado segue uma distribuição normal. Isso significa que a recompensa total do modelo inicial está aproximadamente no meio da distribuição total das recompensas totais da população. Ao calcular a diferença, os modelos com recompensa total abaixo da média recebem uma probabilidade negativa. Quanto menor a recompensa total do modelo, maior a probabilidade negativa. De maneira similar, os modelos com a maior recompensa total também recebem a maior probabilidade positiva. Isso nos permite, do ponto de vista prático, direcionar o treinamento do modelo na direção desejada. Se o ruído adicionado tiver um efeito positivo, multiplicando-o por uma probabilidade positiva, resultará em um viés positivo no coeficiente de peso. Se o ruído adicionado tiver um impacto negativo, multiplicando-o por uma probabilidade negativa, mudamos a direção do viés do coeficiente de peso de negativo para positivo. Isso permite direcionar o treinamento do modelo para maximizar a recompensa total.
Além disso, segundo o algoritmo original, os parâmetros do modelo são corrigidos com base na média ponderada do ruído. Portanto, também normalizamos o vetor de probabilidades obtidas de forma que a soma dos valores absolutos de todos os seus elementos seja igual a "1".
v_Probability = v_Rewards - v_Rewards.Mean(); float Sum = MathAbs(v_Probability).Sum(); if(Sum == 0) v_Probability[0] = 1; else v_Probability = v_Probability / Sum;
Depois de determinar os coeficientes de atualização do modelo, que escrevemos no vetor v_Probability, realizamos o ciclo de iteração sobre as camadas do modelo. É no corpo desse ciclo que formaremos os parâmetros dos modelos da nova população.
No corpo do ciclo, primeiro obtemos um ponteiro para uma matriz dinâmica de objetos da camada atual. E verificamos se o ponteiro recebido para o objeto é válido. Verificamos também o tamanho da matriz dinâmica, pois deve corresponder ao tamanho da população dada. Se o tamanho da população for insuficiente, chamaremos o método CreatePopulation para criar modelos adicionais. Lembre-se de que aqui usamos o método da classe pai sem alterações.
for(int l = 1; l < layers.Total(); l++) { CLayer *layer = layers.At(l); if(!layer) return false; if(layer.Total() < (int)i_PopulationSize) if(!CreatePopulation()) return false;
A seguir, chamamos o método GetWeights, que criará os parâmetros atualizados da camada do modelo atual nas matrizes m_Weights e m_WeightsConv. O algoritmo do próprio método será considerado posteriormente.
if(!GetWeights(l)) return false;
Isso significa que agora que obtivemos os parâmetros atualizados do nosso modelo, podemos prosseguir com a preenchimento da população. Para isso, criamos um ciclo aninhado com o número de iterações igual ao tamanho da população.
No corpo do ciclo, obtemos um ponteiro para o objeto do neurônio atual da camada neural analisada. E verificamos a validade do ponteiro recebido. E então obtemos um ponteiro para o objeto da matriz de pesos.
for(uint i = 0; i < i_PopulationSize; i++) { CNeuronBaseOCL* neuron = layer.At(i); if(!neuron) return false; CBufferFloat* weights = neuron.getWeights();
Se o ponteiro da matriz de pesos resultante for válido, começamos a trabalhar com ele. Aqui criamos outro ciclo aninhado que irá iterar sobre os elementos da matriz de pesos.
No corpo do ciclo, primeiro verificamos a probabilidade de usar uma mutação e, se necessário, geramos um número aleatório. Se o número aleatório gerado for menor que a probabilidade de mutação, escrevemos um coeficiente de peso aleatório no elemento atual da matriz. E avançamos para a próxima iteração do ciclo. Usamos aproximadamente a mesma abordagem no algoritmo genético.
if(!!weights) { for(int w = 0; w < weights.Total(); w++) { if(mutation > 0) { int err_code; float random = (float)Math::MathRandomNormal(0.5, 0.5, err_code); if(mutation > random) { if(!weights.Update(w, GenerateWeight((uint)m_Weights.Cols()))) { Print("Error of update weights"); return false; } continue; } }
Se o peso atual for atualizado, primeiro verificamos seu valor atual. Se necessário, substituímos o número inválido por um fator de ponderação aleatório.
if(!MathIsValidNumber(m_Weights[0, w])) { if(!weights.Update(w, GenerateWeight((uint)m_Weights.Cols()))) { Print("Error of update weights"); return false; } continue; }
E no final da iteração do ciclo aninhado, adicionamos ruído ao peso atual.
if(!weights.Update(w, m_Weights[0, w] + GenerateWeight((uint)m_Weights.Cols()))) { Print("Error of update weights"); return false; } } weights.BufferWrite(); }
Depois de adicionar ruído a todos os elementos da matriz de pesos do elemento atual da população, transferimos os parâmetros atualizados para a memória do OpenCL.
Se necessário, repetimos as iterações descritas acima para a matriz de pesos da camada convolucional.
if(neuron.Type() != defNeuronConvOCL) continue; CNeuronConvOCL* temp = neuron; weights = temp.GetWeightsConv(); for(int w = 0; w < weights.Total(); w++) { if(mutation > 0) { int err_code; float random = (float)Math::MathRandomNormal(0.5, 0.5, err_code); if(mutation > random) { if(!weights.Update(w, GenerateWeight((uint)m_WeightsConv.Cols()))) { Print("Error of update weights"); return false; } continue; } }
if(!MathIsValidNumber(m_WeightsConv[0, w])) { if(!weights.Update(w, GenerateWeight((uint)m_WeightsConv.Cols()))) { Print("Error of update weights"); return false; } continue; }
if(!weights.Update(w, m_WeightsConv[0, w] + GenerateWeight((uint)m_WeightsConv.Cols()))) { Print("Error of update weights"); return false; } } weights.BufferWrite(); } }
As iterações são feitas para todos os elementos da sequência.
No final do método, redefinimos o vetor de acumulação da recompensa total e encerramos o mesmo.
v_Rewards.Fill(0); //--- return true; }
Seguindo a cadeia de chamadas de métodos, a seguir veremos o método GetWeights, que chamamos do método anterior. Seu objetivo é atualizar os parâmetros do modelo que está sendo otimizado. Lembrando que a classe pai do algoritmo genético CNetGenetic utilizado por nós, possui um método de mesmo nome para descarregar os parâmetros de uma camada neural de todos os modelos populacionais. Posteriormente, usamos a matriz resultante para criar uma nova população. Aqui seguimos a mesma lógica, apenas o conteúdo muda de acordo com o algoritmo de otimização utilizado.
O método GetWeights recebe como parâmetro o número de série da camada neural cuja matriz de parâmetros será criada. No corpo do método, verificamos a presença de um vetor de probabilidade formado utilizando os representantes da população na atualização dos parâmetros do modelo. Em seguida, chamamos o método da classe pai com o mesmo nome, e durante o processo, controlamos a execução das operações.
bool CNetEvolution::GetWeights(uint layer) { if(v_Probability.Sum() == 0) return false; if(!CNetGenetic::GetWeights(layer)) return false;
Uma vez concluídas as operações do método da classe, esperamos que as matrizes m_Weights e m_WeightsConv contenham os coeficientes de peso da camada neural analisada de todos os modelos populacionais.
Observe que as matrizes contêm pesos, e para atualizar os parâmetros do modelo, precisamos dos valores do ruído adicionado e dos parâmetros do modelo inicial.
Procedemos de forma semelhante ao ajuste da recompensa. Sabemos que o ruído segue uma distribuição normal. E cada parâmetro dos modelos populacionais é a soma do parâmetro correspondente do modelo inicial e do ruído. Assumimos que os parâmetros do modelo inicial se encontram no centro da distribuição dos parâmetros correspondentes dos modelos populacionais. Dessa forma, podemos utilizar o vetor de valores médios dos parâmetros populacionais correspondentes.
if(m_Weights.Cols() > 0) { vectorf mean = m_Weights.Mean(0);
Assim, subtraindo o vetor de médias da matriz de parâmetros dos modelos populacionais, podemos obter a matriz de ruído adicionado necessária.
matrixf temp = matrixf::Zeros(1, m_Weights.Cols()); if(!temp.Row(mean, 0)) return false; temp = (matrixf::Ones(m_Weights.Rows(), 1)).MatMul(temp); m_Weights = m_Weights - temp;
Utilizar a mesma abordagem para calcular o ruído adicionado e as probabilidades de seu uso na atualização dos pesos do modelo nos permite obter valores comparáveis. Então, podemos utilizar a fórmula mencionada anteriormente para atualizar os parâmetros do modelo. Em seguida, basta transferir os valores obtidos para a matriz adequada.
mean = mean + m_Weights.Transpose().MatMul(v_Probability) * lr; if(!m_Weights.Resize(1, m_Weights.Cols())) return false; if(!m_Weights.Row(mean, 0)) return false; }
Se necessário, repetimos as operações para a segunda matriz.
if(m_WeightsConv.Cols() > 0) { vectorf mean = m_WeightsConv.Mean(0); matrixf temp = matrixf::Zeros(1, m_WeightsConv.Cols()); if(!temp.Row(mean, 0)) return false; temp = (matrixf::Ones(m_WeightsConv.Rows(), 1)).MatMul(temp); m_WeightsConv = m_WeightsConv - temp; mean = mean + m_WeightsConv.Transpose().MatMul(v_Probability) * lr; if(!m_WeightsConv.Resize(1, m_WeightsConv.Cols())) return false; if(!m_WeightsConv.Row(mean, 0)) return false; } //--- return true; }
E o código completo de todos os métodos e classes pode ser encontrado no anexo.
Acima, discutimos os métodos do algoritmo que foram modificados para elaborar o algoritmo evolutivo. No entanto, para a funcionalidade completa da classe, ainda precisamos substituir os métodos para direcionar o fluxo para os métodos correspondentes da classe pai. Lembre-se de que esta é uma medida necessária para a herança não pública.
bool CNetEvolution::SetPopulationSize(uint size) { return CNetGenetic::SetPopulationSize(size); }
bool CNetEvolution::feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) { return CNetGenetic::feedForward(inputVals, window, tem); }
bool CNetEvolution::Rewards(CArrayFloat *rewards) { if(!CNetGenetic::Rewards(rewards)) return false; //--- v_Probability = v_Rewards - v_Rewards.Mean(); v_Probability = v_Probability / MathAbs(v_Probability).Sum(); //--- return true; }
bool CNetEvolution::GetLayerOutput(uint layer, CBufferFloat *&result) { return CNet::GetLayerOutput(layer, result); }
void CNetEvolution::getResults(CBufferFloat *&resultVals)
{
CNetGenetic::getResults(resultVals);
}
Para finalizar o trabalho da classe, precisamos redefinir os métodos para lidar com arquivos. Primeiramente, precisamos decidir sobre o método de salvamento do modelo. Como mencionado anteriormente, não salvamos o modelo separadamente com os parâmetros atualizados, mas somente atualizamos os parâmetros para construir uma nova população. No entanto, para salvar o modelo treinado, precisamos escolher apenas um, e aqui é lógico manter o modelo com o melhor resultado. Entre os métodos da classe pai, já temos um, e vamos direcionar o fluxo das operações para ele.
bool CNetEvolution::Save(string file_name, bool common = true) { return CNetGenetic::SaveModel(file_name, -1, common); }
Com a preservação do modelo, o problema foi resolvido. Vamos passar para o método de carregamento do modelo pré-treinado. A situação é semelhante, mas há uma nuance. Durante o processo de treinamento, não salvamos toda a população, mas apenas um modelo com os melhores resultados. Assim, depois de carregar tal modelo, precisamos criar uma população a partir dele. No método de carregamento da classe pai, facilitamos isso, embora aí seja criada uma população de modelos com parâmetros absolutamente aleatórios. Precisamos criar uma população em torno de um modelo com a adição de ruído. Para fazer isso, primeiro chamamos o método de carregamento de dados do modelo de classe pai, que criará a funcionalidade e a população do tamanho necessário. Em seguida, redefinimos o vetor de recompensas totais e chamamos o método NextGeneration, no qual uma nova população com as características necessárias é criada a partir do modelo carregado.
bool CNetEvolution::Load(string file_name, uint population_size, bool common = true) { if(!CNetGenetic::Load(file_name, population_size, common)) return false; v_Rewards.Fill(0); float average, maximum; if(!NextGeneration(0, average, maximum)) return false; //--- return true; }
A questão de como separar o modelo carregado dos modelos gerados aleatoriamente foi abordada anteriormente. Mas como fazer isso? Na verdade, esse problema é resolvido de maneira bastante simples. O método da classe pai coloca o modelo carregado na posição "0" da população e adiciona modelos gerados aleatoriamente a ele. Usamos o vetor de recompensa total dos modelos para determinar a probabilidade de usar o ruído adicionado. Antes de chamar o método para criar uma nova população, redefinimos cuidadosamente esse vetor para zero. Isso garante que, no corpo do método NextGeneration, obteremos um vetor com valores zero, cuja soma é "0". Como resultado, a probabilidade de usar apenas o modelo com índice "0" (carregado do arquivo) para formar a base de parâmetros dos modelos da nova população é de 100%, enquanto a probabilidade de usar os parâmetros dos modelos gerados aleatoriamente é "0". Dessa forma, a nova população é construída em torno do modelo carregado do arquivo.
bool CNetEvolution::NextGeneration(float mutation, float &average, float &maximum) { ............. ............. ............. v_Probability = v_Rewards - v_Rewards.Mean(); float Sum = MathAbs(v_Probability).Sum(); if(Sum == 0) v_Probability[0] = 1; else v_Probability = v_Probability / Sum; ............. ............. ............. }
Revisamos o algoritmo de todos os métodos da nova classeCNetEvolution e podemos proceder ao treinamento do modelo, na próxima seção deste artigo.
3. Teste
O Expert Advisor "Evolution.mq5" foi criado a partir do Expert Advisor do artigo anterior para treinar o modelo. Todos os parâmetros e configurações do Expert Advisor permanecem inalterados. Na verdade, basta mudar a classe do objeto no Expert Advisor para treinar modelos com o algoritmo genético, e é possível treinar novos modelos com o algoritmo de evolução.
Contudo, vou me aprofundar um pouco no procedimento para criar um novo modelo. Lembrando que depois de criar a ferramenta para transferência de aprendizado nos artigos [7] e [8], decidi não especificar a arquitetura do modelo no código do Expert Advisor. Isso nos permite experimentar com diferentes modelos sem precisar alterar o código do EA.
Para criar um novo modelo, executamos a ferramenta NetCreator, criada anteriormente. Não estamos usando a parte esquerda da ferramenta e não estamos carregando nenhum modelo pré-treinado, pois estamos criando um modelo completamente novo.
Durante o processo de aprendizado, utilizamos 12 parâmetros de cada descrição de vela para alimentar a entrada do modelo, e planejamos analisar os dados históricos com uma profundidade de 20 velas. Portanto, o tamanho da camada de entrada é de 240 neurônios (12 * 20). Utilizamos uma camada neural totalmente conectada sem uma função de ativação como camada de entrada. Adicionamos os parâmetros da primeira camada no centro da nossa ferramenta e clicamos no botão "ADD LAYER". Isso resulta na descrição da primeira camada de neurônios que é exibida na parte direita da nossa ferramenta.

A seguir, está o processo de criação da arquitetura do nosso modelo. Por exemplo, queremos que nosso modelo analise os padrões de 3 velas adjacentes. Para fazer isso, adicionamos uma camada de convolução com o tamanho da janela analisada de 36 neurônios (12 * 3). A etapa de mistura da janela analisada é definida para 12 neurônios, o que corresponde ao número de elementos de descrição de uma vela. Para aumentar a flexibilidade do modelo, criamos 12 filtros para análise de padrões. Utilizamos a tangente hiperbólica como função de ativação, pois permite separar logicamente os padrões de alta e baixa. Isso faz com que a saída da camada neural seja normalizada dentro da faixa de valores da função de ativação.

Cabe lembrar que a camada de convolução que criamos primeiro retornará uma sequência de todos os elementos de cada filtro, um após o outro. Isso pode ser comparado a uma matriz em que cada linha representa um filtro diferente. E os elementos da linha representam o resultado do filtro em toda a sequência de dados de entrada.
Em seguida, vamos analisar os resultados dos filtros gerados pela camada de convolução criada anteriormente Construiremos uma cascata de 3 camadas de convolução, cada uma delas analisando os resultados da camada anterior. Todas as três camadas terão as mesmas características, analisando 2 neurônios vizinhos com passos de 1 neurônio. Cada camada utilizará 2 filtros para análise.

Como pode ser visto, o tamanho do vetor de resultados aumenta de camada para camada devido à pequeno passo da janela de dados analisados e aos múltiplos filtros. Normalmente, são utilizadas camadas de subamostragem para reduzir a dimensionalidade, seja medindo a saída dos filtros ou tomando o valor máximo. Neste caso, optamos por não utilizá-las, com a intenção de preservar o máximo de informações úteis possíveis.
As camadas convolucionais desempenham uma função de preparação dos dados de entrada, destacando alguns padrões contidos neles. Quanto mais camadas convolutivas houver, mais complexos serão os padrões que o modelo é capaz de extrair. No entanto, é importante ter cuidado para não criar modelos muito profundos, pois isso pode complicar o processo de aprendizado. Embora os métodos de otimização sem gradientes não sejam afetados pelos problemas de explosão/dissipação do gradiente, não é necessário usar redes profundas para resolver todos os problemas. É recomendável experimentar diferentes variantes e avaliar o impacto do aumento da profundidade do modelo no resultado final. Pode-se observar que, em algum momento, adicionar mais camadas não trará melhorias significativas, mas exigirá recursos adicionais para otimizar o modelo.
Vamos processar os resultados das camadas neurais convolucionais utilizando um perceptron de três camadas, cada uma com 500 neurônios. A função de ativação escolhida foi a tangente hiperbólica, mas sugerimos experimentar outras para comparar os resultados.

O objetivo final é obter uma distribuição de probabilidade para as ações "Comprar", "Vender" e "Esperar". Para isso, adicionaremos outra camada totalmente conectada com três neurônios, sem a necessidade de utilizar uma função de ativação.

Em seguida, utilizaremos a camada SoftMax para transferir o resultado para o domínio das probabilidades.

Neste ponto, consideramos o desenvolvimento do novo modelo concluído. A última etapa é salvar o modelo com um nome específico, utilizando a função "SAVE MODEL".

Lembre-se de que o treinamento do modelo foi realizado utilizando dados históricos dos últimos 2 anos do EURUSD no gráfico H1, conforme descrito em artigos anteriores. E não vou me deter nisso.
É interessante que durante a otimização do modelo, o gráfico da dinâmica do erro total apresentou uma dinâmica abrupta.

Após a otimização, testamos o modelo no testador de estratégia. Para testar, usamos o modelo "Evolution-test.mq5", que é uma cópia exata do Expert Advisor de vários artigos anteriores. As alterações afetaram apenas o nome do arquivo do modelo carregado. O código completo do Expert Advisor está disponível no anexo.
Os testes foram realizados nas últimas 2 semanas, com dados que não foram utilizados no treinamento do modelo, para simular o ambiente real o mais próximo possível. Os resultados mostraram que a abordagem proposta é viável. O gráfico abaixo ilustra a dinâmica do crescimento do equilíbrio. Ao todo, foram realizadas 107 operações de negociação durante o período de teste, das quais quase 55% foram lucrativas. A relação entre negociações lucrativas e não lucrativas é próxima de 1:1, mas a média de lucro das negociações bem-sucedidas é 43% maior do que a média das negociações perdedoras, o que resultou em um fator de lucro geral de 1,69 e um fator de recuperação de 3,39.


Considerações finais
Neste artigo, apresentamos um método de otimização sem gradiente, o algoritmo evolutivo, e implementamos uma classe para tal. A eficácia do algoritmo foi comprovada através da otimização do modelo e dos testes dos resultados obtidos no testador de estratégia, os quais demonstraram a possibilidade de lucro do EA. No entanto, é importante destacar que os testes foram realizados para um curto período de tempo e não garantem lucro a longo prazo.
O modelo e o Expert Advisor construídos neste artigo têm como objetivo apenas demonstrar a tecnologia. Antes de utilizá-los em contas reais, são necessárias configurações e otimizações adicionais.
Referências
- Redes neurais de maneira fácil (Parte 26): aprendizado por reforço
- Redes neurais de maneira fácil (Parte 27): aprendizado Q profundo (DQN)
- Redes neurais de maneira fácil (Parte 28): algoritmo de gradiente de política
- Redes neurais de maneira fácil (Parte 29): algoritmo ator-crítico de vantagem (advantage actor-critic)
- Natural Evolution Strategies
- Evolution Strategies as a Scalable Alternative to Reinforcement Learning
- Redes neurais de maneira fácil (Parte 23): criando uma ferramenta para transferência de aprendizado
- Redes neurais de maneira fácil (Parte 24): melhorando a ferramenta para transferência de aprendizado
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Evolution.mq5 | EA | EA para otimização de modelos |
| 2 | NetEvolution.mqh | Biblioteca de classe | Biblioteca para elaborar o algoritmo evolutivo |
| 3 | Evolution-test.mq5 | EA | EA para prova do modelo no testador de estratégia |
| 4 | NeuroNet.mqh | Biblioteca de classes | Biblioteca para preparar modelos de redes neurais |
| 5 | NeuroNet.cl | Biblioteca | Biblioteca de código OpenCL para manusear modelos de redes neurais |