Redes neurais de maneira fácil (Parte 29): Algoritmo ator-crítico de vantagem (Advantage actor-critic)
Dmitriy Gizlyk | 12 dezembro, 2022
Conteúdo
- Introdução
- 1. Pontos fortes dos métodos de aprendizado por reforço discutidos anteriormente
- 2. Algoritmo ator-crítico de vantagem
- 3. Implementação
- 4. Teste
- Considerações finais
- Referências
- Programas utilizados no artigo
Introdução
Neste artigo, continuamos nosso estudo sobre métodos de aprendizado por reforço. Em artigos anteriores falamos sobre métodos para aproximar a função de recompensa (aprendizado Q) e para treinar a função de gradiente de política. Cada método tem suas próprias vantagens e desvantagens. E, certamente, quando construímos e treinamos nosso modelo, gostaríamos de aproveitar ao máximo suas vantagens. Assim, na busca por métodos para minimizar as deficiências dos algoritmos utilizados, muitas vezes recorremos a tentativas de construir certos conglomerados de algoritmos e de métodos que conhecemos. E, bem, nesta oportunidade, trataremos de como combinar os dois algoritmos acima falados em um único método de treinamento de modelo, o chamado de ator-crítico de vantagem (Advantage actor-critic).
1. Pontos fortes dos métodos de aprendizado por reforço discutidos anteriormente
Mas antes de combinar algoritmos, vamos relembrar seus pontos fortes e fracos.
No processo de interação com o ambiente, o agente realiza determinadas ações ao mesmo tempo que influi no ambiente. Quando isso ocorre, a influência de fatores externos e as ações do agente provocam que o ambiente mude. E após cada mudança, o ambiente informa o agente transferindo determinada recompensa. Essa recompensa pode ser positiva ou negativa. O valor e o sinal da recompensa indicam ao agente a utilidade da mudança. O agente não conhece como se forma a recompensa. O objetivo do agente é aprender a realizar isso para receber a máxima recompensa possível durante a interação com o ambiente .
Primeiro estudamos o aprendizado Q, isto é, o algoritmo de aproximação da função de recompensa. Treinamos nosso modelo de forma a aprender a prever a próxima recompensa com a maior precisão possível após executar uma ou outra ação durante um determinado estado do ambiente. É aí que o agente executa ações com base no valor da recompensa prevista e na política de comportamento do agente. Como regra, aqui é usada a estratégia gananciosa ou ɛ-gananciosa. Uma estratégia gananciosa envolve a escolha da ação com a maior recompensa prevista, e é usada com mais frequência ao usar o agente de maneira global.
A estratégia ɛ-gananciosa é semelhante à estratégia gananciosa em mais do que apenas o nome. Também envolve a escolha da ação com a maior recompensa prevista. Mas ao mesmo tempo permite a escolha de uma ação aleatória com probabilidade ɛ. O que é usado na etapa de treinamento do modelo para entender melhor o ambiente. De fato, se não ocorresse assim, após receber uma recompensa positiva, o modelo repetiria constantemente uma ação e não estudaria outras possibilidades. Assim, ele nunca saberia o quão ideal foi a ação ou se outras ações poderiam trazer mais recompensas. E queremos forçar o agente a explorar o ambiente o máximo possível e a tirar o máximo proveito dele.
As vantagens do método aprendizado Q são bastante óbvias. Treinamos o modelo para prever a recompensa. O ambiente nos dá a recompensa. E, quanto a valores, temos uma relação direta entre os resultados do modelo e a referência recebida do ambiente. Desde essa perspetiva, tal aprendizado é semelhante aos métodos de aprendizado supervisionado. Ao treinar o modelo, usamos o erro padrão como uma função de perda.
Aqui é importante prestar atenção. O modelo treinado retornará a recompensa acumulada média até o final da sessão (e para tal levará em consideração o fator de desconto que o ambiente dá ao agente após realizar uma ação específica em um estado semelhante do ambiente ao treinar o modelo), enquanto o ambiente retornará uma recompensa para cada transição específica para um novo estado. E aqui vemos uma lacuna que é preenchida após o agente efetuar a passagem completa do episódio.
Uma das desvantagens do algoritmo é a complexidade do treinamento do modelo. Lembre que, para treinar o modelo, precisamos introduzir algumas entidades e realizar alguns truques. Em primeiro lugar, os sucessivos estados do ambiente estão fortemente correlacionados entre si. E, na maioria dos casos, diferem apenas em pequenos detalhes. O treinamento direto sobre tais dados levaria a um constante retreinamento do modelo conforme o estado atual, com uma completa perda da capacidade de generalização de dados. Por esse motivo, precisávamos criar um buffer de dados históricos para treinar o modelo. Ao fazer isto último, selecionávamos aleatoriamente estados provenientes do buffer de dados históricos, o que possibilitava minimizar a correlação entre os 2 estados usados sequencialmente para treinamento.
Ao treinar o modelo com os dados reais da recompensa que o ambiente nos dá, obtemos um modelo com baixa dispersão de dados, ou seja, a dispersão dos valores retornados pelo modelo para cada estado é aceitavelmente pequena. Isso é um fator positivo. Mas lembremos que o ambiente retorna uma recompensa durante cada transição específica. E precisamos maximizar os lucros durante todo o período visível. Bem, para calcular esses lucros é necessário que o agente conclua a passagem da sessão. No entanto, graças ao uso de um buffer de dados históricos e à adição de um modelo para prever recompensas futuras, conseguimos construir um algoritmo que pode retreinar o modelo durante seu uso prático, em outras palavras, conseguimos construir um processo de aprendizado on-line. Mas, para alcançar esse propósito, tivemos que pagar com um erro na previsão da recompensa.
Na verdade, quando usamos o segundo modelo para prever recompensas futuras, entendemos e aceitamos perfeitamente os riscos de ter erros em tais previsões. Mas cada erro cometido, além de ser levado em consideração ao treinar o modelo, influenciou todas as previsões posteriores. Assim, obtivemos um modelo capaz de prever resultados com uma pequena dispersão, mas com um grande viés. Isso pode ser ignorado quando usamos a estratégia gananciosa. Afinal de contas, é quando escolhemos a recompensa máxima, que estamos apenas comparando com o resto. O viés ou dimensionamento dos valores neste caso não afeta o resultado final da seleção da ação.

E, claro, ao usar aprendizado Q, nosso modelo é treinado apenas para prever recompensas. Para selecionar ações, precisamos especificar a política (estratégia) do comportamento do agente na etapa de criação do modelo. E o uso de uma estratégia gananciosa só pode funcionar com sucesso em ambientes determinísticos. E não é totalmente aplicável à construção de estratégias estocásticas.
O uso de gradiente de política, ao contrário, não exige que definamos a política (estratégia) de comportamento do agente na etapa de criação do modelo. Este método permite que o agente construa sua política de comportamento, que pode ser gananciosa e estocástica.
O modelo treinado pelo método do gradiente de políticas retorna a distribuição de probabilidade de atingir o resultado desejado ao escolher uma ou outra ação em cada estado específico do ambiente.
Ao treinar o modelo, também usamos as recompensas que o ambiente nos dá. Além disso, para selecionar a melhor estratégia em cada estado do ambiente, usa-se a recompensa cumulativa até o final da sessão. Obviamente, para atualizar os pesos do modelo, o agente precisa passar por toda a sessão. Talvez esta seja a principal desvantagem deste método. Não podemos construir um modelo de aprendizado on-line porque desconhecemos as recompensas futuras.
Ao mesmo tempo, o uso da recompensa cumulativa real nos permite minimizar o erro constante, o viés dos dados previstos em relação ao seu valor real. Essa foi a falha do aprendizado Q por conta do uso de valores preditivos para recompensas futuras.
No entanto, deixe-me lembrá-lo de que, no gradiente de política, treinamos o modelo para prever não a recompensa esperada, mas, sim, a distribuição de probabilidade de alcançar o resultado desejado quando um agente executa uma ação em um determinado estado do ambiente. E como função de perda, usamos a função logarítmica.
")
Para determinar analiticamente a direção da minimização do erro, usamos, como sempre, a derivada da função de perda. Nesse caso, a propriedade da derivada do logaritmo é muito conveniente.

Após multiplicar a derivada da função de perda pela recompensa positiva, aumentamos a probabilidade de escolher tal ação. E, ao multiplicar a derivada da função de perda por uma recompensa negativa, ajustamos nossos pesos na direção oposta. Dessa maneira, reduzimos assim a probabilidade de escolher tal ação. E o valor do modulo da recompensa determinará a etapa de ajuste dos pesos.
Como se pode ver, ao atualizar a matriz de peso do nosso modelo, o uso de recompensas ocorre de forma indireta. Portanto, obtemos um modelo cujos resultados têm um pequeno viés em relação aos dados verdadeiros, mas uma dispersão bastante grande.

Um dos aspectos positivos do método é sua capacidade de estudar o ambiente. Afinal, se ao usar o aprendizado Q e a estratégia ɛ-gananciosa, determinávamos o equilíbrio entre o estudo e o uso do ambiente usando o parâmetro ɛ, então o gradiente de política usa amostragem de ações a partir de uma determinada distribuição.
No início do treinamento, a probabilidade de realizar todas as ações é quase igual. E o modelo tende a maximizar o estudo do ambiente, escolhendo uma ou outra ação do agente com igual probabilidade. No processo de treinamento do modelo, a distribuição probabilística das ações muda. A probabilidade de escolher ações lucrativas aumenta, enquanto não lucrativas, diminui. Isso reduz a tendência do modelo para estudo do ambiente. E o equilíbrio se desloca para o uso.
Devemos atentar para mais um ponto. Quando usamos a recompensa cumulativa, focamos em alcançar um resultado no final da sessão. E, quando fazemos isso, não avaliamos o impacto de cada etapa específica. Tal abordagem, por exemplo, pode ensinar nosso agente a manter posições não lucrativas em antecipação a uma reversão de tendência ou a fazer um grande número de negócios não lucrativos. Esses negócios serão cobertos por outros negócios lucrativos pouco frequentes, mas com alta lucratividade. Afinal, com o lucro final da sessão, o modelo considerará isso um resultado positivo e aumentará a probabilidade de efetuar esse tipo de negócios. Obviamente, o grande número de iterações tem o propósito de minimizar esse fator, uma vez que a capacidade que tem o método para estudar o ambiente deve ajudar o modelo a encontrar a estratégia ótima. Mas isso faz com que o processo de treinamento do modelo se prolongue.
Recapitulemos. Os modelos de aprendizado Q têm baixa dispersão, mas alto viés. Porém, o gradiente de política permite treinar um modelo com um pequeno viés e uma grande dispersão. Gostaríamos de poder treinar o modelo com dispersão e viés mínimos.
O gradiente de políticas constrói uma estratégia ampla sem levar em conta o impacto de cada etapa. Nós gostaríamos de receber o rendimento máximo em cada etapa, para isso usamos o aprendizado Q. Lembre a função de Bellman. Seu uso envolve a escolha da melhor ação em cada etapa.
A utilização de métodos de aproximação de função Q requer a definição da política de comportamento do agente na fase de criação do modelo. Mas preferimos que o próprio modelo determine a estratégia com base na experiência de interagir com o ambiente. E, claro, não gostaríamos de nos limitar a estratégias comportamentais deterministas. Isso nos permite implementar métodos de aprendizado de políticas.
É aqui que o desejo de combinar os dois métodos para obter melhores resultados se torna bastante óbvio.
2. Algoritmo ator-crítico de vantagem
As tentativas mais bem-sucedidas de combinar a aproximação da função de recompensa e o aprendizado de políticas deram como resultado os métodos da família ator-crítico. Hoje convido você a se iniciar no algoritmo do "ator-crítico de vantagem" (advantage ator-crítico, em inglês).
A família de métodos ator-crítico envolve o uso de dois modelos. O primeiro modelo, o ator, é responsável por escolher a ação do agente e é treinado por métodos de aproximação de funções de política. O outro, o crítico, é treinado por métodos de aprendizado Q e avalia as ações escolhidas pelo ator.
A primeira coisa que gostaríamos de fazer é reduzir a dispersão dos dados no modelo de política. Vamos dar outra olhada na função de perda de nosso modelo de política. Aqui multiplicamos o logaritmo da probabilidade prevista de que a ação selecionada ocorra pela recompensa cumulativa descontada. O valor da probabilidade prevista é normalizado no intervalo [0, 1].
![]()
Para reduzir a dispersão, podemos reduzir o valor da recompensa cumulativa. Mas devemos fazê-lo sem perturbar a influência das ações no resultado geral. E, com isso, é necessário observar a comparabilidade dos dados para diferentes sessões de treinamento do agente. Alternativamente, podemos sempre subtrair alguma constante fixa ou a recompensa média para toda a sessão.
![]()
A segunda propriedade que gostaríamos de acrescentar é ensinar o modelo a avaliar a contribuição de cada ação individual. À primeira vista, a simples ideia de desistir da recompensa cumulativa e usar para treinamento só a recompensa da transição atual pode acabar mal. Em primeiro lugar, obter uma grande recompensa na etapa atual não nos garante a mesma grande recompensa no futuro. Podemos obter uma grande recompensa por nos passarmos para um estado desfavorável, como conseguir o "queijo na ratoeira".
Por outro lado, a recompensa nem sempre depende da ação. Muitas vezes, pode-se cair em uma situação em que a recompensa depende mais do estado do ambiente do que da capacidade do agente de avaliar o estado em questão. Por exemplo, ao efetuar negócios na direção da tendência global, o agente pode aguardar as tendências corretivas contra a tendência e esperar que o preço se mova na direção certa. Em cujo caso, o agente não precisa analisar detalhadamente o estado atual para identificar tendências. Basta determinar corretamente a tendência global. Nesse caso, há uma grande probabilidade de entrar em uma posição que não esteja ao melhor preço. Afinal de contas, com a análise detalhada correta, poderia ter-se esperado por uma correção e entrado na posição a um preço melhor. Mas o risco de uma correção se transformar em uma mudança de tendência acarreta uma perda muito maior. E se isso acontecesse, sem esperar por uma reversão, a posição aberta causaria grandes perdas.
Portanto, seria útil comparar precisamente a recompensa cumulativa com algum resultado de referência. Mas onde podemos arranjá-lo? É aí que entra o crítico. É com a sua ajuda que avaliaremos o trabalho do nosso ator.
A ideia é que o modelo crítico seja treinado para avaliar o estado atual do ambiente, o quanto potencialmente o ator pode receber recompensas provenientes do estado atual antes do final da sessão. Ao ocorrer isso, o ator está aprendendo a selecionar ações que potencialmente renderão recompensas maiores do que a média das sessões de treinamento anteriores. Assim, substituímos a constante na fórmula da função de perda acima pela avaliação do estado.
![]()
Onde V(s) é a função de avaliação do estado do ambiente.
Para treinar a função de avaliação do estado, usamos a mesma raiz quadrada média do erro.
![]()
É importante dizer que, na prática, existem várias abordagens para construir um modelo usando esse algoritmo. Usamos duas redes neurais separadas. Uma para o ator e outra para o crítico. Mas muitas vezes é usada uma arquitetura de uma rede neural com duas saídas. A chamada rede neural "de duas cabeças", onde parte das camadas neurais é comum e é responsável pelo processamento dos dados iniciais. Aqui várias camadas de tomada de decisão são divididas em direções. Uma parte é responsável pela política do modelo (ator), enquanto a outra parte, pela avaliação do estado (crítico). Não se pode deixar de concordar que tanto o ator quanto o crítico trabalham com o mesmo estado do ambiente. Isso significa que a função de reconhecimento de estado pode ter um comum.
Além disso, há implementações on-line de treinamento de modelos advantage actor-critic. Nelas, por analogia com o aprendizado Q, a recompensa cumulativa é substituída pela soma da recompensa recebida na última transição, e da avaliação do estado subsequente, levando em consideração o fator de desconto. Então as funções de perda assumem a seguinte forma.
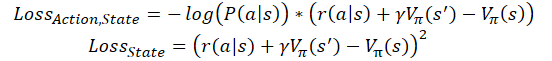
Onde ɣ é o fator de desconto.
Mas você tem que pagar pelo estudo on-line. Tal modelo tem um grande erro e é mais difícil de treinar.
3. Implementação
Uma vez iniciados nos aspectos teóricos do método, podemos prosseguir para a parte prática deste artigo e montar o treinamento do modelo usando as ferramentas MQL5. Antes de escrever o algoritmo descrito, é imporante dizer que esta implementação não exigirá nenhuma mudança fundamental na arquitetura de construção de nossos modelos. Não vamos construir um modelo de 2 cabeças. E nos limitaremos à construção de 2 redes neurais separadas, a do ator e a do crítico, usando os meios já existentes.
Além disso, não treinaremos modelos completamente novos. Em vez disso, usaremos 2 modelos dos últimos 2 artigos. O modelo do artigo aprendizado Q será usado como crítico. E o modelo do artigo de gradiente de política será empregado como ator.
Aqui é necessário mencionar alguns pequenos desvios em relação ao material teórico acima. O modelo do ator cumpre integralmente os requisitos do algoritmo considerado. Mas, em contraste com ele, o modelo de crítico que usamos é ligeiramente diferente da função de avaliação do estado do ambiente, descrita acima. A questão é que a avaliação do estado do ambiente é independente da ação que o agente toma. Afinal, o custo de um estado é o benefício máximo que nosso agente pode obter desse estado. E se olharmos para a função Q que treinamos anteriormente, o custo do estado será igual ao valor máximo do vetor de resultados de dada função. Porém, para o correto treinamento do modelo, teremos que levar em consideração a ação realizada pelo agente no estado analisado.
E agora proponho olhar para o código de implementação do método. Para treinar o modelo, criaremos um Expert Advisor com um nome eloquente, "Actor_Critic.mq5". O modelo de EA foi emprestado dos EAs de artigos anteriores. Conforme mencionado acima, usaremos 2 modelos pré-treinados. Os modelos foram treinados separadamente e salvos em arquivos diferentes. Sendo assim, primeiro definiremos os arquivos para carregar os modelos. Os nomes desses arquivos revelam claramente uma referência aos artigos anteriores mencionados.
#define ACTOR Symb.Name()+"_"+EnumToString((ENUM_TIMEFRAMES)Period())+"_REINFORCE" #define CRITIC Symb.Name()+"_"+EnumToString((ENUM_TIMEFRAMES)Period())+"_Q-learning"
Para 2 modelos, precisamos de 2 instâncias da classe de rede neural. Para transparência do código, os modelos serão nomeados de acordo com seu papel no algoritmo que está sendo construído.
CNet Actor; CNet Critic;
No método de inicialização do EA, carregamos os modelos e imediatamente comparamos os tamanhos das camadas dos dados de entrada e dos resultados. Ao carregar modelos, não podemos avaliar a comparabilidade dos modelos, isto é, examinar se podemos treiná-los com amostras comparáveis. Mas é nosso dever verificar a comparabilidade das arquiteturas dos modelos, em particular averiguamos o tamanho da camada de dados de entrada. Isso nos dará confiança de que ambos os modelos usam o mesmo padrão de descrição de estado para avaliar o estado do ambiente.
E depois verificamos o tamanho da camada de resultados de ambos os modelos, o que nos permitirá comparar a discrição das possíveis ações dos agentes.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ................ ................ ................ //--- float temp1, temp2; if(!Actor.Load(ACTOR + ".nnw", dError, temp1, temp2, dtStudied, false) || !Critic.Load(CRITIC + ".nnw", dError, temp1, temp2, dtStudied, false)) return INIT_FAILED; //--- if(!Actor.GetLayerOutput(0, TempData)) return INIT_FAILED; HistoryBars = TempData.Total() / 12; Actor.getResults(TempData); if(TempData.Total() != Actions) return INIT_PARAMETERS_INCORRECT; if(!vActions.Resize(SessionSize) || !vRewards.Resize(SessionSize) || !vProbs.Resize(SessionSize)) return INIT_FAILED; //--- if(!Critic.GetLayerOutput(0, TempData)) return INIT_FAILED; if(HistoryBars != TempData.Total() / 12) return INIT_PARAMETERS_INCORRECT; Critic.getResults(TempData); if(TempData.Total() != Actions) return INIT_PARAMETERS_INCORRECT; //--- ................ ................ ................ //--- return(INIT_SUCCEEDED); }
Ao fazer isso, não esquecemos de controlar o processo de execução das operações e salvar os dados necessários nas variáveis apropriadas. Em particular, salvamos o número de velas do padrão analisado, que corresponde ao tamanho da camada de dados de entrada dos modelos carregados.
A implementação do algoritmo de aprendizado do modelo foi feita diretamente na função Train. No início da função, como sempre, determinamos o intervalo da amostra de treinamento.
void Train(void) { //--- MqlDateTime start_time; TimeCurrent(start_time); start_time.year -= StudyPeriod; if(start_time.year <= 0) start_time.year = 1900; datetime st_time = StructToTime(start_time);
E realizamos o carregamento dos dados históricos. Ao fazer isso, devemos verificar o resultado de todas as operações.
int bars = CopyRates(Symb.Name(), TimeFrame, st_time, TimeCurrent(), Rates); if(!RSI.BufferResize(bars) || !CCI.BufferResize(bars) || !ATR.BufferResize(bars) || !MACD.BufferResize(bars)) { ExpertRemove(); return; } if(!ArraySetAsSeries(Rates, true)) { ExpertRemove(); return; } //--- RSI.Refresh(); CCI.Refresh(); ATR.Refresh(); MACD.Refresh();
Aqui estimamos a quantidade de dados carregados e preparamos variáveis locais.
int total = bars - (int)(HistoryBars + SessionSize+2); //--- CBufferFloat* State; float loss = 0; uint count = 0;
Em seguida, preparamos um sistema de laços para o treinamento do agente. O loop externo conta o número de épocas de treinamento. Assim, no corpo do loop, definimos o ponto inicial da sessão. Esse ponto inicial é escolhido aleatoriamente a partir dos dados históricos carregados. Ao escolher este ponto, 2 fatores são levados em consideração. Primeiro, o ponto inicial da sessão deve ser precedido por dados históricos suficientes para formar um padrão. E desde o ponto inicial da sessão até o final da amostra de treinamento, deve haver dados históricos suficientes para concluir a sessão.
for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int error_code; int shift = (int)(fmin(fabs(Math::MathRandomNormal(0, 1, error_code)), 1) * (total) + SessionSize);
Eu não escrevi o algoritmo de aprendizado on-line, já que estamos treinando o modelo com dados históricos. E usar uma sessão completa geralmente dá melhores resultados. Mas, ao mesmo tempo, o trabalho no mercado é interminável. Assim, resolvi fazer uma implementação em lote do algoritmo. Aqui o tamanho da sessão é limitado pelo tamanho do pacote de atualização de dados. E esse valor é especificado pelo usuário no parâmetro externo SessionSize.
Em seguida, criamos um loop aninhado para a iteração inicial da sessão. No corpo deste loop, primeiro criamos um objeto para registrar os parâmetros da descrição do estado do sistema. E não nos esquecemos de verificar o resultado da criação de um novo objeto.
States.Clear(); for(int batch = 0; batch < SessionSize; batch++) { int i = shift - batch; State = new CBufferFloat(); if(!State) { ExpertRemove(); return; }
Depois disso, salvamos os parâmetros do estado atual do ambiente, em outras palavras, vamos preparar um padrão para análise na etapa atual do algoritmo.
int r = i + (int)HistoryBars; if(r > bars) { delete State; continue; } for(int b = 0; b < (int)HistoryBars; b++) { int bar_t = r - b; float open = (float)Rates[bar_t].open; TimeToStruct(Rates[bar_t].time, sTime); float rsi = (float)RSI.Main(bar_t); float cci = (float)CCI.Main(bar_t); float atr = (float)ATR.Main(bar_t); float macd = (float)MACD.Main(bar_t); float sign = (float)MACD.Signal(bar_t); if(rsi == EMPTY_VALUE || cci == EMPTY_VALUE || atr == EMPTY_VALUE || macd == EMPTY_VALUE || sign == EMPTY_VALUE) { delete State; continue; } //--- if(!State.Add((float)Rates[bar_t].close - open) || !State.Add((float)Rates[bar_t].high - open) || !State.Add((float)Rates[bar_t].low - open) || !State.Add((float)Rates[bar_t].tick_volume / 1000.0f) || !State.Add(sTime.hour) || !State.Add(sTime.day_of_week) || !State.Add(sTime.mon) || !State.Add(rsi) || !State.Add(cci) || !State.Add(atr) || !State.Add(macd) || !State.Add(sign)) { delete State; break; } }
Verificamos se os dados salvos estão completos, e chamamos o método de propagação do modelo de política.
if(IsStopped()) { delete State; ExpertRemove(); return; } if(State.Total() < (int)HistoryBars * 12) { delete State; continue; } if(!Actor.feedForward(GetPointer(State), 12, true)) { delete State; ExpertRemove(); return; }
Em seguida, amostramos a ação do agente a partir da distribuição resultante.
Actor.getResults(TempData); int action = GetAction(TempData); if(action < 0) { delete State; ExpertRemove(); return; }
Determinamos a recompensa pela ação selecionada. É importante dizer que a política de recompensas não mudou nada desde os últimos experimentos do artigo anterior. Assim, pretendo obter resultados comparáveis quanto ao teste do método. Isso permitirá comparar o impacto da alteração do algoritmo de aprendizado no resultado final do modelo, em comparação com testes anteriores.
double reward = Rates[i - 1].close - Rates[i - 1].open; switch(action) { case 0: if(reward < 0) reward *= -20; else reward *= 1; break; case 1: if(reward > 0) reward *= -20; else reward *= -1; break; default: if(batch == 0) reward = -fabs(reward); else { switch((int)vActions[batch - 1]) { case 0: reward *= -1; break; case 1: break; default: reward = -fabs(reward); break; } } break; }
E salvamos os valores obtidos em buffers para usar posteriormente durante a atualização dos pesos do modelo.
if(!States.Add(State)) { delete State; ExpertRemove(); return; } vActions[batch] = (float)action; vRewards[SessionSize - batch - 1] = (float)reward; vProbs[SessionSize - batch - 1] = TempData.At(action); //--- }
Assim concluímos as iterações do primeiro loop aninhado que permite coletar informações sobre a sessão. E depois de iterar sobre todos os estados da sessão, obteremos um conjunto completo de dados para atualizar os modelos.
Em seguida, calculamos a recompensa descontada cumulativa para cada estado do ambiente.
vectorf rewards = vectorf::Full(SessionSize, 1); rewards = MathAbs(rewards.CumSum() - SessionSize); rewards = (vRewards * MathPow(vectorf::Full(SessionSize, DiscountFactor), rewards)).CumSum(); rewards = rewards / fmax(rewards.Max(), fabs(rewards.Min()));
Aqui vamos calcular o valor da função de perda e salvar os modelos ao obter melhores resultados.
loss = (fmin(count, 9) * loss + (rewards * MathLog(vProbs) * (-1)).Sum() / SessionSize) / fmin(count + 1, 10); count++; float total_reward = vRewards.Sum(); if(BestLoss >= loss) { if(!Actor.Save(ACTOR + ".nnw", loss, 0, 0, Rates[shift - SessionSize].time, false) || !Critic.Save(CRITIC + ".nnw", Critic.getRecentAverageError(), 0, 0, Rates[shift - SessionSize].time, false)) return; BestLoss = loss; }
Observem que salvamos os modelos antes de atualizar as matrizes de peso. Afinal, foi com esses parâmetros que o modelo alcançou os resultados que estimamos pela função perda. Depois de atualizar as matrizes, o modelo receberá os parâmetros atualizados e veremos os resultados do trabalho com novos parâmetros somente no final da próxima sessão.
Ao final das iterações da época de aprendizado, realizamos outro loop aninhado no qual efetuamos a atualização dos parâmetros do modelo. Aqui vamos extrair os estados médios do buffer em ordem e realizar uma propagação dos dois modelos com a retirada do estado. E, claro, não nos esquecemos de controlar o processo de execução das operações.
for(int batch = SessionSize - 1; batch >= 0; batch--) { State = States.At(batch); if(!Actor.feedForward(State) || !Critic.feedForward(State)) { ExpertRemove(); return; }
É importante referir que é obrigatória a implementação de propagação para cada modelo, mesmo se salvarmos todos os dados necessários nos buffers. A questão é que durante a retropropagação, o algoritmo de aprendizado usa dados intermediários dos cálculos das camadas neurais. Já para uma correta distribuição do gradiente de erro e, com ela, para uma correta atualização dos pesos, precisamos de um alinhamento claro da cadeia completa de todos os valores intermediários do modelo para cada estado.
Em seguida, atualizamos o parâmetro do crítico. E aqui podemos ver que a atualização do modelo se aplica apenas à ação selecionada pelo agente. Nesse caso, o gradiente das ações restantes é considerado zero. E essa diferença em relação ao material teórico descrito anteriormente é causada justamente pelo uso da função Q previamente treinada, que retorna a recompensa prevista dependendo da ação escolhida pelo agente. O treinamento da função de avaliação de estado, proposto pelos autores do método, não depende da ação a ser tomada e não requer tal detalhamento.
Critic.getResults(TempData); float value = TempData.At(TempData.Maximum(0, 3)); if(!TempData.Update((int)vActions[batch], rewards[SessionSize - batch - 1])) { ExpertRemove(); return; } if(!Critic.backProp(TempData)) { ExpertRemove(); return; }
Após atualizar com sucesso os parâmetros do crítico, atualizamos os parâmetros do ator da mesma forma. Aqui, conforme mencionado acima, para avaliar a ação escolhida pelo agente, utilizamos o valor máximo do vetor de resultados da função Q para o estado analisado do ambiente.
if(!TempData.BufferInit(Actions, 0) || !TempData.Update((int)vActions[batch], rewards[SessionSize - batch - 1] - value)) { ExpertRemove(); return; } if(!Actor.backProp(TempData)) { ExpertRemove(); return; } } PrintFormat("Iteration %d, Cummulative reward %.5f, loss %.5f", iter, total_reward, loss); }
Após a conclusão de todas as iterações de atualização dos parâmetros do modelo, exibimos uma mensagem informativa ao usuário e passamos para a próxima época.
O processo de treinamento do modelo termina após o número total de épocas ter sido concluído, a menos que a execução seja interrompida anteriormente pelo usuário.
Comment(""); //--- ExpertRemove(); }
As operações de função são concluídas limpando o campo de comentário e chamando a função de desligamento do Expert Advisor.
O código completo do EA pode ser encontrado no anexo.
4. Teste
Depois de criar o EA de treinamento de modelo, realizamos um teste completo do método advantage actor-critic . Primeiro, iniciamos o processo de treinamento do modelo, mais precisamente, rodamos o treinamento adicional de modelos dos 2 artigos anteriores
Realizamos o treinamento com o EURUSD, timeframe H1, histórico dos últimos 2 anos. Usamos os parâmetros padrão do indicador. Pode-se observar que os parâmetros de treinamento dos modelos são utilizados sem alteração ao longo da série de artigos.
Como vantagem do retreinamento dos modelos dos artigos anteriores, podemos mencionar o fato de podermos utilizar os EAs de teste do artigo anterior para verificar seus resultados de treinamento. Eu fiz isso. Depois de treinar o modelo, peguei o modelo de política retreinado e rodei o EA "REINFORCE-test.mq5" no testador de estratégia usando o modelo mencionado. O algoritmo para sua construção foi descrito no artigo anterior. E seu código completo pode ser encontrado no anexo.
Abaixo está um gráfico do balanço do EA durante os testes. É importante notar que o balanço aumentou bastante uniformemente durante o teste. Observe que o modelo foi testado com dados não incluídos no conjunto de treinamento. O que fala sobre a consistência da abordagem para construir um sistema de negociação. Para uma verificação impecável do trabalho do modelo, todas as operações foram realizadas com um lote mínimo fixo sem o uso de stop loss e take profit. O uso de tal EA é altamente desencorajado para negociação real, mas demonstra bem o trabalho do modelo treinado.

No gráfico de preços, pode-se ver com que rapidez os negócios perdedores são fechados e as posições lucrativas são mantidas um pouco. Aqui é necessário prestar atenção para que todas as operações sejam realizadas na abertura de uma nova vela. Ao fazer isso, pode-se notar várias operações de negociação realizadas quase na abertura das velas (de fractal) de reversão.

Em geral, durante o processo de teste, o EA apresentou um Fator de Lucro no nível de 2,20. A parcela de transações lucrativas ultrapassou 56%. Ao mesmo tempo, a negociação lucrativa média excedeu a negociação perdida média em 70%.

Aqui, devo alertá-lo contra o uso deste Expert Advisor para negociação real, pois ele foi criado apenas para testar o modelo. Em primeiro lugar, o período de teste do EA é muito curto para transferi-lo para negociação real. Em segundo lugar, o EA é desprovido de qualquer bloqueio de gerenciamento de dinheiro e gerenciamento de risco. Todas as operações de negociação são desprovidas de stop loss e take profit, o que é altamente desencorajado para uso em negociação real.
Considerações finais
Neste artigo, nos iniciamos no advantage actor-critic, que é outro algoritmo de aprendizado por reforço. Ele combina abordagens previamente estudadas, aprendizado Q e gradiente de políticas no seu melhor. Isso permite elevar a fasquia em termos de resultados obtidos no processo de treinamento de modelos por reforço. Construímos o algoritmo considerado usando MQL5. Treinamos o modelo com dados históricos reais. De acordo com os resultados do teste, o modelo mostrou capacidade de gerar lucros, o que nos permite tirar conclusões sobre a possibilidade de construir sistemas de negociação usando esse algoritmo de treinamento de modelos.
Devo dizer que, atualmente, a família de algoritmos ator-crítico provavelmente dá os melhores resultados de entre os métodos de aprendizado por reforço. No entanto, antes de usar os modelos para negociação real, eles precisam de um longo treinamento e testes completos, usando vários testes de estresse.
Referências
- Asynchronous Methods for Deep Reinforcement Learning
- Redes neurais de maneira fácil (Parte 26): aprendizado por reforço
- Redes neurais de maneira fácil (Parte 27): aprendizado Q profundo (DQN)
- Redes neurais de maneira fácil (Parte 28): algoritmo de gradiente de política
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Actor-Critic.mq5 | EA | EA para treinamento de modelos |
| 2 | REINFORCE-test.mq5 | EA | EA para prova do modelo no testador de estratégia |
| 3 | NeuroNet.mqh | Biblioteca de classes | Biblioteca para preparar modelos de redes neurais |
| 4 | NeuroNet.cl | Biblioteca | Biblioteca de código do programa OpenCL para preparar modelos de redes neurais |