Programmazione basata su automi come nuovo approccio alla creazione di sistemi di trading automatizzati
MT5 | 17 dicembre, 2021
ἓν οἶδα ὅτι οὐδὲν οἶδα ( ο φιλόσοφος Σωκράτης )
So di non sapere nulla (il filosofo Socrate)
Introduzione
Per cominciare, questo argomento è completamente nuovo per i trader che sviluppano EA utilizzando il linguaggio MetaQuotes 4/5 (MQL4/5). Ho potuto vederlo di persona quando ho provato a fare una ricerca pertinente sul sito di MetaQuotes. Non c'è nulla su questo argomento.
Ogni trader crea il proprio Expert Advisor, il quale richiede un approccio serio per affrontare tutti i tipi di problemi associati alla programmazione e alla logica del programma molto complicata. Alla fine, il programma dovrebbe funzionare da solo come un orologio in qualsiasi situazione standard e di forza maggiore.
Ma come si può comprendere tutto? Questo è estremamente difficile, motivo per cui i sistemi di controllo automatico richiedono una corretta programmazione di tutti i sistemi di controllo che possono essere raggiunti al meglio utilizzando l'unica tecnologia di programmazione appropriata della programmazione basata su automi. Negli ultimi anni, una grande attenzione è stata rivolta allo sviluppo di tecnologie di programmazione per sistemi embedded e real-time che stabiliscono requisiti elevati per la qualità del software.
Nel 1991, l'autore russo A.A. Shalyto (lettore, professore, dottore in scienze ingegneristiche, capo del dipartimento Head of the "Programming Technologies" presso la SPbSU ITMO), ha sviluppato una tecnologia di programmazione che ha chiamato "programmazione basata su automi". Credo che i lettori possano trovare interessante vedere quanto può essere semplice la programmazione basata su automi o la tecnologia SWITCH. Permette di rendere lo sviluppo di MTS utilizzando il linguaggio MetaQuotes così conveniente che non potrebbe essere migliore di così. E si fonde perfettamente nel sistema del processo decisionale complesso.
1. Risolvere il problema
Un sogno a lungo accarezzato da tutti gli ideatori di problemi e sviluppatori di software deve essere quello di avere una soluzione pianificata al problema (algoritmo) e un'implementazione di quell'algoritmo pienamente coerente con esso. Ma non sembra funzionare in questo modo per originatori e sviluppatori. Gli algoritmi tendono a tralasciare ciò che è importante per gli sviluppatori per l'implementazione, mentre il testo del programma di per sé ha poca somiglianza con l'algoritmo.
Pertanto, ci sono due algoritmi: uno è su carta (per registrare e documentare soluzioni di progettazione), che di solito rappresenta un certo risultato di progettazione invece dei metodi impiegati per ottenere un determinato risultato, mentre il secondo algoritmo è nella mente dello sviluppatore (che è, tuttavia, anche salvato testualmente).
La versione finale del testo del programma è spesso seguita da tentativi di modificare la documentazione, per cui molte cose non vengono ancora prese in considerazione. In questo caso, la logica del programma può probabilmente essere diversa dalla logica dell'algoritmo, dimostrando così una mancanza di corrispondenza. Dico intenzionalmente "probabile" perché nessuno controllerà mai il testo del programma di qualcuno.
Se il programma è grande, è impossibile verificare se corrisponde all'algoritmo solo dal testo. L'accuratezza dell'implementazione può essere verificata utilizzando una procedura chiamata "test". Fondamentalmente, controlla come lo sviluppatore ha afferrato l'algoritmo (disposto su carta), lo ha trasformato in un altro algoritmo nella sua mente e lo ha prodotto come un programma. Alla fine, lo sviluppatore è l'unico detentore di informazioni preziose sulla logica e tutto ciò che è stato coniato prima dell'implementazione diventa assolutamente irrilevante.
Non è che lo sviluppatore possa ammalarsi (o ... dimettersi). Il punto è che la logica del programma sottostante sarebbe diversa con ogni sviluppatore, a seconda della loro intelligenza e conoscenza di un linguaggio di programmazione. In ogni caso, lo sviluppatore introduce e utilizza molte variabili intermedie come ritiene opportuno. E se il programma è grande e logicamente complesso, sarà necessario uno specialista più qualificato per trovare i glitch (e qui non intendo glitch del sistema operativo o uso scorretto delle funzioni del linguaggio, ma piuttosto un'implementazione impropria in termini di logica) e risolverlo attraverso il testo del programma stesso.
La maggior parte degli sviluppatori non è a dir poco entusiasta di scrivere algoritmi prima di programmarli (o addirittura di disegnarli su carta), il che è probabilmente dovuto al fatto che hanno ancora bisogno di pensare a qualcosa di proprio lungo il percorso. In effetti, perché perdere tempo a disegnare alcuni rettangoli, diamanti e frecce quando è meglio procedere immediatamente alla programmazione e quindi delineare un algoritmo in qualche modo simile o molto generale nella documentazione?
Tutti si sono abituati - gli sviluppatori lo fanno perché è più facile in questo modo, mentre i creatori di problemi non hanno sempre competenze di programmazione nella misura richiesta e, anche nel caso in cui lo facciano, semplicemente non sono in grado di apportare una modifica tempestiva a ciò che gli sviluppatori presenteranno. Anche i comodi ambienti di programmazione contribuiscono alla validità dell'ordine di sviluppo specificato. Strumenti avanzati per il debug e il monitoraggio dei valori delle variabili ci danno speranza per il rilevamento di eventuali errori nella logica.
Mentre il tempo sta scivolando via e la scadenza del progetto si avvicina, lo sviluppatore è seduto e disegna su un "tovagliolo" soluzioni a un determinato problema logico che, a proposito, deve ancora essere implementato, per non parlare degli errori trascurati durante i test per i test segue praticamente lo stesso scenario (caotico) ... Questa è la situazione attuale. C'è una soluzione o può almeno essere migliorata? Sembra che qualcosa di importante si perda nella transizione da un algoritmo strutturato in modo standard al codice del programma.
2. Parte logica del programma
L'autore della "programmazione basata su automi" ha proposto il seguente concetto della parte logica ideale di un programma. L'intera logica del programma si basa sullo switch. In poche parole, qualsiasi algoritmo di controllo (automa) può essere implementato come mostrato di seguito (non pensare molto al significato dei commenti a questo punto, basta dare un'occhiata alla struttura).
switch(int STATUS ) // Мulti-valued global state variable of the automaton. { case 0: // start // Checking arc and loop conditions (in order of priority), // transition (change of the value of the variable STATUS) // and execution of arc and loop actions (output function execution); // logging transitions and actions if the condition is met. 0 // Calling nested automata. // Execution of output functions in the state. break ; case 1: // Checking arc and loop conditions (in order of priority), // transition (change of the value of the variable STATUS) // and execution of arc and loop actions (output function execution); // logging transitions and actions if the condition is met. // Calling nested automata. // Execution of output functions in the state. break ; ********* ********* ********* case N-1: // Checking arc and loop conditions (in order of priority), // transition (change of the value of the variable STATUS) // and execution of arc and loop actions (output function execution); // logging transitions and actions if the condition is met. // Calling nested automata. // Execution of output functions in the state. break ; case N: // Checking arc and loop conditions (in order of priority), // transition (change of the value of the variable STATUS) // and execution of arc and loop actions (output function execution); // logging transitions and actions if the condition is met. // Calling nested automata. // Execution of output functions in the state. break ; }
3. Programmazione basata su automi come spiegato dall'autore A.A. Shalyto ·
Indipendentemente dalle tecniche di sviluppo, qualsiasi programma ha stati determinati da tutti i suoi valori di dati in qualsiasi momento specifico. Ci possono essere centinaia e persino migliaia di variabili e diversi flussi di controllo in un grande programma applicativo. Un set completo di queste variabili descrive lo stato del programma applicativo in un momento specifico.
Lo stato del programma può essere trattato in modo più semplice, come una raccolta di valori di tutte le variabili di controllo, quelle che prendono parte a tutte le condizioni di transizione. Una modifica del valore di una delle variabili di controllo comporterà quindi una modifica dello stato del programma e il numero di stati del programma sarà determinato dal numero massimo possibile di combinazioni di valori delle variabili di controllo che si verificano durante l'operazione del programma. Supponiamo che in un programma vengano utilizzate solo variabili di controllo binarie (flag). Il numero di stati del programma contenente n variabili di controllo binarie si troverà in questo caso nell'intervallo da n a 2n.
Può darsi che lo sviluppatore abbia previsto reazioni a tutte le combinazioni di valori variabili di controllo (2n combinazioni nel nostro caso). Tuttavia, è più probabile che alcune combinazioni di valori variabili di controllo (fino a 2n-n) si siano rivelate non specificate. Quindi, se si verifica una combinazione inaspettata di azioni di input, il programma può passare a uno stato non specificato.
Ha lo stesso effetto dell'inazione di un EA per un trader nei seguenti eventi:
- divario,
- perdita del deposito,
- cadere in una situazione di saldo negativo con successiva Margin Call,
- non ottenere un buon profitto andando a zero e più in rosso,
- apertura e chiusura errate di long e short,
- altre situazioni ovviamente avverse.
Tali stati sono chiamati "non visualizzati". La complessità causa la difficoltà di enumerare, tanto meno comprendere, tutti i possibili stati del programma portando alla sua inaffidabilità... La complessità della struttura è la fonte di stati non visivi che costituiscono botole di sicurezza. Il comportamento del programma in uno stato non specificato può variare da errori di protezione della memoria all'estensione del programma a nuove funzioni e alla creazione di effetti collaterali di varia natura.
Molti utenti di PC e probabilmente tutti gli sviluppatori di software si sono imbattuti in situazioni in cui un programma in uso o in fase di sviluppo entra in uno stato non specificato.
Per eliminare la possibilità stessa di stati non specificati nel programma, tutti gli stati richiesti dovrebbero essere esplicitamente specificati già in fase di progettazione e solo una variabile di controllo multivalore dovrebbe essere utilizzata per differenziarli. È quindi necessario identificare tutte le possibili transizioni tra gli stati e sviluppare un programma in modo che non possa "andare fuori strada".
Sono necessari tre componenti per raggiungere il rigore nello sviluppo del comportamento del programma:
- Modello matematico che consente di identificare in modo inequivocabile gli stati del programma e le possibili transizioni tra di essi;
- Notazione grafica per quel modello;
- Metodo universale per l'implementazione di algoritmi espressi in questa notazione.
Un automa finito basato sulla nozione di "stato" si propone di essere usato come modello matematico. La programmazione basata su automi supporta le fasi di sviluppo del software come progettazione, implementazione, debug e documentazione.
Mentre il termine "evento" sta diventando sempre più comunemente usato nella programmazione negli ultimi anni, l'approccio proposto si basa sulla nozione di "stato". Dopo averlo accoppiato con il termine "azione di input" che può essere una variabile di input o un evento, è possibile introdurre il termine "automa senza output". Quest'ultimo è seguito dal termine "azione di output" e la nozione di automa (deterministico finito) è ulteriormente introdotta. L'area di programmazione basata su questo concetto è quindi chiamata programmazione basata su automi e il rispettivo processo di sviluppo è indicato come progettazione di programmi basati su automi.
L'approccio specificato è peculiare in quanto, quando viene applicato, gli automi sono rappresentati da grafici di transizione. Per distinguere tra i loro nodi, viene introdotto il termine "assegnazione di stato". Quando si sceglie una "assegnazione di stato multivalore", gli stati il cui numero coincide con il numero di valori che la variabile selezionata può assumere, possono essere differenziati utilizzando una sola variabile. Questo fatto ha permesso di introdurre nella programmazione il termine «osservabilità del programma».
La programmazione nell'ambito dell'approccio proposto viene effettuata attraverso "stati" piuttosto che "variabili" (flag) che aiutano a comprendere e specificare meglio il problema e le sue componenti. Il debug in questo caso viene eseguito registrando in termini di automi.
Poiché l'approccio di cui sopra propone di passare dal grafico di transizione al codice del programma utilizzando un metodo formale e isomorfo, sembra più ragionevole farlo applicando strutture di switch quando vengono utilizzati linguaggi di programmazione di alto livello. Per questo motivo si è deciso di utilizzare il termine «tecnologia SWITCH» quando ci si riferisce al paradigma di programmazione basato su automi.
4. Programmazione esplicita basata sullo stato
L'applicazione dell'approccio basato sugli automi è stata ulteriormente estesa ai sistemi basati su eventi che sono anche chiamati "reattivi". I sistemi reattivi interagiscono con l'ambiente utilizzando messaggi alla velocità impostata dall'ambiente (un EA può essere incluso nella stessa classe).
Lo sviluppo di sistemi basati su eventi che utilizzano automi è stato reso possibile utilizzando l'approccio procedurale, da cui deriva il nome di programmazione esplicita basata sullo stato. Le azioni di output sono in questo metodo assegnate ad archi, loop o nodi di grafici di transizione (vengono utilizzati automi misti - automi di Moore e Mealy). Ciò consente di ottenere una rappresentazione compatta della sequenza di azioni che sono reazioni ad azioni di input rilevanti.
L'approccio proposto alla programmazione di una data classe di sistemi presenta una maggiore centralizzazione della logica dovuta all'eliminazione dei gestori di eventi e alla generazione di un sistema di automi interconnessi chiamati dai gestori. L'interazione tra automi in un tale sistema può essere ottenuta nidificando, chiamando e scambiando numeri di stati.
Il sistema di automi interconnessi forma una parte di programma indipendente dal sistema, mentre una parte dipendente dal sistema è formata da funzioni di azione di input e output, gestori, ecc.
Un'altra caratteristica chiave dell'approccio dato è che, quando viene applicato, gli automi vengono utilizzati in modo trino:
- per specificazione;
- per l'implementazione (rimangono nel codice del programma);
- per la registrazione in termini di automi (come specificato sopra).
Quest'ultimo consente di controllare l'accuratezza del funzionamento del sistema di automi. La registrazione viene eseguita automaticamente sulla base del programma sviluppato e può essere utilizzata per problemi su larga scala con logica di programma complessa. Ogni registro può in questo caso essere considerato come uno script pertinente.
I log permettono di monitorare il programma in funzione e illustrare il fatto che gli automi non sono 'immagini', ma vere e proprie entità attive. Si propone di utilizzare un approccio basato su automi non solo durante la creazione di un sistema di controllo, ma anche durante la modellazione di oggetti di controllo.
5. Concetti di base della programmazione basata su automi
Il concetto di base della programmazione basata su automi è STATE. La proprietà principale dello stato del sistema in qualsiasi momento specifico t0 è quella di "separare" il futuro (t > t0) dal passato (t < t0), nel senso che lo stato corrente contiene tutte le informazioni sul passato del sistema, le quali sono necessarie per determinare le sue reazioni a qualsiasi azione di input generata in un dato momento t0.
Quando si utilizza il termine STATE non è richiesta la conoscenza dei dati storici. Lo stato può essere considerato come una caratteristica speciale che combina implicitamente tutte le azioni di input del passato che influenzano la reazione dell'entità nel momento presente. La reazione ora dipende solo dall'azione di input e dallo stato corrente.
La nozione di "azione di input" è anche una delle nozioni chiave nella programmazione basata su automi. Un'azione di input è più comunemente un vettore. I suoi componenti sono divisi in eventi e variabili di input, a seconda del significato e del meccanismo di generazione.
La combinazione dell'insieme finito di stati e dell'insieme finito di azioni di input forma un automa (finito) senza output. Tale automa reagisce alle azioni di input modificando il suo stato attuale in un certo modo. Le regole in base alle quali gli stati possono essere modificati sono chiamate funzione di transizione dell'automa.
Ciò che viene definito automa (finito) nella programmazione basata su automi è fondamentalmente la combinazione di "automa senza output" e "azione di input". Tale automa reagisce all'azione di input non solo cambiando il suo stato, ma anche generando determinati valori alle uscite. Le regole per generare azioni di output sono chiamate funzione di output dell'automa.
Quando si progetta un sistema con un comportamento complesso, è necessario prendere come punto di partenza gli oggetti di controllo esistenti con un certo insieme di operazioni e un determinato insieme di eventi che possono sorgere nell'ambiente esterno(mercato).
In pratica, la progettazione è più comunemente premessa su oggetti ed eventi di controllo:
-
I dati iniziali del problema non sono semplicemente una descrizione verbale del comportamento target del sistema, ma anche una specifica (più o meno) accurata dell'insieme di eventi in arrivo al sistema dall'ambiente esterno e un gran numero di richieste e comandi di tutti gli oggetti di controllo.
-
Viene creato un set di stati di controllo.
-
Ad ogni richiesta di oggetti di controllo viene assegnata una variabile di input corrispondente dell'automa, mentre ad ogni comando viene assegnata una variabile di output corrispondente. L'automa che garantirà un comportamento di sistema richiesto è costruito in base a stati di controllo, eventi, variabili di input e output.
6. Caratteristiche e vantaggi del programma
La prima caratteristica di un programma basato su automi è che la presenza di un ciclo esterno è essenziale. Fondamentalmente non sembra esserci nulla di nuovo; la cosa principale qui è che questo ciclo sarà l'unico nella parte logica dell'intero programma! (cioè un nuovo tick in entrata.)
La seconda caratteristica segue la prima. Ogni automa contiene una struttura di commutazione (in realtà, è praticamente costituita da essa) che comprende tutte le operazioni logiche. Quando viene chiamato un automa, il controllo viene trasferito a una delle etichette "caso" e, seguendo le azioni pertinenti, l'operazione dell'automa (sottoprogramma) viene completata fino all'avvio successivo. Queste azioni consistono nel verificare le condizioni di transizione e se una determinata condizione viene soddisfatta, vengono chiamate le funzioni di output pertinenti e lo stato dell'automa viene modificato.
La principale conseguenza di tutto quanto detto sopra è che l'implementazione di un automa non è solo semplice, ma soprattutto che il programma può fare a meno di molte variabili logiche intermedie (flag) la cui funzionalità in ogni automa è fornita da una variabile di stato multivalore.
L'ultima affermazione è difficile da credere in quanto ci siamo abituati a utilizzare molte variabili globali e locali (flag) senza pensare troppo. Come possiamo farne a meno?! Si tratta molto spesso di flag che segnalano al programma che una condizione è soddisfatta. Il flag viene impostato (su TRUE) quando lo sviluppatore lo ritiene necessario, ma poi (di solito solo dopo che il flag inizia a dare origine a effetti desiderati essendo sempre TRUE) si tenta dolorosamente di ripristinarlo su FALSE altrove nel programma.
Sembra familiare, non è vero? Ora dai un'occhiata all'esempio e osserva: qui non vengono utilizzate variabili aggiuntive; la modifica riguarda solo il valore del numero di stato e solo quando è soddisfatta una condizione logica. Non è un degno sostituto dei flag?!
L'algoritmo svolge un ruolo importante nella creazione di una parte logica di un programma. La frase chiave da ricordare qui è "parte logica". Lo stato è alla base di tutto in questo caso. Un'altra parola che dovrebbe essere aggiunta è "in attesa". E, a mio parere, otteniamo una definizione abbastanza adeguata di "stato di attesa". Quando siamo nello stato, attendiamo la comparsa di azioni di input (attributi, valori o eventi). L'attesa può essere breve o lunga. O, in altre parole, ci sono stati che possono essere instabili e stabili.
La prima proprietà dello stato è il fatto che si attende un insieme limitato di azioni di input nello stato. Qualsiasi algoritmo (e ovviamente qualsiasi programma) ha informazioni di input e output. Le azioni di output possono essere suddivise in due tipi: variabili (ad es. operazioni sulle proprietà dell'oggetto) e funzioni (ad es. funzione di avvio della chiamata dell'applicazione, funzione di report, ecc.).
La seconda proprietà dello stato è la fornitura di un insieme di valori accurati delle variabili di output. Ciò rivela una circostanza molto semplice ma estremamente importante: tutti i valori delle variabili di output possono essere determinati in qualsiasi momento poiché l'algoritmo (programma) si trova in un certo stato in ogni momento.
Il numero di stati è limitato, così come il numero di valori delle variabili di output. La funzione per la registrazione delle transizioni è perfettamente integrata nella funzione dell'automa e la sequenza delle transizioni tra gli stati, così come la consegna delle azioni di output, possono di conseguenza essere sempre determinate.
L'elenco completo delle funzionalità è fornito nella sezione 2. Le caratteristiche della tecnologia proposta e l'elenco completo dei vantaggi sono disponibili nella sezione 3. Vantaggi della tecnologia proposta. Questo articolo semplicemente non può coprire la grande quantità di informazioni sull'argomento! Dopo uno studio approfondito di tutta la letteratura di ricerca scritta da Anatoly Shalyto, tutte le domande teoriche dovrebbero essere indirizzate a lui personalmente all’indirizzo shalyto@mail.ifmo.ru.
E, essendo l'utente delle sue idee scientifiche pur avendo in mente i nostri obiettivi e problemi, darò più avanti tre esempi della mia implementazione della tecnologia di programmazione basata su automi.
7. Esempi di programmazione basata su automi
7.1. Esempio di comprensione
Lo stato è solo una modalità in cui esiste il sistema. Ad esempio, l'acqua esiste in 3 stati: solido, liquido o gassoso. Passa da uno stato all'altro quando influenzato da una variabile: la temperatura (a pressione costante).
Supponiamo di avere un grafico temporale di Temperatura (t) (nel nostro caso - il valore del prezzo):

int STATUS=0; // a global integer is by all means always a variable !!! STATUS is a multi-valued flag //----------------------------------------------------------------------------------------------// int start() // outer loop is a must { switch(STATUS) { case 0: //--- start state of the program if(T>0 && T<100) STATUS=1; if(T>=100) STATUS=2; if(T<=0) STATUS=3; break; case 1: //--- liquid // set of calculations or actions in this situation (repeating the 1st status -- a loop in automata-based programming) // // and calls of other nested automata A4, A5; if(T>=100 ) { STATUS=2; /* set of actions when transitioning, calls of other nested automata A2, A3;*/} if(T<0) { STATUS=3; /* set of actions when transitioning, calls of other nested automata A2, A3;*/} // logging transitions and actions when the condition is met. break; case 2: //--- gas // set of calculations or actions in this situation (repeating the 2nd status -- a loop in automata-based programming) // // and calls of other nested automata A4, A5; if(T>0 && T<100) { STATUS=1; /* set of actions when transitioning, calls of other nested automata A2, A3;*/} if(T<=0) { STATUS=3; /* set of actions when transitioning, calls of other nested automata A2, A3;*/} // logging transitions and actions when the condition is met. break; case 3: //--- solid // set of calculations or actions in this situation (repeating the 3rd status -- a loop in automata-based programming) // // and calls of other nested automata A4, A5; if(T>0 && T<100) {STATUS=1; /* set of actions when transitioning, calls of other nested automata A2, A3;*/} if(T>=100) {STATUS=2; /* set of actions when transitioning, calls of other nested automata A2, A3;*/} // logging transitions and actions when the condition is met. break; } return(0); }
Il programma può essere reso più sofisticato aggiungendo il parametro di pressione P e nuovi stati e introducendo una dipendenza complessa dimostrata nel grafico:

Questo automa ha 32 = 9 condizioni di transizione, quindi nulla può essere lasciato fuori o trascurato. Questo stile può anche essere molto conveniente quando si scrivono istruzioni e leggi! Qui non sono consentite scappatoie e aggiramenti delle leggi: tutte le combinazioni di varianti di successione di eventi devono essere coperte e tutti i casi descritti.
La programmazione basata su automi ci impone di tenere conto di tutto, anche se alcune varianti di successione di eventi non sarebbero altrimenti pensate ed è per questo che è lo strumento principale quando si controllano leggi, istruzioni e sistemi di controllo per coerenza e integrità. C'è anche una legge matematica:
Diagramma di transizione: N = 3 stati, il numero di transizioni e loop è N2 = 9 (uguale al numero di frecce).
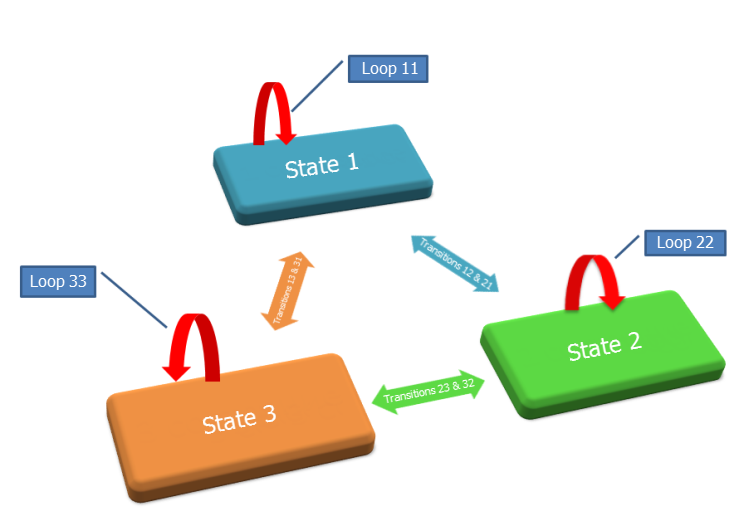
Se il numero di variabili nell'esempio era diverso, allora:
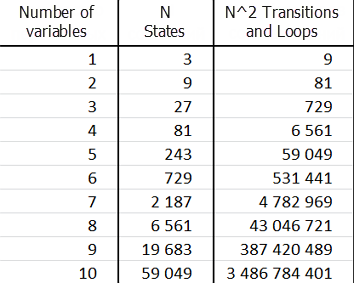
Mostra che tutti i valori calcolati nella tabella aumentano esponenzialmente, cioè la progettazione è un processo complicato che richiede accuratezza nella selezione delle principali variabili sistemiche.
Anche se ci sono solo due parametri, è molto difficile descrivere tutto! Tuttavia, in pratica, è tutto molto più facile! A seconda della logica e del significato, le transizioni del 50-95% non possono esistere fisicamente e il numero di stati è anche inferiore del 60-95%. Questa analisi della logica e del significato riduce notevolmente la difficoltà di descrivere tutte le transizioni e gli stati.
Nei casi più complicati, è necessario calcolare il numero massimo di stati per tutti i dati di input e output noti in un EA. La soluzione a questo problema può essere trovata applicando il calcolo combinatorio e le funzioni di combinazione, permutazione, disposizione e calcolo combinatorio enumerativo .
7.2. Relè con isteresi
La programmazione di relè, trigger, registri, contatori, decodificatori, comparatori e altri elementi del sistema di controllo digitale e analogico non lineare può essere molto comoda in un EA.

- xmax = 100 - il valore massimo di prelievo;
- xmin = -100 - il valore minimo di prelievo;
- x = x(t) - segnale all'ingresso;
- Y = Y(t) - segnale all'uscita.
int status=0; // at the beginning of the program we globally assign //------------------------------------------------------------------// switch(status) { case 0: // start Y=x; if(x>xmax) {status=1;} if(x<xmin) {status=2;} break; case 1: //++++++++++++++++++++ if(x>xmax) Y=x; if(x<xmax) Y=xmin; if(x<=xmin) {status=2; Y=xmin;} break; case 2: //-------------------- if(x<xmin) Y=x; if(x>xmin) Y=xmax; if(x>=xmax) {status=1; Y=xmax;} break; }
La caratteristica del relè:
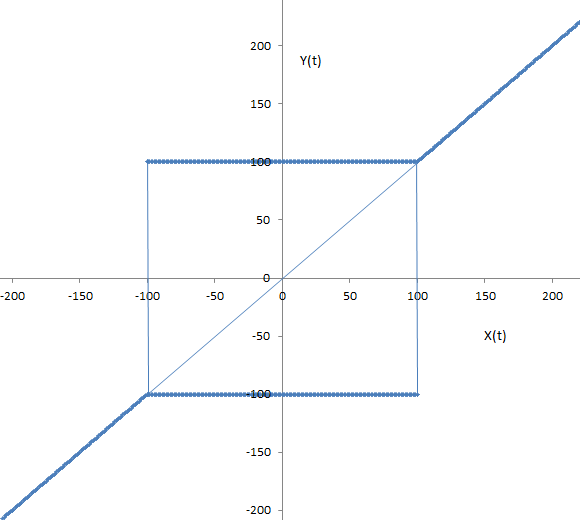
7.3. Modello per 9 Stati e 81 varianti di successione degli eventi
Y è lo stato di input corrente dell'automa da 1 a 9. Il valore di Y viene generato nell'EA al di fuori del sottoprogramma indicato. MEGASTATUS è lo stato passato di Y.
int MEGASTATUS=0; // at the beginning of the program we globally assign //---------------------------------------------------------------------// void A0(int Y) // automaton template { switch(MEGASTATUS) { case 0: // start MEGASTATUS=Y; break; case 1: // it was the past // it became current, repeating if(Y=1) { /*set of actions in this situation, calls of other nested automata A2, A3, ... */ } // Loop// // new current if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 2: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } //Loop// if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } // e.g. if the transition from 2 to 6 is in essence impossible or does not exist, do not write anything if(Y=6) { /* set of actions in this situation */ } // the automaton will then be reduced but the automaton template shall be complete to count in everything if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 3: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } //Loop// if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 4: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } //Loop// if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 5: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } //Loop// if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 6: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } //Loop// if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 7: // it was the past //it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } //Loop// if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 8: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } //Loop// if(Y=9) { /* set of actions in this situation */ } // logging transitions and actions when the condition is met. break; case 9: // it was the past // it has become current if(Y=1) { /* set of actions in this situation */ } if(Y=2) { /* set of actions in this situation */ } if(Y=3) { /* set of actions in this situation */ } if(Y=4) { /* set of actions in this situation */ } if(Y=5) { /* set of actions in this situation */ } if(Y=6) { /* set of actions in this situation */ } if(Y=7) { /* set of actions in this situation */ } if(Y=8) { /* set of actions in this situation */ } if(Y=9) { /* set of actions in this situation */ } //Loop// // logging transitions and actions when the condition is met. break; } MEGASTATUS=Y; }
7.4. Automa del lettore audio
Esaminiamo un semplice lettore audio.
Questo dispositivo può trovarsi in 6 stati:
- Pronto;
- Nessuna traccia;
- Riprodurre;
- Avanti veloce;
- Riavvolgimento;
- Pausa.
Il sistema di controllo del lettore audio è rappresentato da un automa. I pulsanti premuti sono considerati eventi che hanno effetto sull'automa. Le transizioni tra tracce, riproduzione, controllo del display, ecc. sono azioni di output.
switch(STATUS) { case 0: //--- "Ready" if(Event == 3) { STATUS = 3; } //«>>» button pressed if(Event == 6) { STATUS = 1; } //Audio file not found if(Event == 1) { STATUS = 2; } //«PLAY» button pressed z1(); // Set the indicator to the initial state break; case 1: //--- "No Track" z6(); // Give the «No Track» message break; case 2: //--- "Playing" if(Event == 4) { STATUS = 4; } //«<<» button pressed if(Event == 5) { STATUS = 5; } //«PAUSE»( | | ) button pressed if(Event == 3) { STATUS = 3; } //«>>» button pressed if(Event == 2) { STATUS = 0; } //«STOP» button pressed z2(); // Playing break; case 3: //--- "Fast-Forward" z3(); // Next track { STATUS=2; } break; case 4: //--- "Rewind" z4(); // Previous track { STATUS=2; } break; case 5: //--- "Pause" if(Event == 5) { STATUS = 2; } //«PAUSE» button pressed if(Event == 1) { STATUS = 2; } //«PLAY» button pressed if(Event == 2) { STATUS = 0; } //«STOP» button pressed if(Event == 3) { STATUS = 3; } //«>>» button pressed if(Event == 4) { STATUS = 4; } //«<<» button pressed z5(); //Pause break; }
In teoria, questo automa potrebbe contenere 36 varianti di transizione, ma solo 15 sono realmente esistenti e tutti i dettagli possono essere trovati nella descrizione fornita dall'autore.
8. А.А. Raccomandazioni di Shalyto sull'esecuzione del progetto
Informazioni complete su come preparare e scrivere la documentazione del progetto possono essere trovate qui http://project.ifmo.ru/books/3, mentre in questo articolo ti darò solo un breve estratto:
- Il libro di А.А. Shalyto "Logic Control. Methods of Hardware and Software Implementation of Algorithms. SPb.: Nauka, 2000", disponibile sul sito web specificato nella sezione "Libri" e che può essere preso come prototipo". Incarna una corretta presentazione delle informazioni in quanto è stato pubblicato dalla più antica e rispettabile casa editrice in Russia.
- L'introduzione fornisce i motivi per la pertinenza dell'argomento scelto, indicare brevemente il problema in esame e specificare il linguaggio di programmazione e il sistema operativo utilizzati nel progetto.
- Una descrizione verbale dettagliata del problema in questione è fornita nella sezione "Descrizione del problema" insieme a figure, diagrammi e schermate che chiariscono il problema descritto.
- Quando si utilizza la programmazione orientata agli oggetti, la sezione "Progettazione" deve includere un diagramma di classi. Le classi principali devono essere accuratamente descritte. È consigliabile preparare un "Diagramma a blocchi della classe" per ognuno di essi con l'obiettivo di presentare la sua interfaccia e i metodi utilizzati insieme all'indicazione dei metodi basati su automi.
- Devono essere forniti tre documenti per ogni automa nella sezione "Automi": una descrizione verbale, un diagramma di collegamento dell'automa e un grafico di transizione.
- La descrizione verbale deve essere abbastanza dettagliata, tuttavia, dato il fatto che il comportamento di un automa complesso è difficile da descrivere in modo chiaro, di solito rappresenta una "dichiarazione di intenti".
- Il diagramma di collegamento dell'automa fornisce una descrizione dettagliata della sua interfaccia. La parte sinistra del diagramma deve presentare:
- fonti di dati;
- nome completo di ogni variabile di input;
- nome completo di ogni evento;
- predicati con numeri di stato di altri automi che vengono utilizzati nell'automa dato come azioni di input. Ad esempio, si può usare il predicato Y8 == 6, il quale prende il valore uguale a uno una volta che l'ottavo automa passa al sesto stato);
- variabili di input indicate come x con indici rilevanti;
- eventi indicati come e con indici pertinenti;
- variabili per memorizzare gli stati dell'automa con il numero N, indicato come YN.
La parte destra del diagramma deve presentare:- variabili di output indicate come z con indici pertinenti;
- nome completo di ogni variabile di output;
- eventi generati dall'automa dato (se presenti);
- nome completo di ogni evento generato;
- ricevitori di dati.
- Se in nodi o transizioni vengono utilizzati algoritmi computazionali complessi, la sezione "Algoritmi computazionali" spiega la scelta degli algoritmi e fornisce la loro descrizione (inclusa la descrizione matematica). Questi algoritmi sono designati dalle variabili x e z, a seconda che i calcoli vengano effettuati all'ingresso o all'uscita.
- Le peculiarità dell'implementazione del programma devono essere esposte nella sezione "Implementazione". Questa deve in particolare presentare un modello per un'implementazione formale e isomorfa degli automi. Anche le implementazioni degli automi vanno fornite qui.
- "Conclusione" copre i vantaggi e gli svantaggi del progetto completato. Può anche offrire modi per migliorare il progetto.
9. Conclusione
Incoraggio tutti voi a:
- esplorare questo nuovo approccio alla programmazione.
- implementare questo approccio completamente nuovo ed estremamente interessante per programmare le tue idee e strategie di trading.
Spero che la programmazione basata su automi:
- nel tempo diventi lo standard di programmazione e progettazione per tutti i trader e anche per gli sviluppatori di MetaQuotes Language.
- sia la base nel complesso processo decisionale durante la progettazione di un EA.
- in futuro si sviluppi in un nuovo linguaggio - MetaQuotes Language 6 - che supporti l'approccio di programmazione basato su automi e una nuova piattaforma - MetaTrader 6.
Se tutti gli sviluppatori di trading seguiranno questo approccio di programmazione, l'obiettivo di creare un EA senza perdite potrà essere raggiunto. Questo primo articolo è il mio tentativo di mostrarvi uno sbocco completamente nuovo per la creatività e la ricerca nel campo della progettazione e programmazione basata su automi come impulso a nuove invenzioni e scoperte.
E un'altra cosa: sono pienamente d'accordo con l'articolo dell'autore e ritengo che sia importante fornirlo in forma concisa (testo completo qui http://is.ifmo.ru/works/open_doc/):
Perché i codici sorgente non sono una soluzione per comprendere i programmi
La questione centrale nella programmazione pratica è la questione della comprensione dei codici di programma. È sempre utile avere i codici sorgente a portata di mano, ma il problema è che questo spesso non è sufficiente. E di solito è necessaria una documentazione aggiuntiva per ottenere una comprensione di un programma non banale. Questa necessità cresce esponenzialmente con l'aumentare della quantità di codice.
L'analisi del codice di programma, volta a ripristinare le decisioni di progettazione originali prese dagli sviluppatori, e la comprensione dei programmi sono due importanti rami della tecnologia di programmazione la cui esistenza va di pari passo con l'insufficienza di codici sorgente per la comprensione dei programmi.
Chiunque sia mai stato coinvolto in un importante progetto di ricostruzione del software ricorderà sempre la sensazione di impotenza e perplessità che arriva quando si vede per la prima volta un gruppo di codici sorgente mal documentati (anche se non sempre scritti male). La disponibilità di codici sorgente non è di grande aiuto quando non c'è accesso agli sviluppatori chiave. Se il programma è scritto in un linguaggio di livello relativamente basso ed è inoltre mal documentato, tutte le principali decisioni di progettazione di solito si disperdono nei dettagli di programmazione e richiedono una ricostruzione. In casi come questo, il valore della documentazione di livello superiore, come le specifiche dell'interfaccia e la descrizione dell'architettura, può superare il valore del codice sorgente stesso.
La consapevolezza del fatto che i codici sorgente sono inadeguati per comprendere i programmi ha dato origine a tentativi di combinare il codice e una documentazione di livello superiore.
Se perdi le prime fasi del progetto, la complessità e la quantità di lavoro "bloccheranno" virtualmente i codici sorgente, a condizione che non ci sia una documentazione di alto livello in atto. Comprendere il codice "preistorico" in assenza degli sviluppatori che originariamente lavoravano al progetto o di una documentazione adeguata che consentiva di risolvere le decisioni architettoniche rilevanti è probabilmente una delle sfide più difficili che i programmatori incontrano».
Perché i programmi hanno carenze di design
Quindi, mentre l'assenza di codici sorgente può essere negativa, la loro disponibilità può anche essere scarsamente vantaggiosa. Cosa manca ancora per una vita "felice per sempre"? La risposta è semplice: una documentazione di design dettagliata e accurata che include la documentazione del programma come uno dei suoi componenti.
Ponti, strade e grattacieli non possono normalmente essere costruiti senza documentazione a portata di mano, il che non è vero per i programmi.
La situazione che si è verificata nella programmazione può essere definita come segue: "Se i costruttori costruissero edifici nel modo in cui i programmatori scrivono i programmi, allora il primo picchio di passaggio avrebbe distrutto la civiltà".
Perché una buona quantità di documentazione di progettazione dettagliata e chiara viene emessa per l'hardware e può essere relativamente e facilmente compresa e modificata da uno specialista medio anche anni dopo la sua emissione, ma tale documentazione è inesistente per il software o è scritta in modo puramente formale e uno specialista altamente qualificato è tenuto a modificarla (se manca lo sviluppatore)?
Apparentemente, questa situazione può essere spiegata come segue. In primo luogo, lo sviluppo e la produzione di hardware sono due diversi processi eseguiti da diverse organizzazioni. Pertanto, se la qualità della documentazione è scarsa, l'ingegnere di sviluppo trascorrerà il resto della sua vita lavorando nello "stabilimento", il che ovviamente non è quello che vorrebbe. Quando si tratta di sviluppo di software, la situazione cambia in quanto, in questo caso, sia lo sviluppatore che il produttore di software sono di solito la stessa azienda e quindi, indipendentemente dall'elenco dei documenti, il loro contenuto sarà, di regola, piuttosto superficiale.
In secondo luogo, l'hardware è "hard", mentre il software è "soft". Rende più facile modificare i programmi, ma non dà motivo di non emettere del tutto la documentazione di progettazione. È noto che la maggior parte dei programmatori è patologicamente riluttante a leggere e tanto più a scrivere la documentazione.
L'esperienza suggerisce che praticamente nessuno dei programmatori appena qualificati, anche i più intelligenti, può preparare la documentazione di progettazione. E nonostante il fatto che molti di loro abbiano seguito e superato corsi lunghi e complessi di matematica, non ha quasi alcun effetto sulla loro logica e sul rigore della scrittura della documentazione. Potrebbero usare notazioni diverse per una stessa cosa in tutta la documentazione (indipendentemente dalle sue dimensioni), chiamandola così ad esempio bulbo, lampadina, lampada o Lampada, scrivendola con una lettera piccola o maiuscola ogni volta che vogliono. Immagina cosa succede quando danno libero sfogo alla loro fantasia!
Apparentemente, accade a causa del fatto che durante la programmazione il compilatore segnala le incongruenze, mentre la documentazione di progettazione viene scritta senza alcun prompt.
La questione della qualità della documentazione software sta diventando una questione di crescente importanza sociale. Lo sviluppo del software sta progressivamente diventando simile allo show business con il suo forte motivo di profitto. Tutto è fatto in una folle corsa, senza pensare a cosa ne sarà del prodotto in futuro. Come lo show business, la programmazione misura tutto in termini di "profitti e perdite", piuttosto che "buoni e cattivi". Nella maggior parte dei casi, una buona tecnologia non è quella che è effettivamente buona, ma quella che paga.
La riluttanza a scrivere documentazione di progettazione è probabilmente anche associata al fatto che più il progetto è limitato (non documentato), più indispensabile è l'autore.
Tale comportamento lavorativo si estende purtroppo allo sviluppo di software per sistemi altamente critici. È in gran parte dovuto al fatto che i programmi sono nella maggior parte dei casi scritti e non progettati. "Durante la progettazione, qualsiasi tecnica più complicata schede CRC o diagrammi di casi d'uso è considerata troppo complessa e quindi non viene utilizzata. Un programmatore può sempre rifiutarsi di applicare una determinata tecnologia segnalando al capo che potrebbe non essere in grado di rispettare la scadenza".
Ciò porta a situazioni in cui anche gli "utenti non considerano gli errori nel software qualcosa di fuori dall'ordinario".
Attualmente è opinione diffusa che la progettazione e la documentazione adeguata debbano essere in atto quando si tratta di grandi edifici e non di software.
In conclusione, va notato che tale situazione non esisteva nella programmazione in passato - quando i primi computer su larga scala erano in uso e i programmi venivano progettati o sviluppati con molta attenzione poiché, in caso di errore, il tentativo successivo si svolgeva normalmente in non prima di un giorno. Pertanto, il progresso tecnico ci ha portato a una programmazione meno attenta.
Referenze
Sfortunatamente, i nostri problemi e le nostre preoccupazioni non possono essere rintracciati sul sito web del dipartimento dell'istituto in cui A.A. Shalyto funziona. Loro hanno i propri problemi e obiettivi e sono totalmente estranei e inconsapevoli dei nostri concetti e definizioni, quindi nessun esempio rilevante per il nostro argomento.
I principali libri/manuali di A.A. Shalyto:
- Automata-Based Programming. http://is.ifmo.ru/books/_book.pdf
- Using Flow Graphs and Transition Graphs in Implementation of Logic Control Algorithms. http://is.ifmo.ru/download/gsgp.pdf
- Automata-Based Programming. http://is.ifmo.ru/works/_2010_09_08_automata_progr.pdf
- Transformation of Iterative Algorithms into Automata-Based Algorithms. http://is.ifmo.ru/download/iter.pdf
- Switch-Technology: Automata-Based Approach to Developing Software for Reactive Systems. http://is.ifmo.ru/download/switch.pdf
- Automata-Based Program Design. Algorithmization and Programming of Logic Control Problems. http://is.ifmo.ru/download/app-aplu.pdf
- Using Genetic Algorithm to Design Autopilot for a Simplified Helicopter Model. http://is.ifmo.ru/works/2008/Vestnik/53/05-genetic-helicopter.pdf
- Explicit State-Based Programming. http://is.ifmo.ru/download/mirpk1.pdf
- Algorithmization and Programming for Logic Control and Reactive Systems. http://is.ifmo.ru/download/arew.pdf
- Object-Oriented Approach to Automata-Based Programming. http://is.ifmo.ru/works/ooaut.pdf
- Graphical Notation for Inheritance of Automata-Based Classes. http://is.ifmo.ru/works/_12_12_2007_shopyrin.pdf
- Programming in... 1 (One) Minute. http://is.ifmo.ru/progeny/1minute/?i0=progeny&i1=1minute
Progetti:
- Modeling Operation of ATMs. http://is.ifmo.ru/unimod-projects/bankomat/
- Modeling Nuclear Reactor Control Process. http://is.ifmo.ru/projects/reactor/
- Elevator Control System. http://is.ifmo.ru/projects/elevator/
- Automata-Based Development of Coffee Maker Control System. http://is.ifmo.ru/projects/coffee2/
- Design and Research of Automata for Driving. http://is.ifmo.ru/projects/novohatko/
- Modeling a Digital Camera Using Automata-Based Programming. http://project.ifmo.ru/shared/files/200906/5_80.pdf
- Using Automata-Based Programming to Model a Multi-Agent System for Unmanned Vehicles. http://project.ifmo.ru/shared/files/200906/5_41.pdf
- Visual Rubik's Cube Solution System. http://is.ifmo.ru/projects/rubik/
and other interesting articles and projects: http://project.ifmo.ru/projects/, http://is.ifmo.ru/projects_en/ and http://is.ifmo.ru/articles_en/.
P.S.
Il numero di possibili eventi diversi di un Cubo di Rubik è (8! × 38−1) × (12! × 212−1)/2 = 43 252 003 274 489 856 000. Ma questo numero non tiene conto del fatto che i quadrati centrali possano avere orientamenti diversi.
Pertanto, considerando gli orientamenti delle facce centrali, il numero di eventi diventa 2048 volte più grande, cioè 88 580 102 706 155 225 088 000.
Il mercato Forex e lo scambio non hanno così tante varianti di successione di eventi, ma i problemi ad essi associati possono essere facilmente risolti in 100-200 passaggi utilizzando questo paradigma di programmazione. È vero! Il mercato e gli EA sono in costante concorrenza. È come giocare a scacchi dove nessuno conosce le mosse imminenti dell'avversario (proprio come noi). Tuttavia ci sono programmi per computer impressionanti, come Rybka (motore di scacchi molto potente) progettato sulla base di algoritmi di potatura alfa-beta.
Possano questi successi altrui darvi energia in altre aree della programmazione e impegno nel nostro lavoro! Anche se, certamente sappiamo tutti che non sappiamo nulla.