Valutazione dei Sistemi di Trading - l'Efficacia dell'Entrata, dell'Uscita e dei Trade in Generale
Mykola Demko | 9 dicembre, 2021
Introduzione
Ci sono molte misure che determinano l'efficacia di un sistema di trading e i trader scelgono quelle che preferiscono. Questo articolo tratta gli approcci descritti nel libro "Statistika dlya traderov" ("Statistiche per i Trader") di S.V. Bulashev. Sfortunatamente, il numero di copie di questo libro è troppo basso e non è stato ripubblicato per molto tempo; tuttavia, la sua versione elettronica è ancora disponibile su molti siti web.
Prologo
Vi ricordo che il libro è stato pubblicato nel 2003. Era l’epoca di MetaTrader 3 con il linguaggio di programmazione MQL-II. E la piattaforma era piuttosto progressista per quel periodo. Pertanto, possiamo tenere traccia dei cambiamenti delle condizioni di trading stesse confrontandolo con il moderno client terminal MetaTrader 5. Va notato che l'autore del libro è diventato un guru per molte generazioni di trader (considerando il rapido cambio di generazioni in questo settore). Ma il tempo non si ferma; nonostante i principi descritti nel libro siano ancora applicabili, gli approcci dovrebbero essere adattati.
S.V. Bulashev scrisse il suo libro, prima di tutto, sulla base delle condizioni di trading attuali di quel periodo. Ecco perché non possiamo usare le statistiche descritte dall'autore senza una trasformazione. Per renderlo più chiaro, ricordiamo le possibilità di trading di quei tempi: il trading marginale su un mercato spot implica che l'acquisto di una valuta per ottenere un profitto speculativo si trasformi in vendita dopo un po '.
Queste sono le basi e vale la pena ricordarle: l'esatta interpretazione è stata utilizzata quando è stato scritto il libro "Statistiche per i Trader". Ogni posizione di 1 lotto avrebbe dovuto essere chiusa dalla posizione inversa dello stesso volume. Tuttavia, dopo due anni (nel 2005), l'uso di tali statistiche necessitava di una riorganizzazione. Il motivo è che la chiusura parziale delle posizioni è diventata possibile in MetaTrader 4. Quindi, per usare le statistiche descritte da Bulashev abbiamo bisogno di migliorare il sistema di interpretazione, in particolare l'interpretazione dovrebbe essere fatta per la chiusura e non per l’apertura.
Dopo altri 5 anni, la situazione è cambiata in modo significativo. Dov'è il termine così abituale Ordine? Non c'è più. Considerando il flusso di domande in questo forum, è meglio descrivere l'esatto sistema di interpretazione in MetaTrader 5.
Quindi, oggi non esiste più il termine classico Ordine. Un ordine ora è una richiesta di trading al server di un broker, che viene effettuata da un trader o MTS per aprire o modificare una posizione di trading. Ora è una posizione; per capirne il significato, ho menzionato il trading marginale. Il dato di fatto è che il trading marginale viene eseguito su denaro preso in prestito; e una posizione esiste finché quel denaro esiste.
Non appena si regolano i conti con il mutuatario chiudendo la posizione e, di conseguenza, fissando un profitto/perdita, la posizione cessa di esistere. A tal proposito, questo fatto spiega il motivo per cui un inverso di posizione non la chiude. Il dato di fatto è che il prestito rimane comunque e non c'è differenza se hai preso in prestito denaro per l'acquisto o per la vendita. Una posizione è semplicemente una storia di un ordine eseguito.
Ora parliamo delle caratteristiche del trading. Attualmente, in MetaTrader 5, possiamo sia chiudere parzialmente una posizione di trading che incrementarne una esistente. Così, il classico sistema di interpretazione, in cui ogni apertura di una posizione di un certo volume è seguita dalla chiusura con lo stesso volume, fa parte del passato. Ma è davvero impossibile recuperarlo dalle informazioni memorizzate in MetaTrader 5? Quindi, prima di tutto, riorganizzeremo l'interpretazione.
L'Efficacia dell'Entrata
Non è un segreto che molte persone vogliano rendere il loro trading più efficace, ma come descrivere (formalizzare) questo termine? Se consideri che una posizione sia un percorso superato dal prezzo, allora diventa ovvio che ci sono due punti estremi su quel percorso: minimo e massimo del prezzo all'interno della sezione osservata. Tutti si sforzano per entrare nel mercato il più vicino possibile al minimo (al momento dell'acquisto). Questo può essere considerato come una regola principale di qualsiasi trading: acquistare ad un prezzo basso, vendere ad un prezzo elevato.
L'efficacia dell'entrata determina quanto vicino al minimo acquisti. In altre parole, l'efficacia dell’entrata è il rapporto della distanza tra il massimo e il prezzo di entrata nell'intero percorso. Perché misuriamo la distanza al minimo attraverso la differenza del massimo? Abbiamo bisogno che l'efficacia sia uguale a 1 quando si entra al minimo (e che sia uguale a 0 quando si entra al massimo).
Ecco perché per il nostro rapporto prendiamo il resto della distanza, e non la distanza tra il minimo e l'entrata stessa. Qui, dobbiamo sottolineare che la situazione della vendita è speculare rispetto a quella dell'acquisto.
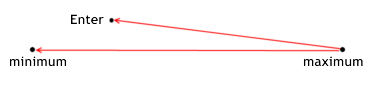
L'efficacia di entrare in posizione mostra quanto bene un MTS realizzi il potenziale profitto relativamente al prezzo di entrare durante determinati trade. Ciò viene calcolato con la seguente formula:
for long positions enter_efficiency=(max_price_trade-enter_price)/(max_price_trade-min_price_trade); for short positions enter_efficiency=(enter_price-min_price_trade)/(max_price_trade-min_price_trade); The effectiveness of entering can have a value within the range from 0 to 1.
L'Efficacia dell'Uscita
La situazione con l'uscita è simile:
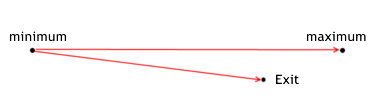
L'efficacia di Uscita da una posizione mostra quanto bene un MTS realizzi il potenziale profitto rispetto al prezzo di uscita dalla posizione durante determinati trade. Ciò viene calcolato con la seguente formula:
for lone positions exit_efficiency=(exit_price - min_price_trade)/(max_price_trade - min_price_trade); for short positions exit_efficiency=(max_price_trade - exit_price)/(max_price_trade - min_price_trade); The effectiveness of exiting can have a value withing the range from 0 to 1.
L'Efficacia di un Trade
Nel complesso, l'efficacia di un trade è determinata sia dall'entrata che dall'uscita. Può essere calcolata come il rapporto tra il percorso tra l'entrata e l'uscita alla distanza massima durante il trade (cioè la differenza tra minimo e massimo). Pertanto, l'efficacia di un trade può essere calcolata in due modi: direttamente utilizzando le informazioni primarie sul trading o utilizzando i risultati già calcolati di entrate e uscite precedentemente valutati (con uno spostamento di intervallo).
L'efficacia del trade mostra quanto bene un MTS realizzi il profitto potenziale totale durante determinati trade. Viene calcolato con le seguenti formule:
for long positions trade_efficiency=(exit_price-enter_price)/(max_price_trade-min_price_trade); for short positions trade_efficiency=(enter_price-exit_price)/(max_price_trade-min_price_trade); general formula trade_efficiency=enter_efficiency+exit_efficiency-1; The effectiveness of trade can have a value within the range from -1 to 1. The effectiveness of trade must be greater than 0,2. The analysis of effectiveness visually shows the direction for enhancing the system, because it allows evaluating the quality of signals for entering and exiting a position separately from each other.
Trasformazione dell'Interpretazione
Prima di tutto, per evitare qualsiasi tipo di confusione, dobbiamo chiarire i nomi degli oggetti di interpretazione. Poiché gli stessi termini - ordine, trade, posizione sono usati in MetaTrader 5 e da Bulachev, dobbiamo distinguerli. Nel mio articolo, userò il nome "trade" per l'oggetto di interpretazione di Bulachev, cioè il trade è una posizione; usa anche il termine "ordine" in tal senso e, in quel contesto, questi termini sono identici. Bulachev chiama posizione una transazione incompiuta, mentre noi la chiameremo trade non chiuso.
Qui, puoi vedere che tutti e 3 i termini si adattano facilmente alla singola parola "trade". Non rinomineremo l'interpretazione in MetaTrader 5; il significato di questi tre termini rimane come progettato dagli sviluppatori del client terminal. Di conseguenza, abbiamo 4 parole che useremo: Posizione, Deal, Ordinee Trade.
Poiché un Ordine è un comando al server per l'apertura/modifica di una posizione e non riguarda direttamente le statistiche, ma lo fa direttamente attraverso una posizione (il motivo è che l'invio di un ordine non sempre comporta l'esecuzione della posizione corrispondente di volume e prezzo specificati), allora è giusto raccogliere le statistiche dalle posizioni e non dagli ordini.
Analizziamo un esempio di interpretazione della stessa posizione (per rendere più chiara la descrizione di cui sopra):
interpretation in МТ-5 deal[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 deal[ 1 ] in/out 0.2 buy 1.22261 2010.06.14 13:36 deal[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 deal[ 3 ] out 0.2 sell 1.22310 2010.06.14 13:41
interpretation by Bulachev trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 out 1.22261 2010.06.14 13:36 trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36 out 1.22310 2010.06.14 13:41 trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 out 1.22310 2010.06.14 13:41
Ora, descriverò il modo in cui sono state condotte quelle manipolazioni. Deal[ 0 ] apre la posizione, la scriviamo come l'inizio del nuovo trade:
trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33
Successivamente, arriva il contrario della posizione; significa che tutte le operazioni precedenti dovrebbero essere chiuse. Di conseguenza, le informazioni sul deal[ 1 ] inverso verranno prese in considerazione sia alla chiusura che all'apertura del nuovo trade. Una volta che tutti i trade non chiusi prima del deal con la direzione in/out sono chiusi, dobbiamo aprire il nuovo trade. Vale a dire, utilizziamo solo le informazioni sul prezzo e sul tempo del deal selezionato per la chiusura, al contrario dell'apertura di un'operazione, quando vengono utilizzati anche il tipo e il volume. Qui, dobbiamo chiarire che un termine che non viene stato usato prima che apparisse nella nuova interpretazione - è la direzione del deal. In precedenza, intendevamo un acquisto o una vendita dicendo la "direzione" e il termine "tipo" aveva lo stesso significato. D’ora in poi tipo e direzione sono termini diversi.
Iltipo è un acquisto o una vendita, mentre la direzione è entrare o uscire da una posizione. Questo è il motivo per cui una posizione viene sempre aperta con un deal della direzione ine viene chiusa con un out deal. Ma la direzione si limita solo all'apertura e alla chiusura delle posizioni. Questi termini includono anche l'aumento del volume di una posizione (se l’"in" deal non è il primo nella lista) e la chiusura parziale di una posizione (gli "out" deal non sono gli ultimi nella lista). Poiché la chiusura parziale è ora disponibile, è logico introdurre anche il contrario della posizione; un inverso si verifica quando viene eseguita un deal opposto di dimensioni superiori alla posizione corrente, ovvero si tratta di un deal in/out.
Quindi, abbiamo chiuso i trade precedentemente aperti (per invertire la posizione):
trade[ 0 ] in 0.1 sell 1.22218 2010.06.14 13:33 out 1.22261 2010.06.14 13:36
Il volume di riposo è di 0,1 lotti e viene utilizzato per l'apertura del nuovo trade:
trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36
Poi arriva il deal[ 2 ] con la direzione in, apri un altro trade:
trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39
E infine, il deal che chiude la posizione - deal[ 3 ] chiude tutti i trade nella posizione che non sono ancora chiusi:
trade[ 1 ] in 0.1 buy 1.22261 2010.06.14 13:36 out 1.22310 2010.06.14 13:41 trade[ 2 ] in 0.1 buy 1.22337 2010.06.14 13:39 out 1.22310 2010.06.14 13:41
L'interpretazione sopra descritta mostra l'essenza dell'interpretazione utilizzata da Bulachev - ogni trade aperto ha un certo punto di entrata e un certo punto di uscita , ha il suo volume e tipo. Tuttavia, questo sistema di interpretazione non considera una sfumatura: la chiusura parziale. Se guardi più da vicino, vedrai che il numero di trade è uguale al numero di in deal (considerando gli in/out deal). In questo caso, vale la pena interpretare dagliindeal, ma ci saranno piùoutdeal a chiusura parziale (potrebbe esserci una situazione in cui il numero di in deal e out deal è lo stesso, ma non corrispondono l'un l'altro dal volume).
Per elaborare tutti gliout deal, dovremmo interpretare dagli out deal. E questa contraddizione sembra essere incompatibile se eseguiamo un'elaborazione separata dei deal, all'inizio - tutti gli in deal e poi tutti gli out deal (o viceversa). Tuttavia, se elaboriamo le offerte in sequenza e applichiamo una regola di elaborazione speciale a ciascuna, allora non ci sono contraddizioni.
Ecco un esempio, in cui il numero di out deal è maggiore del numero di in deal (con descrizione):
interpretation in МТ-5 deal[ 0 ] in 0.3 sell 1.22133 2010.06.15 08:00 deal[ 1 ] out 0.2 buy 1.22145 2010.06.15 08:01 deal[ 2 ] in/out 0.4 buy 1.22145 2010.06.15 08:02 deal[ 3 ] in/out 0.4 sell 1.22122 2010.06.15 08:03 deal[ 4 ] out 0.1 buy 1.2206 2010.06.15 08:06
interpretation by Bulachev trade[ 0 ] in 0.2 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:01 trade[ 1 ] in 0.1 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:02 trade[ 2 ] in 0.3 buy 1.22145 2010.06.15 08:02 out 1.22122 2010.06.15 08:03 trade[ 3 ] in 0.1 sell 1.22122 2010.06.15 08:03 out 1.2206 2010.06.15 08:06
Abbiamo una situazione, quando un deal di chiusura arriva dopo l'apertura, ma non ha l'intero volume, bensì solo una parte di esso (0,3 lotti sono aperti e 0,2 sono chiusi). Come gestire tale situazione? Se ogni trade viene chiuso con lo stesso volume, la situazione può essere considerata come l'apertura di più trade con un singolo deal. Pertanto, avranno gli stessi punti di apertura e diversi punti di chiusura (è chiaro che il volume di ogni trade è determinato dal volume di chiusura). Ad esempio, scegliamo deal[ 0 ] per l'elaborazione, apriamo il trade:
trade[ 0 ] in 0.3 sell 1.22133 2010.06.15 08:00
Quindi, selezioniamo deal[ 1 ], chiudiamo il trade aperto e, durante la chiusura, scopriamo che il volume di chiusura non è sufficiente. Fai una copia del trade precedentemente aperto e specifica la mancanza di volume nel suo parametro "volume". Dopodiché, chiudi i trade iniziale con il volume del deal (cioè cambiamo il volume del trade iniziale specificato all'apertura con il volume di chiusura):
trade[ 0 ] in 0.2 sell 1.22133 2010.06.15 08:00 out 1.22145 2010.06.15 08:01 trade[ 1 ] in 0.1 sell 1.22133 2010.06.15 08:00
Tale trasformazione può sembrare non adatta a un trader, dal momento che il trader potrebbe voler chiudere un altro trade e non questo. Tuttavia, in ogni caso, la valutazione dei sistemi non sarà danneggiata da una corretta trasformazione. L'unica cosa che può essere danneggiata è la fiducia del trader nel trading senza perdite in MetaTrader 4; questo sistema di ricalcolo rivelerà tutte le delusioni.
Il sistema di interpretazione statistica descritto nel libro di Bulachev non ha emozioni e permette di valutare onestamente le decisioni dalla posizione di entrata, uscita ed entrambi i tassi in totale. E la possibilità di trasformazione dell'interpretazione (l'una nell'altra senza perdita di dati) dimostra che è sbagliato dire che un MTS sviluppato per MetaTrader 4 non può essere ricreato per il sistema di interpretazione di MetaTrader 5. L'unica perdita quando si trasforma l'interpretazione può essere l'appartenenza del volume a diversi ordini (MetaTrader 4). In realtà, se non ci sono più ordini (nel vecchio significato di questo termine) da contabilizzare, allora è solo la stima soggettiva di un trader.
Codice per la Trasformazione dell'Interpretazione
Diamo un'occhiata al codice stesso. Per preparare un traduttore abbiamo bisogno della caratteristica di ereditarietà dell’OOP. Ecco perché suggerisco a coloro che non lo conoscono ancora, di aprire il Manuale Utente MQL5 e imparare la teoria. Prima di tutto, descriviamo una struttura di interpretazione di un accordo (potremmo velocizzare il codice ottenendo quei valori direttamente usando le funzioni standard di MQL5, ma è meno leggibile e potrebbe confonderti).
//+------------------------------------------------------------------+ //| structure of deal | //+------------------------------------------------------------------+ struct S_Stat_Deals { public: ulong DTicket; // ticket of deal ENUM_DEAL_TYPE deals_type; // type of deal ENUM_DEAL_ENTRY deals_entry; // direction of deal double deals_volume; // volume of deal double deals_price; // price of opening of deal datetime deals_date; // time of opening of deal S_Stat_Deals(){}; ~S_Stat_Deals(){}; };
Questa struttura contiene tutti i dettagli principali su un affare, i dettagli derivati non sono inclusi poiché possiamo calcolarli se necessario. Poiché gli sviluppatori hanno già implementato molti metodi delle statistiche di Bulachev nello strategy tester, non ci resta che integrarlo con i metodi personalizzati. Quindi, implementiamo metodi come l'efficacia di un trade nel suo complesso e l'efficacia dell'apertura e della chiusura.
E per ottenere questi valori dobbiamo implementare l'interpretazione delle informazioni primarie come il prezzo di apertura/chiusura, l’ora di apertura/chiusura, il prezzo minimo/massimo durante un trade. Se abbiamo queste informazioni primarie, possiamo ottenere molte informazioni derivate. Inoltre, voglio attirare la vostra attenzione sulla struttura del trade descritta di seguito: è la struttura principale, tutte le trasformazioni di interpretazione si basano su di essa.
//+------------------------------------------------------------------+ //| structure of trade | //+------------------------------------------------------------------+ struct S_Stat_Trades { public: ulong OTicket; // ticket of opening deal ulong CTicket; // ticket of closing deal ENUM_DEAL_TYPE trade_type; // type of trade double trade_volume; // volume of trade double max_price_trade; // maximum price of trade double min_price_trade; // minimum price of trade double enter_price; // price of opening of trade datetime enter_date; // time of opening of trade double exit_price; // price of closing of trade/s22> datetime exit_date; // time of closing of trade double enter_efficiency;// effectiveness of entering double exit_efficiency; // effectiveness of exiting double trade_efficiency;// effectiveness of trade S_Stat_Trades(){}; ~S_Stat_Trades(){}; };
Ora, poiché abbiamo creato due strutture principali, possiamo definire la nuova classe C_Pos che trasforma l'interpretazione. Prima di tutto, dichiariamo i puntatori alle strutture di interpretazione di deal e trade. Poiché le informazioni possono essere necessarie nelle funzioni ereditate, dichiarale come pubbliche; e, poiché ci possono essere molti deal e trade, usa un array come puntatore alla struttura invece di una variabile. Pertanto, le informazioni saranno strutturate e disponibili da qualsiasi posto.
Quindi, dobbiamo dividere la storia in posizioni separate ed eseguire tutte le trasformazioni all'interno di una posizione come in un ciclo di trading completo. Per farlo, dichiara le variabili per l'interpretazione degli attributi di posizione(id della posizione, simboli della posizione, numero di deal, numero di trade).
//+------------------------------------------------------------------+ //| class for transforming deals into trades | //+------------------------------------------------------------------+ class C_Pos { public: S_Stat_Deals m_deals_stats[]; // structure of deals S_Stat_Trades m_trades_stats[]; // structure of trades long pos_id; // id of position string symbol; // symbol of position int count_deals; // number of deals int count_trades; // number of trades int trades_ends; // number of closed trades int DIGITS; // accuracy of minimum volume by the symbols of position C_Pos() { count_deals=0; count_trades=0; trades_ends=0; }; ~C_Pos(){}; void OnHistory(); // creation of history of position void OnHistoryTransform();// transformation of position history into the new system of interpretation void efficiency(); // calculation of effectiveness by Bulachev's method private: void open_pos(int c); void copy_pos(int x); void close_pos(int i,int c); double nd(double v){return(NormalizeDouble(v,DIGITS));};// normalization to minimum volume void DigitMinLots(); // accuracy of minimum volume double iHighest(string symbol_name,// symbol name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ); double iLowest(string symbol_name,// symbol name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ); };
La classe ha tre metodi pubblici che elaborano le posizioni.
OnHistory() crea la cronologia delle posizioni://+------------------------------------------------------------------+ //| filling the structures of history deals | //+------------------------------------------------------------------+ void C_Pos::OnHistory() { ArrayResize(m_deals_stats,count_deals); for(int i=0;i<count_deals;i++) { m_deals_stats[i].DTicket=HistoryDealGetTicket(i); m_deals_stats[i].deals_type=(ENUM_DEAL_TYPE)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_TYPE); // type of deal m_deals_stats[i].deals_entry=(ENUM_DEAL_ENTRY)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_ENTRY);// direction of deal m_deals_stats[i].deals_volume=HistoryDealGetDouble(m_deals_stats[i].DTicket,DEAL_VOLUME); // volume of deal m_deals_stats[i].deals_price=HistoryDealGetDouble(m_deals_stats[i].DTicket,DEAL_PRICE); // price of opening m_deals_stats[i].deals_date=(datetime)HistoryDealGetInteger(m_deals_stats[i].DTicket,DEAL_TIME); // time of opening } };
Per ogni deal, il metodo crea una copia della struttura e la compila con le informazioni sul deal. Questo è esattamente ciò che intendevo quando sopra dicevo che possiamo farne a meno, ma è più conveniente con esso (quelli che perseguono i microsecondi di accorciamento del tempo possono sostituire il richiamo di queste strutture con la linea che si trova a destra del segno di uguaglianza).
OnHistoryTransform() trasforma la cronologia delle posizioni nel nuovo sistema di interpretazione:
- Prima, ho descritto come le informazioni dovrebbero essere trasformate; ora consideriamone un esempio. Per la trasformazione, abbiamo bisogno di un valore alla precisione del quale dovremmo calcolare il volume di un deal (volume minimo); DigitMinLots() se ne occupa; tuttavia, se un programmatore è sicuro che questo codice non verrà eseguito in altre condizioni, questo parametro può essere specificato nel constructor e la funzione può essere saltata.
- Quindi azzerare i contatori count_trades e trades_ends. Successivamente, riallocare la memoria per la struttura di interpretazione dei trade. Poiché non conosciamo con certezza il numero esatto di trade, dovremmo riallocare la memoria in base al numero di deal in posizione. Se, inoltre, sembra che ci siano più trade, allora riallocheremo nuovamente la memoria per diverse volte; ma allo stesso tempo la maggior parte dei trade avrà abbastanza memoria e l'allocazione della memoria per l'intero array consente di risparmiare tempo alla nostra macchina in modo significativo.
Consiglio di utilizzare questo metodo ovunque quando necessario; allocare la memoria ogni volta che appare un nuovo oggetto di interpretazione. Se non ci sono informazioni precise sulla quantità di memoria richiesta, allora dobbiamo allocarla ad un valore approssimativo. In ogni caso, è più economico che riallocare l'intero array ad ogni passaggio.
Poi arriva il loop in cui tutti i deal di una posizione vengono filtrati usando tre filtri: se il deal èin, in/out, out. Per ogni variante vengono attuate azioni specifiche. I filtri sono sequenziali, nidificati. In altre parole, se un filtro restituisce false, allora solo in questo caso controlliamo il filtro successivo. Tale costruzione è economica con le risorse, perché le azioni non necessarie vengono eliminate. Per rendere il codice più leggibile, vengono intraprese molte azioni per le funzioni dichiarate nella classe come private. A tal proposito, queste funzioni erano pubbliche durante lo sviluppo. Inoltre, mi sono reso conto che non ce n'è bisogno nelle altre parti del codice, quindi sono state ridichiarate come private. Questa è la facilità con cui si può maneggiare l'ambito dei dati nell’OOP.
Quindi, nel filtro in viene eseguita la creazione di un nuovo trade (la funzione open_pos(); ecco perché aumentiamo la dimensione dell’array dei puntatori di uno e copiamo la struttura del deal nei campi corrispondenti della struttura del trade. Inoltre, poiché la struttura del trade ha due volte più campi di prezzo e tempo, solo i campi di apertura vengono riempiti quando viene aperto un trade, quindi viene conteggiato come incompleto; puoi capirlo dalla differenza di count_tradesetrades_ends. La questione è che i contatori hanno valori zero all'inizio. Non appena appare un trade, il contatore count_trades viene aumentato e quando il trade viene chiuso, il contatore trades_ends viene aumentato. Pertanto, la differenza tra count_tradese trades_ends può dirti quanti trade non vengono chiusi in qualsiasi momento.
La funzione open_pos() è piuttosto semplice, apre solo i trade e attiva il contatore corrispondente; altre funzioni simili non sono così semplici. Quindi, se un deal non è del tipo in, allora può essere in/out o out. Da due varianti, prima di tutto, controlla quella che viene eseguita più facilmente (questo non è un problema fondamentale, ma ho costruito il controllo nell'ordine di difficoltà crescente di esecuzione).
La funzione che elabora il filtro in/out somma le posizioni aperte da tutti i trade i non chiusi (ho già accennato come sapere quali trade non sono chiusi utilizzando la differenza tra count_trades e trades_ends). Pertanto, calcoliamo il volume totale che viene chiuso dal deal dato (e il resto del volume verrà riaperto ma con il tipo di deal corrente). Qui dobbiamo notare che il deal ha la direzione in/out, il che significa che il suo volume supera il volume totale della posizione precedentemente aperta. Ecco perché è logico calcolare la differenza tra la posizione e il deal in/out, per conoscere il volume del nuovo trade da riaprire.
Se un deal ha la direzione out , allora è ancora tutto più complicato. Prima di tutto, l'ultimo deal in una posizione ha sempre la direzione out, quindi qui dovremmo fare un'eccezione - se è l'ultimo deal, chiudi tutto ciò che abbiamo. Altrimenti (se il deal non è l'ultimo), sono possibili due varianti. Poiché il deal non è in/out maout, allora le varianti sono: la prima variante è che il volume è esattamente lo stesso di quello di apertura, cioè il volume del deal di apertura è uguale al volume del deal di chiusura; la seconda variante è che quei volumi non sono gli stessi.
La prima variante viene elaborata mediante la chiusura. La seconda variante è più complicata, due varianti sono di nuovo possibili: quando il volume è maggiore e quando il volume è inferiore a quello di apertura. Quando il volume è maggiore, chiudi il trade successivo fino a quando il volume di chiusura non diventa uguale o inferiore al volume di apertura. Se il volume non è sufficiente per chiudere l'intero trade successivo (c'è meno volume), equivale alla chiusura parziale. Qui dobbiamo chiudere il trade con il nuovo volume (quello che rimane dopo le operazioni precedenti), ma prima di esso, fare una copia del trade con il volume mancante. E, naturalmente, non dimenticare i contatori.
Nel trading, ci può essere una situazione in cui c'è già una coda di trade successivi alla chiusura parziale dopo la riapertura di un trade. Per evitare confusione, tutti dovrebbero essere spostati di uno, per mantenere la cronologia della chiusura.
//+------------------------------------------------------------------+ //| transformation of deals into trades (engine classes) | //+------------------------------------------------------------------+ void C_Pos::OnHistoryTransform() { DigitMinLots();// fill the DIGITS value count_trades=0;trades_ends=0; ArrayResize(m_trades_stats,count_trades,count_deals); for(int c=0;c<count_deals;c++) { if(m_deals_stats[c].deals_entry==DEAL_ENTRY_IN) { open_pos(c); } else// else in { double POS=0; for(int i=trades_ends;i<count_trades;i++)POS+=m_trades_stats[i].trade_volume; if(m_deals_stats[c].deals_entry==DEAL_ENTRY_INOUT) { for(int i=trades_ends;i<count_trades;i++)close_pos(i,c); trades_ends=count_trades; open_pos(c); m_trades_stats[count_trades-1].trade_volume=m_deals_stats[c].deals_volume-POS; } else// else in/out { if(m_deals_stats[c].deals_entry==DEAL_ENTRY_OUT) { if(c==count_deals-1)// if it's the last deal { for(int i=trades_ends;i<count_trades;i++)close_pos(i,c); trades_ends=count_trades-1; } else// if it's not the last deal { double out_vol=nd(m_deals_stats[c].deals_volume); while(nd(out_vol)>0) { if(nd(out_vol)>=nd(m_trades_stats[trades_ends].trade_volume)) { close_pos(trades_ends,c); out_vol-=nd(m_trades_stats[trades_ends].trade_volume); trades_ends++; } else// if the remainder of closed position is less than the next trade { // move all trades forward by one count_trades++; ArrayResize(m_trades_stats,count_trades); for(int x=count_trades-1;x>trades_ends;x--)copy_pos(x); // open a copy with the volume equal to difference of the current position and the remainder m_trades_stats[trades_ends+1].trade_volume=nd(m_trades_stats[trades_ends].trade_volume-out_vol); // close the current trade with new volume, which is equal to remainder close_pos(trades_ends,c); m_trades_stats[trades_ends].trade_volume=nd(out_vol); out_vol=0; trades_ends++; } }// while(out_vol>0) }// if it's not the last deal }// if out }// else in/out }// else in } };
Calcolo dell'Efficacia
Una volta che il sistema di interpretazione è trasformato, possiamo valutare l'efficacia dei trade con la metodologia di Bulachev. Le funzioni necessarie per tale valutazione sono nel metodo efficiency(), il riempimento della struttura del trade con i dati calcolati viene eseguito anche lì. L'efficacia dell'entrata e dell'uscita viene misurata da 0 a 1 e per l'intero trade viene misurata da -1 a 1.
//+------------------------------------------------------------------+ //| calculation of effectiveness | //+------------------------------------------------------------------+ void C_Pos::efficiency() { for(int i=0;i<count_trades;i++) { m_trades_stats[i].max_price_trade=iHighest(symbol,PERIOD_M1,m_trades_stats[i].enter_date,m_trades_stats[i].exit_date); // maximal price of trade m_trades_stats[i].min_price_trade=iLowest(symbol,PERIOD_M1,m_trades_stats[i].enter_date,m_trades_stats[i].exit_date); // minimal price of trade double minimax=0; minimax=m_trades_stats[i].max_price_trade-m_trades_stats[i].min_price_trade;// difference between maximum and minimum if(minimax!=0)minimax=1.0/minimax; if(m_trades_stats[i].trade_type==DEAL_TYPE_BUY) { //Effectiveness of entering a position m_trades_stats[i].enter_efficiency=(m_trades_stats[i].max_price_trade-m_trades_stats[i].enter_price)*minimax; //Effectiveness of exiting from a position m_trades_stats[i].exit_efficiency=(m_trades_stats[i].exit_price-m_trades_stats[i].min_price_trade)*minimax; //Effectiveness of trade m_trades_stats[i].trade_efficiency=(m_trades_stats[i].exit_price-m_trades_stats[i].enter_price)*minimax; } else { if(m_trades_stats[i].trade_type==DEAL_TYPE_SELL) { //Effectiveness of entering a position m_trades_stats[i].enter_efficiency=(m_trades_stats[i].enter_price-m_trades_stats[i].min_price_trade)*minimax; //Effectiveness of exiting from a position m_trades_stats[i].exit_efficiency=(m_trades_stats[i].max_price_trade-m_trades_stats[i].exit_price)*minimax; //Effectiveness of trade m_trades_stats[i].trade_efficiency=(m_trades_stats[i].enter_price-m_trades_stats[i].exit_price)*minimax; } } } }
Il metodo utilizza due metodi privati iHighest() e iLowest(); essi sono simili e l'unica differenza sono i dati richiesti e la funzione di ricerca fmin o fmax.
//+------------------------------------------------------------------+ //| searching maximum within the period start_time --> stop_time | //+------------------------------------------------------------------+ double C_Pos::iHighest(string symbol_name,// symbols name ENUM_TIMEFRAMES timeframe, // period datetime start_time, // start date datetime stop_time // end date ) { double buf[]; datetime start_t=(start_time/60)*60;// normalization of time of opening datetime stop_t=(stop_time/60+1)*60;// normaliztion of time of closing int period=CopyHigh(symbol_name,timeframe,start_t,stop_t,buf); double res=buf[0]; for(int i=1;i<period;i++) res=fmax(res,buf[i]); return(res); }
Il metodo cerca il massimo all’interno del periodo tra due date specificate. Le date vengono passate alla funzione come parametri start_time e stop_time. Poiché le date dei trade vengono passate alla funzione e una richiesta di trade può arrivare anche a metà della barra di 1 minuto, la normalizzazione della data al valore più vicino della barra viene eseguita all'interno della funzione. Lo stesso viene fatto nella funzione iLowest(). Con il metodo sviluppato efficiency() abbiamo l'intera funzionalità per lavorare con una posizione; ma non c'è ancora alcun trattamento della posizione stessa. Superiamo questo determinando una nuova classe, nella quale saranno disponibili tutti i metodi precedenti; in altre parole, dichiarala come una derivata di C_Pos.
Classe Derivata (engine class)
class C_PosStat:public C_Pos
Per considerare le informazioni statistiche, creare una struttura che verrà data alla nuova classe.
//+------------------------------------------------------------------+ //| structure of effectiveness | //+------------------------------------------------------------------+ struct S_efficiency { double enter_efficiency; // effectiveness of entering double exit_efficiency; // effectiveness of exiting double trade_efficiency; // effectiveness of trade S_efficiency() { enter_efficiency=0; exit_efficiency=0; trade_efficiency=0; }; ~S_efficiency(){}; };
E il corpo della classe stessa:
//+------------------------------------------------------------------+ //| class of statistics of trade in whole | //+------------------------------------------------------------------+ class C_PosStat:public C_Pos { public: int PosTotal; // number of positions in history C_Pos pos[]; // array of pointers to positions int All_count_trades; // total number of trades in history S_efficiency trade[]; // array of pointers to the structure of effectiveness of entering, exiting and trades S_efficiency avg; // pointer to the structure of average value of effectiveness of entering, exiting and trades S_efficiency stdev; // pointer to the structure of standard deviation from // average value of effectiveness of entering, exiting and trades C_PosStat(){PosTotal=0;}; ~C_PosStat(){}; void OnPosStat(); // engine classes void OnTradesStat(); // gathering information about trades into the common array // functions of writing information to a file void WriteFileDeals(string folder="deals"); void WriteFileTrades(string folder="trades"); void WriteFileTrades_all(string folder="trades_all"); void WriteFileDealsHTML(string folder="deals"); void WriteFileDealsHTML2(string folder="deals"); void WriteFileTradesHTML(string folder="trades"); void WriteFileTradesHTML2(string folder="trades"); string enum_translit(ENUM_DEAL_ENTRY x,bool latin=true);// transformation of enumeration into string string enum_translit(ENUM_DEAL_TYPE x,bool latin=true); // transformation of enumeration into string (overloaded) private: S_efficiency AVG(int count); // arithmetical mean S_efficiency STDEV(const S_efficiency &mo,int count); // standard deviation S_efficiency add(const S_efficiency &a,const S_efficiency &b); //add S_efficiency take(const S_efficiency &a,const S_efficiency &b); //subtract S_efficiency multiply(const S_efficiency &a,const S_efficiency &b); //multiply S_efficiency divided(const S_efficiency &a,double b); //divide S_efficiency square_root(const S_efficiency &a); //square root string Head_style(string title); };
Suggerisco di analizzare questa classe in direzione inversa, dalla fine all'inizio. Tutto termina con la scrittura di una tabella di deal e trade nei file. Una fila di funzioni viene scritta per questo scopo (puoi capire lo scopo di ciascuna dal nome). Le funzioni creano un report csv su deal e trade, nonché report html di due tipi (differiscono solo visivamente, ma hanno lo stesso contenuto).
void WriteFileDeals(); // writing csv report on deals void WriteFileTrades(); // writing csv report on trade void WriteFileTrades_all(); // writing summary csv report of fitness functions void WriteFileDealsHTML2(); // writing html report on deals, 1 variant void WriteFileTradesHTML2();// writing html report on trades, 2 variant
La funzione enum_translit() ha lo scopo di trasformare i valori delle enumerazioni in tipo stringa per scriverli nel file log. La sezione privata contiene diverse funzioni della struttura S_efficiency. Tutte le funzioni compensano gli svantaggi del linguaggio, in particolare le operazioni aritmetiche con le strutture. Poiché le opinioni sull'implementazione di questi metodi variano, possono essere realizzate in modi diversi. Li ho realizzati come metodi di operazioni aritmetiche con i campi delle strutture. Qualcuno potrebbe dire che è meglio elaborare ogni campo della struttura usando un metodo individuale. Riassumendo, direi che ci sono tante opinioni quanti sono i programmatori. Spero che in futuro avremo la possibilità di eseguire tali operazioni utilizzando metodi integrati.
Il metodo AVG() calcola il valore medio aritmetico dell'array passato, ma non mostra l'intero quadro della distribuzione, ecco perché viene fornito con un altro metodo che calcola la deviazione standard STDEV(). La funzione OnTradesStat() ottiene i valori di efficacia (precedentemente calcolati in OnPosStat()) e li elabora con metodi statistici. E infine, la funzione principale della classe - OnPosStat().
Questa funzione dovrebbe essere considerata nel dettaglio. Consiste in due parti, quindi può essere facilmente divisa. La prima parte cerca tutte le posizioni ed elabora la loro id salvandola nell’array temporaneo id_pos. Passo dopo passo: seleziona l'intera cronologia disponibile, calcola il numero di deal, esegui il ciclo di elaborazione dei deal. Il ciclo: se il tipo di deal è balans, saltalo (non è necessario interpretare il deal iniziale), altrimenti - salva l’id della posizione nella variabile ed esegui la ricerca. Se lo stesso id esiste già nella base (l'array di id_po), vai al deal successivo, altrimenti scrivi id alla base. In tal modo, dopo aver elaborato tutti i deal, abbiamo l'array riempito con tutti gli idesistenti di posizioni e il numero di posizioni.
long id_pos[];// auxiliary array for creating the history of positions if(HistorySelect(0,TimeCurrent())) { int HTD=HistoryDealsTotal(); ArrayResize(id_pos,PosTotal,HTD); for(int i=0;i<HTD;i++) { ulong DTicket=(ulong)HistoryDealGetTicket(i); if((ENUM_DEAL_TYPE)HistoryDealGetInteger(DTicket,DEAL_TYPE)==DEAL_TYPE_BALANCE) continue;// if it's a balance deal, skip it long id=HistoryDealGetInteger(DTicket,DEAL_POSITION_ID); bool present=false; // initial state, there's no such position for(int j=0;j<PosTotal;j++) { if(id==id_pos[j]){ present=true; break; } }// if such position already exists break if(!present)// write id as a new position appears { PosTotal++; ArrayResize(id_pos,PosTotal); id_pos[PosTotal-1]=id; } } } ArrayResize(pos,PosTotal);
Nella seconda parte, realizziamo tutti i metodi descritti n precedenza nella classe base C_Pos. Consiste in un ciclo che va oltre le posizioni ed esegue i metodi corrispondenti di elaborazione delle posizioni. La descrizione del metodo è fornita nel codice seguente.
for(int p=0;p<PosTotal;p++) { if(HistorySelectByPosition(id_pos[p]))// select position { pos[p].pos_id=id_pos[p]; // assigned id of position to the corresponding field of the class C_Pos pos[p].count_deals=HistoryDealsTotal();// assign the number of deal in position to the field of the class C_Pos pos[p].symbol=HistoryDealGetString(HistoryDealGetTicket(0),DEAL_SYMBOL);// the same actions with symbol pos[p].OnHistory(); // start filling the structure sd with the history of position pos[p].OnHistoryTransform(); // transformation of interpretation, filling the structure st. pos[p].efficiency(); // calculation of the effectiveness of obtained data All_count_trades+=pos[p].count_trades;// save the number of trades for displaying the total number } }
Metodi di Chiamata della Classe
Quindi, abbiamo considerato l'intera classe. Resta da fare un esempio di chiamata. Per mantenere le possibilità di costruzione, non ho dichiarato esplicitamente la chiamata in una funzione. Inoltre, puoi migliorare la classe per le tue esigenze, implementare nuovi metodi di elaborazione statistica dei dati. Di seguito, viene riportato un esempio di chiamata del metodo della classe da uno script:
//+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ #include <Bulaschev_Statistic.mqh> void OnStart() { C_PosStat start; start.OnPosStat(); start.OnTradesStat(); start.WriteFileDeals(); start.WriteFileTrades(); start.WriteFileTrades_all(); start.WriteFileDealsHTML2(); start.WriteFileTradesHTML2(); Print("cko tr ef=" ,start.stdev.trade_efficiency); Print("mo tr ef=" ,start.avg.trade_efficiency); Print("cko out ef=",start.stdev.exit_efficiency); Print("mo out ef=",start.avg.exit_efficiency); Print("cko in ef=" ,start.stdev.enter_efficiency); Print("mo in ef=" ,start.avg.enter_efficiency); }
Lo script crea 5 file di report in base alla quantità di funzioni che scrivono i dati nel file nella directory Files\OnHistory. Le seguenti funzioni principali sono presenti qui- OnPosStat() e OnTradesStat(), vengono utilizzate per chiamare tutti i metodi necessari. Lo script termina con la stampa del valore ottenuto di efficacia del trading nel suo complesso. Ognuno di questi valori può essere utilizzato per l'ottimizzazione genetica.
Poiché non è necessario scrivere ogni report in un file durante l'ottimizzazione, la chiamata della classe in un Expert Advisor ha un aspetto leggermente diverso. In primo luogo, al contrario di uno script, un Expert Advisor può essere eseguito nel tester (questo è ciò per cui lo prepariamo). Lavorare nello strategy tester ha le sue peculiarità. Durante l'ottimizzazione, abbiamo accesso alla funzione OnTester(), in quanto la sua esecuzione viene eseguita prima dell'esecuzione della funzione OnDeinit(). Quindi, la chiamata dei principali metodi di trasformazione può essere separata. Per la comodità di modificare la funzione fitness dai parametri di un Expert Advisor, ho dichiarato un'enumerazione a livello globale, non come parte della classe. A questo punto, l'enumerazione si trova nello stesso foglio con i metodi della classe C_PosStat.
//+------------------------------------------------------------------+ //| enumeration of fitness functions | //+------------------------------------------------------------------+ enum Enum_Efficiency { avg_enter_eff, stdev_enter_eff, avg_exit_eff, stdev_exit_eff, avg_trade_eff, stdev_trade_eff };
Questo è ciò che dovrebbe essere aggiunto alla voce dell'Expert Advisor.
#include <Bulaschev_Statistic.mqh> input Enum_Efficiency result=0;// Fitness function
Ora, possiamo solo descrivere il passaggio del parametro necessario utilizzando l'operatore switch.
//+------------------------------------------------------------------+ //| Expert optimization function | //+------------------------------------------------------------------+ double OnTester() { start.OnPosStat(); start.OnTradesStat(); double res; switch(result) { case 0: res=start.avg.enter_efficiency; break; case 1: res=-start.stdev.enter_efficiency; break; case 2: res=start.avg.exit_efficiency; break; case 3: res=-start.stdev.exit_efficiency; break; case 4: res=start.avg.trade_efficiency; break; case 5: res=-start.stdev.trade_efficiency; break; default : res=0; break; } return(res); }
Voglio attirare la tua attenzione sul fatto che la funzione OnTester() viene utilizzata per ottimizzare la funzione personalizzata. Se hai bisogno di trovare il minimo della funzione personalizzata, allora è meglio invertire la funzione stessa moltiplicandola per -1. Come nell'esempio con la deviazione standard, tutti capiscono che più piccolo è lo stdev, minore è la differenza tra l'efficacia dei trade, quindi la stabilità dei trade è maggiore. Ecco perché lo stdev dovrebbe essere ridotto al minimo. Ora, poiché abbiamo affrontato la chiamata del metodo di classe, consideriamo la possibilità di scrivere i report in un file.
In precedenza, ho menzionato i metodi di classe che creano il report. Ora, vedremo dove e quando dovrebbero essere chiamati. I report devono essere creati solo quando viene avviato l’Expert Advisor per una singola esecuzione. In caso contrario, l’Expert Advisor creerà i file in modalità di ottimizzazione; cioè invece di un file creerà molti file (se ogni volta vengono passati nomi di file diversi) o uno, ma l'ultimo con lo stesso nome per tutte le esecuzioni, ciò che è assolutamente privo di significato, poiché spreca la risorsa per le informazioni che vengono ulteriormente cancellate.
Ad ogni modo, non è necessario creare file di report durante l'ottimizzazione. Se ottieni molti file con nomi diversi, probabilmente non aprirai la maggior parte di essi. La seconda variante ha uno spreco di risorse per ottenere le informazioni che vengono eliminate immediatamente.
Ecco perché l’opzione migliore è quella di fare filtro (avviare il report solo in modalità Optimization[disabled]). Pertanto, l'HDD non sarà pieno di report che non vengono mai visualizzati. Inoltre, la velocità di ottimizzazione aumenta (non è un segreto che le operazioni più lente siano le operazioni sui file); inoltre, viene mantenuta la possibilità di ottenere rapidamente un report con i parametri necessari. In realtà, non importa dove posizionare il filtro, nell'OnTester o nella funzione OnDeinit. L'importante è che i metodi di classe, che creano il report, dovrebbero essere chiamati dopo i metodi principali che eseguono la trasformazione. Ho posizionato il filtro su OnDeinit() per non sovraccaricare il codice:
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if(!(bool)MQL5InfoInteger(MQL5_OPTIMIZATION)) { start.WriteFileDeals(); // writing csv report on deals start.WriteFileTrades(); // writing csv report on trades start.WriteFileTrades_all(); // writing summary csv report on fitness functions start.WriteFileDealsHTML2(); // writing html report on deals start.WriteFileTradesHTML2();// writing html report on trades } } //+------------------------------------------------------------------+
La sequenza di chiamata dei metodi non è importante. Tutto ciò che è necessario per effettuare i report viene preparato nei metodi OnPosState OnTradesStat. Inoltre, non importa se chiami tutti i metodi di scrittura dei report o solo alcuni di essi; il funzionamento di ciascuno di essi è individuale; è un'interpretazione delle informazioni già memorizzate nella classe.
Controllo nello Strategy Tester.
Il risultato di una singola esecuzione nello strategy tester viene riportato di seguito:
Statistiche sulle Medie Mobili del Report dei Trade | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| # | Ticket | tipo | volume | Open | Close | Prezzo | Efficienza | ||||||
| open | close | prezzo | time | prezzo | ora | max | min | enter | exit | trade | |||
| pos[0] | id 2 | EURUSD | |||||||||||
| 0 | 2 | 3 | buy | 0,1 | 1,37203 | 15.03.2010 13:00:00 | 1,37169 | 15.03.2010 14:00:00 | 1,37236 | 1,37063 | 0,19075 | 0,61272 | -0,19653 |
| pos[1] | id 4 | EURUSD | |||||||||||
| 1 | 4 | 5 | sell | 0,1 | 1,35188 | 23.03.2010 08:00:00 | 1,35243 | 23.03.2010 10:00:00 | 1,35292 | 1,35025 | 0,61049 | 0,18352 | -0,20599 |
| pos[2] | id 6 | EURUSD | |||||||||||
| 2 | 6 | 7 | sell | 0,1 | 1,35050 | 23.03.2010 12:00:00 | 1,35343 | 23.03.2010 16:00:00 | 1,35600 | 1,34755 | 0,34911 | 0,30414 | -0,34675 |
| pos[3] | id 8 | EURUSD | |||||||||||
| 3 | 8 | 9 | sell | 0,1 | 1,35167 | 23.03.2010 18:00:00 | 1,33343 | 26.03.2010 05:00:00 | 1,35240 | 1,32671 | 0,97158 | 0,73842 | 0,71000 |
| pos[4] | id 10 | EURUSD | |||||||||||
| 4 | 10 | 11 | sell | 0,1 | 1,34436 | 30.03.2010 16:00:00 | 1,33616 | 08.04.2010 23:00:00 | 1,35904 | 1,32821 | 0,52384 | 0,74213 | 0,26597 |
| pos[5] | id 12 | EURUSD | |||||||||||
| 5 | 12 | 13 | buy | 0,1 | 1,35881 | 13.04.2010 08:00:00 | 1,35936 | 15.04.2010 10:00:00 | 1,36780 | 1,35463 | 0,68261 | 0,35915 | 0,04176 |
| pos[6] | id 14 | EURUSD | |||||||||||
| 6 | 14 | 15 | sell | 0,1 | 1,34735 | 20.04.2010 04:00:00 | 1,34807 | 20.04.2010 10:00:00 | 1,34890 | 1,34492 | 0,61055 | 0,20854 | -0,18090 |
| pos[7] | id 16 | EURUSD | |||||||||||
| 7 | 16 | 17 | sell | 0,1 | 1,34432 | 20.04.2010. 18:00:00 | 1,33619 | 23.04.2010 17:00:00 | 1,34491 | 1,32016 | 0,97616 | 0,35232 | 0,32848 |
| pos[8] | id 18 | EURUSD | |||||||||||
| 8 | 18 | 19 | sell | 0,1 | 1,33472 | 27.04.2010 10:00:00 | 1,32174 | 29.04.2010 05:00:00 | 1,33677 | 1,31141 | 0,91916 | 0,59267 | 0,51183 |
| pos[9] | id 20 | EURUSD | |||||||||||
| 9 | 20 | 21 | sell | 0,1 | 1,32237 | 03.05.2010 04:00:00 | 1,27336 | 07.05.2010 20:00:00 | 1,32525 | 1,25270 | 0,96030 | 0,71523 | 0,67553 |
Rapporto sull'Efficacia | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fitness Func | Valore Medio | Deviazione Standard | |||||||||||
| Enter | 0,68 | 0,26 | |||||||||||
| Exit | 0,48 | 0,21 | |||||||||||
| Trade | 0,16 | 0,37 | |||||||||||
E il grafico del bilanciamento è:
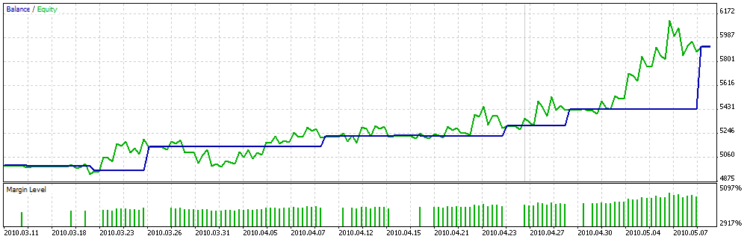
Si può vedere chiaramente sul grafico che la funzione personalizzata di ottimizzazione non cerca di scegliere i parametri con la maggiore quantità di deal, ma i deal con lunga durata, in quanto i deal hanno quasi lo stesso profitto, cioè la dispersione non è elevata.
Poiché il codice delle Medie Mobili non contiene le caratteristiche di aumento del volume di posizione o di chiusura parziale di essa, il risultato della trasformazione non sembra essere vicino a quello sopra descritto. Di seguito, puoi trovare un altro risultato dell'avvio dello script nell'account aperto appositamente per testare i codici:
| pos[286] | id 1019514 | EURUSD | |||||||||||
| 944 | 1092288 | 1092289 | buy | 0,1 | 1, 26733 | 08.07.2010 21:14:49 | 1,26719 | 08.07.2010 21:14:57 | 1,26752 | 1,26703 | 0,38776 | 0,32653 | -0,28571 |
| pos[287] | id 1019544 | EURUSD | |||||||||||
| 945 | 1092317 | 1092322 | sell | 0,2 | 1,26761 | 08.07.2010 21:21:14 | 1,26767 | 08.07.2010 21:22:29 | 1,26781 | 1,26749 | 0,37500 | 0,43750 | -0,18750 |
| 946 | 1092317 | 1092330 | sell | 0,2 | 1,26761 | 08.07.2010 21:21:14 | 1,26792 | 08.07.2010 21:24:05 | 1,26782 | 1,26749 | 0,36364 | -0,30303 | -0,93939 |
| 947 | 1092319 | 1092330 | sell | 0,3 | 1,26761 | 08.07.2010 21:21:37 | 1,26792 | 08.07.2010 21:24:05 | 1,26782 | 1,26749 | 0,36364 | -0,30303 | -0,93939 |
| pos[288] | id 1019623 | EURUSD | |||||||||||
| 948 | 1092394 | 1092406 | buy | 0,1 | 1,26832 | 08.07.2010 21:36:43 | 1,26843 | 08.07.2010 21:37:38 | 1,26882 | 1,26813 | 0,72464 | 0,43478 | 0,15942 |
| pos[289] | id 1019641 | EURUSD | |||||||||||
| 949 | 1092413 | 1092417 | buy | 0,1 | 1,26847 | 08.07.2010 21:38:19 | 1,26852 | 08.07.2010 21:38:51 | 1,26910 | 1,26829 | 0,77778 | 0,28395 | 0,06173 |
| 950 | 1092417 | 1092433 | sell | 0,1 | 1,26852 | 08.07.2010 21:38:51 | 1,26922 | 08.07.2010 21:39:58 | 1,26916 | 1,26829 | 0,26437 | -0,06897 | -0,80460 |
| pos[290] | id 1150923 | EURUSD | |||||||||||
| 951 | 1226007 | 1226046 | buy | 0,2 | 1,31653 | 05.08.2010 16:06:20 | 1,31682 | 05.08.2010 16:10:53 | 1,31706 | 1,31611 | 0,55789 | 0,74737 | 0,30526 |
| 952 | 1226024 | 1226046 | buy | 0,3 | 1,31632 | 05.08.2010 16:08:31 | 1,31682 | 05.08.2010 16:10:53 | 1,31706 | 1,31611 | 0,77895 | 0,74737 | 0,52632 |
| 953 | 1226046 | 1226066 | sell | 0,1 | 1,31682 | 05.08.2010 16:10:53 | 1,31756 | 05.08.2010 16:12:49 | 1,31750 | 1,31647 | 0,33981 | -0,05825 | -0,71845 |
| 954 | 1226046 | 1226078 | sell | 0,2 | 1,31682 | 05.08.2010 16:10:53 | 1,31744 | 05.08.2010 16:15:16 | 1,31750 | 1,31647 | 0,33981 | 0,05825 | -0,60194 |
| pos[291] | id 1155527 | EURUSD | |||||||||||
| 955 | 1230640 | 1232744 | sell | 0,1 | 1,31671 | 06.08.2010 13:52:11 | 1,32923 | 06.08.2010 17:39:50 | 1,33327 | 1,31648 | 0,01370 | 0,24062 | -0,74568 |
| 956 | 1231369 | 1232744 | sell | 0,1 | 1,32584 | 06.08.2010 14:54:53 | 1,32923 | 06.08.2010 17:39:50 | 1,33327 | 1,32518 | 0,08158 | 0,49938 | -0,41904 |
| 957 | 1231455 | 1232744 | sell | 0,1 | 1,32732 | 06.08.2010 14:58:13 | 1,32923 | 06.08.2010 17:39:50 | 1,33327 | 1,32539 | 0,24492 | 0,51269 | -0,24239 |
| 958 | 1231476 | 1232744 | sell | 0,1 | 1,32685 | 06.08.2010 14:59:47 | 1,32923 | 06.08.2010 17:39:50 | 1,33327 | 1,32539 | 0,18528 | 0,51269 | -0,30203 |
| 959 | 1231484 | 1232744 | sell | 0,2 | 1,32686 | 06.08.2010 15:00:20 | 1,32923 | 06.08.2010 17:39:50 | 1,33327 | 1,32539 | 0,18655 | 0,51269 | -0,30076 |
| 960 | 1231926 | 1232744 | sell | 0,4 | 1,33009 | 06.08.2010 15:57:32 | 1,32923 | 06.08.2010 17:39:50 | 1,33327 | 1,32806 | 0,38964 | 0,77543 | 0,16507 |
| 961 | 1232591 | 1232748 | sell | 0,4 | 1,33123 | 06.08.2010 17:11:29 | 1,32850 | 06.08.2010 17:40:40 | 1,33129 | 1,32806 | 0,98142 | 0,86378 | 0,84520 |
| 962 | 1232591 | 1232754 | sell | 0,4 | 1,33123 | 06.08.2010 17:11:29 | 1,32829 | 06.08.2010 17:42:14 | 1,33129 | 1,32796 | 0,98198 | 0,90090 | 0,88288 |
| 963 | 1232591 | 1232757 | sell | 0,2 | 1,33123 | 06.08.2010 17:11:29 | 1,32839 | 06.08.2010 17:43:15 | 1,33129 | 1,32796 | 0,98198 | 0,87087 | 0,85285 |
| pos[292] | id 1167490 | EURUSD | |||||||||||
| 964 | 1242941 | 1243332 | sell | 0,1 | 1,31001 | 10.08.2010 15:54:51 | 1,30867 | 10.08.2010 17:17:51 | 1,31037 | 1,30742 | 0,87797 | 0,57627 | 0,45424 |
| 965 | 1242944 | 1243333 | sell | 0,1 | 1,30988 | 10.08.2010 15:55:03 | 1,30867 | 10.08.2010 17:17:55 | 1,31037 | 1,30742 | 0,83390 | 0,57627 | 0,41017 |
| pos[293] | id 1291817 | EURUSD | |||||||||||
| 966 | 1367532 | 1367788 | sell | 0,4 | 1.28904 | 06.09.2010 00:24:01 | 1,28768 | 06.09.2010 02:53:21 | 1,28965 | 1,28710 | 0,76078 | 0,77255 | 0,53333 |
Ecco come appare l'informazione trasformata; per dare ai lettori la possibilità di considerare tutto deliberatamente (e la cognizione arriva attraverso il confronto), salvo la storia originale dei deal in un file separato; questa è la storia che ora manca a molti trader, che sono abituati a vederla nella sezione [Resultati] di MetaTrader 4.
Conclusione
In conclusione, voglio suggerire agli sviluppatori di aggiungere la possibilità di ottimizzare gli Expert Advisor non solo con un parametro personalizzato, ma di realizzarlo in combinazione con quelli standard come si fa con le altre funzioni di ottimizzazione. Riassumendo questo articolo, posso dire che contiene solo le basi, il potenziale iniziale. Spero che i lettori siano in grado di migliorare la classe in base alle proprie esigenze. Buona Fortuna!