Repaso de HTML usando MQL4
MetaQuotes | 20 abril, 2016
Introducción
HTML (lenguaje de marca de hipertexto) fue creado para formatear adecuadamente materiales contextuales. Todos los documentos de este tipo se formatean con palabras que realizan una función especial llamadas 'etiquetas'. Prácticamente toda la información en los archivos html quedan incluidas dentro de etiquetas. Si queremos extraer los datos puros, tenemos que separar la información del servicio (etiquetas) de los datos correspondientes. Llamaremos a este procedimiento un repaso de HTML cuya finalidad es destacar la estructura de las etiquetas.
¿Qué es una etiqueta?
En términos de una simple descripción, una etiqueta es cualquier palabra encerrada en corchetes angulares. Por ejemplo, esto es una etiqueta: <etiqueta>, aunque en HTML las etiquetas son ciertas palabras que se escriben en caracteres latinos. Por ejemplo, <html> es una etiqueta correcta, pero no hay una etiqueta <html2>. Además, muchas etiquetas pueden tener atributos adicionales que requieren un formato realizado por dicha etiqueta. Por ejemplo, <div align="center"> es la etiqueta <div> en la que se especifica el atributo adicional de alineación centrada del contenido de la misma.
Las etiquetas se suelen utilizar en pares: hay etiquetas de apertura y de cierre. Se diferencia entre sí solo por la presencia de la barra inclinada. La etiqueta <div> es una etiqueta de apertura, mientras que la etiqueta </div> es una de cierre. Todos los datos encerrados entre las etiquetas de apertura y de cierre son el contenido de la etiqueta. Este es el contenido que nos interesa en la revisión del código HTML. Ejemplo:
<td>6</td>
La etiqueta <td> contiene aquí '6'.
¿Qué significa "revisión del texto"?
En el contenido de este artículo, significa que queremos obtener todas las palabras incluidas en un archivo html y encerradas dentro de dos corchetes en ángulo: '<' y '>' - apertura y cierre. No analizaremos aquí si cada palabra en estos corchetes es una palabra correcta o no. Nuestra tarea es puramente técnica. Escribiremos todas las etiquetas consecutivas encontradas en una matriz de string por orden de llegada. Llamaremos a esta matriz 'estructura de etiqueta'.
Función de lectura de archivo
Antes de analizar un archivo de texto es mejor cargarlo en una matriz string. De este modo, abriremos y cerraremos inmediatamente el archivo para no olvidar cerrarlo por error. Además, una función definida por el usuario que lee el texto de un archivo en una matriz es mucho más conveniente para una aplicación múltiple que escribir cada vez todo el procedimiento de lectura de los datos con una comprobación obligada de los posibles errores. La función ReadFileToArray() tiene tres parámetros:
- string array[] - una matriz string pasada por un enlace que permite cambiar su tamaño y contenido directamente en la función;
- string FileName - el archivo da nombre a las líneas desde las que debe leer en array[];
- string WorkFolderName - nombre de subcarpeta en el directorio Terminal_directory\experts\files.
//+------------------------------------------------------------------+ //| writing the content of the file into string array 'array[]' | //| in case of failing, return 'false' | //+------------------------------------------------------------------+ bool ReadFileToArray(string &array[],string FileName, string WorkFolderName) { bool res=false; int FileHandle; string tempArray[64000],currString; int stringCounter; int devider='\x90'; string FullFileName; if (StringLen(WorkFolderName)>0) FullFileName=StringConcatenate(WorkFolderName,"\\",FileName); else FullFileName=FileName; //---- Print("Trying to read file ",FileName); FileHandle=FileOpen(FullFileName,FILE_READ,devider); if (FileHandle!=-1) { while(!FileIsEnding(FileHandle)) { tempArray[stringCounter]=FileReadString(FileHandle); stringCounter++; } stringCounter--; if (stringCounter>0) { ArrayResize(array,stringCounter); for (int i=0;i<stringCounter;i++) array[i]=tempArray[i]; res=true; } FileClose(FileHandle); } else { Print("Failed reading file ",FileName); } //---- return(res); }
El tamaño de la matriz string auxiliar es 64.000 elementos. Los archivos de un mayor número de líneas se supone que no aparecen con mucha frecuencia. No obstante, podemos cambiar este parámetros a nuestro antojo. La variable stringCounter cuenta el número de líneas leídas del archivo en la matriz auxiliar temArray[], luego, las líneas leídas se escriben en array[], cuyo tamaño se establece previamente igual a stringCounter. En caso de error, el programa mostrará un mensaje en los registros del asesor experto, que podemos ver en la pestaña "Experts".
Si array[] ya ha sido rellenada con éxito, la función ReadFileToArray() devuelve 'true'. De lo contrario, devuelve 'false'.
Función de ayuda FindInArray()
Antes de comenzar a procesar el contenido de la matriz string en nuestra búsqueda de las etiquetas, debemos dividir la tarea general en varias subtareas más pequeñas. Hay varias soluciones para la tarea de detectar la estructura de la etiqueta. Ahora veremos una específica. Vamos a crear una función que nos informará en qué línea y en qué posición en esta línea se coloca la palabra buscada. Pasaremos a esta función la matriz string y la variable string que contiene la palabra que estamos buscando.
//+-------------------------------------------------------------------------+ //| It returns the coordinates of the first entrance of text matchedText | //+-------------------------------------------------------------------------+ void FindInArray(string Array[], // string array to search matchedText for int inputLine, // line number to start search from int inputPos, // position number to start search from int & returnLineNumber, // found line number in the array int & returnPosIndex, // found position in the line string matchedText // searched word ) { int start; returnLineNumber=-1; returnPosIndex=-1; int pos; //---- for (int i=inputLine;i<ArraySize(Array);i++) { if (i==inputLine) start=inputPos; else start=0; if (start>=StringLen(Array[i])) start=StringLen(Array[i])-1; pos=StringFind(Array[i],matchedText,start); if (pos!=-1) { returnLineNumber=i; returnPosIndex=pos; break; } } //---- return; }
La función FindInArray() devuelve las "coordenadas" de matchedText usando variables entero pasadas por enlace. La variable returnLineNumber contiene el número de línea, mientras que returnPosIndex contiene el número de la posición en esta línea.
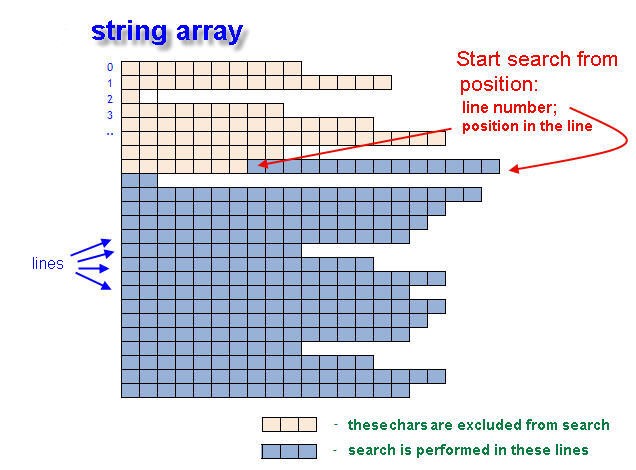
Fig. 1. Busca la posición inicial del texto en la matriz string.
Esta búsqueda no se realiza en toda la matriz, sino que comienza desde el número de línea inputLine y el número de posición inpuPos. Estas son coordenadas de búsqueda inicial en Array[]. Si no se encuentra la palabra de la búsqueda, la variables devueltas (returnLineNumber y returnPosIndex) contendrán el valor -1 (menos uno).
Obtener una línea por sus coordenadas de inicio y finalización a partir de una matriz string
Si tenemos las coordenadas de inicio y finalización de una etiqueta, necesitamos obtener y escribir en el string todos los caracteres situados entre los dos corchetes en ángulo. Usaremos para ello la función getTagFromArray().
//+------------------------------------------------------------------+ //| it returns a tag string value without classes | //+------------------------------------------------------------------+ string getTagFromArray(string inputArray[], int lineOpen, int posOpen, int lineClose, int posClose, int line_, int pos_) { string res=""; //---- if (ArraySize(inputArray)==0) { Print("Zero size of the array in function getTagFromArray()"); return(res); } string currString; int endLine=-1; int endPos=-1; if (lineClose>=0 && line_>=0) // both space and a closing angle bracket are available { endLine=MathMin(lineClose,line_); // the number of ending line is defined if (lineClose==line_ && pos_<posClose) endPos=pos_;// if the space and the closing angle bracket are in // one line, the position number is the same as that of the space if (lineClose==line_ && pos_>posClose) endPos=posClose;// if the space and the closing angle bracket are in // one line, the position number is the same as that of the space if (lineClose>line_) endPos=pos_;// if the line containing a space is before the line containing a closing bracket, // the position is equal to that of the space if (lineClose<line_) endPos=posClose;// if the line containing a closing bracket is before the line // containing a space, the position is equal to that of the closing bracket } if (lineClose>=0 && line_<0) // no space { endLine=lineClose; endPos=posClose; } for (int i=lineOpen;i<=endLine;i++) { if (i==lineOpen && lineOpen!=endLine) // if the initial line from the given position { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen)); } if (i==lineOpen && lineOpen==endLine) // one line { currString=inputArray[i]; res=StringConcatenate(res,StringSubstr(currString,posOpen,endPos-posOpen)); } if (i>lineOpen && i<endLine) // copy the whole line { res=StringConcatenate(res,inputArray[i]); } if (i>endLine && endLine>lineOpen) // copy the beginning of the end line { currString=inputArray[i]; if (endPos>0) res=StringConcatenate(res,StringSubstr(currString,0,endPos)); } } if (StringLen(res)>0) res=res+">"; //---- return(res); }
En esta función, buscamos consecutivamente en todas las líneas situadas dentro de las coordenadas de los corchetes de ángulo de apertura y cierre con la participación de las coordenadas espaciales. El funcionamiento de la función permite obtener la expresión de <tag_name>, que consta de varias líneas.
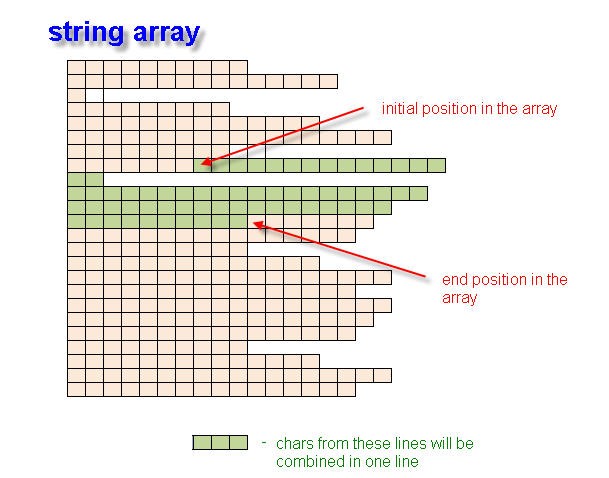
Fig. 2. Creación de una variable string de la matriz string usando las posiciones iniciales y finales.
Obtención de la estructura de la etiqueta
Ahora tenemos dos funciones de ayuda, por lo que podemos comenzar a buscar las etiquetas. Para ello, buscaremos consecutivamente '<', '>' y ' ' (space) con la función FindInArray(). Para ser más exactos, buscaremos las posiciones de estos caracteres en la matriz string y luego ensamblaremos los nombres de las etiquetas encontradas usando la función getTagFromArray() y luego los colocaremos en una matriz que contenga la estructura de la etiqueta. Como puede ver, la tecnología es muy simple. Este algoritmo se materializa en la función FillTagStructure().
//+------------------------------------------------------------------+ //| fill out the tag structure | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// tag structure being created string array[], // initial html text int line, // line number in array[] int pos) // position number in the line { //---- int array_Size=ArraySize(array); if (line==-1000 || pos==-1000 ) { Alert("Invalid values of search position in function FillTagStructure()"); return; } string currString="",newTag=""; int size=ArraySize(array),structureSize=ArraySize(structure); if (size==0) { Alert("Zero-size array is passed for processing to function FillTagStructure()"); return; } int newLine=-1000,newPos=-1000; bool tagFounded=false; int lineOpen,posOpen,lineClose,posClose,line_,pos_; FindInArray(array,line,pos,lineOpen,posOpen,"<"); if (lineOpen!=-1 && posOpen!=-1) { FindInArray(array,lineOpen,posOpen+1,lineClose,posClose,">"); FindInArray(array,lineOpen,posOpen+1,line_,pos_," "); if (lineClose !=-1) // a closing angle bracket is found { newTag=getTagFromArray(array,lineOpen,posOpen,lineClose,posClose,line_,pos_); newLine=lineClose; newPos=posClose+1; tagFounded=true; } else { Print("Closing angle bracket is not found in function FillTagStructure()" ); return; } } if (tagFounded) { ArrayResize(structure,structureSize+1); structure[structureSize]=newTag; FillTagStructure(structure,array,newLine,newPos); } //---- return; }
Recuerde que en caso de encontrar una etiqueta, el tamaño de la matriz que representa la estructura de la etiqueta se incrementa en una unidad, se añade una nueva etiqueta y luego la función se llama a sí misma de forma recursiva.

Fig. 3. Un ejemplo de esta función recursiva: La función FillTagStructure() se llama a sí misma.
Este método para escribir funciones para realizar cálculos consecutivos es muy atractivo y a menudo mejora el lote de un programador. En base a esta función se desarrolló el script TagsFromHTML.mq4 que busca las etiquetas en el informe del probador, StrategyTester.html, y muestra todas las etiquetas encontradas en el registro.
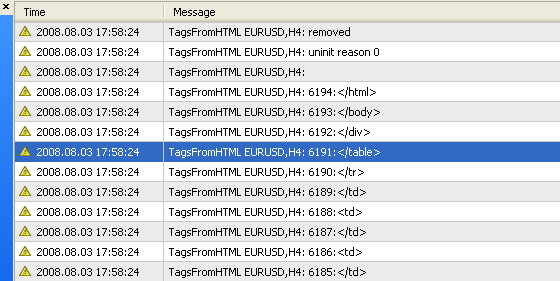
Fig. 4. Resultado de las operaciones del script TagsFromHTML.mq4: Se muestran el número de la etiqueta y la propia etiqueta.
Como puede ver, un informe de pruebas puede contener algunos miles de etiquetas. En la Fig. 4 puede ver que la última etiqueta encontrada, </html>, tiene el número 6194. Es imposible buscar en dicha cantidad de etiquetas manualmente.
Encerrando los contenidos entre etiquetas
Buscar las etiquetas es una tarea auxiliar, ya que la tarea principal es obtener información contenida en las etiquetas. Si vemos el contenido de StartegyTester.html usando un editor de textos, por ejemplo, Notepad, podemos ver que los datos del informe se encuentran en las etiquetas <table> y</table>. La etiqueta 'table' sirve para formatear datos tabulados y normalmente incluye muchas líneas colocadas entre las etiquetas <tr> y </tr>.
A su vez, cada línea contiene celdas que están colocadas entre las etiquetas <td> y </td>. Nuestro propósito es encontrar contenidos relevantes entre las etiquetas <td> y recopilar estos datos en strings formateados según nuestras necesidades. En primer lugar, vamos a realizar algunas modificaciones en la función FillTagStructure() de forma que podamos almacenar la estructura de la etiqueta y la información sobre las posiciones de inicio y finalización de la etiqueta.

Fig. 5. Junto con la propia etiqueta, sus posiciones de inicio y finalización en la matriz de string se escriben en las matrices correspondientes.
Sabiendo el nombre de la etiqueta y las coordenadas de cada inicio y finalización de la etiqueta, podemos fácilmente obtener el contenido situado entre dos etiquetas consecutivas. Para esta finalidad, vamos a escribir otra función, GetContent(), que es muy similar a la función getTagFromArray().
//+------------------------------------------------------------------+ //| get the contents of lines within the given range | //+------------------------------------------------------------------+ string GetContent(string array[], int start[1][2],int end[1][2]) { string res = ""; //---- int startLine = start[0][0]; int startPos = start[0][1]; int endtLine = end[0][0]; int endPos = end[0][1]; string currString; for (int i = startLine; i<=endtLine; i++) { currString = array[i]; if (i == startLine && endtLine > startLine) { res = res + StringSubstr(currString, startPos); } if (i > startLine && i < endtLine) { res = res + currString; } if (endtLine > startLine && i == endtLine) { if (endPos > 0) res = res + StringSubstr(currString, 0, endPos); } if (endtLine == startLine && i == endtLine) { if (endPos - startPos > 0) res = res + StringSubstr(currString, startPos, endPos - startPos); } } //---- return(res); }
Ahora podemos procesar los contenidos de las etiquetas en cualquier forma que nos sea cómoda. Puede ver un ejemplo de dicho procesamiento en el script ReportHTMLtoCSV.mq4. Esta es la función start() del script:
int start() { //---- int i; string array[]; ReadFileToArray(array, filename,""); int arraySize=ArraySize(array); string tags[]; // array to store tags int startPos[][2];// tag-start coordinates int endPos[][2]; // tag-end coordinates FillTagStructure(tags, startPos, endPos, array, 0, 0); //PrintStringArray(tags, "tags contains tags"); int tagsNumber = ArraySize(tags); string text = ""; string currTag; int start[1][2]; int end[1][2]; for (i = 0; i < tagsNumber; i++) { currTag = tags[i]; //Print(tags[i],"\t\t start pos=(",startPos[i][0],",",startPos[i][1],") \t end pos = (",endPos[i][0],",",endPos[i][1],")"); if (currTag == "<table>") { Print("Beginning of table"); } if (currTag == "<tr>") { text = ""; start[0][0] = -1; start[0][1] = -1; } if (currTag == "<td>") {// coordinates of the initial position for selecting the content between tags start[0][0] = endPos[i][0]; start[0][1] = endPos[i][1]; } if (currTag == "</td>") {// coordinates of the end position for selecting the content between tags end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; } if (currTag == "</td>") {// coordinates of the end position for selecting the content between tags end[0][0] = startPos[i][0]; end[0][1] = startPos[i][1]; text = text + GetContent(array, start, end) + ";"; } if (currTag == "</tr>") { Print(text); } if (currTag == "</table>") { Print("End of table"); } } //---- return(0); }
En la Fig. 6 puede ver cómo aparece un archivo de registro conteniendo los mensajes de este script y abierto con Microsoft Excel.
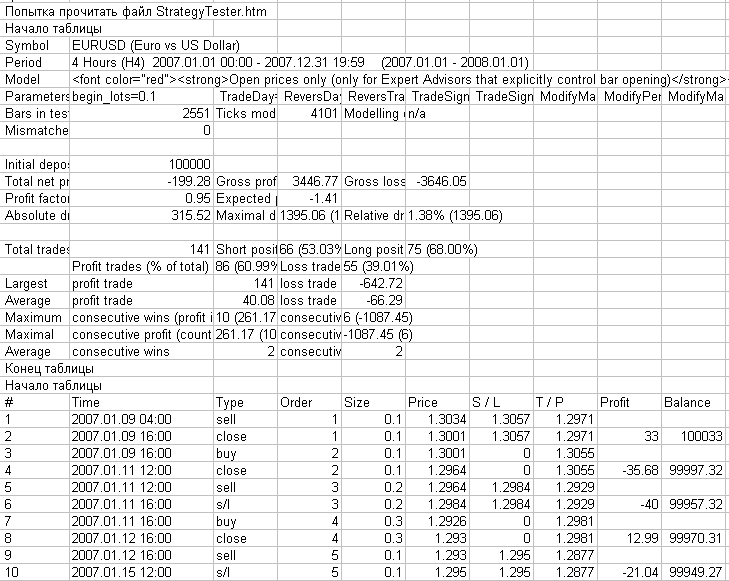
Fig. 6. El archivo de registro de la carpeta MetaTrader 4\experts\logs que contiene los resultados del funcionamiento del script ReportHTMLtoCSV.mq4, abierto con Micrisoft Excel.
En la Fig. 6 anterior puede ver la estructura conocida del informe de pruebas de MetaTrader 4.
Defectos de este script
Hay varios tipos de errores de programación. Los errores del primer tipo (errores sintácticos) son fáciles de detectar en la fase de compilación. Los errores del segundo tipo son algorítmicos. El código del programa se compila correctamente, pero puede haber situaciones imprevistas en el algoritmo que originan patrones de error en el programa o incluso un fallo del sistema. Estos errores no son tan fáciles de detectar, pero aún es posible.
Por último, puede haber errores del tercer tipo, los errores conceptuales. Dichos errores se producen si el algoritmo del programa, estando escrito correctamente, no está listo para usar el programa en condiciones algo distintas. El script ReportHTMLtoCSV.mq4 es bastante adecuado para procesar documentos html pequeños que contenga algunos miles de etiquetas, pero no lo es tanto para procesar millones de ellas. Tiene dos cuellos de botella. El primero es el redimensionamiento múltiple de las matrices.

Fig. 7. Múltiples llamadas a la función ArrayResize() para cada nueva etiqueta encontrada.
En el proceso de funcionamiento del script, la llamada a la función ArrayResize() decenas, cientos de miles o incluso millones de veces requerirá emplear una gran cantidad de tiempo. Cada redimensionamiento dinámico de una matriz requiere algo de tiempo para asignar una nueva área del tamaño necesario en la memoria del PC y para copiar el contenido de la antigua matriz en esta nueva. Si asignamos una matriz de un tamaño bastante mayor por adelantado, podremos reducir sustancialmente el tiempo necesario para estas operaciones adicionales. Por ejemplo, vamos a declarar la matriz 'tags' de la forma siguiente:
string tags[1000000]; // array to store tags
Ahora podemos escribir en ella hasta millones de etiquetas sin que se necesario llamar a la función ArrayResize() un millón de veces.
El otro defecto del script ReportHTMLtoCSV.mq4 es el uso de la función recursiva. Cada llamada de la función FillTagStructure() requiere la asignación de una cierta área de la RAM para colocar la variable local necesaria en esta copia local de la función. Si el documento contiene 10.000 etiquetas, la función FillTagStructure() será llamada 10.000 veces. La memoria para situar la función recursiva se asigna de una zona reservada previamente cuyo tamaño se indica por la directiva #property del tamaño de pila:
#property stacksize 1000000
En este caso, al compilador se le asigna un millón de bytes para la pila. Si la memoria de la pila no es suficiente para las llamadas a la función, obtendremos el error stack overflow (desbordamiento de pila). Si necesitamos llamar a la función recursiva millones de veces, incluso la asignación de centenares de megabytes a la pila puede ser una tarea en vano. Por tanto, tenemos que modificar ligeramente el algoritmo de búsqueda de la etiqueta para evitar el uso de llamadas recursivas.
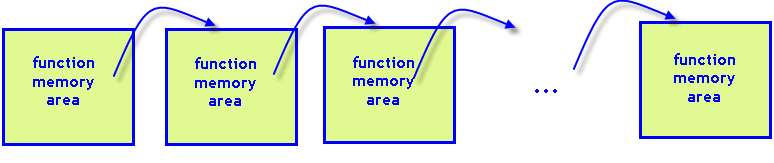
Fig. 8. Cada llamada a la función recursiva requiere su propia zona de la memoria en la pila del programa.
Lo haremos de otra forma: nueva función FillTagStructure()
Vamos a reescribir la función para la obtención de la estructura de la etiqueta. Ahora, esta usará explícitamente un ciclo para trabajar con el string array[]. El algoritmo de la nueva función es claro, si ha entendido el de la antigua función.
//+------------------------------------------------------------------+ //| it fills out the tag structure | //+------------------------------------------------------------------+ void FillTagStructure(string & structure[],// tag structure to be created int & start[][], // tag start (line, position) int & end[][], // tag end (line, position) string array[]) // initial html text { //---- int array_Size = ArraySize(array); ArrayResize(structure, capacity); ArrayResize(start, capacity); ArrayResize(end, capacity); int i=0, line, posOpen, pos_, posClose, tagCounter, currPos = 0; string currString; string tag; int curCapacity = capacity; while (i < array_Size) { if (tagCounter >= curCapacity) // if the number of tags exceeds { // the storage capacity ArrayResize(structure, curCapacity + capacity); // increase the storage in size ArrayResize(start, curCapacity + capacity); // also increase the size of the array of start positions ArrayResize(end, curCapacity + capacity); // also increase the size of the array of end positions curCapacity += capacity; // save the new capacity } currString = array[i]; // take the current string //Print(currString); posOpen = StringFind(currString, "<", currPos); // search for the first entrance of '<' after position currPos if (posOpen == -1) // not found { line = i; // go to the next line currPos = 0; // in the new line, search from the very beginning i++; continue; // return to the beginning of the cycle } // we are in this location, so a '<' has been found pos_ = StringFind(currString, " ", posOpen); // then search for a space, too posClose = StringFind(currString, ">", posOpen); // search for the closing angle bracket if ((pos_ == -1) && (posClose != -1)) // space is not found, but the bracket is { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it into tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } // we are in this location, so both the space and the closing bracket have been found if ((pos_ != -1) && (posClose != -1)) { if (pos_ > posClose) // space is after bracket { tag = StringSubstr(currString, posOpen, posClose - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it to the tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } // no, the space is still before the closing bracket if (pos_ < posClose) { tag = StringSubstr(currString, posOpen, pos_ - posOpen) + ">"; // assemble tag structure[tagCounter] = tag; // written it to the tags array setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // we will start the next search for a new tag continue; // from position posClose where a closing bracket has been found } } // we are in this location, so neither a space nor a closing bracket have been found if ((pos_ == -1) && (posClose == -1)) { tag = StringSubstr(currString, posOpen) + ">"; // assemble a tag of what we have structure[tagCounter] = tag; // written it to the tags array while (posClose == -1) // and organized a cycle to search for { // the first closing bracket i++; // increase in size the counter of lines currString = array[i]; // count the new line posClose = StringFind(currString, ">"); // and search for a closing bracket in it } setPositions(start, end, tagCounter, i, posOpen, i, posClose+1); tagCounter++; // increased in size the counter of tags found currPos = posClose; // it seems to have been found, then set the initial position } // to search for a new tag } ArrayResize(structure, tagCounter); // cut the tags array size down to the number of //---- // tags found return; }
Las matrices ahora se redimensionan por partes según la capacidad (capacity) de los elementos. El valor de capacity se indica declarando la constante:
#define capacity 10000
Las posiciones de inicio y finalización de cada etiqueta se establecen ahora usando la función setPositions().
//+------------------------------------------------------------------+ //| write the tag coordinates into the corresponding arrays | //+------------------------------------------------------------------+ void setPositions(int & st[][], int & en[][], int counter,int stLine, int stPos, int enLine, int enPos) { //---- st[counter][0] = stLine; st[counter][1] = stPos; en[counter][0] = enLine; en[counter][1] = enPos; //---- return; }
A propósito, ya no necesitamos las funciones FindInArray() and getTagFromArray(). Se adjunta el código completo dado en el scriptReportHTMLtoCSV-2.mq4. El vídeo nos muestra cómo usar el script.
Conclusión
Se revisa el algoritmo del repaso del documento HTML para las etiquetas y se da un ejemplo de cómo extraer información del informe del probador de estrategias en el terminal de cliente de MetaTrader 4.
No intente usar llamadas masivas a la función ArrayResize() ya que esto puede provocar un consumo excesivo de tiempo.
Además, el uso de funciones recursivas puede consumir recursos de RAM esenciales. Si se usan llamadas masivas a dicha función, intente reescribirlas para que no sea necesaria la recursión.