Predicción del precio usando redes neuronales
Shashev Sergei | 14 marzo, 2016
Introducción
Durante los últimos años observamos la aparición de un gran interés por las redes neuronales, usadas con éxito en distintas áreas: los negocios, la medicina, la tecnología, la geología y la física. Las redes neuronales se usan ampliamente en ámbitos que requieren la predicción, la clasificación y la gestión. Este impresionante éxito se debe a varias razones:
- Amplias posibilidades. Las redes neuronales son una potente herramienta de modelado que permite la reproducción de relaciones tremendamente complejas. En particular, las redes neuronales son no lineales por naturaleza. Durante un periodo de muchos años, el modelado lineal era el principal método para el modelado en la mayoría de campos, ya que los procedimientos de optimización para ello están bien desarrollados. En las tareas donde la aproximación lineal no es suficiente, los modelos lineales funcionan con escasa eficacia. Además, las redes neuronales son capaces de vencer "el curso de la dimensionalidad", lo que no permite el modelado de relaciones lineales cuando tenemos un gran número de variables.
- Uso fácil. Las redes neuronales aprenden mediante ejemplos. El usuario de una red neuronal coteja los datos representativos y luego inicia el algoritmo de entrenamiento, que acepta automáticamente la estructura de datos. Por supuesto, el usuario debe tener una serie de conocimientos heurísticos sobre la forma de seleccionar y preparar los datos, de elegir la arquitectura de red adecuada y de interpretar los resultados. No obstante, el nivel de conocimientos necesarios para usar con éxito las redes neuronales es mucho menor que el necesario en los métodos estadísticos tradicionales.
Las redes neuronales son atractivas desde el punto de vista de la intuición, ya que están basadas en el modelo primitivo biológico de los sistemas nerviosos. En el futuro, el desarrollo de dichos modelos neurobiológicos puede llevar a la creación de computadoras realmente inteligentes. [1]
La predicción de series de tiempo financieras es un elemento fundamental de cualquier actividad de inversión. La idea de inversión, invertir dinero ahora con la finalidad de obtener beneficios en el futuro, se basa en la idea de predecir el futuro. Por consiguiente, la predicción de series de tiempo financieras es una parte central del sector de la inversión: todas las bolsas de valores y mercados bursátiles no oficiales.
Se sabe que el 99 % de todas las operaciones son especulativas, es decir, no tienen por finalidad obtener resultados reales, sino obtener beneficios usando el sistema "comprar barato y vender caro". Todas ellas están basadas en predicciones de los movimientos del precio por parte de los participantes en las transacciones. Algo que es importante: las predicciones de los participantes en las transacciones son opuestas entre sí. Por tanto, la cantidad de operaciones especulativas caracteriza la diferencia en las predicciones de los participantes en el mercado, es decir, en realidad la imposibilidad de predecir las series de tiempo financieras.
Esta es la característica más importante de las series de tiempo del mercado y subyace a la teoría del mercado "eficiente", descrita en la tesis de L. Bachelier en 1900. De acuerdo con esta tesis, un inversor solo puede confiar en la rentabilidad media del mercado, evaluada por los índices, como el Dow Jones o el S&P 500 para la bolsa de Nueva York. Cualquier beneficio especulativo es aleatorio por naturaleza y es como los juegos de azar (hay algo atractivo en ello, ¿verdad?). La razón de la naturaleza impredecible de las curvas del mercado es la misma que la de por qué el dinero raramente se encuentra en el suelo en los sitios públicos: lo desean demasiadas personas.
Naturalmente, la teoría de un mercado eficiente no es apoyada por los participantes en el mercado (que buscan el dinero que está por ahí en cualquier parte). Muchos de ellos creen que, a pesar de parecer estocástico, todas las series de tiempo están repletas de regularidades ocultas, es decir, que son predecibles, al menos parcialmente. El fundador el análisis ondulatorio, E. Elliot, intentó encontrar dichas irregularidades empíricas ocultas en sus artículos de la década de los años 30.
En los 80, este punto de vista fue inesperadamente apoyado por la recién aparecida teoría del caos dinámico. Esta teoría se basa en la contraposición del estado caótico y la aleatoriedad. Las series caóticas solo parecen aleatorias, pero como procesos dinámicos determinísticos, permiten la predicción a corto plazo. El ámbito de la predicción probabilística está restringido a nivel temporal por el horizonte de predicción, pero este puede ser suficiente para obtener beneficios reales de la predicción (Chorafas, 1994). Y quienes usan los mejores métodos matemáticos para la obtención de regularidades a partir de las series caóticas con ruido, pueden esperar grandes beneficios, a expensas de compañeros menos equipados.
La última década se ha caracterizado por un crecimiento constante de la popularidad del análisis técnico: un conjunto de reglas empíricas basadas en distintos indicadores sobre el comportamiento del mercado. El análisis técnico se centra en el comportamiento individual de este instrumento financiero, aparte de otros valores bursátiles. Pero el análisis técnico es muy subjetivo y funciona de forma ineficiente en el extremo derecho del gráfico: exactamente donde necesitamos la predicción de la dirección del precio. Por esta razón, está ganando más popularidad el análisis de la neurored, ya que, al contrario que el técnico, no establece ningún tipo de restricción sobre el tipo de información de entrada. Esto puede ser los indicadores de las series de indicador, así como la información sobre el comportamiento de otros instrumentos del mercado. No en vano, las redes neuronales son usadas ampliamente por los inversores institucionales (por ejemplo, grandes fondos de capital de pensiones), que trabajan con grandes carteras, dando una gran importancia a la correlación entre los distintos mercados.
El modelado puro de neuroredes se basa solo en los datos y no usa ningún argumento previo. Este es, al mismo tiempo, su punto fuerte y su punto débil. Los datos disponibles pueden ser insuficientes para en entrenamiento y la dimensionalidad de las entradas puede ser demasiado grande.
Por esta razón, para una buena predicción debemos usar los neuropaquetes con gran funcionalidad.
Preparación de los datos
Para comenzar la operación debemos preparar los datos. La corrección de este trabajo supone el 80 % del éxito.
El gurú de las redes neuronales dice que como entradas y salidas no debemos usar los valores de las cotizaciones Ct. Los que es realmente importante son los cambios en las cotizaciones. Aunque la amplitud de estos cambios es una regla menor que las propias cotizaciones, hay una fuerte correlación entre los valores sucesivos de las cotizaciones: el valor de una cotización más probable en el siguiente momento será igual a su valor previo C(t+1)=C(t)+delta(C)=C(t).
Mientras tanto, para una mayor calidad del entrenamiento, debemos buscar la independencia estadística de las entradas, es decir, evitar dichas correlaciones. Por ello, es lógico elegir como entradas las variables con valores estadísticos más independientes, por ejemplo, los cambios de cotización delta(C) o el logaritmo del incremento relativo log(C(t)/C(t+1)).
La última elección es mejor para las series de tiempo largas, cuando la influencia de la inflación es sensible. En tal caso, las simples diferencias en las partes de las series tendrán la amplitud suficiente, ya que están valoradas realmente en unidades distintas. Y al contrario, las relaciones de cotizaciones sucesivas no dependen de las unidades de medición y serán de la misma escala con independencia del cambio inflacionario de las unidades de medición. Como resultado, la gran estacionaridad de las series permite usar para el entrenamiento grandes historiales, proporcionando de este modo un mejor entrenamiento.
La desventaja de la inmersión en el espacio del retraso es la "vista" restringida de la red. Por el contrario, el análisis técnico no establece una ventana en el pasado, y a veces usa valores de series distantes. Por ejemplo, los valores de las series máximos y mínimos, incluso en el pasado relativamente remoto se dice que tienen un gran efecto sobre la psicología de los operadores y por tanto deben ser valorados en la predicción. Una ventana de inmersión en el espacio del retraso que no sea lo suficientemente amplia no es capaz de proporcionar dicha información, lo que naturalmente reduce la eficiencia de la predicción. Por otro lado, al ampliarse la ventana hasta dichas dimensiones, cuando incluye valores de las series más extremos, incrementa la dimensionalidad de la red, lo que origina una peor precisión en la predicción de la neurored.
La salida de esta situación aparentemente insalvable son los métodos alternativos de codificación del comportamiento pasado de las series. Instintivamente está claro que cuanto más nos alejemos en el tiempo en el historial de las series, menos detalles de su comportamiento influyen en el resultado de la predicción. Se basa en la psicología de la percepción subjetiva del pasado que tienen los operadores, que en realizad crean el futuro. Por tanto, necesitamos encontrar la presentación de la dinámica de las series que tendría una precisión selectiva: cuanto más lejos en el tiempo, menos detalles, aunque preservamos la forma general de la curva.
Una herramienta bastante prometedora puede ser la descomposición de ondulaciones. En términos de la capacidad de informar, es igual a la inmersión en el retraso, pero acepta más fácilmente la compresión de dichos datos, que describe el pasado con precisión selectiva.
Elección del software
Hay distintos tipos de software cuya finalidad es trabajar con las redes neuronales. Algunos de ellos son más o menos universales y otros están altamente especializados. Esta es una lista breve de algunos programas:
1. Matlab es un laboratorio de escritorio para los cálculos matemáticos, el diseño de circuitos eléctricos y el modelado de sistemas complejos. Posee un lenguaje de programación integrado y un gran conjunto de herramientas para las redes neuronales: Anfis Editor (interfaz de educación, creación, formación y gráfica), interfaz de comandos para programar redes, nnTool: para una configuración más precisa de una red.
2. Statistica es un potente software para el análisis de datos y la búsqueda de regularidades estadísticas. En este paquete, el trabajo con neuroredes se presenta en el bloque STATISTICA Neural Networks (abreviado, ST Neural Networks, paquete de neurored de la empresa StatSoft) que es una versión de todo el conjunto de métodos para neuroredes del análisis de datos.
3. BrainMaker tiene por finalidad la resolución de tareas, que no tienen métodos ni algoritmos formales, con datos de entrada incompletos, con ruido y contradictorios. Para dichas tareas hacemos referencia a los intercambios en el mercado y la predicción financiera, el modelado de situaciones de crisis, el reconocimiento de patrones y otros.
4. NeuroShell Day Trader es un sistema de neurored que cumple los requisitos específicos de los operadores y es bastante fácil de usar. Este programa está altamente especializado y está destinado al trading, aunque en realidad se parece mucho a una caja negra (blackbox).
5. Otros programas son menos populares.
Para las tareas primarias, Matlab es bastante adecuado. Intentaremos definir la idoneidad de una neurored para la predicción en Forex.
La información sobre MatLab puede encontrarse en la wikipedia en https://en.wikipedia.org/wiki/MATLAB
En el sitio web http://www.mathworks.com/hay una gran cantidad de información sobre el programa. Puede comprar el programa en http://www.mathworks.com/store/
Experimento
Preparación de los datos
Los datos se adquieren fácilmente usando herramientas estándar de MetaTrader:
Servicio -> archivo Quotes -> Exportar
Como resultado obtenemos un archivo *.csv, que es la materia prima para la preparación de los datos. Para transformar el archivo en uno adecuado para el uso como archivo *.xls, importamos los datos del archivo *.csv. Para esta finalizad, en Excel hacemos lo siguiente:
Datos -> Importar datos externos -> Importar datos e indicar el archivo primario preparado. En el maestro de importación, todas las acciones necesarias se realizan en 3 pasos:
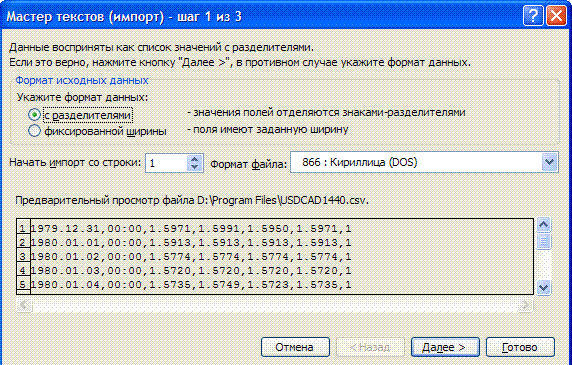
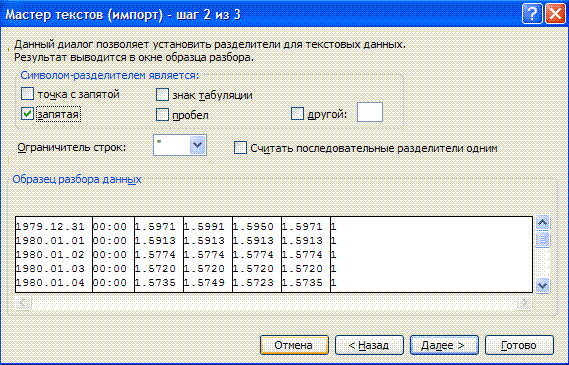
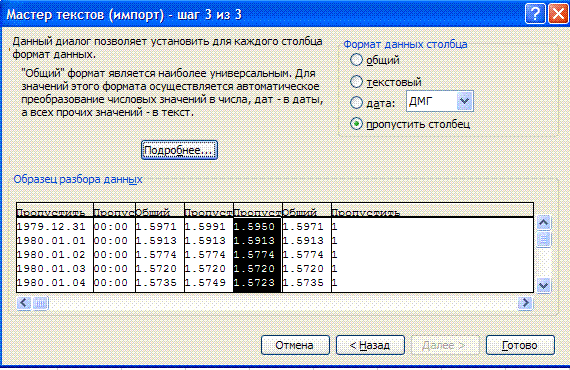
Un tercer paso sustituye el separador de enteros y la parte decimal por un punto, usando More...
Para aceptar los datos como números, no como strings, sustituimos el separador del entero y la parte decimal por un punto:
Servicio -> Parámetros -> Internacional -> Separador de enteros y parte decimal.
Las capturas de pantalla muestran el ejemplo de guardar, abrir y cerrar los precios, los demás datos todavía no son necesarios.
Ahora transformamos todos los datos de acuerdo con lo que queremos predecir. Vamos a predecir el precio de cierre del día siguiente sobre los cuatro anteriores (los datos se presentan en cinco columnas y los precios están en orden cronológico).
1,2605 |
1,263 |
1,2641 |
1,2574 |
1,2584 |
1,2666 |
1,263 |
1,2641 |
1,2574 |
1,2584 |
1,2666 |
1,2569 |
1,2641 |
1,2574 |
1,2584 |
1,2666 |
1,2569 |
1,2506 |
1,2574 |
1,2584 |
1,2666 |
1,2569 |
1,2506 |
1,2586 |
1,2584 |
1,2666 |
1,2569 |
1,2506 |
1,2586 |
1,2574 |
Gracias a las sencillas manipulaciones en Excel, los datos se preparan en un par de minutos. Adjunto a este artículo hay un ejemplo de un archivo con datos preparados.
Para que Matlab reconozca los archivos, los datos preparados deben guardarse en archivos *.txt o *.dat. Vamos a guardarlos como archivos *.txt. Luego, cada archivo debe ser dividido: para el entrenamiento (selección) de la red y su prueba (selección externa). Dichos datos euro.zip preparados inteligentemente son adecuados para una operación posterior.
Conocimiento de Matlab
Desde la línea de comandos, iniciamos el paquete ANFIS usando el comando anfisedit. El editor tiene cuatro barras: para los datos (Load data), para la generación de la red (Generate FIS), para el entrenamiento (Train FIS) y para su prueba (Test FIS). La barra superior se usa para previsualizar la estructura de la neurored (ANFIS Info).
Aquí puede encontrar más información sobre el funcionamiento del paquete:
http://www.mathworks.com/access/helpdesk/help/toolbox/fuzzy/
Para iniciar los datos de carga de la operación preparados en las etapas anteriores: cronometramos Load Data e indicamos el archivo con los datos de la selección. Luego creamos una red neuronal haciendo clic en Generate FIS.
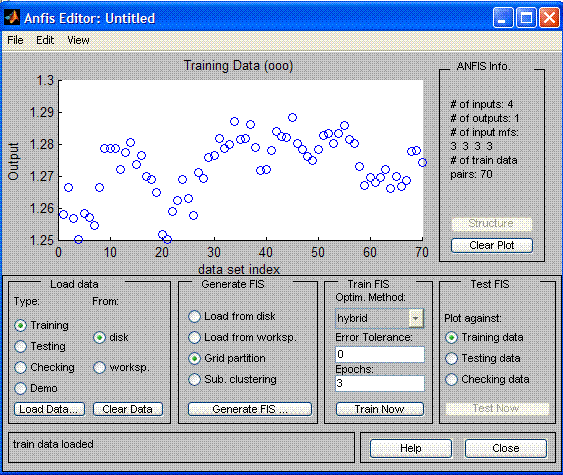
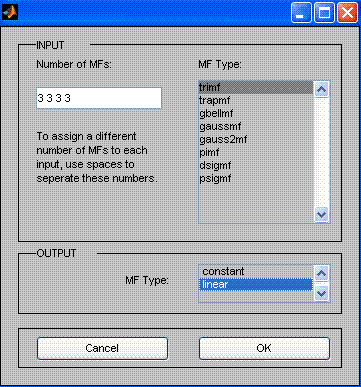
Para cada variable de entrada establecemos 3 variables lingüistas con una función de referencia triangular. Establecemos una función lineal como función de referencia de una función de salida.
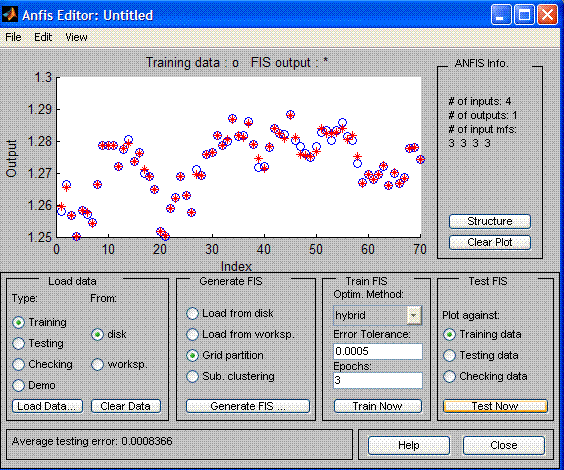
Para el entrenamiento de la neurored, el paquete AnfisEdit incluye 2 algoritmos de entrenamiento: propagación hacia atrás y el híbrido. Con un entrenamiento híbrido la red es entrenada en dos o tres ejecuciones. En una selección de entrenamiento (60 valores) después del entrenamiento, la predicción por la red difiere de la real en varios puntos.
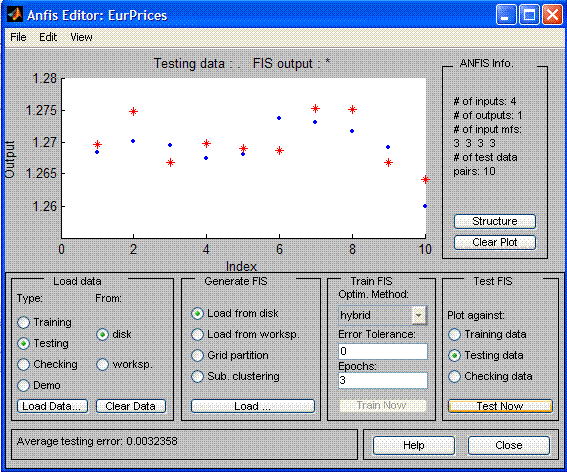
Pero lo que necesitamos predecir es el futuro. Como datos de selección exteriores tomamos los siguientes 9 días después de los datos de selección interiores. En los datos de selección exteriores, el error medio cuadrático tuvo 32 puntos, lo que es, por supuesto, inaceptable en el trading real, pero muestra que la dirección de la neurored puede desarrollarse más: el juego debe valer una vela.
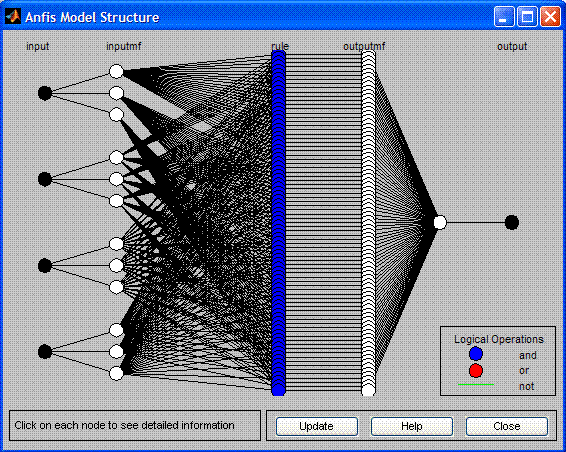
El resultado de nuestro trabajo es una red neuronal híbrida multicapas que puede predecir valores absolutos del precio en el futuro próximo. Cambia cardinalmente en su arquitectura y finalidad desde una red neuronal monocapa, descrita por Y. Reshetov en este artículo /ru/articles/1447 y realizada como un asesor experto https://www.mql5.com/ru/code/10289.
Hemos logrado recibir predicciones más o menos tolerables sobre las cotizaciones, aunque los expertos en redes neuronales recomiendan encarecidamente no hacer esto. Para ver la neurored resultante hacemos clic en Structure. En el archivo adjunto neuro.zip se encuentra una red neuronal entrenada.
Conclusión
Las redes neuronales son una herramienta muy poderosa para trabajar en los mercados financieros, pero aprender esta tecnología requiere tiempo y esfuerzo, no menos que aprender el análisis técnico.
Una ventaja de las redes neuronales es su objetividad en la toma de decisiones, mientras que su desventaja es que las decisiones se toman realmente por una caja negra.
El principal problema que puede producirse durante el trabajo con esta tecnología está relacionado con el correcto procesamiento previo de los datos. Esta etapa juega un papel crucial en la predicción de datos y muchos intentos fallidos de trabajar con las redes neuronales están relacionados con esta etapa.
Para aprender a usar correctamente las redes uno debe experimentar mucho: pero el juego merece la pena. Si los inversores institucionales usan esta herramienta, los operadores habituales pueden también intentar tener éxito usando las redes neuronales entrenadas, ya que cualquier cosa puede ser introducida como información en la red: desde indicadores y precios, hasta señales del análisis fundamental.
Referencias bibliográficas
1. Nejrokompyuting i ego primenenie v nauke i biznese. A. Ezhov, S. Shumskij. 1998