Der Algorithmus CatBoost von Yandex für das maschinelle Lernen, Kenntnisse von Python- oder R sind nicht erforderlich
Aleksey Vyazmikin | 4 Dezember, 2020
Vorwort
Dieser Artikel befasst sich mit der Erstellung von Modellen zur Beschreibung von Marktmustern mit einem begrenzten Satz von Variablen und der Hypothese über die Verhaltensmuster unter Verwendung des maschinellen Lernalgorithmus CatBoost von Yandex. Um das Modell zu entwickeln, benötigen Sie keine Kenntnisse von Python- oder R. Es reichen grundlegende MQL5-Kenntnisse aus — das ist genau mein Niveau. Daher hoffe ich, dass der Artikel als gutes Tutorial für ein breites Publikum hilft, um diejenigen zu unterstützen, die daran interessiert sind, Fähigkeiten des maschinellen Lernens zu evaluieren und in ihre Programme zu implementieren. Der Artikel liefert wenig akademisches Wissen. Wenn Sie zusätzliche Informationen benötigen, lesen Sie bitte die Artikelserie von Vladimir Perervenko.
Der Unterschied zwischen dem klassischen Ansatz und dem maschinellen Lernen im Handel
Das Konzept einer Handelsstrategie ist wohl jedem Händler vertraut. Darüber hinaus ist die Handelsautomatisierung ein wichtiger Aspekt für diejenigen, die das Glück haben, das Produkt von MetaQuotes zu nutzen. Wenn wir die Handelsumgebung im Code eliminieren, implizieren die meisten Strategien hauptsächlich die Auswahl von Ungleichheiten (meistens zwischen dem Preis und einem Indikator auf dem Chart) oder verwenden Indikatorwerte und ihre Bereiche, um Einstiegs- (Positionseröffnung) und Ausstiegsentscheidungen zu treffen.
Fast jeder Entwickler von Handelsstrategien hat immer wieder Einsichten erlangt, die dazu führen, dass mehr Handelsbedingungen und neue Ungleichheiten hinzukommen. Jede solche Hinzufügung bewirkt eine Veränderung der finanziellen Ergebnisse in einem bestimmten Zeitintervall. Aber ein anderes Zeitintervall, ein anderer Zeitrahmen oder ein anderes Handelsinstrument kann enttäuschende Ergebnisse zeigen — das Handelssystem ist nicht mehr effizient und der Händler muss nach neuen Mustern und Bedingungen suchen. Darüber hinaus verringert das Hinzufügen jeder neuen Bedingung die Anzahl der Handelsgeschäfte.
Dem Suchprozess folgt in der Regel die Optimierung von Ungleichheiten, die für Handelsentscheidungen herangezogen werden. Der Optimierungsprozess überprüft eine Reihe von Parametern, die oft über die ursprünglichen Datenwerte hinausgehen. Ein anderer Fall ist, wenn die durch die Parameteroptimierung erzeugten Ungleichheitswerte so selten auftreten, dass sie eher als statistische Abweichung denn als gefundenes Muster betrachtet werden können, obwohl sie die Gleichgewichtskurve oder jeden anderen optimierbaren Parameter verbessern könnten. Infolgedessen führt die Optimierung zu einer Überanpassung der in der Handelsstrategie implementierten heuristischen Idee an die verfügbaren Marktdaten. Ein solcher Ansatz ist im Hinblick auf die Rechenressourcen, die für die Suche nach einer optimalen Lösung aufgewendet werden, nicht effizient, wenn die Strategie die Verwendung einer großen Anzahl von Variablen und deren Werten impliziert.
Die Methoden des maschinellen Lernens können die Parameteroptimierungs- und Mustersuchprozesse beschleunigen, indem Ungleichheitsregeln generiert werden, die nur diejenigen Parameterwerte überprüfen, die auf den analysierten Daten vorhanden waren. Verschiedene Modellerstellungsmethoden verwenden unterschiedliche Ansätze. Im Allgemeinen geht es jedoch darum, die Lösungssuche auf die für das Training verfügbaren Daten zu beschränken. Anstatt Ungleichheiten zu erzeugen, die für die Handelsentscheidungslogik verantwortlich sind, liefert das maschinelle Lernen nur die Werte von Variablen, die Informationen über den Preis und die Faktoren, die die Preisbildung beeinflussen, enthalten. Solche Daten werden als Merkmale (oder Prädiktoren) bezeichnet.
Merkmale müssen das Ergebnis beeinflussen, das wir durch ihre Abfrage erzielen wollen. Das Ergebnis wird normalerweise als numerischer Wert ausgewiesen: Dies kann eine Klassennummer der Klassifizierung oder ein Sollwert für die Regression sein. Ein solches Ergebnis ist die Zielvariable. Einige Trainingsmethoden haben keine Zielvariable, wie z.B. Clustering-Methoden, aber wir werden in diesem Artikel nicht auf sie eingehen.
Wir brauchen also Prädiktoren und Zielvariablen.
Prädiktoren
Für Prädiktoren können Sie die Zeit, den OHLC-Preis eines Handelsinstruments und seiner Derivate, also verschiedene Indikatoren, verwenden. Es ist auch möglich, andere Prädiktoren zu verwenden, wie z.B. Wirtschaftsindikatoren, Handelsvolumen, Open Interest, Orderbuchmuster, Optionsstreiks Griechenlands und andere Datenquellen, die den Markt beeinflussen. Ich glaube, dass das Modell zusätzlich zu den Informationen, die sich bis zum aktuellen Moment gebildet haben, auch die Informationen erhalten sollte, die die Bewegung beschreiben, die zum aktuellen Moment geführt hat. Streng genommen sollten die Prädiktoren Informationen über die Preisbewegung über einen bestimmten Zeitraum liefern.
Ich lege einige Typen von Prädiktoren fest, die beschreiben:
- Signifikante Niveaus, die sein können:
- Horizontal (wie z.B. ein Eröffnungspreis einer Handelssitzung)
- Linear (zum Beispiel ein Regressionskanal)
- Gebrochen (berechnet durch eine nicht-lineare Funktion, z.B. gleitende Durchschnitte)
- Preis und Niveau Position:
- In einem festen Bereich in Punkten
- In einem festen Bereich als Prozentsatz:
- Bezogen auf den Eröffnungskurs des Tages oder ein Niveau
- Relativ zum Volatilitätsniveau
- Relativ zu Trendsegmenten verschiedener TFs (Zeitrahmen)
- Beschreibungen von Preisschwankungen (Volatilität)
- Informationen über den Zeitpunkt eines Ereignisses:
- Anzahl der Balken, die seit dem Beginn des signifikanten Ereignisses verstrichen sind (ab dem aktuellen Balken oder dem Beginn einer anderen Periode, z.B. dem Tag)
- Die Anzahl der Balken, die seit dem Ende des signifikanten Ereignisses verstrichen sind (ab dem aktuellen Balken oder dem Beginn einer anderen Periode, z.B. dem Tag)
- Die Anzahl der Balken, die seit Beginn und Ende des Ereignisses verstrichen sind, was die Ereignisdauer anzeigt
- Aktuelle Zeit als Stundenzahl, Wochentag, Dekaden- oder Monatsnummer oder andere
- Informationen über die Ereignisdynamik:
- Die Anzahl der Schnittpunkte signifikanter Pegel (dies schließt die Berechnung unter Berücksichtigung der Dämpfung/Wiederholungsfrequenz ein)
- Höchst-/Mindestpreis zum Zeitpunkt des ersten/letzten Ereignisses (der relative Preis)
- Ereignisgeschwindigkeit in Punkten pro Zeiteinheit
- Konvertierung von OHLC-Daten in andere Koordinatenebenen
- Indikatorwerte von Oszillatoren.
Für Prädiktoren können wir Informationen aus verschiedenen Zeitrahmen und Handelsinstrumenten entnehmen, die sich auf denjenigen beziehen, der für den Handel verwendet werden soll. Natürlich gibt es viel mehr mögliche Methoden, um Informationen zu liefern. Die einzige Empfehlung besteht darin, genügend Daten bereitzustellen, um die Hauptpreisdynamik des Handelsinstruments zu reproduzieren. Nachdem Sie einmal Prädiktoren vorbereitet haben, können Sie diese für verschiedene Zwecke weiter verwenden. Dadurch wird die Suche nach einem Modell, das nach den grundlegenden Bedingungen der Handelsstrategie funktioniert, erheblich vereinfacht.
Das Ziel
In diesem Artikel verwenden wir eine binäre Klassifikation, d. h. 0 und 1. Diese Auswahl ergibt sich aus einer Einschränkung, auf die später noch eingegangen wird. Was kann also durch Null und Eins repräsentiert werden? Ich habe zwei Varianten:
- die erste Variante: "1" — eine Position eröffnen (oder eine andere Aktion ausführen) und "0" — keine Position eröffnen (oder keine andere Aktion ausführen);
- die zweite Variante: "1" — eine Kaufposition eröffnen (erste Aktion) und "0" — eine Verkaufsposition eröffnen (zweite Aktion).
Um die Zielvariable eines Signals zu erzeugen, können wir einfache Grundstrategien verwenden, vorausgesetzt, sie erzeugen eine ausreichende Anzahl von Signalen für das maschinelle Lernen:
- Eine Position eröffnen, wenn ein Kauf- oder Verkaufspreisniveau überschritten wird (jeder Indikator kann als Niveau dienen);
- Öffnen einer Position auf dem N-Balken vom Beginn der Stunde an oder Ignorieren der Eröffnung, abhängig von der Position des Preises im Verhältnis zum Eröffnungskurs des aktuellen Tages.
Versuchen Sie, eine grundlegende Strategie zu finden, die die Generierung einer ungefähr ähnlichen Anzahl von Null und Einsen ermöglicht, da dies ein besseres Lernen erleichtert.
Software für maschinelles Lernen
Wir werden maschinelles Lernen mit der Software CatBoost durchführen, die über diesem Link heruntergeladen werden kann. Dieser Artikel zielt darauf ab, eine unabhängige Version zu erstellen, die keine andere Programmiersprache erfordert, und dafür brauchen Sie nur die neueste Version der Exe-Datei herunterzuladen, z.B. catboost-0.24.1.exe.
CatBoost ist ein Open-Source-Algorithmus für maschinelles Lernen von der bekannten Firma Yandex. Wir können also relevanten Produktsupport, Verbesserungen und Fehlerbehebungen erwarten.
Sie können die Präsentation von Yandex hier ansehen (aktivieren Sie englische Untertitel, da die Präsentation auf Russisch ist).
Kurz gesagt, CatBoost baut ein Ensemble von Entscheidungsbäumen so auf, dass jeder nachfolgende Baum die Werte der gesamten probabilistischen Antwort aller vorherigen Bäume verbessert. Dies wird als Gradientenverstärkung bezeichnet.
Datenvorbereitung für das maschinelle Lernen
Die Daten, die Prädiktoren und Zielvariable enthalten, werden als Stichprobe bezeichnet. Es handelt sich um ein Datenfeld, das eine Aufzählung von Prädiktoren als Spalten enthält, in denen jede Zeile den Messzeitpunkt darstellt, der die Prädiktorwerte zu diesem Zeitpunkt anzeigt. Die in der Zeichenfolge aufgezeichneten Messungen können in bestimmten Zeitintervallen erhalten werden oder verschiedene Objekte, z.B. Bilder, darstellen. Normalerweise hat die Datei ein CSV-Format, das ein bedingtes Trennzeichen für Spaltenwerte und Kopfzeilen (optional) verwendet.
In unserem Beispiel verwenden wir die folgenden Prädiktoren:
- Zeit / Stunden / Stundenteile / Wochentag
- Die relative Position der Balken
- Oszillatoren
Die Zielvariable ist ein Signal durch einen Schnittpunkt eines MA, das beim nächsten Balken unangetastet bleibt. Wenn der Preis über dem MA liegt, dann Kaufen. Liegt der Preis unter dem MA, dann Verkaufen. Jedes Mal, wenn ein Signal eintrifft, sollte eine bestehende Position geschlossen werden. Die Zielvariable zeigt an, ob eine Position eröffnet werden soll oder nicht.
Ich empfehle nicht die Verwendung eines Skripts zur Generierung der Zielvariablen und der Prädiktorvariablen. Verwenden wir stattdessen einen Expert Advisor, der das Erkennen von logischen Fehlern im Code bei der Generierung einer Stichprobe sowie eine detaillierte Simulation des Eintreffens der Daten ermöglicht - dies wird dem Eintreffen der Daten im realen Handel ähnlich sein. Darüber hinaus werden wir in der Lage sein, unterschiedliche Eröffnungszeiten verschiedener Instrumente zu berücksichtigen, wenn die Zielvariable mit unterschiedlichen Symbolen arbeitet, sowie die Verzögerung beim Datenempfang und bei der Datenverarbeitung zu berücksichtigen, um zu verhindern, dass der Algorithmus in die Zukunft blickt, um Indikatorneuzeichnungen und eine für das Training ungeeignete Logik abzufangen. Infolgedessen werden die Prädiktoren auf dem Balken in Echtzeit berechnet, wenn das Modell in der Praxis angewendet wird.
Einige algorithmische Händler, insbesondere diejenigen, die maschinelles Lernen verwenden, geben an, dass Standardindikatoren meist nutzlos sind, da sie verzögert und vom Preis abgeleitet werden, d.h. sie liefern keine neuen Informationen, während Neuronale Netze jeden Indikator erstellen können. Die Möglichkeiten von Neuronalen Netzen sind in der Tat groß, aber sie erfordern oft eine Rechenleistung, die den meisten gewöhnlichen Händlern nicht zur Verfügung steht. Außerdem erfordert es Zeit, solche neuronalen Netze zu erlernen. Auf Entscheidungsbäumen basierende maschinelle Lernmethoden können bei der Erstellung neuer mathematischer Einheiten nicht mit neuronalen Netzen konkurrieren, da sie die Eingabedaten nicht transformieren. Sie gelten jedoch als effizienter als neuronale Netze, wenn es notwendig ist, direkte Abhängigkeiten zu identifizieren, insbesondere in großen und heterogenen Datenarrays. Tatsächlich besteht der Zweck von Neuronalen Netzen darin, neue Muster zu erzeugen, d.h. Parameter, die den Markt beschreiben. Modelle von Entscheidungsbäumen zielen auf die Identifizierung von Mustern aus den Mengen solcher Muster ab. Indem wir Standardindikatoren vom Terminal als Prädiktor verwenden, nehmen wir das Muster, das von Tausenden von Händlern in verschiedenen Börsen- und OTC-Märkten in verschiedenen Ländern verwendet wird. Daher können wir davon ausgehen, dass wir in der Lage sein werden, eine entgegengesetzte Abhängigkeit des Händlerverhaltens von Indikatorwerten zu identifizieren, die sich schließlich auf das Handelsinstrument auswirkt. Ich habe bisher noch keine Oszillatoren verwendet, daher bin ich selber interessiert, das Ergebnis zu sehen.
Die folgenden Indikatoren aus der Standardterminallieferung werden verwendet:
- Accelerator Oszillator
- Average Directional Movement Index (ADX)
- Average Directional Movement Index (ADX) von Welles Wilder
- Average True Range
- Bears Power
- Bulls Power
- Commodity Channel Index
- Chaikin Oszillator
- DeMarker
- Force Index
- Gator
- Market Facilitation Index
- Momentum
- Money Flow Index
- Gleitender Durchschnitt von Oszillatoren
- Moving Averages Convergence/Divergence (MACD)
- RSI (Relative Strength Index)
- Relative Vigor Index
- Standardabweichung
- Stochastik Oszillator
- Triple Exponential Moving Averages Oscillator (dreifacher EMA)
- Williams' Percent Range
- Variable Index Dynamic Average
- Volumen
Die Indikatoren werden für alle in MetaTrader 5 verfügbaren Zeitrahmen bis hin zum Tagesrahmen berechnet.
Als ich diesen Artikel schrieb, fand ich heraus, dass die Werte der folgenden Indikatoren stark vom Datum des Testbeginns im Terminal abhängen, deshalb habe ich beschlossen, sie auszuschließen. Es ist möglich, die Differenz zwischen den Werten auf verschiedenen Balken für diese Indikatoren zu verwenden, aber das geht über diesen Artikel hinaus.
Die Liste der ausgeschlossenen Indikatoren:
- Awesome Oszillator
- On Balance Volume
- Accumulation/Distribution
Um mit CSV-Tabellen zu arbeiten, werden wir die wunderbare Bibliothek csv_fast.mqh von Aliaksandr Hryshyn verwenden. Die Eigenschaften der Bibliothek:
- Tabellen erstellen, aus einer Datei lesen und in einer Datei speichern.
- Lesen und Schreiben von Informationen in jede Tabellenzelle auf der Grundlage der Zellenadresse.
- Tabellenspalten können verschiedene Datentypen speichern, was den RAM-Verbrauch senkt.
- Tabellenabschnitte können vollständig von den angegebenen Adressen an die angegebene Adresse einer anderen Tabelle kopiert werden.
- Bietet Filterung nach jeder Tabellenspalte.
- Bietet eine mehrstufige Sortierung in absteigender und aufsteigender Reihenfolge, entsprechend den in den Spaltenzellen angegebenen Werten.
- Erlaubt die Neuindizierung und das Ausblenden von Spalten.
- Es gibt noch weitere nützliche und nutzerfreundliche Funktionen.
Komponenten des Expert Advisors
Grundlegende Strategie:
Ich entschied mich für eine Strategie mit einfachen Bedingungen als Basisstrategie, die das Signal erzeugt. Demnach sollte der Markteintritt erfolgen, wenn die folgenden Bedingungen erfüllt sind:
- Der Preis hat den gleitenden Durchschnittspreis überschritten.
- Nachdem Bedingung 1 erfüllt ist, hat der Preis zum ersten Mal den gekreuzten MA auf dem vorherigen Balken nicht berührt.
Dies war meine erste Strategie, die ich Anfang der 00er Jahre erstellt habe. Es ist eine einfache Strategie, die zur Trendklasse gehört. Sie zeigt gute Ergebnisse bei entsprechenden Teilen der Handelsgeschichte. Lassen Sie uns versuchen, die Zahl der Falscheingaben in flachen Bereichen mit Hilfe des maschinellen Lernens zu reduzieren.
Der Signalgenerator ist wie folgt:
//+-----------------------------------------------------------------+ //| Returns a buy or Sell signal - basic strategy | //+-----------------------------------------------------------------+ bool Signal() { // Reset position opening blocking flag SellPrIMA=false; // Open a pending sell order BuyPrIMA=false; // Open a pending buy order SellNow=false; // Open a market sell order BuyNow=false; // Open a market buy order bool Signal=false;// Function operation result int BarN=0; // The number of bars on which MA is not touched if(iOpen(Symbol(),Signal_MA_TF,0)>MA_Signal(0) && iLow(Symbol(),Signal_MA_TF,1)>MA_Signal(1)) { for(int i=2; i<100; i++) { if(iLow(Symbol(),Signal_MA_TF,i)>MA_Signal(i))break;// Signal has already been processed on this cycle if(iClose(Symbol(),Signal_MA_TF,i+1)<MA_Signal(i+1) && iClose(Symbol(),Signal_MA_TF,i)>=MA_Signal(i)) { for(int x=i+1; x<100; x++) { if(iLow(Symbol(),Signal_MA_TF,x)>MA_Signal(x))break;// Signal has already been processed on this cycle if(iHigh(Symbol(),Signal_MA_TF,x)<MA_Signal(x)) { BarN=x; BuyNow=true; break; } } } } } if(iOpen(Symbol(),Signal_MA_TF,0)<MA_Signal(0) && iHigh(Symbol(),Signal_MA_TF,1)<MA_Signal(1)) { for(int i=2; i<100; i++) { if(iHigh(Symbol(),Signal_MA_TF,i)<MA_Signal(i))break;// Signal has already been processed on this cycle if(iClose(Symbol(),Signal_MA_TF,i+1)>MA_Signal(i+1) && iClose(Symbol(),Signal_MA_TF,i)<=MA_Signal(i)) { for(int x=i+1; x<100; x++) { if(iHigh(Symbol(),Signal_MA_TF,x)<MA_Signal(x))break;// Signal has already been processed on this cycle if(iLow(Symbol(),Signal_MA_TF,x)>MA_Signal(x)) { BarN=x; SellNow=true; break; } } } } } if(BuyNow==true || SellNow==true)Signal=true; return Signal; }
Erhalt von Prädiktoren:
Die Prädiktoren werden mit Hilfe von Funktionen ermittelt (ihr Code ist unten angehängt). Ich werde Ihnen jedoch zeigen, wie dies für eine große Anzahl von Indikatoren leicht möglich ist. Wir werden Indikatorwerte in drei Punkten verwenden: den ersten und zweiten geformten Balken, der es ermöglicht, das Niveau des Indikators zu bestimmen, und einen Balken mit einer Verschiebung von 15 - dies ermöglicht es, die Bewegungsdynamik des Indikators zu verstehen. Dies ist natürlich eine vereinfachte Art und Weise der Informationsbeschaffung und kann erheblich erweitert werden.
Alle Prädiktoren werden in eine Tabelle geschrieben, die im Arbeitsspeicher des Computers gebildet wird. Die Tabelle hat eine Zeile; sie wird später als numerischer Eingangsdatenvektor für den CatBoost-Modellinterpreter verwendet.
#include "CSV fast.mqh"; // Class for working with tables CSV *csv_CB=new CSV(); // Create a table class instance, in which current predictor values will be stored //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { CB_Tabl();// Creating a table with predictors return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Create a table with predictors | //+------------------------------------------------------------------+ void CB_Tabl() { //--- Columns for oscillators Size_arr_Buf_OSC=ArraySize(arr_Buf_OSC); Size_arr_Name_OSC=ArraySize(arr_Name_OSC); Size_TF_OSC=ArraySize(arr_TF_OSC); for(int n=0; n<Size_arr_Buf_OSC; n++)SummBuf_OSC=SummBuf_OSC+arr_Buf_OSC[n]; Size_OSC=3*Size_TF_OSC*SummBuf_OSC; for(int S=0; S<3; S++)// Loop by the number of shifts { string Shift="0"; if(S==0)Shift="1"; if(S==1)Shift="2"; if(S==2)Shift="15"; for(int T=0; T<Size_TF_OSC; T++)// Loop by the number of timeframes { for(int o=0; o<Size_arr_Name_OSC; o++)// Loop by the number of indicators { for(int b=0; b<arr_Buf_OSC[o]; b++)// Loop by the number of indicator buffers { name_P=arr_Name_OSC[o]+"_B"+IntegerToString(b,0)+"_S"+Shift+"_"+arr_TF_OSC[T]; csv_CB.Add_column(dt_double,name_P);// Add a new column with a name to identify a predictor } } } } } //+------------------------------------------------------------------+ //--- Call predictor calculation //+------------------------------------------------------------------+ void Pred_Calc() { //--- Get information from oscillator indicators double arr_OSC[]; iOSC_Calc(arr_OSC); for(int p=0; p<Size_OSC; p++) { csv_CB.Set_value(0,s(),arr_OSC[p],false); } } //+------------------------------------------------------------------+ //| Get values of oscillator indicators | //+------------------------------------------------------------------+ void iOSC_Calc(double &arr_OSC[]) { ArrayResize(arr_OSC,Size_OSC); int n=0;// Indicator handle index int x=0;// Total number of iterations for(int S=0; S<3; S++)// Loop by the number of shifts { n=0; int Shift=0; if(S==0)Shift=1; if(S==1)Shift=2; if(S==2)Shift=15; for(int T=0; T<Size_TF_OSC; T++)// Loop by the number of timeframes { for(int o=0; o<Size_arr_Name_OSC; o++)// Loop by the number of indicators { for(int b=0; b<arr_Buf_OSC[o]; b++)// Loop by the number of indicator buffers { arr_OSC[x++]=iOSC(n, b,Shift); } n++;// Mark shift to the next indicator handle for calculation } } } } //+------------------------------------------------------------------+ //| Get the value of the indicator buffer | //+------------------------------------------------------------------+ double iOSC(int OSC, int Bufer,int index) { double MA[1]= {0.0}; int handle_ind=arr_Handle[OSC];// Indicator handle ResetLastError(); if(CopyBuffer(handle_ind,0,index,1,MA)<0) { PrintFormat("Failed to copy data from the OSC indicator, error code %d",GetLastError()); return(0.0); } return (MA[0]); }
Akkumulation und Markierung von Proben:
Um eine Probe zu erstellen und zu speichern, werden wir Prädiktorwerte akkumulieren, indem wir sie aus der Tabelle csv_CB in die Tabelle csv_Arhiv kopieren.
Wir lesen das Datum des vorhergehenden Signals, bestimmen den Ein- und Ausstiegspreis des Handels und definieren das Ergebnis, nach dem das entsprechende Etikett vergeben wird: "1" — positiv, "0" — negativ. Wir markieren auch die Art des durch das Signal durchgeführten Geschäfts. Dies wird weiter dazu beitragen, ein Saldendiagramm zu erstellen: "1" - Kauf und "-1" - Verkauf. Lassen Sie uns hier auch das finanzielle Ergebnis einer Handelsoperation berechnen. Für das finanzielle Ergebnis werden getrennte Spalten mit Kauf- und Verkaufsergebnissen verwendet: dies ist praktisch, wenn die Grundstrategie schwieriger ist oder Elemente des Positionsmanagements enthält, die das Ergebnis beeinflussen können.
//+-----------------------------------------------------------------+ //| The function copies predictors to archive | //+-----------------------------------------------------------------+ void Copy_Arhiv() { int Strok_Arhiv=csv_Arhiv.Get_lines_count();// Number of rows in the table int Stroka_Load=0;// Starting row in the source table int Stolb_Load=1;// Starting column in the source table int Stroka_Save=0;// Starting row to write in the table int Stolb_Save=1;// Starting column to write in the table int TotalCopy_Strok=-1;// Number of rows to copy from the source. -1 copy to the last row int TotalCopy_Stolb=-1;// Number of columns to copy from the source, if -1 copy to the last column Stroka_Save=Strok_Arhiv;// Copy the last row csv_Arhiv.Copy_from(csv_CB,Stroka_Load,Stolb_Load,TotalCopy_Strok,TotalCopy_Stolb,Stroka_Save,Stolb_Save,false,false,false);// Copying function //--- Calculate the financial result and set the target label, if it is not the first market entry int Stolb_Time=csv_Arhiv.Get_column_position("Time",false);// Find out the index of the "Time" column int Vektor_P=0;// Specify entry direction: "+1" - buy, "-1" - sell if(BuyNow==true)Vektor_P=1;// Buy entry else Vektor_P=-1;// Sell entry csv_Arhiv.Set_value(Strok_Arhiv,Stolb_Time+1,Vektor_P,false); if(Strok_Arhiv>0) { int Stolb_Target_P=csv_Arhiv.Get_column_position("Target_P",false);// Find out the index of the "Time" column int Load_Vektor_P=csv_Arhiv.Get_int(Strok_Arhiv-1,Stolb_Target_P,false);// Find out the previous operation type datetime Load_Data_Start=StringToTime(csv_Arhiv.Get_string(Strok_Arhiv-1,Stolb_Time,false));// Read the position opening date datetime Load_Data_Stop=StringToTime(csv_Arhiv.Get_string(Strok_Arhiv,Stolb_Time,false));// Read the position closing date double F_Rez_Buy=0.0;// Financial result in case of a buy operation double F_Rez_Sell=0.0;// Financial result in case of a sell operation double P_Open=0.0;// Position open price double P_Close=0.0;// Position close price int Metka=0;// Label for target variable P_Open=iOpen(Symbol(),Signal_MA_TF,iBarShift(Symbol(),Signal_MA_TF,Load_Data_Start,false)); P_Close=iOpen(Symbol(),Signal_MA_TF,iBarShift(Symbol(),Signal_MA_TF,Load_Data_Stop,false)); F_Rez_Buy=P_Close-P_Open;// Previous entry was buying F_Rez_Sell=P_Open-P_Close;// Previous entry was selling if((F_Rez_Buy-comission*Point()>0 && Load_Vektor_P>0) || (F_Rez_Sell-comission*Point()>0 && Load_Vektor_P<0))Metka=1; else Metka=0; csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+2,Metka,false);// Write label to a cell csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+3,F_Rez_Buy,false);// Write the financial result of a conditional buy operation to the cell csv_Arhiv.Set_value(Strok_Arhiv-1,Stolb_Time+4,F_Rez_Sell,false);// Write the financial result of a conditional sell operation to the cell csv_Arhiv.Set_value(Strok_Arhiv,Stolb_Time+2,-1,false);// Add a negative label to the labels to control labels } }
Wir verwenden das Modell:
Verwenden wir die Klasse "Catboost.mqh" von Aliaksandr Hryshyn, die von hier heruntergeladen werden kann, um die mit dem Modell CatBoost erhaltenen Daten zu interpretieren.
Ich habe die Tabelle "csv_Chek" für das Debugging hinzugefügt, in der der Wert des Modells CatBoost bei Bedarf gespeichert wird.
//+-----------------------------------------------------------------+ //| The function applies predictors in the CatBoost model | //+-----------------------------------------------------------------+ void Model_CB() { CB_Siganl=1; csv_CB.Get_array_from_row(0,1,Solb_Copy_CB,features); double model_result=Catboost::ApplyCatboostModel(features,TreeDepth,TreeSplits,BorderCounts,Borders,LeafValues); double result=Logistic(model_result); if (result<Porog || result>Pridel) { BuyNow=false; SellNow=false; CB_Siganl=0; } if(Use_Save_Result==true) { int str=csv_Chek.Add_line(); csv_Chek.Set_value(str,1,TimeToString(iTime(Symbol(),PERIOD_CURRENT,0),TIME_DATE|TIME_MINUTES)); csv_Chek.Set_value(str,2,result); } }
Speichern einer Auswahl in einer Datei:
Speichern der Tabelle am Ende des Testdurchlaufs, Angabe des Dezimaltrennzeichens als Komma
//+------------------------------------------------------------------+ // Function writing predictors to a file | //+------------------------------------------------------------------+ void Save_Pred_All() { //--- Save predictors to a file if(Save_Pred==true) { int Stolb_Target=csv_Arhiv.Get_column_position("Target_100",false);// Find out the index of the Target_100 column csv_Arhiv.Filter_rows_add(Stolb_Target,op_neq,-1,true);// Exclude lines with label "-1" in target variable csv_Arhiv.Filter_rows_apply(true);// Apply filter csv_Arhiv.decimal_separator=',';// Set a decimal separator string name=Symbol()+"CB_Save_Pred.csv";// File name csv_Arhiv.Write_to_file("Save_Pred\\"+name,true,true,true,true,false,5);// Save the file up to 5 characters } //--- Save the model values to a debug file if(Use_Save_Result==true) { csv_Chek.decimal_separator=',';// Set a decimal separator string name=Symbol()+"Chek.csv";// File name csv_Chek.Write_to_file("Save_Pred\\"+name,true,true,true,true,false,5);// Save file up to 5 decimal places } }
Nutzerdefinierte Qualitätsbewertung für Strategieeinstellungen:
Als Nächstes müssen wir geeignete Einstellungen für den Indikator finden, der vom Basismodell verwendet wird. Lassen Sie uns also einen Wert für den Strategietester berechnen, der das Minimum an Positionen bestimmt und den Prozentsatz der profitablen Positionen zurückgibt. Je mehr Objekte für das Training zur Verfügung stehen (Positionen), desto ausgewogener wird die Stichprobe sein (je näher der Prozentsatz der profitablen Positionen bei 50% liegt), desto besser wird das Training sein. Die nutzerdefinierte Variable wird in der nachstehenden Funktion berechnet.
//+------------------------------------------------------------------+ //| Custom variable calculating function | //+------------------------------------------------------------------+ double CustomPokazatelf(int VariantPokazatel) { double custom_Pokazatel=0.0; if(VariantPokazatel==1) { double Total_Tr=(double)TesterStatistics(STAT_TRADES); double Pr_Tr=(double)TesterStatistics(STAT_PROFIT_TRADES); if(Total_Tr>0 && Total_Tr>15000)custom_Pokazatel=Pr_Tr/Total_Tr*100.0; } return(custom_Pokazatel); }
Steuerung der Ausführungshäufigkeit des Hauptcodeteils:
Handelsentscheidungen sollten bei einer neuen Balken-Eröffnung generiert werden. Dies wird durch die folgende Funktion überprüft:
//+-----------------------------------------------------------------+ //| Returns TRUE if a new bar has appeared on the current TF | //+-----------------------------------------------------------------+ bool isNewBar() { datetime tm[]; static datetime prevBarTime=0; if(CopyTime(Symbol(),Signal_MA_TF,0,1,tm)<0) { Print("%s CopyTime error = %d",__FUNCTION__,GetLastError()); } else { if(prevBarTime!=tm[0]) { prevBarTime=tm[0]; return true; } return false; } return true; }
Handelsfunktionen:
Der Expert Advisor verwendet die Handelsklasse "cPoza6". Die Idee wurde von mir entwickelt, und die Hauptimplementierung wurde von Vasiliy Pushkaryov geliefert. Ich habe die Klasse an der Moskauer Börse getestet, aber ihr Konzept wurde nicht vollständig umgesetzt. Deshalb lade ich alle ein, es zu verbessern - nämlich, es braucht Funktionen für die Arbeit mit der Geschichte. Für diesen Artikel habe ich die Überprüfung der Kontoarten deaktiviert. Seien Sie also bitte vorsichtig. Die Klasse wurde ursprünglich für Netting-Konten entwickelt, aber ihre Funktionsweise wird für den Expert Advisor ausreichen, damit die Leser in diesem Artikel maschinelles Lernen studieren können.
Hier ist der Code des Expert Advisors ohne Funktionsbeschreibungen (der Klarheit halber).
Wenn wir einige Hilfsfunktionen nicht einbeziehen und obige Funktionsbeschreibungen entfernen, sieht der EA-Code in diesem Schritt wie folgt aus:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Check the correctness of model response interpretation values if(Porog>=Pridel || Pridel<=Porog)return(INIT_PARAMETERS_INCORRECT); if(Use_Pred_Calc==true) { if(Init_Pred()==INIT_FAILED)return(INIT_FAILED);// Initialize indicator handles CB_Tabl();// Creating a table with predictors Solb_Copy_CB=csv_CB.Get_columns_count()-3;// Number of columns in the predictor table } // Declare handle_MA_Slow handle_MA_Signal=iMA(Symbol(),Signal_MA_TF,Signal_MA_Period,1,Signal_MA_Metod,Signal_MA_Price); if(handle_MA_Signal==INVALID_HANDLE) { PrintFormat("Failed to create handle of the handle_MA_Signal indicator for the symbol %s/%s, error code %d", Symbol(),EnumToString(Period()),GetLastError()); return(INIT_FAILED); } //--- Create a table to write model values - for debugging purposes if(Use_Save_Result==true) { csv_Chek.Add_column(dt_string,"Data"); csv_Chek.Add_column(dt_double,"Rez"); } return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { if(Save_Pred==true)Save_Pred_All();// Call a function to write predictors to a file delete csv_CB;// Delete the class instance delete csv_Arhiv;// Delete the class instance delete csv_Chek;// Delete the class instance } //+------------------------------------------------------------------+ //| Test completion event handler | //+------------------------------------------------------------------+ double OnTester() { return(CustomPokazatelf(1)); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Operations are only executed when the next bar appears if(!isNewBar()) return; //--- Get information on trading environment (deals/orders) OpenOrdersInfo(); //--- Get signal from the basic strategy if(Signal()==true) { //--- Calculate predictors if(Use_Pred_Calc==true)Pred_Calc(); //---Apply the CatBoost model if(Use_Model_CB==true)Model_CB(); //--- If there is an open position at the signal generation time, close it if(PosType!="0")ClosePositions("Close Signal"); //--- Open a new position if (BuyNow==true)OpenPositions(BUY,1,0,0,"Open_Buy"); if (SellNow==true)OpenPositions(SELL,1,0,0,"Open_Sell"); //--- Copy the table with the current predictors to the archive table if(Save_Pred==true)Copy_Arhiv(); } }
Einstellungen für externe Expert Advisors:
Nachdem wir nun den EA-Funktionscode betrachtet haben, wollen wir sehen, welche Einstellungen der EA hat:
1. Konfigurieren der Aktionen von Prädiktoren:
- "Calculate predictors" — auf "wahr" setzen, wenn Sie die Auswahl speichern oder das CatBoost-Modell anwenden möchten;
- "Save predictors" — auf "wahr" setzen, wenn Sie Prädiktoren für weiteres Training in einer Datei speichern möchten;
- "Volume type in indicators" — setzen Sie den Volumentyp: Ticks oder reales Börsenvolumen;
- "Show predictor indicators on a chart" — auf "wahr" setzen, wenn Sie den Indikator sehen möchten;
- "Commission and spread in points to calculate target" — dies wird zur Berücksichtigung der Provision und des Spreads in Zieletiketten sowie zum Filtern kleinerer positiver Transaktionen verwendet;
2. MA-Indikatorparameter für das grundlegende Strategiesignal:
- "Period"
- "Timeframe";
- "MA methods";
- "Calculation price";
3. Anwendungsparameter des CatBoost-Modells:
- "Apply CatBoost model on data" — kann nach dem Training und dem Kompilieren des Expert Advisors mit dem trainierten Modell auf "true" gesetzt werden;
- "Threshold for classifying one by the model" — der Schwellenwert, bei dem der Modellwert als Eins interpretiert wird;
- "Limit for classifying one by the model" — der Grenzwert, bis zu dem der Modellwert als eine Person interpretiert wird;
- "Save model value to file" — auf "true" setzen, wenn Sie eine Datei zur Überprüfung der Modellkorrektheit erhalten möchten.
Die richtigen strategischen Grundeinstellungen finden
Jetzt gilt es den grundlegenden Strategieindikator optimieren. Wählen Sie ein nutzerdefiniertes Kriterium zur Bewertung der Qualität der Strategieeinstellungen. Im Rahmen des Artikels wurden Tests mit den zusammengeführten Si-Futures-Kontrakten des Brokers Otkritie für den Basiswert USDRUB_TOM durchgeführt. Das Instrument heißt "Si Splice". Der Zeitraum reicht vom 01.06.2014 bis zum 31.10.2020 mit dem Zeitrahmen M1. Testmodellierung: 1 Minute OHLC.
Optimierungsparameter des Expert Advisors:
- "Period": von 8 bis 256 mit einer Schrittweite von 8;
- "Timeframe": von M1 bis D1, ohne Schrittweite;
- "MA methods": von SMA bis LWMA, ohne Schrittweite;
- "Calculation price": von CLOSE bis WEIGHTED.

Abb. 1 "Optimierungsergebnisse".
Aus diesen Ergebnissen müssen wir Werte mit einem hohen nutzerdefinierten Parameter auswählen — vorzugsweise 35% und höher, mit einer Anzahl von 15.000 Positionen und mehr (je mehr, desto besser). Optional können auch andere ökonometrische Variablen analysiert werden.
Ich habe den folgenden Parametersatz vorbereitet, um das Potenzial der Erstellung von Handelsstrategien mit Hilfe des maschinellen Lernens zu demonstrieren:
- "Period": 8;
- "Timeframe": 2 Minuten;
- "MA methods": Linear weighted;
- "Calculation price": Hoch
Wir führen einen einzigen Test durch und überprüfen die Ergebnisgrafik.

Abb. 2 "Saldo vor dem Training"
Solche Strategieeinstellungen können im Handel kaum verwendet werden. Das Signal ist sehr verrauscht und führt zu einer Menge falscher Eröffnungen auf. Versuchen wir, sie zu eliminieren. Im Gegensatz zu denjenigen, die mehrere Parameter verschiedener Indikatoren testen, um ein Signal zu filtern und damit zusätzliche Rechenleistung in Bereichen aufwenden, in denen es keinen oder nur sehr selten (was statistisch unbedeutend ist) Indikatorwerte gab, werden wir nur mit den Bereichen arbeiten, in denen Indikatorwerte tatsächlich Informationen lieferten.
Ändern wir die EA-Einstellungen, um die Prädiktoren zu berechnen und zu speichern. Machen wir jetzt einen einzigen Test:
Konfigurieren der Aktionen von Prädiktoren:
- "Calculate predictors" — gesetzt auf "true";
- "Save predictors" — gesetzt auf "true";
- "Volume type in indicators" — setzen Sie den Volumentyp: Ticks oder reales Börsenvolumen;
- "Show predictor indicators on a chart" — verwenden Sie "false";
- "Commission and spread in points to calculate target" — gesetzte auf 50.
Der Rest der Einstellungen bleibt unverändert. Lassen Sie uns einen einzigen Test im Strategietester durchführen. Die Berechnungen werden langsamer durchgeführt, da wir jetzt Daten aus fast 2000 Indikatorpuffern berechnen und sammeln sowie andere Prädiktormodelle berechnen.
Finden Sie die Datei im Ausführungspfad der Agenten (Ich verwende einen 'portable' Modus, also ist meiner "F:\FX\FX\Otkritie Broker_Demo\Tester\Agent-127.0.0.1-3002\MQL5\Files", "3002" (bezeichnet den Thread, der für die Agenten-Operation verwendet wird ) und überprüfen Sie den Inhalt. Wenn die Datei mit der Tabelle erfolgreich geöffnet wird, dann ist alles in Ordnung.
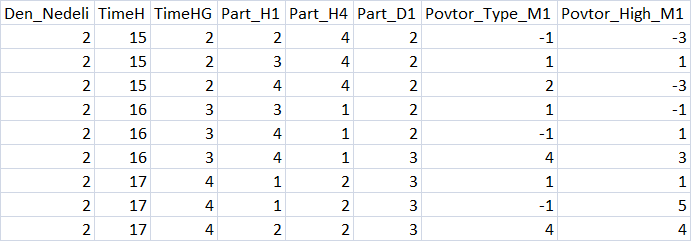
Abb. 3 "Zusammenfassung der Prädiktortabelle"
Aufspalten der Probe
Für weiteres Training teilen Sie die Probe in drei Teile auf und speichern Sie diese in Dateien:
- train.csv — das für das Training verwendete Beispiel
- test.csv — die Probe, die zur Kontrolle des Trainingsergebnisses und zum Abbruch des Trainings verwendet werden soll
- exam.csv — die Stichprobe zur Bewertung des Trainingsergebnisses
Um das Beispiel aufzuteilen, verwenden Sie das Skript CB_CSV_to3x.mq5.
Geben Sie den Pfad zu dem Verzeichnis an, in dem die Erstellung eines Handelsmodells durchgeführt wird, sowie den Namen der Datei, die das Muster enthält.
Eine weitere erstellte Datei ist Test_CB_Setup_0_00000000000 — sie gibt die Indizes der Spalten an, die mit 0 beginnen und für die folgende Bedingung gelten kann: Deaktivieren Sie das Label "Auxiliary" und markieren Sie die Zielspalte mit "Label". Der Inhalt der Datei für unser Beispiel ist wie folgt:
2408 Auxiliary 2409 Auxiliary 2410 Label 2411 Auxiliary 2412 Auxiliary
Die Datei befindet sich an der gleichen Stelle, an der sich auch das durch das Skript vorbereitete Muster befindet.
CatBoost Parameter
CatBoost hat verschiedene Parameter und Einstellungen, die das Trainingsergebnis beeinflussen; sie werden alle hier erklärt. Ich werde hier die Hauptparameter (und ihre Schlüssel, falls vorhanden) erwähnen, die einen größeren Einfluss auf die Modelltrainingsergebnisse haben und die im CB_Bat-Skript konfiguriert werden können:
- "Project directory" — geben Sie den Pfad zu dem Verzeichnis an, in dem sich die "Setup"-Proben befinden;
- "CatBoost exe Dateiname" — ich habe die Version catboost-0.24.1.exe verwendet; Sie sollten die Version angeben, die Sie verwenden;
- "Boosting type (Model boosting scheme)" — es werden zwei Boosting-Optionen ausgewählt:
- Ordered — bessere Qualität bei kleinen Datensätzen, aber es kann langsamer sein.
- Plain — das klassische Gradienten-Boosting-Schema.
- "Tree depth" (Tiefe) — die Tiefe des symmetrischen Entscheidungsbaums, die Entwickler empfehlen Werte zwischen 6 und 10;
- "Maximum iterations (trees)" — die maximale Anzahl von Bäumen, die beim Lösen von maschinellen Lernproblemen aufgebaut werden kann; die Anzahl der Bäume nach dem Lernen kann geringer sein. Wenn in einer Test- oder Validierungsstichprobe keine Modellverbesserung auftritt, sollte die Anzahl der Iterationen im Verhältnis zu einer Änderung des Parameters Lernrate geändert werden;
- "Learning rate" — Gradientenschrittgeschwindigkeit, d.h. Verallgemeinerungskriterium beim Aufbau jedes nachfolgenden Entscheidungsbaums. Je niedriger der Wert, desto langsamer und präziser ist das Training, aber es dauert länger und erzeugt mehr Iterationen, also vergessen Sie nicht, "Maximale Anzahl Iterationen (Bäume)" zu ändern;
- "Methode zur automatischen Berechnung der Zielklassengewichte" (Klassengewichte) — dieser Parameter ermöglicht es, das Training einer unausgeglichenen Stichprobe durch eine Reihe von Beispielen in jeder Klasse zu verbessern. Drei verschiedene Gewichtungsmethoden:
- None — alle Klassengewichte werden auf 1 gesetzt
- Balanced — Klassengewicht basierend auf dem Gesamtgewicht
- SqrtBalanced — Klassengewicht basierend auf der Gesamtzahl der Objekte in jeder Klasse
- "Methode zur Auswahl von Objektgewichten" (Bootstrap-Typ) — der Parameter ist dafür verantwortlich, wie Objekte berechnet werden, wenn Prädiktoren zum Aufbau eines neuen Baumes gesucht werden. Die folgenden Optionen sind verfügbar:
- Bayesian;
- Bernoulli;
- MVS;
- No;
- "Bereich der Zufallsgewichte für die Objektauswahl" (bagging-temperature) — wird verwendet, wenn die Bayes'sche Methode zur Berechnung des Objekts für die Prädiktor-Suche gewählt wird. Dieser Parameter sorgt für Zufälligkeit bei der Auswahl von Prädiktoren für den Baum, was bei der Vermeidung von Überanpassung und beim Auffinden von Mustern hilft. Die Parameter können einen Wert von Null bis unendlich annehmen.
- "Häufigkeit der Probenahme von Gewichten und Objekten beim Bau von Bäumen" (sampling-frequency) — ermöglicht die Änderung der Häufigkeit der Neubewertung von Prädiktoren beim Bau von Bäumen. Unterstützte Werte:
- PerTree — vor der Erstellung jedes neuen Baumes
- PerTreeLevel — vor der Auswahl jeder neuen Teilung eines Baumes
- "Methode des zufälligen Random Teilraums (rsm) — der Prozentsatz der pro Trainingsschritt analysierten Prädiktoren 1=100%. Eine Verringerung des Parameters beschleunigt den Trainingsprozess, fügt etwas Zufälligkeit hinzu, erhöht aber die Anzahl der Iterationen (Bäume) im endgültigen Modell;
- "L2 Regulierung" (l2-leaf-reg) — theoretisch kann dieser Parameter die Überanpassung reduzieren; er beeinflusst die Qualität des resultierenden Modells;
- "Zufallsinitialisierung für das Training" (random-seed) — normalerweise ist er der Generator der Zufallsgewichtskoeffizienten zu Beginn des Trainings. Nach meiner Erfahrung beeinflusst dieser Parameter das Training des Modells signifikant;
- "Der Grad der Zufälligkeit zur Bewertung der Baumstruktur (random-strength)" — dieser Parameter beeinflusst die Schlitzbewertung bei der Erstellung eines Baumes, optimieren Sie ihn, um die Modellqualität zu verbessern;
- "Anzahl der Gradientenschritte zur Auswahl eines Wertes aus der Liste" (leaf-estimation-iterations) — die Blätter werden gezählt, wenn der Baum bereits aufgebaut ist. Sie können einige Gradientenschritte voraus gezählt werden — dieser Parameter beeinflusst die Qualität und Geschwindigkeit des Trainings;
- "Der Quantisierungsmodus für numerische Merkmale" (feature-border-type) — dieser Parameter ist für verschiedene Quantisierungsalgorithmen auf den Probeobjekten verantwortlich. Der Parameter hat großen Einfluss auf die Trainierbarkeit des Modells. Unterstützte Werte:
- Median,
- Uniform,
- UniformAndQuantiles,
- MaxLogSum,
- MinEntropy,
- GreedyLogSum,
- "Die Anzahl der Aufteilungen für numerische Merkmale" (border-count) — dieser Parameter ist für die Anzahl der Aufteilungen des gesamten Wertebereichs jeden Prädiktor verantwortlich. Die Anzahl der Aufspaltungen ist in der Regel tatsächlich geringer. Je größer der Parameter, desto schmaler die Aufspaltung -> desto geringer der Prozentsatz der Beispiele. Er beeinflusst den Lernansatz und die Lernqualität erheblich;
- "Grenzen in einer Datei speichern" (output-borders-file) — Quantisierungsgrenzen können zur weiteren Analyse in einer Datei gespeichert werden, um sie im nachfolgenden Training zu verwenden. Dies wirkt sich auf die Lerngeschwindigkeit aus, da jedes Mal, wenn ein Modell erstellt wird, Daten gespeichert werden;
- "Fehlerbewertungsmetriken für die Lernkorrektur" (loss-function) — eine Funktion, die zur Bewertung der Fehlerbewertung beim Training eines Modells verwendet wird. Ich habe keinen signifikanten Einfluss auf die Ergebnisse bemerkt. Zwei Optionen sind möglich:
- Logloss;
- CrossEntropy;
- "Die Anzahlbäume ohne Verbesserungen, um das Training abzubrechen" (od-wait) — wenn das Training schnell abbricht, versuchen Sie, die Wartezahl zu erhöhen. Ändern Sie auch den Parameter, wenn sich die Lerngeschwindigkeit ändert: je niedriger die Geschwindigkeit, desto länger warten wir auf Verbesserungen, bevor wir das Training beenden;
- "Metrische Funktion der Fehlerbewertung zum Training" (eval-metric) — ermöglicht die Auswahl einer Metrik aus der Liste, nach der der Baum abgeschnitten und das Training beendet wird. Unterstützte Metriken:
- Logloss;
- CrossEntropy;
- Precision;
- Recall;
- F1;
- BalancedAccuracy;
- BalancedErrorRate;
- MCC;
- Accuracy;
- CtrFactor;
- NormalizedGini;
- BrierScore;
- HingeLoss;
- HammingLoss;
- ZeroOneLoss;
- Kappa;
- WKappa;
- LogLikelihoodOfPrediction;
- "Musterobjekt" — ermöglicht die Auswahl eines Modellparameters für das Training. Optionen:
- Keiner
- Random-seed — für Training verwendeter Wert
- Random-strength — der Grad der Zufälligkeit bei der Bewertung der Baumstruktur
- Border-count — Anzahl der Aufteilungen
- l2-Leaf-reg — L2-Regulierung
- Bagging-temperature — Bereich der Zufallsgewichte für die Auswahl von Objekten
- Leaf_estimation_iterations — Anzahl der Gradientenschritte zur Auswahl eines Wertes aus der Liste
- "Anfangsvariablenwert" — festlegen, wo das Training beginnt
- "Endvariablenwert" — festlegen, wo das Training endet
- "Schritt" — Schrittweite der Änderungen
- "Klassifizierungsergebnis-Präsentationstyp"(prediction-type) — wie die Modellantworten geschrieben werden - hat keinen Einfluss auf das Training, das nach dem Training bei der Anwendung des Modells mit Proben verwendet wird:
- Probability — Wahrscheinlichkeit
- Class — Klasse
- RawFormulaVal
- Exponent
- LogProbability
- "Die Anzahl der Bäume im Modell, 0 - alle" — die Anzahl der Bäume im Modell, die für die Klassifizierung verwendet werden sollen, ermöglicht die Bewertung einer Änderung der Klassifizierungsqualität, wenn das Modell auf Stichproben angewendet wird
- "Modellanalysemethode" (fstr-type) — verschiedene Modellanalysemethoden ermöglichen die Bewertung der Prädiktor-Signifikanz für ein bestimmtes Modell. Bitte teilen Sie uns Ihre Ideen dazu mit. Unterstützte Optionen:
- PredictionValuesChange — wie sich die Prognose ändert, wenn sich der Objektwert ändert
- LossFunctionChange — wie sich die Prognose ändert, wenn das Objekt ausgeschlossen wird
- InternalFeatureImportance
- Interaktion
- InternalInteraction
- ShapValues
Das Skript ermöglicht die Suche nach einer Reihe von Parametern der Modelleinrichtung. Wählen Sie dazu ein anderes Objekt als NONE und geben Sie den Startwert, den Endwert und den Schritt an.
Lernstrategie
Ich unterteile die Lernstrategie in drei Stufen:
- Grundeinstellungen sind Parameter, die für die Tiefe und die Anzahl der Bäume im Modell verantwortlich sind, sowie für die Trainingsrate, die Klassengewichte und andere Einstellungen, um den Trainingsprozess zu starten. Diese Parameter werden nicht durchsucht; in den meisten Fällen reichen die vom Skript generierten Standardeinstellungen aus.
- Suche nach optimalen Aufteilungsparametern — CatBoost verarbeitet die Tabelle der Prädiktoren vor, um Wertebereiche entlang der Gittergrenzen zu durchsuchen, und daher müssen wir ein Gitter finden, in dem das Training besser ist. Es macht Sinn, über alle Gittertypen mit einem Bereich von 8-512 zu iterieren; ich benutze bei jedem Wert Stufenschritte: 8, 16, 32 und so weiter.
- Konfigurieren wir das Skript erneut, geben Sie das gefundene Prädiktor-Quantisierungsgitter an, und danach können wir zu weiteren Parametern übergehen. Normalerweise verwende ich "Seed" nur im Bereich von 1-1000.
In diesem Artikel werden wir für die erste Stufe der "Lernstrategie" die Standardeinstellungen CB_Bat verwenden. Die Splitting-Methode wird auf "MinEntropie" eingestellt, das Raster wird Parameter von 16 bis 512 mit einem Schritt von 16 testen.
Um die oben beschriebenen Parameter einzurichten, verwenden wir das Skript "CB_Bat", das Textdateien mit den erforderlichen Schlüsseln für Trainingsmodelle sowie eine Hilfsdatei erstellt:
- _00_Dir_All.txt - Hilfsdatei
- _01_Train_All.txt - Einstellungen für Training
- _02_Rezultat_Exam.txt - Einstellungen für die Aufzeichnung der Klassifizierung durch die Prüfungsprobenmodelle
- _02_Rezultat_test.txt - Einstellungen für die Aufzeichnung der Klassifizierung durch die Modelle der Testproben
- _02_Rezultat_Train.txt - Einstellungen für die Aufzeichnung der Klassifizierung durch die Modelle der Lernprobenmodelle
- _03_Metrik_Exam.txt - Einstellungen für die Aufzeichnung der Metriken jedes Baumes der Prüfungsprobenmodelle
- _03_Metrik_Test.txt - Einstellungen für die Aufzeichnung der Metriken jedes Baums der Testprobenmodelle
- _03_Metrik_Train.txt - Einstellungen für die Aufzeichnung der Metriken jedes Baumes der Trainingsprobenmodelle
- _04_Analiz_Exam.txt - Einstellungen zur Aufzeichnung der Bewertung der Wichtigkeit des Prädiktors für die Modelle der Prüfungsprobenmodelle
- _04_Analiz_Test.txt - Einstellungen zur Aufzeichnung der Bewertung der Wichtigkeit des Prädiktors für die Testprobenmodelle
- _04_Analiz_Train.txt - Einstellungen für die Aufzeichnung der Bewertung der Wichtigkeit des Prädiktors für die Modelle der Trainingsprobenmodelle
Wir könnten eine Datei erstellen, die Aktionen nach dem Training sequentiell ausführt. Aber um die CPU-Auslastung zu optimieren (was in früheren Versionen von CatBoost besonders wichtig war), starte ich nach dem Training 6 Dateien.
Modell-Training
Sobald die Dateien fertig sind, benennen wir die Datei "_00_Dir_All.txt" in "_00_Dir_All.bat" um und führen sie aus - sie erstellt die erforderlichen Verzeichnisse zum Auffinden von Modellen und ändert die Erweiterung anderer Dateien in "bat".
Nun enthält unser Projektverzeichnis den Ordner "Setup" mit folgendem Inhalt:
- _00_Dir_All.bat - Hilfsdatei
- _01_Train_All.bat - Einstellungen für das Training
- _02_Rezultat_Exam.bat - Einstellungen für die Aufzeichnung der Klassifikation durch die Modelle der Prüfungsproben
- _02_Rezultat_test.bat - Einstellungen für die Aufzeichnung der Klassifizierung durch die Modelle der Testproben
- _02_Rezultat_Train.bat - Einstellungen für die Aufzeichnung der Klassifikation durch die Modelle der Lernproben
- _03_Metrik_Exam.bat - Einstellungen für die Aufzeichnung der Metriken jedes Baumes der Modelle der Prüfungsproben
- _03_Metrik_Test.bat - Einstellungen für die Aufzeichnung der Metriken jedes Baumes der Modelle der Testproben
- _03_Metrik_Train.bat - Einstellungen für die Aufzeichnung der Metriken jedes Baumes der Modelle der Trainingsproben
- _04_Analiz_Exam.bat - Einstellungen zur Aufzeichnung der Bewertung der Wichtigkeit der Prädiktors für die Modelle der Prüfungsproben
- _04_Analiz_Test.bat - Einstellungen zur Aufzeichnung der Bewertung der Wichtigkeit des Prädiktors für die Modelle der Testproben
- _04_Analiz_Train.bat - Einstellungen zur Aufzeichnung der Bewertung der Wichtigkeit des Prädiktors für die Modelle der Trainingsproben
- catboost-0.24.1.exe - ausführbare Datei für das Training von CatBoost-Modellen
- train.csv - die für das Training zu verwendende Proben
- test.csv — die Probe, die zur Kontrolle des Trainingsergebnisses und zum Abbruch des Trainings verwendet werden soll
- exam.csv - die Probe zur Bewertung der Ergebnisse
- Test_CB_Setup_0_00000000000//Datei mit Informationen über die für Training verwendeten Beispielspalten
Führen Sie "_01_Train_All.bat" aus und beobachten Sie den Trainingsprozess.
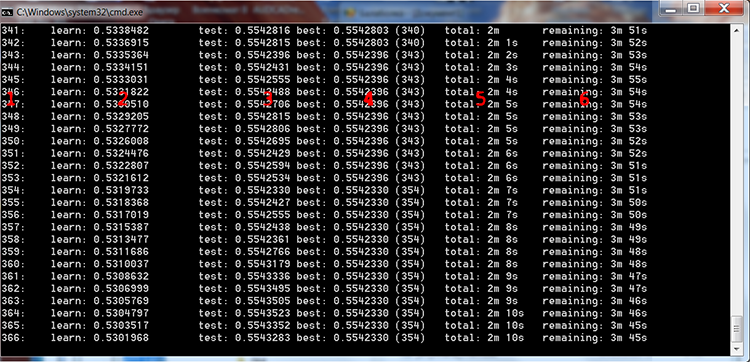
Abb. 4 CatBoost-Trainingsprozess
In der obigen Abbildung habe ich zur Beschreibung der Spalten rote Zahlen hinzugefügt:
- Die Anzahl der Bäume, die der Anzahl der Iterationen entspricht
- Das Ergebnis der Berechnung der ausgewählten Verlustfunktion auf der Trainingsprobe
- Das Ergebnis der Berechnung der gewählten Verlustfunktion auf der Kontrollprobe
- Das beste Ergebnis der Berechnung der gewählten Verlustfunktion auf der Kontrollprobe
- Die seit Beginn des Modell-Trainings tatsächlich verstrichene Zeit
- Geschätzte verbleibende Zeit bis zum Ende des Trainings, wenn alle durch die Einstellungen festgelegten Bäume trainiert werden
Wenn wir in den Skript-Einstellungen einen Suchbereich wählen, werden die Modelle in einer Schleife so oft trainiert, wie es der Dateiinhalt erfordert:
FOR %%a IN (*.) DO ( catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_16\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 16 --feature-border-type MinEntropy --output-borders-file quant_4_00016.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_32\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 32 --feature-border-type MinEntropy --output-borders-file quant_4_00032.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_48\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 48 --feature-border-type MinEntropy --output-borders-file quant_4_00048.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_64\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 64 --feature-border-type MinEntropy --output-borders-file quant_4_00064.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_80\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 80 --feature-border-type MinEntropy --output-borders-file quant_4_00080.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_96\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 96 --feature-border-type MinEntropy --output-borders-file quant_4_00096.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_112\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 112 --feature-border-type MinEntropy --output-borders-file quant_4_00112.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_128\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 128 --feature-border-type MinEntropy --output-borders-file quant_4_00128.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_144\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 144 --feature-border-type MinEntropy --output-borders-file quant_4_00144.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 catboost-0.24.1.exe fit --learn-set train.csv --test-set test.csv --column-description %%a --has-header --delimiter ; --model-format CatboostBinary,CPP --train-dir ..\Rezultat\RS_160\result_4_%%a --depth 6 --iterations 1000 --nan-mode Forbidden --learning-rate 0.03 --rsm 1 --fold-permutation-block 1 --boosting-type Plain --l2-leaf-reg 6 --loss-function Logloss --use-best-model --eval-metric Logloss --custom-metric Logloss --od-type Iter --od-wait 100 --random-seed 0 --random-strength 1 --auto-class-weights SqrtBalanced --sampling-frequency PerTreeLevel --border-count 160 --feature-border-type MinEntropy --output-borders-file quant_4_00160.csv --bootstrap-type Bayesian --bagging-temperature 1 --leaf-estimation-method Newton --leaf-estimation-iterations 10 )
Sobald das Training abgeschlossen ist, werden wir alle 6 verbleibenden bat-Dateien auf einmal starten, um Trainingsergebnisse in Form von Etiketten und statistischen Werten zu erhalten.
Ausdrückliche Bewertung der Lernergebnisse
Verwenden wir das Skript CB_Calc_Svod.mq5, um die metrischen Variablen der Modelle und ihre finanziellen Ergebnisse zu erhalten.
Dieses Skript verfügt über einen Filter für die Auswahl von Modellen nach der Endbilanz der Untersuchungsstichprobe: Wenn die Bilanz höher als ein bestimmter Wert ist, kann ein Bilanzgraph aus der Stichprobe erstellt und die Stichprobe in mqh konvertiert und in einem separaten Verzeichnis des CatBoost-Modellprojekts gespeichert werden.
Warten Sie, bis das Skript abgeschlossen ist - in diesem Fall sehen Sie das neu erstellte "Analiz", das die Datei CB_Svod.csv enthält, und die Bilanzgrafiken nach dem Modellnamen, falls deren Darstellung in den Einstellungen ausgewählt wurde, sowie das Verzeichnis "Models_mqh", das die in das mqh-Format konvertierten Modelle enthält.
Die Datei "CB_Svod.csv" enthält die Metriken der einzelnen Modelle, für die die einzelnen Stichproben erstellt wurden, sowie die Finanzergebnisse.
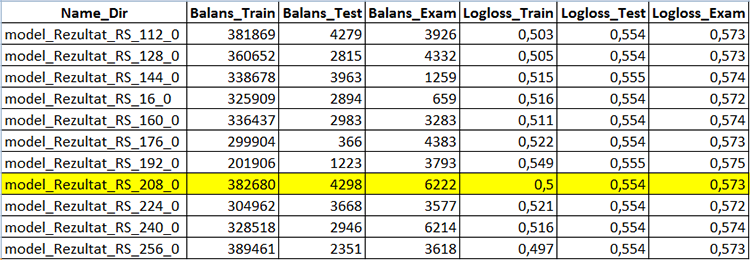
Abb. 5 Teil der Tabelle mit den Ergebnissen der Modellerstellung - CB_Svod.csv
Wählen Sie das gewünschte Modell aus dem Unterverzeichnis Models_mqh des Verzeichnisses aus, in dem unsere Modelle trainiert wurden, und fügen Sie es dem Verzeichnis Expert Advisor hinzu. Kommentieren Sie die Zeile mit leeren Puffern am Anfang des EA-Codes mit "//" aus. Jetzt brauchen wir nur noch die Modelldatei mit dem EA zu verbinden:
//If the CatBoost model is in an mqh file, comment the below line //uint TreeDepth[];uint TreeSplits[];uint BorderCounts[];float Borders[];double LeafValues[];double Scale[];double Bias[]; #include "model_RS_208_0.mqh"; // Model file
Nachdem Sie den Expert Advisor kompiliert haben, setzen Sie die Einstellung "Apply CatBoost model on data" auf "true", deaktivieren Sie die Probenspeicherung und führen Sie den Strategietester mit den folgenden Parametern aus.
1. Konfigurieren der Aktionen von Prädiktoren:
- "Calculate predictors" — gesetzt auf "true";
- "Save predictors" — auf "falsch" setzen
- "Volumentyp des Indikators" — legen Sie den Volumentyp fest, den Sie im Training verwendet haben
- "Anzeigen des Prädiktors auf dem Chart" — "falsch" verwenden
- "Commission and spread in points to calculate target" — verwenden Sie den vorherigen Wert, er hat keinen Einfluss auf das fertige Modell
2. MA-Indikatorparameter für das grundlegende Strategiesignal:
- "Period": 8;
- "Timeframe": 2 Minuten;
- "MA methods": Linear weighted;
- "Calculation price": Hoch
3. Anwendungsparameter des CatBoost-Modells:
- "Apply CatBoost model on data" — auf "wahr" gesetzt
- "Threshold for classifying one by the model" — bei 0,5 lassen;
- "Limit for classifying one by the model" — belassen bei 1
- "Save model value to file" — "falsch" lassen
Das folgende Ergebnis wurde für den gesamten Probenzeitraum erhalten.
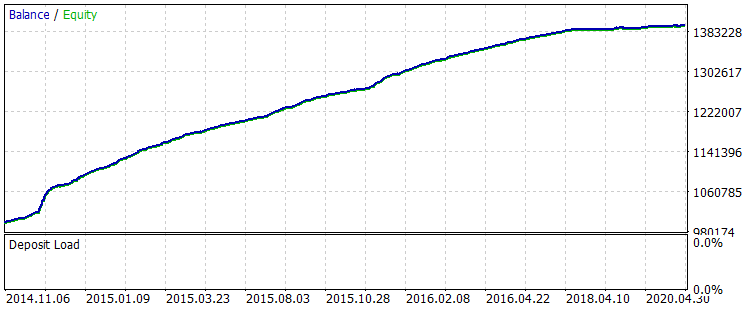
Abb. 6 Saldenkurve nach Training über den Zeitraum 01.06.2014 - 31.10.2020
Vergleichen wir zwei Saldenkurve auf dem Intervall vom 01.08.2019 bis 31.10.2020, das außerhalb der Trainingszeit liegt - dies entspricht der Stichprobe exam.csv, vor und nach dem Training.
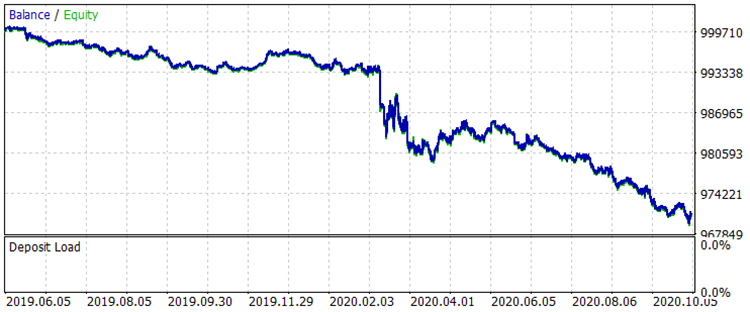
Abb. 7 Bilanz vor Training für den Zeitraum 01.08.2019 - 31.10.2020
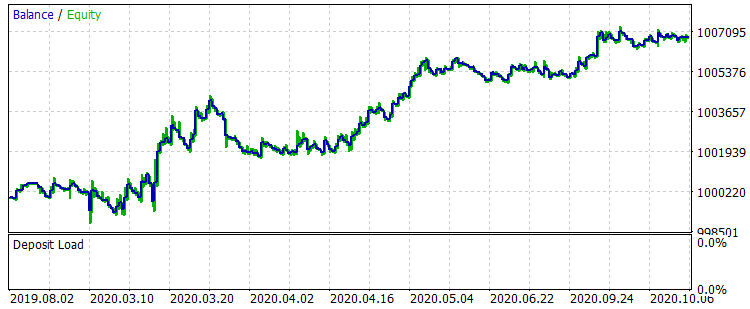
Abb. 8 Saldenkurve nach Training für den Zeitraum 01.08.2019 - 31.10.2020
Die Ergebnisse sind nicht sehr beeindruckend, aber es kann festgestellt werden, dass die Haupthandelsregel "Geldverlust vermeiden" eingehalten wird. Selbst wenn wir ein anderes Modell aus der Datei CB_Svod.csv wählen würden, wäre der Effekt immer noch positiv, denn das finanzielle Ergebnis des erfolglosesten Modells, das wir erhalten haben, beträgt -25 Punkte, und das durchschnittliche finanzielle Ergebnis aller Modelle beträgt 3889,9 Punkte.
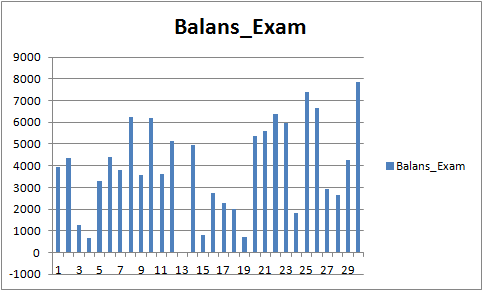
Abb. 9 Finanzielles Ergebnis der trainierten Modelle für den Zeitraum 01.08.2019 - 31.10.2020
Analyse der Prädiktoren
Jedes Modellverzeichnis (für mich MQL5\Files\CB_Stat_03p50Q\Rezultat\RS_208\resultat_4_Test_CB_Setup_0_000000000) hat 3 Dateien:
- Analiz_Train - Analyse der Bedeutung des Prädiktors auf der Stichprobe des Trainings
- Analiz_Test - Analyse der Bedeutung des Prädiktors auf der Test- (Validierungs-) Stichprobe
- Analiz_Exam - Analyse der Bedeutung des Prädiktors bei der Prüfung (außerhalb des Trainings)
Der Inhalt wird unterschiedlich sein, je nachdem, welche "Modellanalysemethode" bei der Generierung der Dateien für das Training gewählt wird. Betrachten wir den Inhalt mit "PredictionValuesChange".
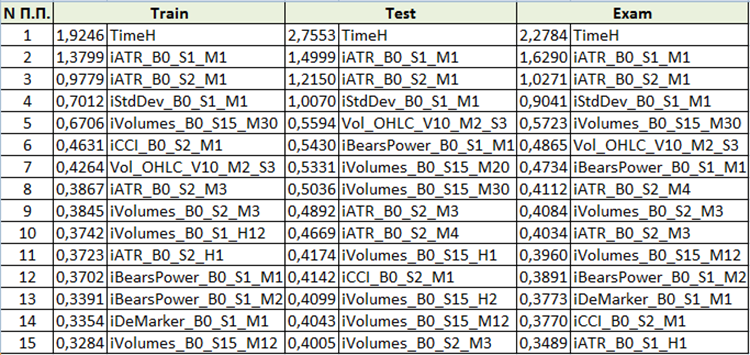
Abb. 10 Zusammenfassende Tabelle der Analyse der Wichtigkeit der Prädiktoren
Aus der Bewertung der Bedeutung des Prädiktors können wir schließen, dass die ersten vier Prädiktoren für das resultierende Modell durchweg wichtig sind. Bitte beachten Sie, dass die Bedeutung der Prädikatoren nicht nur vom Modell selbst, sondern auch von der ursprünglichen Stichprobe abhängt. Wenn der Prädiktor in dieser Stichprobe nicht genügend Werte hatte, kann er nicht objektiv bewertet werden. Diese Methode erlaubt es, die allgemeine Idee der Wichtigkeit des Prädiktors zu verstehen. Seien Sie jedoch bitte vorsichtig damit, wenn Sie mit auf Handelssymbolen basierenden Stichproben arbeiten.
Schlussfolgerungen
- Die Wirksamkeit von Methoden des maschinellen Lernens, wie z.B. Gradientenverstärkung, kann mit der einer endlosen Iteration von Parametern und der manuellen Schaffung zusätzlicher Handelsbedingungen in dem Bemühen um eine Verbesserung der Strategieleistung verglichen werden.
- Standard MetaTrader 5 Indikatoren können für die Zwecke des maschinellen Lernens helfen.
- CatBoost - ist eine hochwertige Bibliothek mit einem Wrapper, der die effiziente Nutzung von Gradienten-Boosting ermöglicht, ohne Python oder R lernen zu müssen.
Schlussfolgerung
Der Zweck dieses Artikels ist es, Ihre Aufmerksamkeit auf maschinelles Lernen zu lenken. Ich hoffe wirklich, dass die detaillierte Beschreibung der Methodik und die zur Verfügung gestellten Reproduktionswerkzeuge dazu führen werden, dass neue Fans des maschinellen Lernens auftauchen. Lassen Sie uns gemeinsam versuchen, neue Ideen zum maschinellen Lernen zu finden, insbesondere ideale Ideen für die Suche nach Prädiktoren. Die Qualität eines Modells hängt von den Eingabedaten und dem Ziel ab, und wenn wir unsere Anstrengungen vereinen, können wir das gewünschte Ergebnis schneller erreichen.
Sie sind mehr als willkommen, Fehler in meinem Artikel und Code zu melden.